金磊 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
“我们已经进入了一个可以进行复杂思考的新阶段。”
OpenAI的CEO奥特曼在年度回顾中,分享了他对大型模型未来发展的看法。
推理模型的重要性日渐凸显,已经成为各大厂商争相角逐的新战场。
在推理模型竞争中,究竟哪一家的能力最强呢?最近,这个问题有了答案。
最近,中国信息通讯研究院(信通院)发布了一份关于大模型推理能力的最新评估报告,结果显示——
文心X1 Turbo在24项能力评估中取得了16项5分、7项4分、1项3分的佳绩,综合评分达到当前的最高“4+级”。
而且它还是国内首款,唯一通过这一评测的大模型。

文心为何能获得“4+级”的认可呢?
人类思维的模仿者:多模态的结合
在最近的AI Day活动上,吴甜副总裁分享了关于文心大模型的一些新进展,特别是上个月推出的
- 文心4.5 Turbo,注重多模态技术,其性能在文心4.5的基础上有了显著提升,同时成本也相对降低。
- 而文心X1 Turbo则强化了思维的深度,继承自X1的基础上,性能大幅提升,并具备更先进的思维链,问答、创作、逻辑推理、工具调用和多模态能力也得到了全面增强。
这两个新模型的最大亮点,恰恰体现了文心大模型发展的两个关键词——多模态融合和深度思考。
多模态技术在文心大模型中的应用

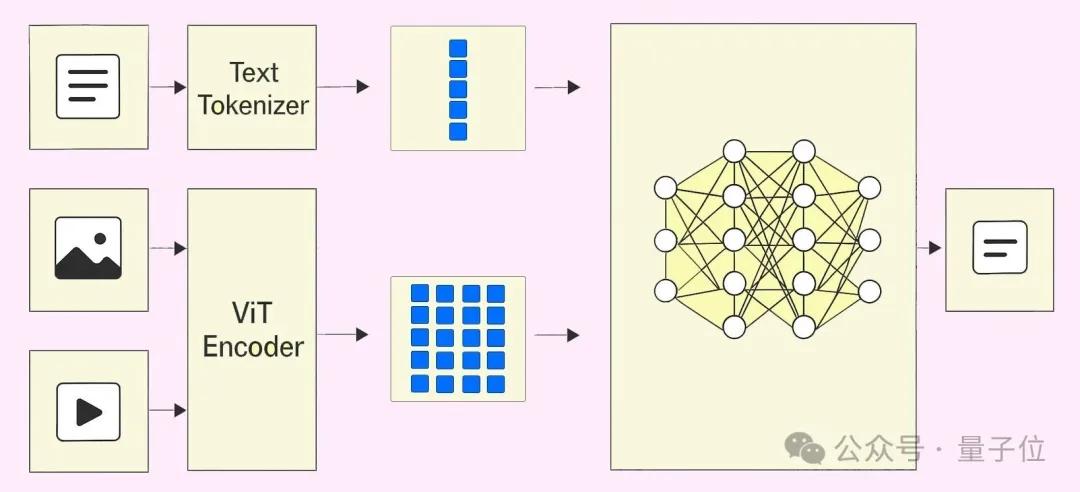
我们先说说多模态吧,文心大模型在这个领域的一个重要技术就是多模态混合训练。
简单来说,就是把文本、图像和视频这些不同的模态进行统一建模和融合训练。
为了处理这些模态在结构、规模和知识密度上不同的特点,百度采用了多模态异构专家建模、自适应分辨率视觉编码、时空重排列的三维旋转位置编码、还有自适应模态感知损失计算等关键技术。
这些技术不仅深入挖掘了各个模态的特征,还大大提升了模型在不同模态间学习的效率和融合效果,整体训练效率提升了近2倍,多模态理解能力提升超过30%。
在后训练阶段,有一项非常重要的技术,就是采用了一个自反馈增强技术框架,这让文心大模型变得更加聪明。
简单来说,这个框架是基于模型自身的生成与评估能力,形成了一种“训练—生成—反馈—增强”的闭环机制。
也就是说,这个技术让大模型能够像我们人类一样,在实践中不断自我提升,真是太酷了!
这种机制不仅解决了大模型在对齐过程中面临的数据生产难度大、成本高和速度慢的问题,还显著降低了模型产生错误信息的风险,帮助模型在处理复杂任务时的能力大幅提升。
而且,通过融合偏好学习的强化学习技术,文心大模型还实现了一个多元统一的奖励机制,这极大地提高了对结果质量的判断准确性。
在对离线和在线学习进行统一优化后,数据利用效率和训练的稳定性都有了显著提升,模型对高质量结果的感知能力也得到了增强。
此外,偏好信号与奖励信号的有效结合,全面提升了模型在理解、生成、逻辑和记忆等方面的能力。
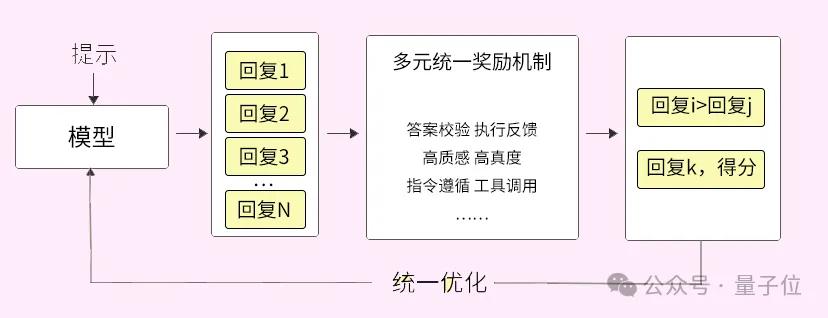
△ 融合偏好学习的强化学习
文心X1 Turbo:打破传统思维的全新突破
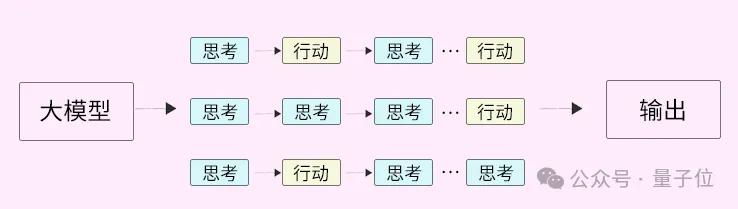
说白了,文心X1 Turbo在思维模型上进行了一次重大革新,不再仅仅依赖于线性的思维链条。
它巧妙地把工具的调用融入到思考的过程中,形成了一种新型的“复合型思维链”,这可真是个创新的思路!
其实,人类在思考和行动时,往往会有多条不同的路径可走,而文心正是把这种灵活的模式应用到它的思维模型中。
在实际操作中,模型可以根据具体任务的需求,选择“边思考边行动”、“先思考后执行”或者“尝试后反思”等多种策略,这样的灵活性真是太棒了!
这意味着,模型在处理问题时,更加贴近人类的思维方式,让它在面对复杂和长期的任务时表现得更加出色。
再加上多元化奖励机制的优化训练,模型在应对跨领域和复杂任务时,思维的广度和逻辑深度都有了显著提升,整体效果居然提高了超过22%呢!
通过上述技术,我们可以看到文心在多模态和深度思考方面的努力,正好契合了大模型发展的两个重要趋势:一是不同模态的融合,二是模仿人类的思维过程。
不仅如此,文心大模型在算法之外,还在数据和基础设施方面进行了大量的技术攻关,真是下足了功夫啊!
聊聊文心大模型的强大数据构建能力
比如说,在数据构建方面,文心大模型可是下足了功夫,搭建了一整套的闭环机制,从“数据挖掘与合成”到“数据分析与评估”再到“模型能力反馈”,环环相扣,真是个系统工程。
这个机制的牛之处在于,它不仅能源源不断地提供高质量且多样化的数据,还具备极强的扩展性,能够迅速适应新出现的数据类型和任务场景。
在这样的体系下,数据构建不仅要确保事实准确、覆盖面广,还得遵循基本原理,确保语义的准确还原,简直是对数据质量的严格把控。
除此之外,文心还引入了一些稀缺知识点来驱动数据挖掘,同时结合真实的线上反馈,自动化地构建数据流程,再加上高效的多模态平行数据构建策略,都是在不断推动模型能力的提升。
从基础设施的角度看,百度在大模型领域有个独特的优势,就是他们自家的飞桨框架。
在底层技术上,百度通过优化框架和模型之间的协作,以及框架和算力的配合,实现了降本增效,真是聪明的做法。
比如说文心4.5 Turbo在飞桨框架的支持下,训练效率是文心4.5的5.4倍,推理能力更是提升了8倍以上,效率飙升。
而且,飞桨框架3.0的推出,还进一步增强了对各种异构芯片的适配能力,支持多模态大模型和并行训练的效率,真是个好消息。
所以,从这次分享的信息来看,百度在提升大模型的训练和推理性能方面的优化思路是非常清晰的——
算力、框架和模型完美结合,深度协同优化。
而且从目前获得的成绩来看,这种优化策略已经显现出了效果,真是让人振奋!
文心4.5 Turbo的表现真让人惊喜!
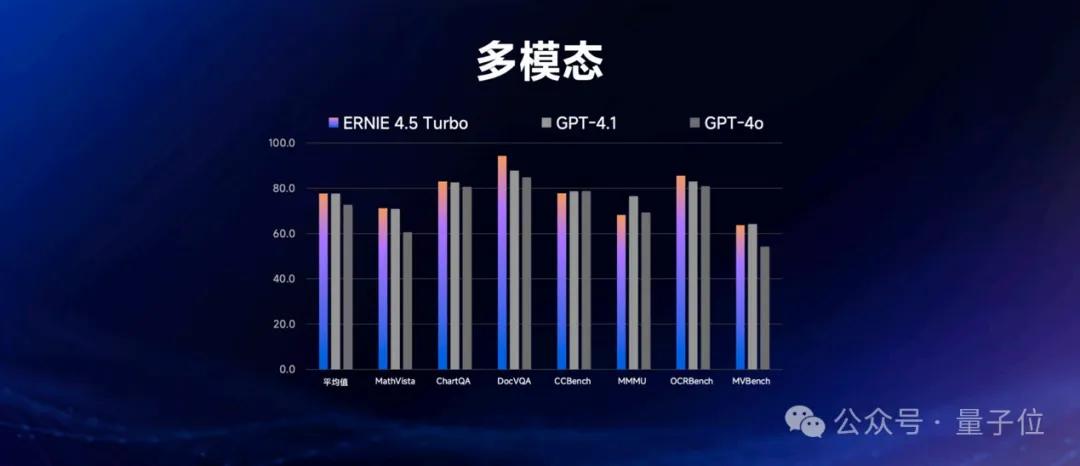
在文本处理方面,文心4.5 Turbo的表现非常出色,它在包含中文、数学、代码等内容的14个数据集上,平均得分达到了80分,超越了GPT-4.5和DeepSeek-V3,这可真是个好消息!
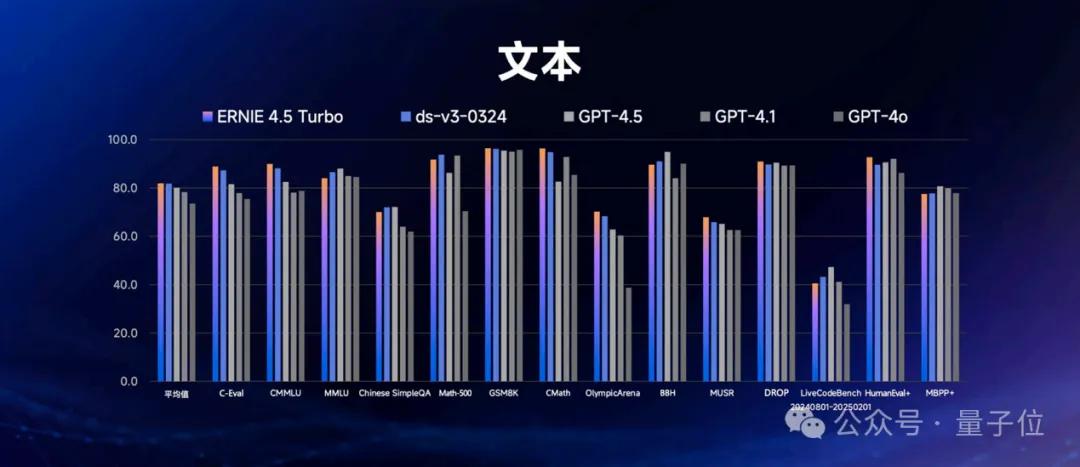
在多模态能力方面,文心4.5 Turbo同样表现优于GPT-4.1和GPT-4o,这说明它的综合能力非常强。
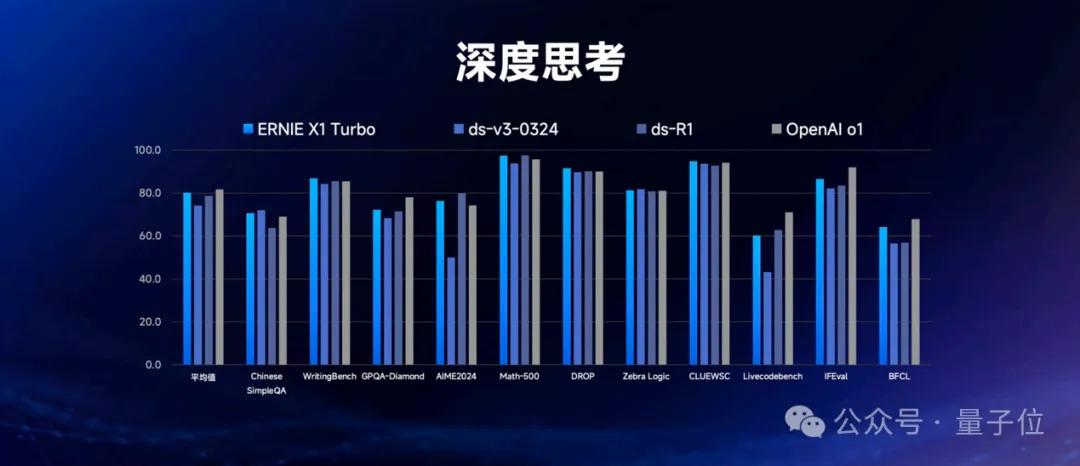
在深度思考方面,文心X1 Turbo也毫不逊色,无论是在各项数据集还是综合得分上,都明显超过了DeepSeek-R1,真是让人刮目相看。
AI的应用场景与实用性
当然,评测结果只能算是“效果”的一种数字化表现,要想真正感受文心的实力,还得看看它在实际应用场景中的表现。
文心X1 Turbo:像人一样思考的AI助手
比如在学习的时候,解物理题,文心X1 Turbo只需看一眼,就能快速推理出清晰的解题步骤和答案,真是太厉害了。

就像之前提到的自反馈机制,通过这个例子,我们能明显感受到文心X1 Turbo在作答时的思维过程,简直就像人类一样。
自然语言是我们沟通的桥梁,而形式语言则是程序能理解的严谨逻辑。大模型在这两者之间架起了一座桥,让思考变得可执行。
在代码应用中,百度依托文心大模型,推出了代码智能体和智能代码助手——文心快码,真是个好帮手。
如今,百度每天新增的代码中,AI生成的部分已经超过了40%,而且这项服务已经帮助了760万开发者,真是个庞大的数字。
百度在更复杂的应用场景中也在不断拓展布局。
以数字人为例,超拟真数字人需要展现出色的表现力,还要与场景和物品进行良好互动,这就需要运用多模态AI技术来实现。
百度利用“剧本”来驱动多模协同的超拟真数字人技术,成功实现了语言、声音和形象的完美结合。
百度的技术实力:六年的蜕变与全栈能力
从2019年的文心1.0到如今的文心4.5 Turbo和X1 Turbo,短短六年时间,文心大模型已经经历了九次重要的版本更新。
而这两款型号,实际上只是百度大模型技术的一个小切面,要想真正了解它的全部,还得从多个维度去深入挖掘。
这项技术目前已经支持了超过十万名数字人主播,直播转化率高达31%,而且直播的启动成本还下降了80%呢!

从行业的角度来看,百度展示的这些应用场景,都是当前大模型应用的热门趋势。
举个例子,在教育领域,根据贝哲斯的报告,到2029年,全球在线教育市场中,K-12教育的规模预计会达到8991.59亿元,年均复合增长率为7.89%。在这波增长中,大模型会扮演非常关键的角色。
至于代码的部分,那就更不必说了。在大模型的评估中,代码能力是一个必不可少的标准,实际上,这也是大模型,尤其是推理模型的主要应用场景。
至于数字人方面,中国互联网协会预测,今年数字人核心市场的规模将达到480.6亿元,几乎是2022年的四倍,同时,这也将推动整个产业市场规模达到6402.7亿元。
从这些技术和应用的布局中,可以看出,百度不仅拥有独特的技术优势,而且已经成功地将这些优势转化为市场上热衷的应用场景。
通过这些布局,我们也能清晰地看到,百度在大模型领域的道路正逐渐显露出轮廓。
百度的大模型之路:从技术到思考的深度探索
说到技术,文心大模型在多模态和深度思考方面真的下了不少功夫。通过强化学习,让模型自我调优,再加上他们强大的技术实力和丰富的数据支持,这一切都让人刮目相看。
从多种知识的融合学习,到增强知识点的能力,再到提升检索、对话和逻辑推理的效果,文心大模型的表现和效率都在不断提升,能力的边界也在持续扩展,真的是一步一个脚印啊。
那么,随之而来的问题自然是:
那么,百度的大模型究竟是怎样的一条发展道路呢?
深入分析之后,我们发现:
文心大模型自2019年3月发布以来,其核心技术框架始终如一,其中,预训练环节对模型的构建至关重要,为其能力打下了坚实基础。
而且,文心一直以来都非常重视事实性、时效性和知识性,并通过知识增强技术来进一步强化这些特性。
在这样的框架下,文心逐渐发展出了智能体技术(也就是模型的思考能力),结合工具的使用能力,来解决现实中的复杂难题。这些都是文心一直以来的核心技术方向。
当然,具体的技术方法也在不断演进。除了预训练阶段,后续的训练(比如强化学习)变得越来越重要,推动模型在原有基础上不断优化和升级。
标题:文心大模型的发展之路:从技术深耕到未来探索

在这个大模型飞速发展的时代,量子位和吴甜的对话中,她提到了文心大模型的独特观点:
首先,行业的快速进步并不让人意外,这是一次全新的科技革命,而不是一时的热潮。回顾历史,每一场科技革命都需要漫长的演变周期,大模型技术也一样——它将在未来的岁月里深刻改变各行各业的运作方式和思维模式。
其次,技术的影响是像涟漪般逐步扩散的:从技术的突破到实际应用,再到最终改变生活,这个过程是渐进的。因此,我们要用动态的视角看待这些发展,既要关注现在的快速变化,也要重视技术的长远价值。
基于以上观点,文心大模型团队始终专注于技术的深耕与前瞻探索。我们意识到未来还有很多方向可以突破,会不断推动技术向更高的目标前进,为行业的下一次变革做好准备。
总结来说,百度的态度是不仅保持敏锐的洞察力,还要坚持长远的视角。
从更宽广的视角来看,自“百模大战”以来,大模型的竞争已经初见收敛,但结局显然还没到;未来还有很多参与者可能会被淘汰。
但可以肯定的是,百度在技术积累和全面能力上,尤其是从底层框架飞桨到上层应用的完整技术链,将是它在决赛圈中脱颖而出的关键。
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态










文心大模型的多模态技术真是让人惊叹,能够有效融合文本、图像和视频,提升了理解能力和学习效率,期待未来的更多应用!
文心大模型在推理能力上的表现令人印象深刻,尤其是自反馈增强技术的应用,确实让模型像人一样不断进步,期待未来能带来更多创新。
文心X1 Turbo的表现真是超出预期,尤其是在多模态融合方面,展现了强大的能力,让人对未来的应用充满期待。
自反馈增强技术的引入让文心大模型学习变得更高效,能够在实践中自我提升,真是太棒了!
文心4.5 Turbo的多模态混合训练效果显著,整体训练效率提升了近2倍,这种技术的进步真令人振奋。
看到文心在推理模型方面取得的成就,尤其是综合评分达到4+级,感到非常欣慰,期待未来更多突破。
文心大模型的多模态混合训练技术太先进了,能有效提升模型在不同模态间的学习效率,真是引领了行业的新方向。期待看到更多的实际应用案例!