
嘿,朋友们,今天小圆要和大家聊聊最近AI界的热议话题:OpenAI刚刚发布的GPT-5.2。它刚刚以“完胜”谷歌的Gemini 3.0 Pro引起了大家的关注,结果又被曝出可能存在“作弊”的嫌疑。
这个事件的焦点其实很简单:在一些重要的测试中,它使用的token数量远超对手,才拿到了高分。不少网友对此表示,这样的胜利并不光彩。那这场看似激烈的AI较量,背后又藏着什么秘密呢?


这场胜利有点水分
事情的起因是某位用户的深思熟虑的计算,揭露了GPT-5.2高分背后的玄机。用远超对手的token消耗换取的高分,究竟算不算真正的实力呢?在AI的世界里,token就好比模型的“思考字数”,消耗越多代表使用的算力和资源越多,成本自然也跟着上涨。
最明显的对比就来自ARC AGI 2测试,这是AI领域公认的严苛评测标准。数据显示,GPT-5.2的xhigh版本取得了52.9%的得分,看似不错,但每个任务的token消耗高达约13.5万个;而谷歌的Gemini 3.0 Pro只花了6.7万个token就达到了相近的成绩,效率简直翻了一番。

实力难分高下的AI模型
说白了,当我们把算力标准化后,这两个模型的真实表现其实很难区分。在一些测试,比如HLE和MMMU-Pro中,GPT-5.2虽然消耗了更多的token,但结果却不尽人意。反倒是在OpenAI自己设计的GDPVal测试集上,它才显得有些突出。要知道,裁判和选手是同一个机构,这样的结果自然让人有些怀疑。

AI评测的真实困境
其实,不光是OpenAI,谷歌也不甘示弱。在谷歌推出的FACTS Benchmark测试中,Gemini 2.5 Pro竟然“超过”了GPT-5,结果也让人半信半疑。就连相对中立的SWE软件工程评测,情况也很复杂,各个模型在不同任务中各有千秋,真没哪个能稳稳领先。
这些现象的背后,归根结底还是利益驱动。随着AI技术商业化的加速,榜单的好成绩直接影响着公司的估值、融资和用户的信任。所以为了在竞争中占得先机,各家厂商自然会调整测试参数,甚至定制测试集,这种“军备竞赛”的模式,实际上已经偏离了AI发展的初衷。

从“敢说真话”到“专心卖货”
OpenAI的转变让人咋舌。对普通用户而言,榜单分数再好看,实际使用起来才是最重要的。然而,GPT-5.2的用户体验和评测成绩之间的差距却很大。有网友反映它在检查代码时“幻觉”频频,连自己写的函数都搞不懂;还有人抱怨它像把成年人当幼儿对待,竟然不如之前的GPT-4o好用。
用户的体验下降,背后其实反映了OpenAI的战略变化。曾几何时,OpenAI是一个勇于直面挑战的研究机构,在2023年还发表了关于AI对行业颠覆风险的论文,甚至登上了《科学》杂志;但如今,它似乎更像是在“专心做生意”的公司。

今年9月发布的《全球用户如何使用ChatGPT》报告,满篇都是AI如何提升效率和创造价值的内容,却对“AI取代就业”这样敏感的话题避而不谈,这种变化直接导致了核心研究人员的流失。经济研究的核心成员Tom Cunningham在离开时直言,团队从严谨的学术研究变成了“公司的宣传部门”。
探讨AI负面影响的课题要么被要求修饰措辞,要么干脆被搁置;而前安全研究员则公开指出ChatGPT可能给用户心理带来的风险。与此相比,竞争对手Anthropic的CEO还敢公开警告AI对初级白领的威胁,虽然这可能是为了引起监管的注意,但至少在对待风险的态度上,OpenAI的沉默显得格外刺眼。

OpenAI的变化其实不难理解,毕竟它现在正朝着万亿美元估值和IPO的目标迈进,还有微软等投资方的利益在背后支持。在巨大的商业利益面前,“诚实”变得确实有些奢侈。然而,企业想要长久发展,光靠榜单和营销是远远不够的,用户体验和社会责任才是根本。
关于GPT-5.2的“作弊”争议,这与其说是个别事件,不如说是AI行业商业化过程中一次“成长的阵痛”。token刷分、榜单优化、商业与学术的失衡,这些问题其实都在提醒我们:AI的价值从来不是靠分数来衡量的,而是看它能否真正解决用户面临的实际问题。


小圆觉得,行业竞争最终还是要回归理性,与其在榜单上打擦边球,不如把资源投入到减少“幻觉”、提升效率、降低用户关注的成本等真正重要的方向上。
对于用户来说,不必过于依赖某个榜单的排名,最终能否满意还是要看实际使用感受。AI技术发展固然需要速度,但更重要的还是温度和诚意。只有在技术进步、商业利益和社会责任之间找到平衡,才能走得更稳更远。毕竟,那些真正强大的AI,从不需要“刷分”来证明自己的能力。









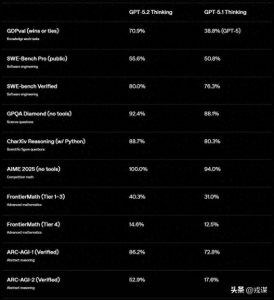

GPT-5.2的测试结果让人怀疑其真实能力,尤其是token消耗这么高,是否真的代表实力呢?用户的真实体验才是关键。
GPT-5.2的表现真是让人难以捉摸,虽然测试分数看似优秀,但高token消耗让人怀疑它的实际能力。希望未来能有更公平的评测标准。
GPT-5.2的高分真相令人深思,过高的token消耗让人对它的实力产生疑虑。希望能看到更公正的评测标准,用户体验才是最重要的。
GPT-5.2的发布真是让人感到困惑,虽然数据上有优势,但实际使用效果却让人失望,特别是在代码检查上频频出错。希望能重视用户体验而非单纯追求高分。
GPT-5.2的高分似乎并不代表真实实力,过多的token消耗让人对它的效率产生质疑。用户体验才是最重要的,希望未来能有更合理的评测。
GPT-5.2虽然在数据上取得了高分,但实际使用中的问题让人失望,很多用户反映它的表现不如预期,甚至不如以前的版本。希望OpenAI能够关注用户反馈,提升产品体验。
GPT-5.2的表现让我感到失望,尽管数据上看起来不错,但实际使用时却频频出错,真希望能改善用户体验。
GPT-5.2的高分背后隐藏着不少问题,过多的token消耗让人怀疑它的真实实力。希望未来的AI评测能更加公正,用户体验也能得到重视。
对GPT-5.2的高分感到困惑,虽然数据漂亮,但实际应用时频频出错,让我很失望。希望能回归用户体验的本质。
虽然GPT-5.2的得分看似很高,但实际使用中却频繁出错,用户体验真的很差。希望能更关注使用效果而不是测试数据。
GPT-5.2在测试中表现不错,但高token消耗让人怀疑它的真实实力,感觉这不是公平竞争。期待更透明的评测标准。
看到GPT-5.2和Gemini 3的对比,真让人思考AI评测的公正性,希望各大厂商能重视用户体验而不是单纯追求数字上的胜利。