文 |有风
编辑 |有风
就在凌晨,OpenAI悄悄发布了GPT-5.2。
这个时机挺有意思的,正好卡在Google的Gemini 3和Anthropic的Claude Opus 4.5发布的间隙。
业内的人都知道,前几个月GPT-5和5.1因为感觉聊天体验太“冰冷”而受到不少批评,这次5.2的快速推出,大家都看得出是竞争对手的压力所致。
听说Sam Altman上周给内部发了一封紧急邮件,要求大家全力以赴改进ChatGPT。

这种紧急的反应,上一次还是在三年前GPT-4发布的前夕。
看来Google和Anthropic的压力确实不小,直接让OpenAI调整了发布节奏。
从“聊天专家”到“工作助手”,GPT-5.2的战略调整
这次GPT-5.2最显著的变化,就是OpenAI不再强调“更好聊天”了。
发布会整个过程中,他们不断强调“专业知识工作”的能力,官网主页甚至把“能帮助你完成实际工作”放在了最显眼的位置。

这种转变让人颇感意外,毕竟之前GPT-5.1还在大力推广“情感交互升级”。
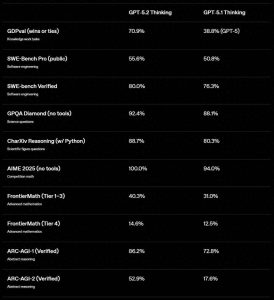
他们甚至制定了一个新的测试标准,叫GDPval,涵盖了44种职业的真实工作任务。
测试结果显示,GPT-5.2在70.9%的任务中与行业专家持平或超越,而GPT-5的这个数字仅为38.8%。
这个提升幅度确实让人惊讶,不过目前还没看到第三方的独立验证数据。
编程能力的提升也明显,SWE-benchPro测试达到了55.6%,而Verified版本更是飙升至80%。
专业能力赶上人类专家?让我们深入聊聊这些数据

有些前端开发的小伙伴试过后表示,处理复杂的3D场景时,代码生成的准确度提升了不少,之前需要花很多时间修复的bug,现在基本上一次就搞定了。
不过,API的费用也随之上涨,输入和输出的单价都提高了大约40%。官方的解释是效率提升了,但总花费可能反而会降低,听起来确实有点复杂。

这次升级中,数学能力的提升让人眼前一亮,FrontierMath的测试结果达到了40.3%,AIME2025卷更是拿到了满分。你想啊,这种考试连奥数的高手都未必能全对。
在GPQADiamond的博士级科学问答中,Thinking版得分92.4%,Pro版则有93.2%的成绩。
一些数学研究者反映,5.2Pro版的解题思路已经能够提供”非平凡的见解”,不再是那些教条式的答案了。
错误率下降了30%这一点,确实让人感到更可靠,日常写报告和研究的时候,使用AI提供的信息也不用再反复检查了。
对于长文处理的能力,已经达到了256k token的级别,Box公司表示,他们在使用过程中,信息提取的速度和推理的准确率都提升了40%。

图像处理的能力也有了明显增强,图表理解的错误率降低了一半,甚至低分辨率的主板上元器件都能准确识别,这对硬件工程师来说真是个好消息。
不过,社区里的反馈呈现出两极分化,很多专业用户都表示满意,尤其是在处理长上下文和复杂推理方面的提升,确实能够提升工作效率。
但是,喜欢用AI进行聊天和角色扮演的用户则不太满意,反映出“人情味”比5.1版本还要淡,成人模式也遥遥无期。
这种现象其实很正常,毕竟OpenAI这一次显然是把重点放在了专业市场上。
AI新阶段的到来:GPT-5.2的影响与展望
你听说了吗?GPT-5.2一发布,就让人觉得AI的竞争进入了一个全新的时代。
以前大家比的都是参数和速度,现在可不一样了,大家开始关注的是实际能做的事情。
OpenAI的目标非常明确:他们想成为知识工作者的“初级助手”,而不仅仅是个聊天工具。
这一转变将对行业产生深远的影响,尤其是那些需要专业知识的职业。
当然,AI再怎么强大,还是有它的局限性。
现在的5.2版本能应对很多专业任务,但有些需要创意和战略思考的工作,短期内还是没法完全取代人类。
而且,价格上涨了40%,这也表明,优质的AI服务是不会一直免费的。
未来可能会出现一种“基础功能免费,专业能力收费”的模式,这对普通用户和企业来说都是个新挑战。
总的来说,GPT-5.2就像是OpenAI为行业树立的新标杆,AI的好坏不再看参数,而是看它能否帮助人们解决实际问题。
这种务实的态度值得点赞,但如何平衡专业能力与用户体验,以及应对技术进步带来的就业挑战,这些问题还需要整个行业共同探索。
毕竟,真正能“干活”的AI才是我们所需要的,而不是仅仅会聊天的玩具。