编辑:编辑部
【新智元导读】今天是OpenAI的十周年,那个我们都知道的超级AI又回来了!新发布的GPT-5.2「全家桶」把谷歌的Gemini 3 Pro给完全压制了,专业水平甚至可以和人类专家媲美。
就在刚刚,OpenAI可谓一鸣惊人!
GPT-5.2震撼登场,全球AI的王者宝座又换人了。

今天一共上线了三款新模型:
· GPT‑5.2 Instant(即时版)
· GPT‑5.2 Thinking(思考版)
· GPT‑5.2 Pro(专业版)
作为目前最强的通用模型,GPT-5.2的设计初衷就是为了应对那些让人抓狂的「高难度知识型工作」。
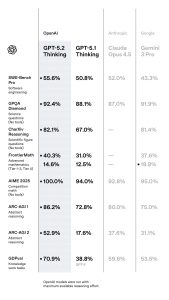
在OpenAI发布的测试结果中,它几乎全方位地击败了Gemini 3 Pro!
GPT-5.2:智能进化的全新标杆
相比于它的前身,GPT-5.2在多个方面都实现了飞跃,比如通用智能、理解复杂文本、调用各种工具的能力以及视觉处理等,真的是无所不包、无死角的全面提升。
- SWE-Bench Pro:直接削减了55.6%的高分记录;
- LMArena代码竞技场:只落后于Claude Opus 4.5,稳稳坐上全球第二;
- ARC-AGI-2:以52.9%的绝对优势,GPT-5.2 Pro荣登世界第一宝座;
- GDPval:覆盖了44种职业知识,表现超过了许多人类专家。
简单来说,GPT-5.2能够从头到尾轻松搞定各种复杂的现实问题,目前没有其它模型能比它更强了。
GPT-5.2评测:强大又昂贵的全新体验
说到新版本的GPT-5.2,除了实力更强,它的上下文处理能力和知识更新也让人眼前一亮!
- 40万字的上下文窗口:轻松处理超长的文本和复杂对话,真是得心应手;
- 最大输出长度达到12.8万字:生成深度长文时再也不怕中途被打断;
- 知识库更新到2025年8月31日:随时掌握全球最新动态,真是个博学的家伙;
- 推理Token支持:特别擅长复杂逻辑和多步推理,厉害了!
当然,性能提升的同时,价格也随之上涨。
跟之前的GPT-5和5.1比,GPT-5.2的输入输出费用整整贵了40%!
更强的推理、更快的响应,加上更高的费用,似乎在暗示着什么——
OpenAI不仅在模型上进行了巨大的升级,背后的计算成本也在不断攀升。


这次真是专业到家了!
一个月之前,GPT-5.1以它那超高的情商和智商首次亮相,结果就遇到了谷歌的Gemini 3,真是个强劲的竞争对手。
而这次的更新正值媒体报道OpenAI内部进入了“红色代码”紧急状态。
不过OpenAI的高层表示,别把GPT-5.2当成是对Gemini 3的反击。OpenAI应用的CEO在接受采访时说:
我们宣布进入“红色代码”状态,是为了给内部传达一个信号,我们想集中精力做重要的事情,这其实是个很好的明确优先级的方法。
总体来看,我们在开发ChatGPT时投入的资源增加了,我觉得这确实有助于模型的推出,但这并不是它在这一周里发布的唯一原因。
这一回,GPT-5.2主打的是专业知识型AI,简直可以说是“打工人的最佳工作助手”。
OpenAI的华人研究员Yu Bai也说:“看似只是个小版本更新,但其实能力的提升是相当大的。”
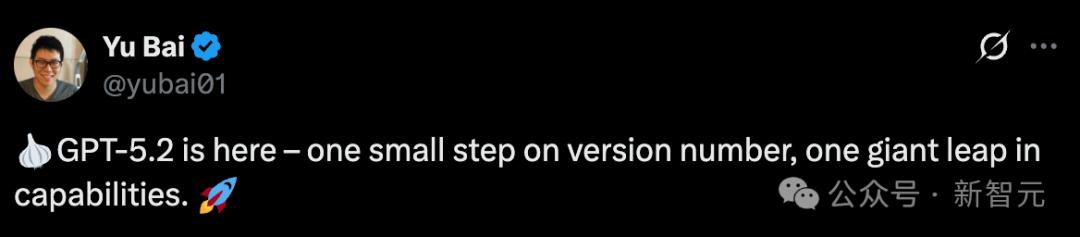
那些人类专家花费4到8小时完成的任务,在评估中,GPT-5.2的胜率达到了70.9%。
GPT-5.2果然没有让人失望,实际操作中它的表现都更加卓越——
无论是制作电子表格、演示文稿,还是编程、图像识别、理解复杂上下文、使用工具、处理多步骤的项目,它都能游刃有余。

根据OpenAI的一份报告显示,ChatGPT每天能为企业用户节省大约40到60分钟的时间。而那些重度使用者每周甚至能省下超过10个小时,真的是挺惊人的吧!
想了解更多?OpenAI最新的报告揭示,前5%的精英效率提升了整整16倍,然而普通人却可能在不知不觉中被淘汰了。
所以说,AI在“专业领域”中大显身手,才是最靠谱的!

人类专家被击败,打工人们欢呼雀跃
现在,GPT‑5.2 Thinking已经成为现实专业工作的顶尖模型了。
在GDPval测试中,GPT‑5.2 Thinking创造了新的记录,它是历史上第一个超越人类专家水平的模型。

根据专家的评估,GPT‑5.2 Thinking在GDPval的知识工作任务中,有70.9%的情况下表现超过或者平分了顶尖行业专家的成绩。
而在完成这些任务时,它的速度竟然比专家快了11倍,成本也低于1%!
这说明,结合人类的监督,GPT‑5.2能够有效地辅佐完成专业工作。

简单来说,不管是帮会计处理财报,还是为产品经理准备PPT,甚至充当程序员的编程小助手,GPT-5.2都游刃有余。

在GDPval的任务中,这个模型需要涵盖美国经济中贡献最高的9个行业,完成44种职业的具体工作。比如,制作销售演示文稿、会计表格、紧急护理排班表、制造图表,甚至短视频。
在ChatGPT的版本中,GPT‑5.2 Thinking引入了GPT‑5 Thinking所不具备的新功能。
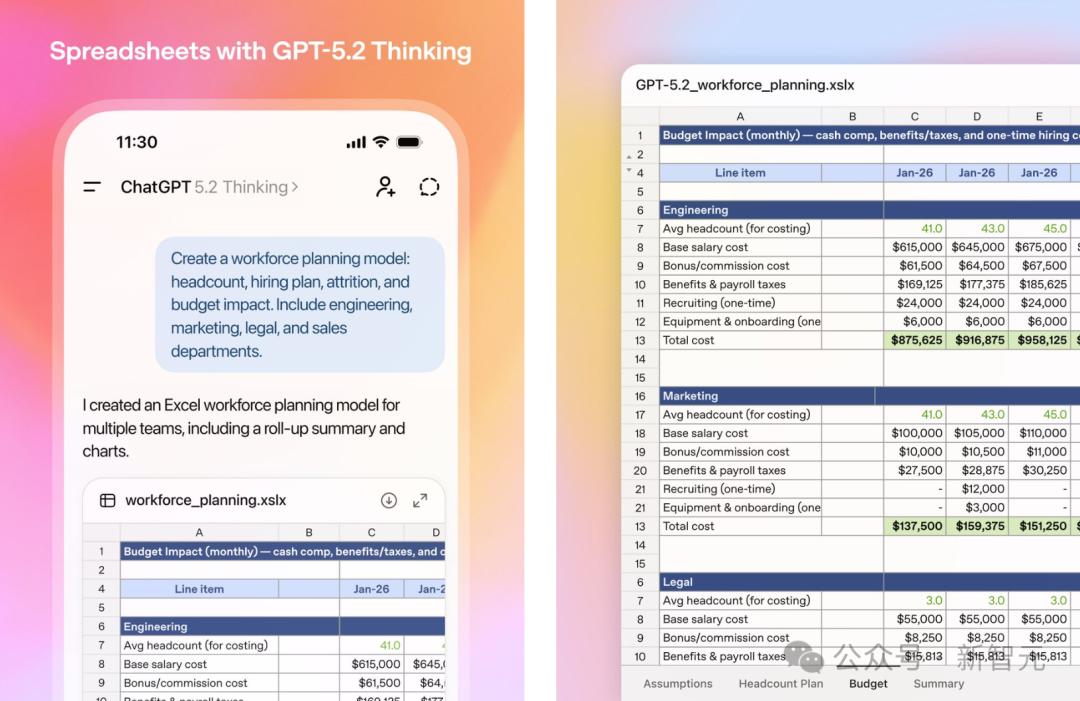
而且,在针对初级投资银行分析师的电子表格建模的内部测试中,GPT-5.2 Thinking的平均得分比GPT‑5.1高出了9.3%,从59.1%提升到68.4%。
对比显示,GPT‑5.2 Thinking生成的电子表格和PPT在复杂性和格式上都有显著提升。
比如,这种高难度的复杂表格,GPT‑5.2 Thinking只需一句话就能生成,简直就是个「人力资源规划的小能手」。

在股权结构表的制作中,GPT-5.2 Thinking像个资深银行分析师一样,完成了所有必要的计算,并且整个过程清晰明了。
反观GPT-5.1 Thinking,不仅在种子轮、A轮和B轮的清算优先权计算上出错,很多行还留空,最后导致股权回报的计算结果也不对,甚至在表头插入了计算公式,真是让人哭笑不得。

说到项目管理,GPT-5.2 Thinking通过时间和任务的轴线,提供了一个直观又清晰的总结。
相比之下,GPT-5.1 Thinking就显得有些粗糙了。


编程领域的记录保持者
当然,在编程方面,GPT-5.2无疑是一个绝对的佼佼者!
在现实世界的软件工程基准SWE-Bench Pro上,GPT-5.2 Thinking创造了一个新的高纪录,达到55.6%。
与只测试Python的SWE-bench Verified相比,SWE-Bench Pro涵盖了四种编程语言,更能抵御数据污染,挑战性和多样性也更强,非常贴近工业应用。

探索GPT-5.2的强大能力,软件开发不再难!
在SWE-Bench Pro这个平台上,模型需要面对一个代码库的挑战,目标是生成一个补丁来修复真实的软件工程问题。
在SWE-bench Verified的测试中,GPT‑5.2 Thinking以80%的优秀成绩脱颖而出。
这表明,它在调试生产环境代码、实现功能请求和重构大型代码库方面更加可靠,甚至能较少依赖人力完成整个修复流程。
而在前端软件工程领域,GPT‑5.2 Thinking的表现也明显优于之前的版本GPT‑5.1 Thinking。
早期的用户发现,它就像全栈工程师的得力助手,尤其在前端开发以及处理复杂或非常规的UI任务(特别是与3D元素相关的工作)时表现得尤为出色。
接下来,我们来看看,仅凭一句提示,GPT‑5.2能创造出什么样的作品:
- 海浪模拟

提示:创建一个单页面应用,包含以下要求:
- 名称:海浪模拟
- 目标:展示逼真的动画波浪。
- 特性:可以调整风速、波高、光照。
- 界面要令人放松且真实。- 节日贺卡制作器
提示:创建一个单页面应用,在一个HTML文件中展示一个温暖有趣的节日贺卡!这个贺卡要互动且适合小朋友们!
- 界面上有多种小物件可以拖放,部分物件应默认放置
- 同时要有有趣的声音互动
- 尽量放置很多可爱有趣的东西
- 动画效果如雪花飘落应使用得当- 打字雨游戏
标题:让我们一起打字雨,挑战你的速度与准确性!
“`html
body {
background-image: url(‘city_background.jpg’);
background-size: cover;
font-family: ‘Arial’, sans-serif;
color: white;
}
#fallingWords {
position: absolute;
top: 0;
left: 50%;
transform: translateX(-50%);
pointer-events: none;
}
.word {
position: absolute;
white-space: nowrap;
animation: fall 5s linear infinite;
}
@keyframes fall {
to {
transform: translateY(100vh);
}
}
#scoreboard {
position: fixed;
top: 20px;
left: 20px;
background-color: rgba(0, 0, 0, 0.5);
padding: 10px;
border-radius: 5px;
}
得分: 0
准确率: 100%
let score = 0;
let correctCount = 0;
let totalCount = 0;
function createWord() {
const words = [‘你好’, ‘世界’, ‘打字’, ‘游戏’, ‘雨’, ‘挑战’];
const randomWord = words[Math.floor(Math.random() * words.length)];
const wordElement = document.createElement(‘div’);
wordElement.classList.add(‘word’);
wordElement.textContent = randomWord;
wordElement.style.left = Math.random() * 100 + ‘vw’;
document.getElementById(‘fallingWords’).appendChild(wordElement);
setTimeout(() => {
wordElement.remove();
}, 5000);
}
function updateScore(isCorrect) {
totalCount++;
if (isCorrect) {
score++;
correctCount++;
}
document.getElementById(‘score’).textContent = score;
document.getElementById(‘accuracy’).textContent = ((correctCount / totalCount) * 100).toFixed(2) + ‘%’;
}
document.addEventListener(‘keydown’, (event) => {
const currentWords = document.querySelectorAll(‘.word’);
currentWords.forEach(word => {
if (word.textContent === event.key) {
word.remove();
updateScore(true);
}
});
});
setInterval(createWord, 1000);
“`

说到处理复杂的任务,GPT‑5.2 Thinking真的是个大升级!这款新模型兼容OpenAI最新的Responses「/compact」端点,帮助我们更好地应对那些上下文较长的挑战。
这意味着,GPT‑5.2 Thinking能够处理更多需要长时间运行的工作流程和工具密集型的任务,以前可能会被上下文长度限制的,现在都能轻松搞定。

视觉理解的飞跃,复杂图表不再难
现在,GPT‑5.2 Thinking是OpenAI最强大的视觉模型,它在图表推理和软件界面理解方面的错误率几乎减半,真是太厉害了!
这意味着,对于日常的专业使用来说,这个模型能更准确地解读各种信息,比如仪表盘、产品截图和技术图表,特别适合金融、运营、工程、设计和客户支持等领域。

跟之前的模型比,GPT‑5.2 Thinking对图像中元素的定位能力提升明显,这对解决问题的布局任务来说至关重要。
在下面的例子中,模型被要求识别图像里的组件(比如主板),并给出带有大致边界框的标签。
即使面对质量不佳的图像,GPT‑5.2也能找到主要区域,并且能够大致放置与每个组件相符的框,而在GPT‑5.1中,这种标记的能力显得相对较弱,空间理解也不如现在的模型。


全面提升的工作流程,焕然一新
GPT‑5.2 Thinking在处理长时间的多轮任务时,展现出其用工具的可靠性,在Tau2-bench Telecom上创下98.7%的新高。
对于那些对延迟特别敏感的场合,GPT‑5.2 Thinking在reasoning.effort=’none’(无推理)的情况下表现得更为出色,远超GPT‑5.1和GPT‑4.1。

对于那些在专业领域工作的人来说,这意味着更为强大的端到端工作流——例如处理客户支持问题、从不同系统中提取信息、进行分析以及生成最终结果,同时各个环节的衔接更为流畅。
比如,当你需要解决复杂的客户服务问题时,GPT-5.2能够更高效地协调多个智能体,确保整个流程顺畅。
在下面的例子中,一位乘客反映了航班延误、错过转机、在纽约过夜的需求以及医疗座位的请求。
GPT‑5.2全程掌控这一任务链——重新预订、特殊协助座位以及赔偿方案,相比于GPT‑5.1,提供了更完整的解决方案。
AI助力科研,打破传统壁垒!

我的航班本来是从巴黎飞往纽约,但结果却延误了,导致我错过了前往奥斯汀的连接航班。更糟糕的是,我的行李也消失不见了,现在我得在纽约过夜。而且因为我有特殊的医疗需求,我需要一个前排座位。你能帮我解决这个问题吗?

独立完成证明,颠覆科研范式
OpenAI希望利用AI技术来推动科学研究的发展,造福每一个人。
为了实现这个目标,OpenAI不断与科学界的专家们进行交流,深入了解他们的需求,看看AI能如何提升他们的工作效率,现在已经有了一些初步的合作成果。

链接:https://cdn.openai.com/pdf/a3f3f76c-98bd-47a5-888f-c52c932a8942/colt-monotonicity-problem.pdf
而在当前的科研辅助工具中,GPT‑5.2 Pro和GPT‑5.2 Thinking被认为是最有力的助手。
在研究生水平的基准测试GPQA Diamond中,GPT‑5.2 Pro的得分达到了93.2%,而GPT‑5.2 Thinking也紧随其后,得分为92.4%。
在专家级的数学评估FrontierMath (Tier 1–3)中,GPT‑5.2 Thinking创造了新的纪录,解决了40.3%的问题。

如今,我们真的开始看到AI模型在推动数学和科学的进步上发挥了重要作用。
比如,最近在使用GPT‑5.2 Pro的研究中,科学家们探讨了统计学习理论中的一个未解之谜。
这个研究成果被记录在一篇新论文中,标题是《关于最大似然估计量的学习曲线单调性》(On Learning-Curve Monotonicity for Maximum Likelihood Estimators)。

论文链接在这里:https://cdn.openai.com/pdf/a3f3f76c-98bd-47a5-888f-c52c932a8942/colt-monotonicity-problem.pdf
这篇论文的最大亮点在于,AI负责了证明部分,而人类则专注于验证和撰写。
作者们并没有提前设计好策略再让模型来填补,而是直接让GPT-5.2 Pro解决这个开放问题,之后人类进行了严格的验证,包括邀请外部专家审查确认。
接着,作者还提了一些简单的后续问题,想看看这个思路能够延伸到多远。结果是,GPT-5.2 Pro不仅解决了原问题,还扩展到了更高维度的情况以及其他常见的统计模型。
在这个过程中,人类主要集中在验证和清晰撰写上,而不是数学推导的框架搭建。

推理AI展现出灵活的智能
在评估通用推理能力的ARC-AGI-1(Verified)基准测试中,GPT‑5.2 Pro成为首个突破90%门槛的模型。
与去年的o3‑preview相比,后者的得分为87%,而GPT‑5.2则在实现同样性能的同时,成本降低了近390倍。

在更高级的ARC-AGI-2(Verified)测试中,GPT‑5.2 Thinking拿下了思维链模型的新高,得分达到了52.9%。
而GPT‑5.2 Pro的表现则更为出色,达到了54.2%,进一步提升了模型在处理新颖和抽象问题上的能力。

这些分数的提升,显示出GPT‑5.2在处理复杂技术任务时,具备更强的多步骤推理能力、更加精准的定量分析和更可靠的问题解决技巧。
如此迅速的进步让评测方感到惊喜,纷纷表示推理AI展现出了真正的“流体智力”。

来自生物医学工程领域的Derya教授激动地表示,这真是AGI的体现!

此外,OpenAI不仅展示了一系列基准测试的结果,还提到了Box、Notion、Windsurf和Zoom等早期测试方的反馈。

GPT‑5.2全家桶,三大杀手级AI
总的来说,使用GPT‑5.2的体验非常棒——它的逻辑性更强,可靠性也提高了,和它聊天真是一种享受。
那么,这个「全家桶」里的三款模型,各自有什么特别之处呢?
GPT‑5.2 Instant:日常办公和学习的好帮手
它就像是个全能的办公助手,不仅继承了GPT-5.1温暖的对话风格,还在速度和实用性上进行了全面提升。
因此,Instant版可以说是日常工作和学习中的得力助手,具体来说:
- 解释更清晰,关键信息一目了然
- 操作指南和步骤更加完善
- 技术写作和翻译能力更强
- 提供更好的学习和职业建议

GPT‑5.2 Thinking:为深入工作量身定制
GPT‑5.2 Thinking简直就像是你的「第二大脑」,专门用来处理那些需要深思熟虑的复杂任务。
尤其在编程、总结长篇文档、解答上传文件的疑问,以及解决烧脑的数学和逻辑题上,都能得心应手。
同时,它还能提供更清晰的结构和实用的细节,帮助你在规划和决策上做得更好。
- 业界领先的长上下文推理能力
- 在表格的创建、分析和格式化上有明显提升
- PPT制作方面也取得了初步成果
GPT-5.2 Pro
如果你碰上那些特别棘手的问题,GPT-5.2 Pro绝对是个聪明又靠谱的选择。
说白了,它就像是那种精雕细琢的专家,慢工出细活。
早期的测试结果显示,它在处理复杂任务时,尤其是编程方面,几乎没有什么错误,能力确实提升了不少。
- 在编程等复杂领域表现得尤为出色
- 是帮助科研人员加快研究进展的最佳工具

性价比提升
从今天开始,付费的ChatGPT用户能优先体验GPT-5.2(包括Instant、Thinking和Pro),无论你是Plus、Pro、Go、Business还是Enterprise套餐。
为了保持ChatGPT的流畅性和可靠性,OpenAI决定逐步推出GPT-5.2。
在ChatGPT中,GPT-5.1会继续以旧版模型的形式提供给付费用户使用三个月,之后就会下线。

在API平台上,GPT-5.2系列新模型可以在Responses API和Chat Completions API中按示例图的方式使用。
开发者们现在能在GPT-5.2 Pro中调节推理参数,而且GPT-5.2 Pro和GPT-5.2 Thinking也支持新的第五种推理强度xhigh,适合那些质量要求最高的任务。
GPT-5.2的定价为每百万输入Token 1.75美元,输出Token为每百万14美元,缓存输入则有90%的折扣。
虽然GPT-5.2的每Token费用更高,但由于它的Token效率更高,实际上性价比反而更高。

还有一件事
今天,OpenAI带着大家一起回顾了过去十年的精彩旅程。


十年前的今天,也就是2015年12月11日,OpenAI正式成立了。

在这十年里,他们取得了许多令人瞩目的成就——
2016年,推出了开源强化学习平台OpenAI Gym,这可是学术界和工业界进行强化学习研究的基础工具哦;
2017年,发表了关于Transformer核心理念的开创性研究,名为《Learning to Remember Rare Events》;
2018年,预训练语言模型GPT问世,这标志着大模型时代的开启;
2019年,1.5B参数的GPT-2横空出世,自然语言处理迎来了爆发;
2020年,175B参数的GPT-3引发了网络热潮,超大规模模型的时代正式来临;
2021年,Codex和DALL·E相继发布,开启了代码和图像生成的新篇章;
2022年,ChatGPT(GPT-3.5)真正点燃了全球的大模型革命,之后的重要事件大家都耳熟能详了。
奥特曼表示:“过去的十年真是精彩绝伦,OpenAI的成就超出了我的想象!”
圣诞惊喜即将来临,你猜猜是什么呢?

他透露说,下周将会有一个圣诞“惊喜”上线。你们觉得这会是什么呢?