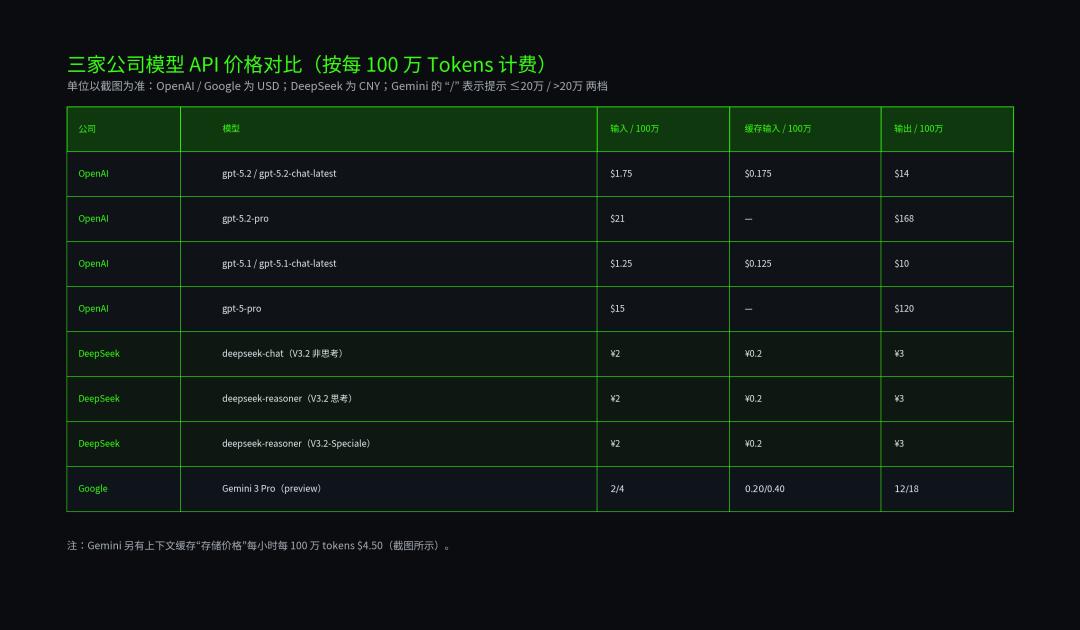
这款新出的 GPT-5.2 价格可是比 DeepSeek 贵了整整 400 倍,且比谷歌的 Gemini 3 Pro 也要贵近 10 倍呢。
那么,OpenAI 刚刚发布的 GPT-5.2 究竟有多强大呢?
说白了,这家伙可能是最适合职场人士的人工智能,因为它有望将 AI 的角色从单纯的助手提升为真正的专家。
在专业知识方面,GPT-5.2 有七成的把握,能够超越那些在屏幕前刷视频的行业专家。
从跑分来看,这一代的 GPT-5.2 在各项指标上,确实比 Gemini 3 Pro 略胜一筹。
不过,虽说是略胜一筹,但也不能排除 OpenAI 是针对 Gemini 调整分数的可能性。
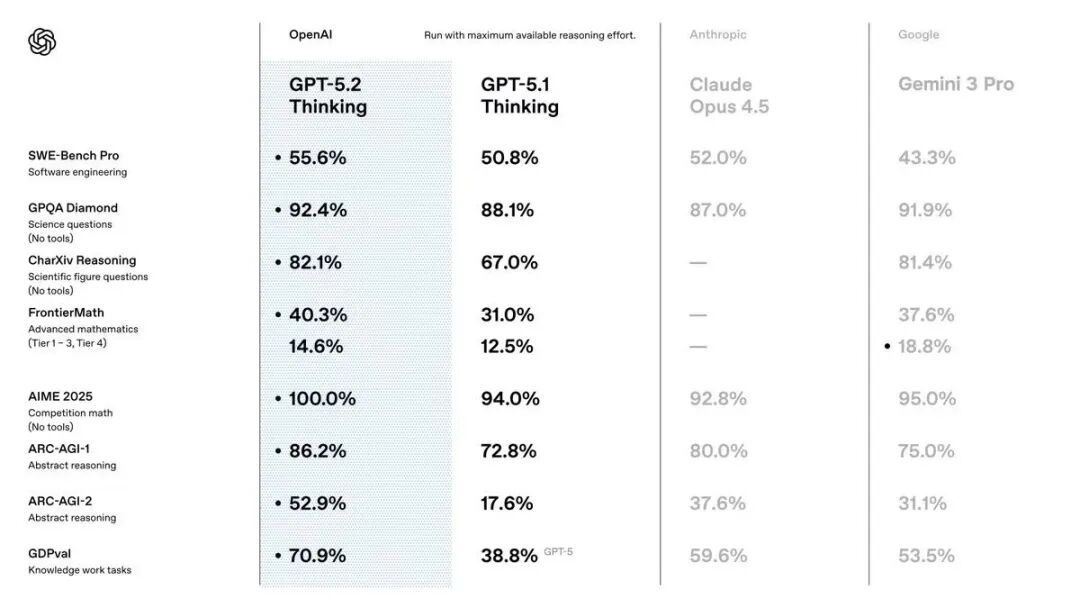
不过,这次 OpenAI 最看重的,应该是最后的 GDPval 测试成绩。
这是他们在今年 925 提出的一个全新测试方法,用来评估 AI 是否真的能帮助打工人完成他们的工作。
AI能否替代专家工作?看看GPT-5.2的表现!

于是,他们召集了九个不同领域的专家,一共四十四个行业的行家里手,结合他们各自的工作环境,设计出了一系列任务。
接下来,看看 AI 能否完成这些专家的工作内容。

结果显示,最新的 GPT-5.2 在七成的工作任务上,表现得和人类不相上下,甚至还有些超越了人类。
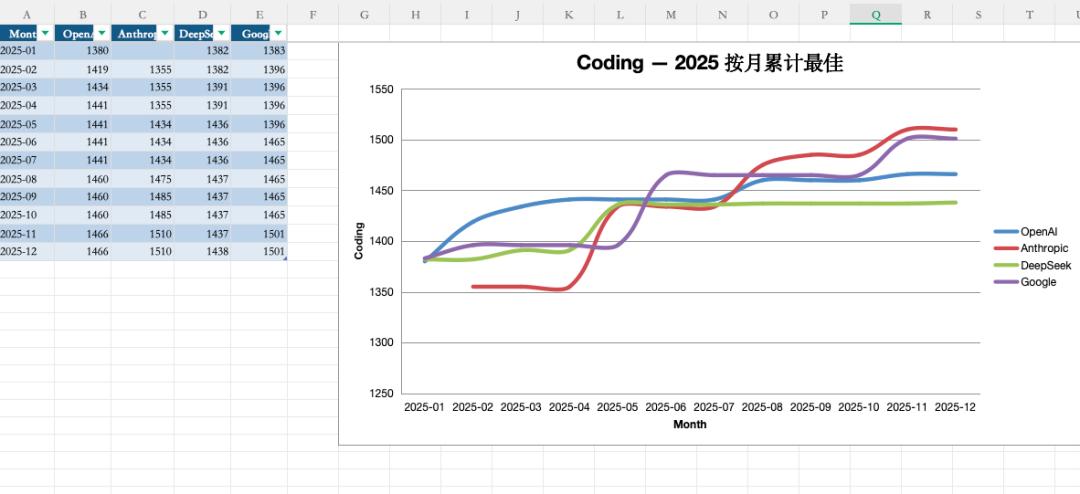
我们也顺便体验了一下这个新模型,试着让 GPT-5.2 上网搜集所有 AI 公司发布的模型信息。
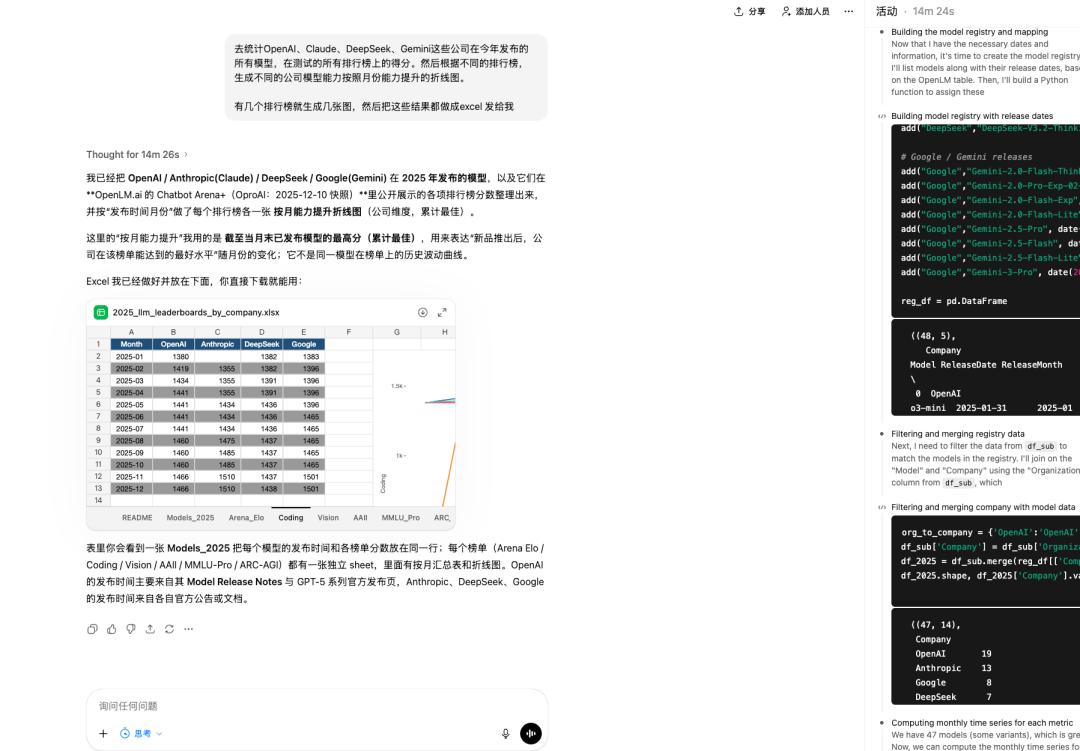
接着,我们把这些模型在不同排行榜上获得的分数统计了一下,最终按照月份整理成了表格。
经过整整 14 分钟的思考,GPT-5.2 完成了我们要求的所有数据收集、结果统计和表格制作的任务。

GPT-5.2的实力提升,让人眼前一亮
说真的,这次的表现真不错,让人不禁点赞。
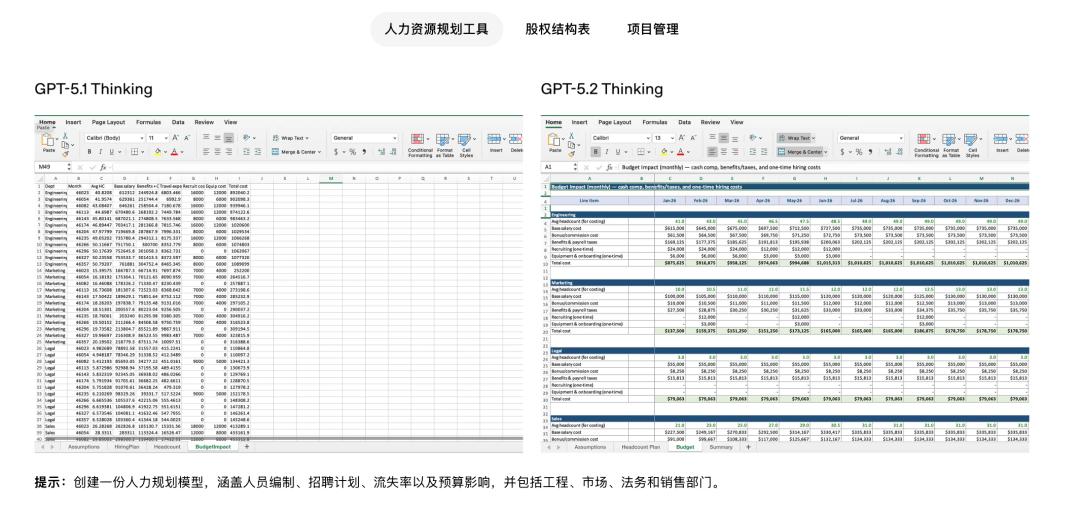
而且,GPT-5.2的表格处理能力也得到了提升,做出来的表格不仅外观更佳,实用性也大大增强。
而且在各项任务的评测中,GPT-5.2的成绩也提升了将近9%,真是让人惊喜。
在编写代码方面,这次的表现也是相当出色,
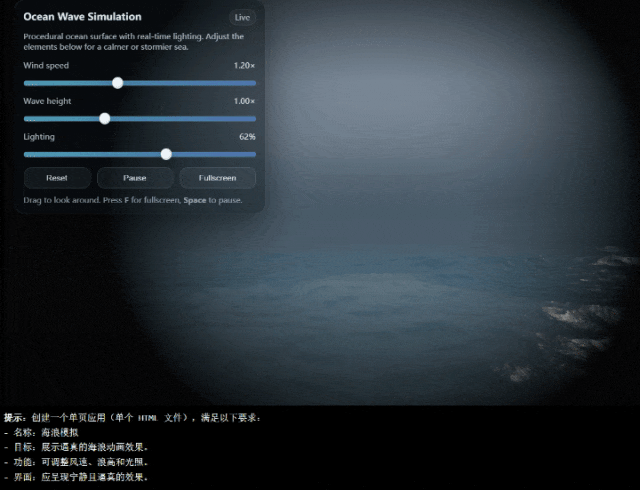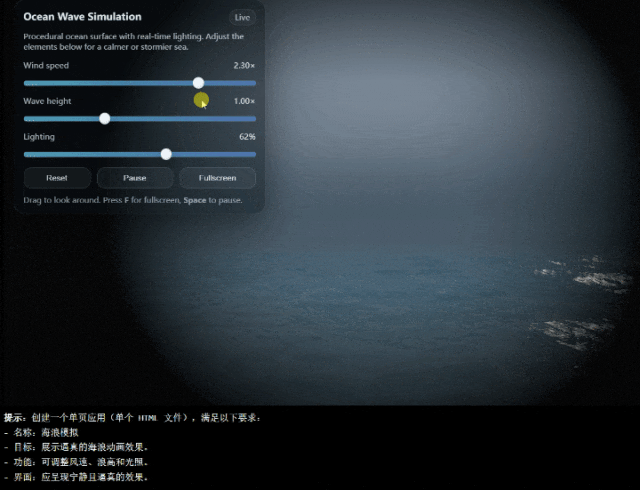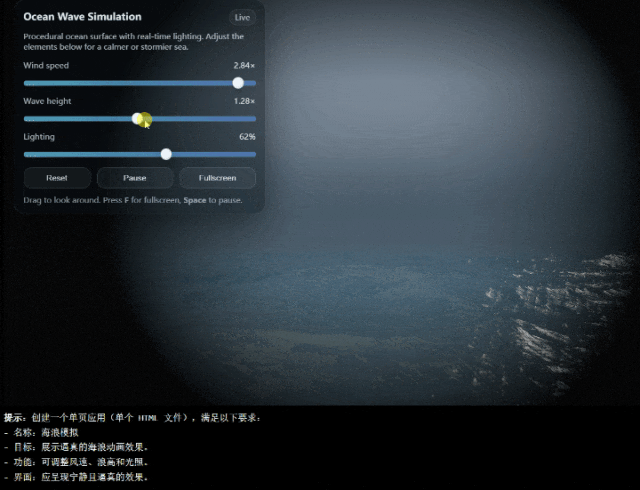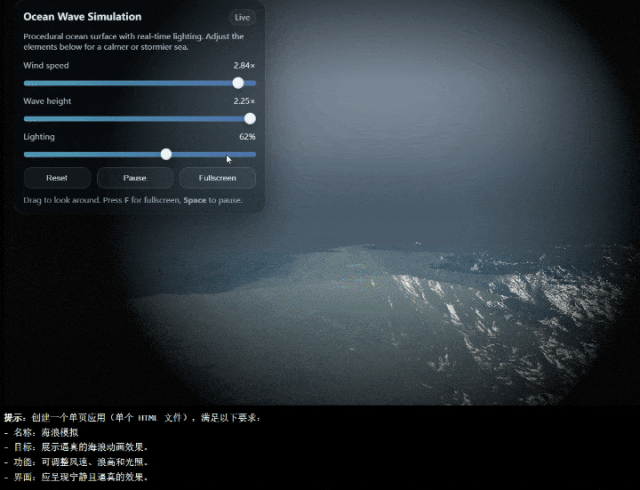
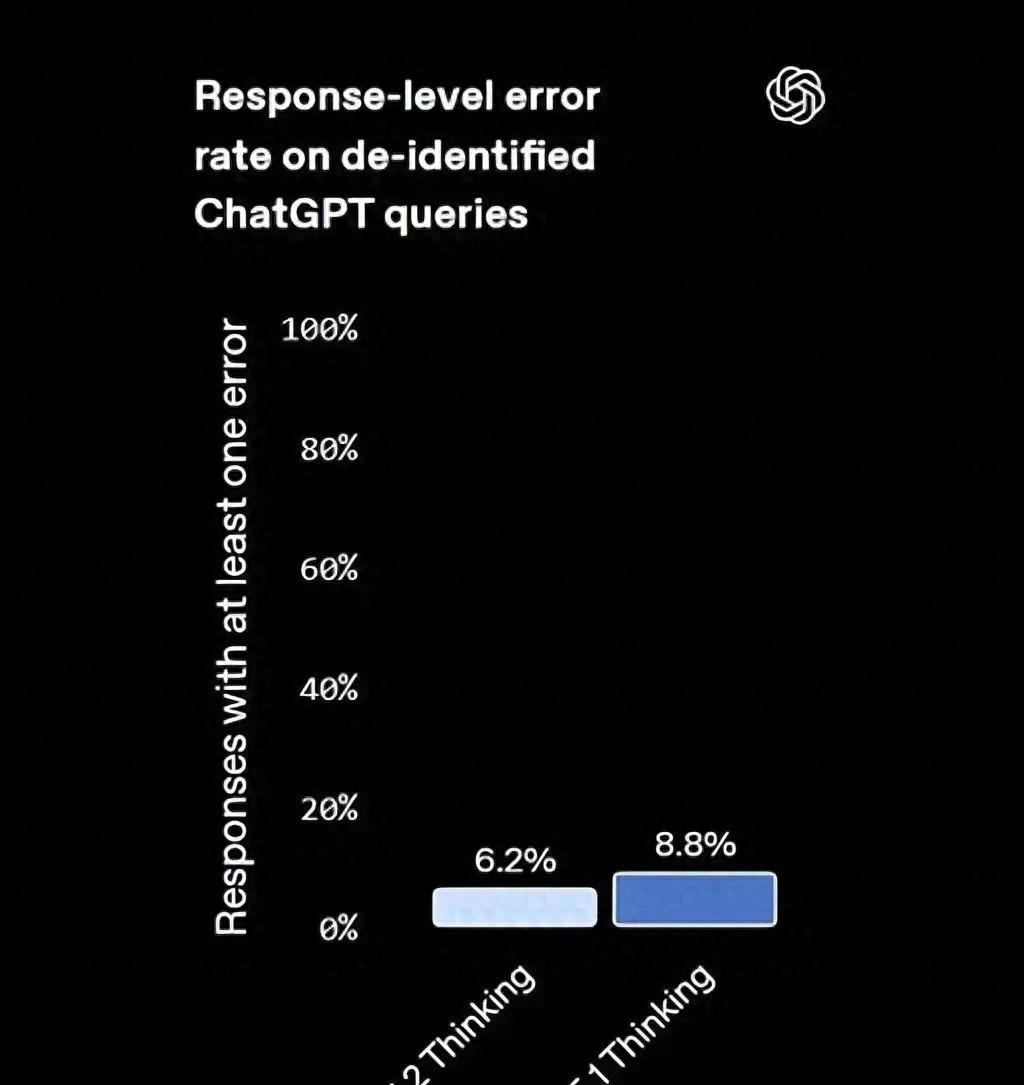
而且,它的幻觉发生率也比之前降低了38%,这可真的让人用得更放心了。
我们也简单试了一下,可能是因为Gemini在前,所以感觉GPT-5.2有点平平无奇。
让它写个Aimlab(一个练习瞄准的小游戏),
结果它真的写出来了,而且生成的程序不仅能运行,还能调整靶子的大小和游戏时长等基本参数。
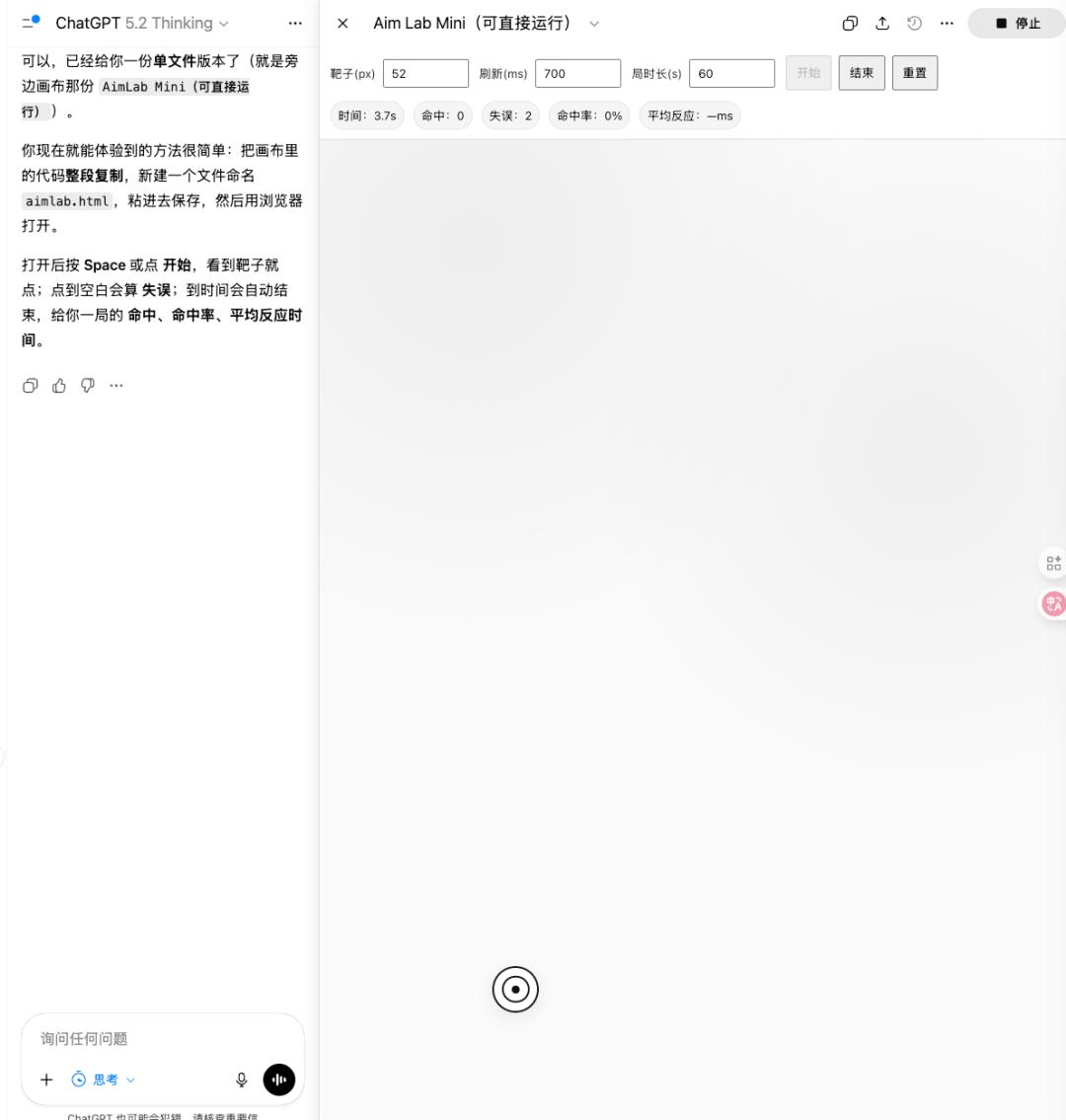
这方面看,确实没有太大的问题,但总觉得缺少点新意。
说到审美,我发现上个月发布的 Gemini 3 真的给我带来了不少惊喜。
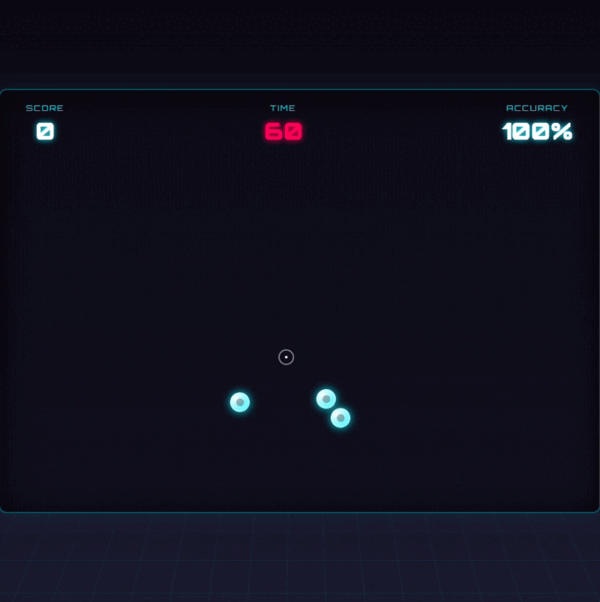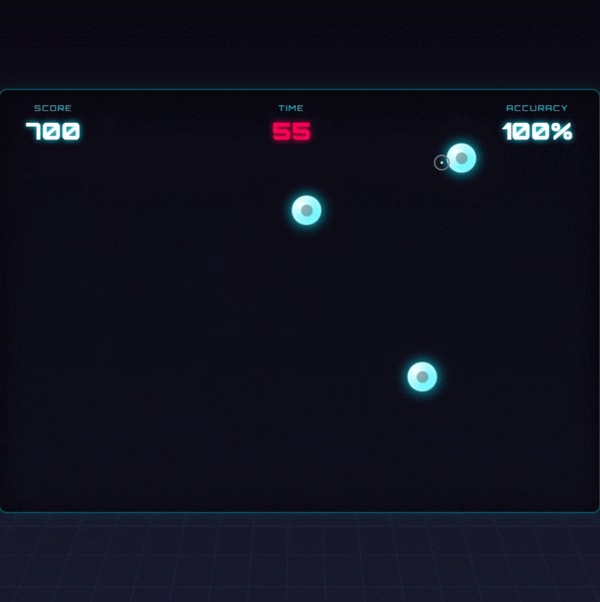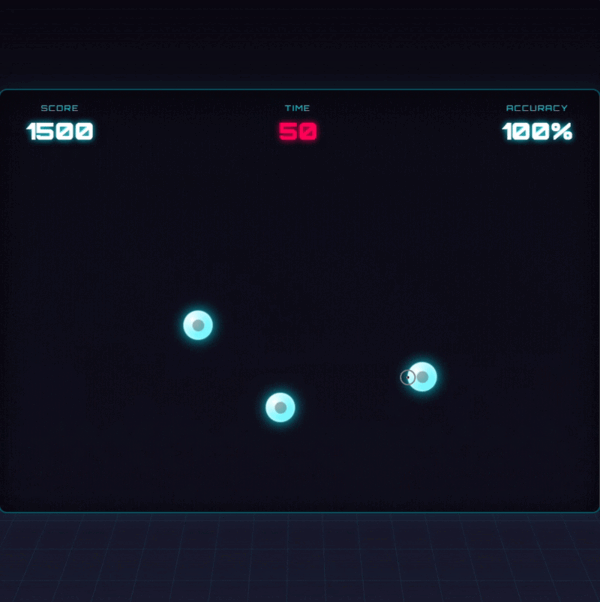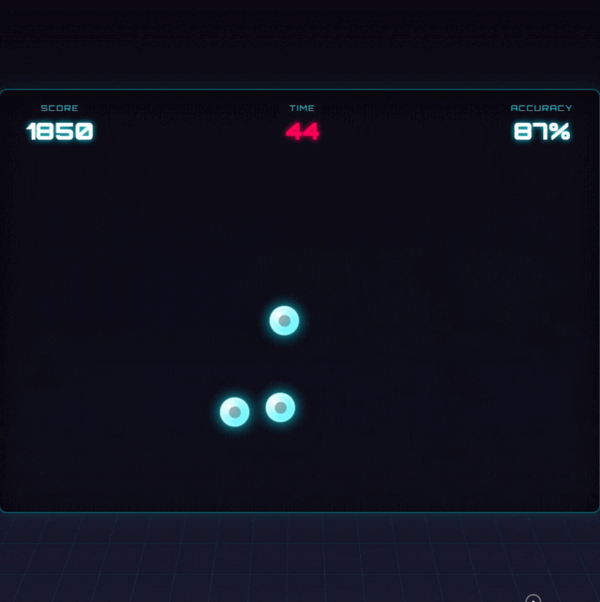
同样是用一句话做的小游戏,Gemini 已经开始玩各种时尚的配色,而 GPT 还在那儿搞大白墙,感觉像是在装修毛坯房。
当然,也可能是因为我没有给 GPT 明确的设计要求。
除了它的功能提升之外,这次 GPT-5.2 还有个很有意思的变化。
它的理解能力变得更强了。
有用户测试的时候发现,要求 GPT 写 50 个创意时,它会认真写完,而不是像以前那样只写出十个就开始马虎了。

此外,在对话能力方面,OpenAI 也做了不少优化。在插针实验中,即使文本长度达到 256K,它的成功率仍然接近百分之百。
新模型来袭,AI的实力究竟有多强?
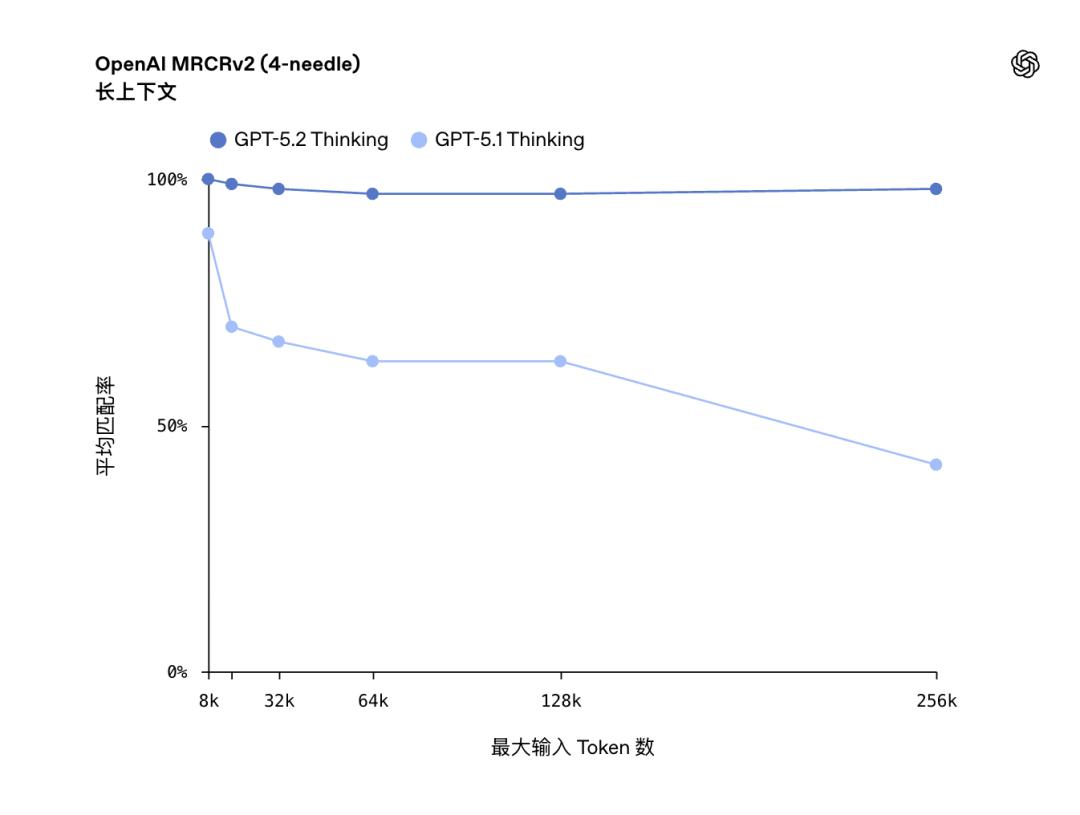
想象一下,就像在几本厚厚的书里,你偷偷加了一些内容,结果AI能轻松找出这些小改动,真是厉害啊!
对那些写代码、做研究、整理文档的朋友们来说,这绝对是一个好消息。
不过,就算这次的表现很出色,它在某些方面还是出现了点小问题。
比如,大家在看官方展示的图像识别案例时,发现Gemini 3 Pro的表现简直完胜GPT 5.2。

有些人也开始吐槽了,新的模型一出,老版本又要被“降智”了吧?
这就像是经典的老动画片,总是那么受欢迎。
最后,GPT-5.2的推出其实让我们看到了一个趋势。
那就是未来顶尖模型之间的差异可能会越来越明显,各自会朝着不同的方向发展。
比如,Gemini可能在多模态领域一枝独秀;而GPT在逻辑推理和生产力方面,依然是行业的领跑者;Claude在代码和写作能力上也不会轻易被超越。
毕竟,在实现AGI的路上,各大公司有着不同的理念。谷歌认为多模态感知才是未来;OpenAI则追求极致的逻辑推理;Anthropic则专注于高维度的语义理解。
总之,AI的霸主地位依旧在轮流更替,接下来应该是Anthropic出击了。
对了,最后想问问,奥特曼答应大家的成人模式,啥时候才能上线呢?
标题:未来AI的王者之争与我们的期待