未来计算的新视角:AMD智能体主机的崭新定义</p>
<p>2026年3月,在北京举行的一场技术沙龙上,AMD给我们这些科技媒体的小伙伴们展示了一项非常有趣的技术。在一台搭载锐龙AI Max+ 395处理器的设备上,基于Qwen 3.5 122B模型的智能体同时处理六个任务。更酷的是,这一切都是在本地完成的,而非依靠云端API。</p>
<p><img decoding="async" src="https://www.2090ai.com/wp-content/uploads/2026/04/image-0V4PdO.webp" loading="lazy" alt="AMD的新赌注:智能体主机开启计算新篇章!"></p>
<p>操作这台设备的用户并不在现场,他们偶尔通过远程进行操作和查看,甚至连鼠标和键盘都不需要碰。AMD想传达的信息是:智能体主机(Agent Computer)并不是对AI PC的简单升级,而是一个全新的计算类型。</p><div class="por-maybe-interested"><div class="por-maybe-interested__text">你可能感兴趣:<a href="https://www.2090ai.com/qwenpaw/26627.html">大厂们竟然都在“养虾”?腾讯、阿里、字节齐聚,OpenClaw企业级生态如何重塑与落地!</a></div></div>
<p><img decoding="async" src="https://www.2090ai.com/wp-content/uploads/2026/04/image-Di4scC.webp" loading="lazy" alt="AMD的新赌注:智能体主机开启计算新篇章!"></p>
<p>AMD正在重新定义个人计算在AI时代的新方式。近年来,“AI PC”在科技圈引起了很多关注,芯片制造商和OEM都在争相展示他们本地AI的推理能力。不过,经过几年的发展,AI PC使用的仍然是传统的交互方式:我们通过键盘、鼠标和触控来操控设备。</p>
<p>而“智能体主机”与AI PC的最大区别在于“谁在使用设备”。</p>
<p>传统PC是我们主要负责操作,AI充当辅助角色;而智能体主机则将这个逻辑翻转过来,我们可以放心地让AI智能体走到前面来,自己只需下达需求并验收结果。虽然这个差异看似微小,但其实计算设备的定位已经发生了根本性的变化。</p>
<p><img decoding="async" src="https://www.2090ai.com/wp-content/uploads/2026/04/image-GeIFRd.webp" loading="lazy" alt="AMD的新赌注:智能体主机开启计算新篇章!"></p>
<p>从技术架构的角度来看,这种定位的差异直接影响了硬件设计的基本逻辑。传统PC的设计主要围绕“人机交互”展开,响应速度、显示效果和输入体验是关键指标。智能体主机的设计则是围绕“机机协同”,算力规模、内存带宽、容量、并发能力以及持续运行的稳定性成为重点。</p>
<p>AMD锐龙AI Max+ 395处理器的配置很好的体现了这种优先级的变化:它配备了16核32线程的CPU、128GB四通道LPDDR5x-8000MT/s的统一内存、96GB可分配给GPU的显存,并且支持多个智能体同时运行。这些配置在传统PC中可能显得“性能过剩”,但在智能体主机的背景下,这些都变成了必需品。</p>
<p><strong>为什么AMD提供了强大的硬件基础</strong></p>
<p>智能体主机的概念确实很吸引人,但要实现却不容易。这需要几个条件:充足的算力、合理的架构设计和成熟的软件生态。AMD正好在这个时候推出了锐龙AI Max系列处理器。</p>
<p>从架构上看,锐龙AI Max系列采用了三合一的设计:CPU(Zen 5架构)、GPU(RDNA 3.5架构)和NPU(XDNA 2架构),这是专门针对AI负载进行了优化的。旗舰型号锐龙AI Max+ 395使用了创新的Zen 5架构和先进的4nm工艺,16核32线程的CPU处理一般计算任务,80MB的高速缓存(L2+L3)确保多任务处理的高效性。CINEBENCH R23的多核分数超过35000分,这在消费级处理器中绝对是顶尖水平。</p>
<p>RDNA 3.5架构的Radeon 8060S集成显卡拥有40组CU核心,3DMark TIME SPY的分数超过11000,足够应对大多数图形处理任务。更重要的是,它在没有独立显卡的情况下,依然能提供强大的AI推理能力。</p>
<p>XDNA 2架构的NPU则是专为AI推理设计的硬件单元,支持Windows 11的AI PC功能。在AI负载下,NPU的能效比比CPU、GPU都要高,这对于需要持续运行的智能体主机来说至关重要。</p>
<p>更重要的是统一内存架构。</p>
<p>AMD锐龙AI Max+ 395支持最高128GB四通道LPDDR5x-8000MT/s的统一内存,带宽达到256GB/s。通过统一内存架构,CPU、GPU和NPU可以共享同一内存,避免了不同存储单元之间拷贝数据的开销。</p>
<p>在这128GB的内存中,最高可以分配96GB作为GPU专属显存。这意味着什么?意味着像GPT-oss-120B这样的超大模型可以在不需要独立显卡的情况下在本地运行。</p>
<p>这个设计有效解决了本地大模型部署的核心痛点:显存容量和带宽的限制。</p>
<p>在实际测试中,搭载锐龙AI Max+ 395的设备运行Qwen 3.5 35B A3B模型时,生成速度可以达到每秒45个tokens。</p>
<p>更引人关注的是并发能力。这些平台支持最多6个智能体同时运行,每个智能体都拥有独立的工作上下文。这种多智能体的协同能力,正是“机机协同”模式的技术基础。</p>
<p><strong>统一内存的价值</strong></p>
<p>在AMD的官方资料中,统一内存架构被简要提及,但这个技术的重要性可能被低估了。</p>
<p>传统PC的内存设计存在一个根本矛盾:CPU需要大容量、低延迟的内存,而GPU则需要高带宽、大容量的显存。在独立显卡方案下,系统内存和显卡显存是分开的,数据需要在两者之间进行拷贝,这个过程的延迟和带宽消耗常常成为性能瓶颈。</p>
<p>统一内存架构恰好解决了这个问题。CPU、GPU和NPU共享同一块内存,每个计算单元可以根据需要动态分配内存资源。对于需要在不同计算单元之间频繁流动的数据,AI推理的负载来说,这种设计显著降低了延迟。</p>
<p>而且,统一内存的价值不仅如此,它为本地大模型的部署提供了可行的解决方案。</p>
<p>大模型的本地部署一直面临一个难题:消费级显卡的显存容量有限,而大模型往往需要巨大的显存。AMD通过将128GB系统内存中的96GB划拨为显存,就相当于为GPU提供了一块96GB的专用显存,这个容量足以运行120B参数级别的模型。在不依靠独立显卡的情况下,消费级设备也能在本地运行高质量的大模型。</p>
<p><strong>应用场景:从“工具”到“伙伴” </strong></p>
<p>技术的真正价值最终体现在实际的应用场景中,智能体主机的应用场景围绕“任务委托”展开:用户只需给智能体下达任务,智能体就能自主完成,用户只需在关键节点查看进度或做出决策。在现场展示的多个领域中,我们可以看到智能体主机带来的显著收益。</p>
<p class="bjh-image-container">晶耀智远公司在医疗领域基于锐龙AI Max+ 395开发了多智能体解决方案,6个智能体分别负责诊断、建档、预警和应急等场景,有效应对医疗专业模型的幻觉问题和数据管理问题,实习医生可以通过该系统获得主任医师级的专业辅助。</p>
<p>行者AI则在教育领域推出音乐和美术教育解决方案,以自研的多模态大模型为核心,提供AI绘画、智能评测、互动创作和词曲生成等一体化能力,构建了“教、学、创、评”全流程的智慧美育闭环。目前,这个方案已经覆盖了30多个省市和300多所院校。</p>
<p>Ryypol与AMD在校验领域深度合作,能够将静态论文转化为“可交互对话”的智能体,系统不仅能够解答文献问题,还能深度解析复杂原理,利用文生图将抽象概念可视化,助力科研工作。</p>
<p>在企业办公领域,元空AI开发的ChatExcel是一款基于自然语言指令的AI数据分析智能体,能够高效完成各类统计与分析、信息整理、数据汇总及图表生成等工作。所有数据都是离线处理,不会上传到任何第三方服务器。</p>
<p class="bjh-image-container">赛博物联自主研发的智能投标助手,依托大模型强大的语义理解、智能检索与内容生成能力,全面提高标书编制工作效率,降低废标风险,灵活运用企业知识资产。</p>
<p>腾达泰源创新打造的“OPC一机双用”架构,实现龙虾OS AI与Windows办公的无缝融合,系统将AI环境与办公环境物理隔离,既保障企业数据绝对安全,又能在需要时一键切换。</p>
<p>首届科技基于锐龙AI Max+ 395的玲珑星核Nova Studio平台,大幅简化了用户在环境配置、软件安装和模型部署等步骤的繁琐过程,真正实现了“开机即用”。借助NovaPaw,所有的Prompt、会话、记忆、文件操作和指令执行都能快速实现本地部署,数据不会外泄,也不上传任何第三方服务器。安全方面更是实现了物理级的安全隔离,确保数据安全与自主性。</p>
<p>这些案例有一个共同特点:智能体在工作流中扮演主动角色,而不是被动响应。这正是智能体主机与AI PC之间的核心区别。</p>
<p><strong>AMD全形态产品矩阵</strong></p>
<p>作为一个新兴类别,智能体主机需要一个完整的产品矩阵和生态支持。AMD在这方面已经有了清晰的布局,打造了全形态的智能体主机产品矩阵:一体机、Mini工作站、笔记本、移动工作站以及水冷工作站,这些产品针对不同场景进行了差异化设计。</p>
<p><img decoding="async" src="https://www.2090ai.com/wp-content/uploads/2026/04/image-VB4Iq5.webp" loading="lazy" alt="AMD的新赌注:智能体主机开启计算新篇章!"></p>
<p>华硕ProArt创13 2026、ROG幻X、惠普Zbook Ultra G1a 14、玄派玄机16、零刻GTR9 PRO、磐镭Bosgame M5、铭凡MS-S1 Max、雷神水冷迷你AI工作站、极摩客EVO-X2、希未R27一体机……这些产品涵盖了从消费级到专业级的各个市场。</p>
<p>AMD如何引领智能体主机新时代</p>
<p>AMD真的是通过提供硬件平台和最佳已知配置(BKC),把合作伙伴的开发和用户的使用门槛都降低了不少。这样一来,合作伙伴就能专心搞定应用场景,而不需要从头开始搭建硬件架构。更重要的是,用户在拿到智能体主机后,也能轻松上手。</p>
<p>这种生态建设的思路,跟AMD在传统PC市场的做法相比,简直是天差地别。在这个崭新的智能体主机市场,AMD从一开始就重视生态系统的建设。</p>
<p><strong>智能体主机改变了计算设备的形态</strong></p>
<p>自从AMD开始大力发展智能体主机以来,市场上涌现出很多围绕“机机交互”设计的新设备。这些设备在算力、能效和生态适配等方面都实现了全面的进化。</p>
<p>过去四十年间,”人机交互”一直是主流:人通过键盘、鼠标、触控等输入设备和计算机进行互动,而计算机则作为工具来完成各种任务,关键在于“增强人的能力”。</p>
<p>但当AI智能体能够独立完成复杂任务时,计算的核心就不再是“增强人的能力”,而是转向“主力承担工作”。鉴于AI技术正不断进步,“机机协同”的计算模式显然是一个长期且不可逆的趋势。AMD的提前布局无疑是相当有远见的。随着AMD锐龙AI Max系列的推出,智能体主机时代的到来将为各行各业注入原生AI动力,逐步彻底地重塑我们的工作流程,真正实现效率的飞跃式提升。</p>
<p>
来源:百家号
原文标题:智能体主机:AMD押注的下一个计算范式
声明:
文章来自网络收集后经过ai改写发布,如不小心侵犯了您的权益,请联系本站删除,给您带来困扰,深表歉意!

 你没听错!这只洋气的开源AI智能体居然被称为“龙虾”,因为它的图标就是那只红彤彤的小龙虾!
你没听错!这只洋气的开源AI智能体居然被称为“龙虾”,因为它的图标就是那只红彤彤的小龙虾! 阿里通义千问离线AI大提速,6G内存也能畅跑,隐私安全还永久免费,普通人也能享受高端AI的福利!
阿里通义千问离线AI大提速,6G内存也能畅跑,隐私安全还永久免费,普通人也能享受高端AI的福利!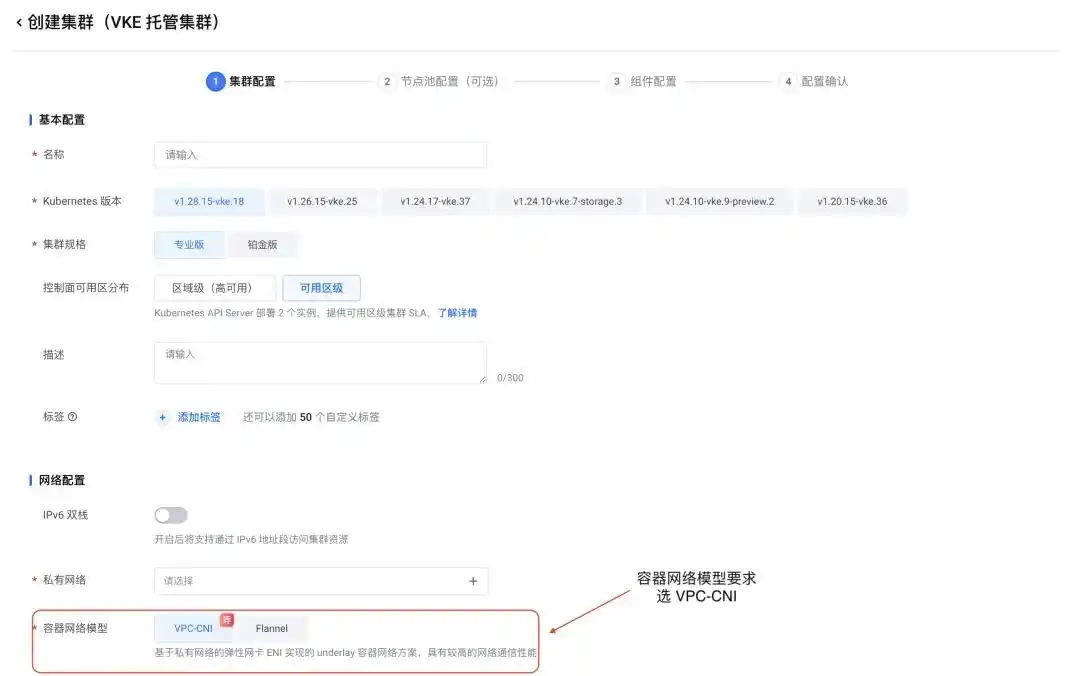 轻松一键,火山引擎云上部署 DeepSeek 大模型,实战体验不容错过!
轻松一键,火山引擎云上部署 DeepSeek 大模型,实战体验不容错过! 探秘Qwen3-VL-Reranker:阿里通义的跨模态重排序模型竟然如此强大!
探秘Qwen3-VL-Reranker:阿里通义的跨模态重排序模型竟然如此强大!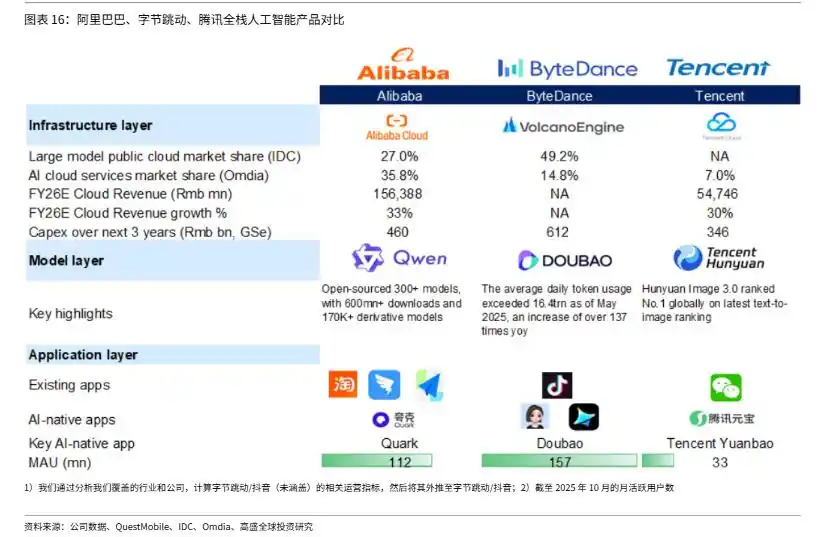 “百虾大战”谁能称王?三大巨头拼命烧钱养AI Agent,真金白银还是泡沫狂欢?
“百虾大战”谁能称王?三大巨头拼命烧钱养AI Agent,真金白银还是泡沫狂欢? 王兴发出“进攻信号”,美团的AI会不会大展身手?
王兴发出“进攻信号”,美团的AI会不会大展身手? 难道“驾驭工程”真的是实现AI平权的唯一道路?
难道“驾驭工程”真的是实现AI平权的唯一道路? 一只龙虾竟然成了MiniMax、月暗和智谱的财神爷,真是太神奇了!
一只龙虾竟然成了MiniMax、月暗和智谱的财神爷,真是太神奇了! 竟然一只龙虾成了MiniMax、月暗和智谱的财神爷!
竟然一只龙虾成了MiniMax、月暗和智谱的财神爷! OpenClaw“全民养虾”时代,哪家Coding Plan最适合你?国内主流Coding Plan套餐详解
OpenClaw“全民养虾”时代,哪家Coding Plan最适合你?国内主流Coding Plan套餐详解
AMD这次的赌注感觉像是在追逐风口,希望他们能稳住,不要跟风。
也许未来我们可以看到基于这项技术的新的游戏类型,真是令人期待。
建议多关注这类新兴技术的应用场景,可能会有意想不到的突破。
这些智能体主机会不会成为未来的主流,真想知道!
期待看到这项技术在实际应用中的表现,可能会带来意想不到的惊喜。
这些新技术在游戏开发中的潜力有多大?会不会有新的玩法出现?
我对这款主机的散热设计有些担心,处理器性能再强也得有好的散热。
这款主机的设计理念让我联想到过去的游戏主机,希望它能带来新的游戏体验。
这款主机的AI能力听起来很强,游戏开发者会不会因此迎来新的创作灵感?
听说新技术会带来更智能的NPC,是真的吗?这会不会改变游戏方式?