资料
DeepSeek 是由中国一家叫深度求索的初创公司推出的大语言模型。它的开源模型主要有:
DeepSeek-V3 :这是一款通用的大语言模型,采用了 MoE 结构,拥有 671B 的参数,激活参数为 37B。它在 14.8T 的 token 上进行了预训练,能提供信息检索、数据分析和自然语言处理等多种服务,适合于客户服务、教育辅导和内容创作等场景;
DeepSeek-R1 :这个推理模型是基于 DeepSeek-V3-Base 训练而成,特别擅长处理数学、代码和自然语言推理等复杂任务,能够在复杂环境中稳定运行,适合工业自动化和家庭服务机器人等领域;
DeepSeek-R1-Distill :这个模型是基于 DeepSeek-R1 训练出的,经过 800K 样本微调,专为资源受限的场景设计。与 DeepSeek-R1 相比,它体积更小、能耗更低,同时性能依然很强大,方便在各种设备上部署。
接下来,我们将介绍三种在火山引擎云上快速部署 DeepSeek-R1-Distill 模型的方法:
第一种方案是基于 GPU 云服务器、容器服务 VKE 和持续交付 CP 的云原生 AI 部署方案,能够提供更强大的水平扩展能力;
第二种方案是基于函数服务 veFaaS 的无服务器化方案,灵活性和便捷性都很强;
第三种方案是基于开源 Terraform 的一键部署方案,用户只需复制脚本并执行,就能安全高效地完成基于 ECS 的部署。
方案一:容器化部署
在企业的生产环境中,结合容器与 AI 技术,可以显著缩短大模型服务的打包和部署时间,同时实现计算资源的快速部署和灵活调配。火山引擎的容器服务 VKE 利用新一代云原生技术,提供以容器为核心的高性能 Kubernetes 集群管理服务,用户可以借此快速构建容器化的 AI 应用。
步骤一:创建 VKE 集群
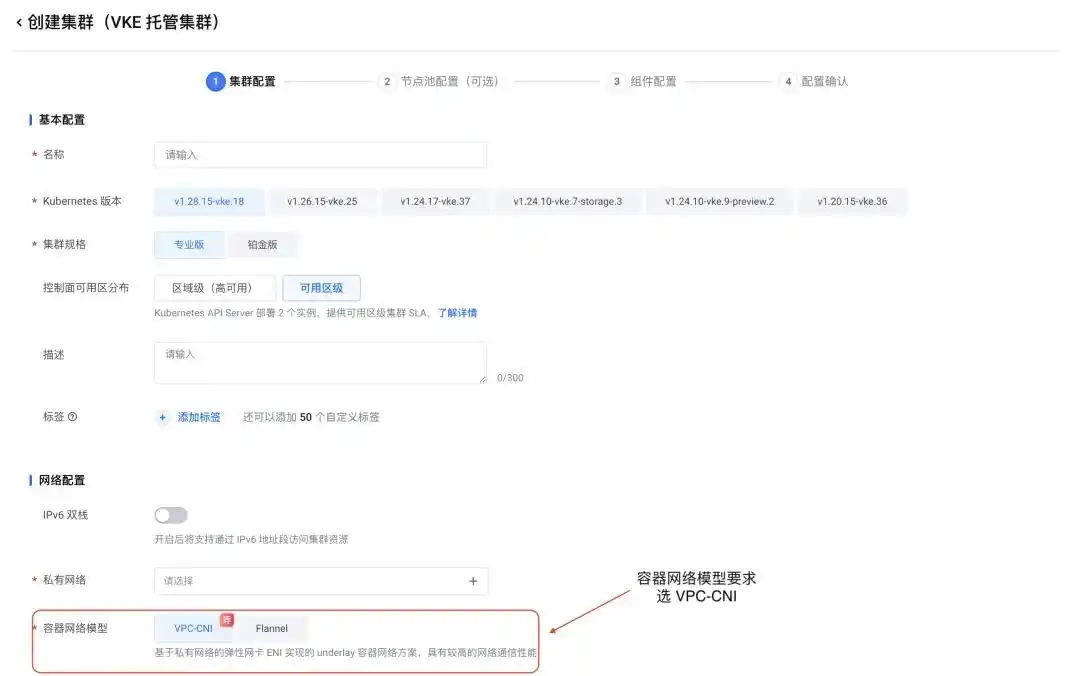
在正式部署 DeepSeek-R1-Distill 模型推理服务之前,我们得先创建 VKE 集群。请访问火山引擎容器服务 VKE 的工作台:https://console.volcengine.com/vke,然后创建托管集群(如下图所示),建议选择 VPC-CNI 作为网络模型:
得益于内外资源的共用,火山引擎为用户提供了高弹性且性价比高的算力产品,覆盖多种型号,以满足企业在利用 AI 技术进行数字化转型时的算力需求。在大模型服务的部署中,我们建议使用不同的 GPU ECS,以获取更高的性价比。以 DeepSeek-R1-Distill 为例,以下是一些节点配置的推荐(用户也可以选择使用整机 8 卡机型来运行多个容器):
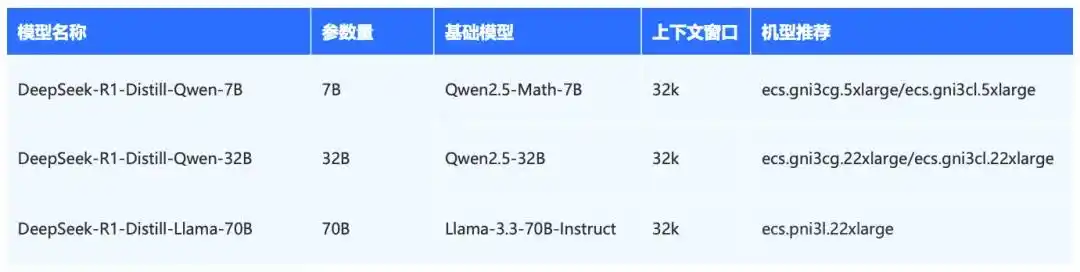
注:若想使用 ecs.gni3cg/ecs.gni3cl/ecs.pni3l,请联系客户经理申请
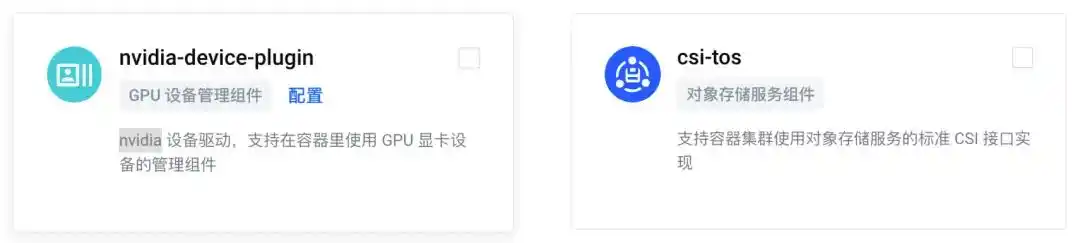
最后,在创建集群时,我们需要选择组件配置,额外选择 csi-tos 和 nvidia-device-plugin 两个组件进行安装(相关文档:https://www.volcengine.com/docs/6460/101014):
步骤二:创建部署集群
接下来的流程跟之前的 FLUX.1 和 Stable-Diffusion-WebUI 的部署类似,这次我们依然会使用火山引擎的持续交付 CP 的 AI 应用功能。它提供了预置模板,集成了主流的 AI 框架,并封装了操作系统、AI 框架以及依赖库等应用环境,能够快速在新创建的容器服务中部署 DeepSeek-R1-Distill,极大地降低了开发难度。
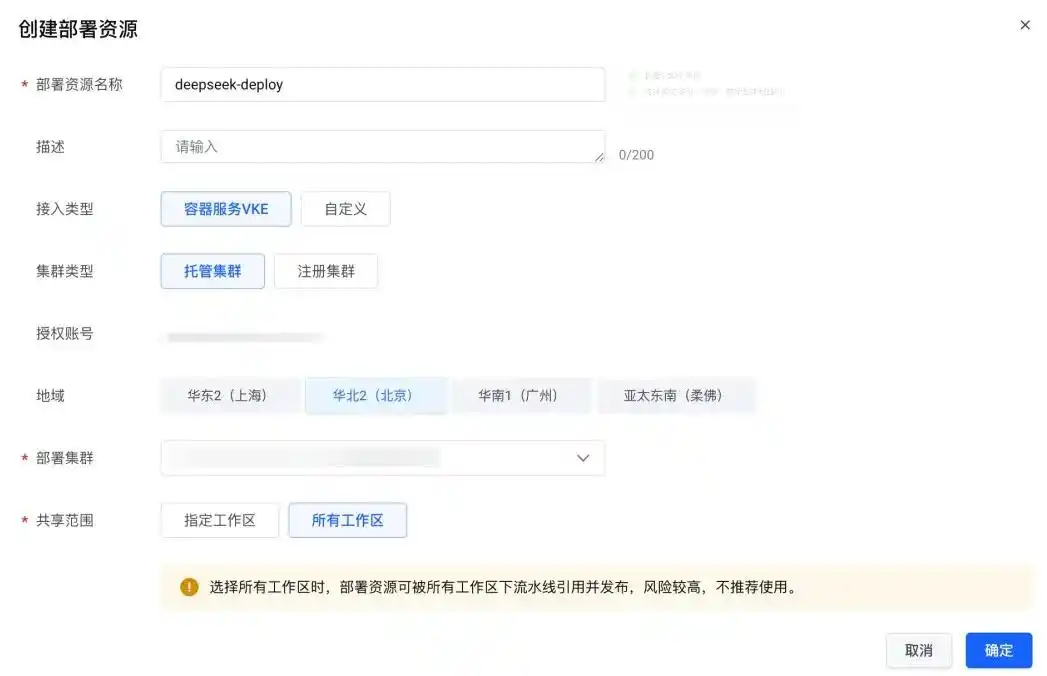
打开火山引擎持续交付产品工作台:https://console.volcengine.com/cp,在左侧菜单中选择“资源管理-部署资源”,点击“创建部署资源”:

在创建部署资源的表单中,选择“接入类型”为“容器服务 VKE”;地域和部署集群则选择刚刚创建的 VKE 集群;共享范围可以选择所有工作区:
步骤三:创建 AI 应用
基础信息配置:在持续交付 CP 的工作台左侧菜单中选择“AI 应用”(邀测功能,欢迎联系客户经理申请),然后点击“创建应用”:
在应用创建表单中,选择“自定义创建”:
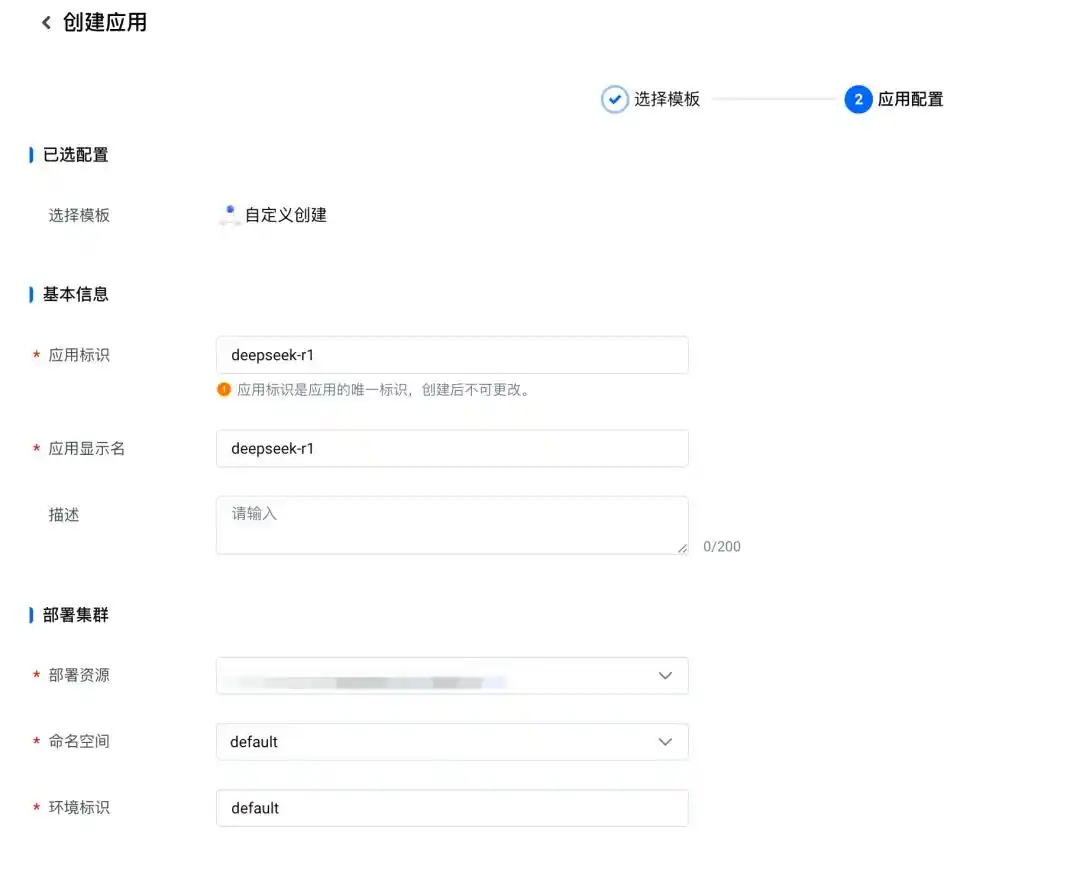
完成应用名和部署集群的配置。要注意的是,这里的部署集群需要选择之前创建的部署集群:
接下来完成启动镜像和模型的配置。针对 DeepSeek-R1-Distill,我们可以选择 SGLang 镜像进行部署;模型可直接选择“官方模型”中的 DeepSeek-R1-Distill,挂载路径设置为“/model”:
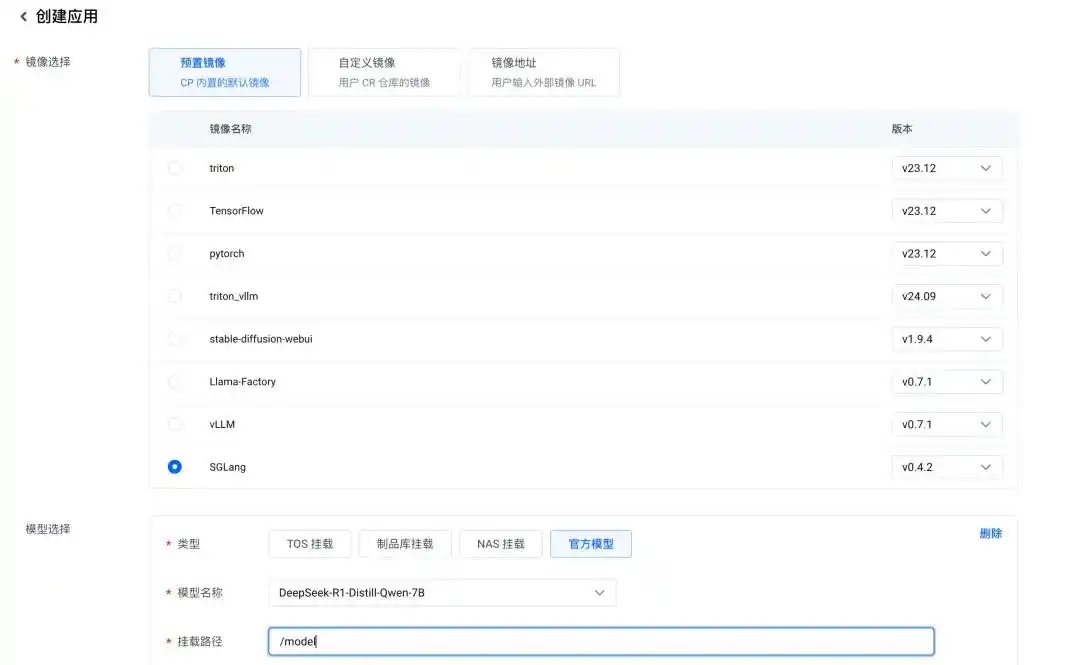
SGLang 默认的启动命令如下,用户也可以根据实际推理服务的需求,对默认启动命令进行调整。
轻松上手 DeepSeek-R1-Distill 部署指南
首先,我们要启动推理服务,可以用下面的命令:
python3 -m sglang.launch_server –model-path /model –context-length 2048 –trust-remote-code –host 0.0.0.0 –port 8080
接下来,设置一下推理服务的规格。这里选一个实例,数量为1。根据不同参数量的 DeepSeek-R1-Distill,咱们可以参考下面的配置建议:

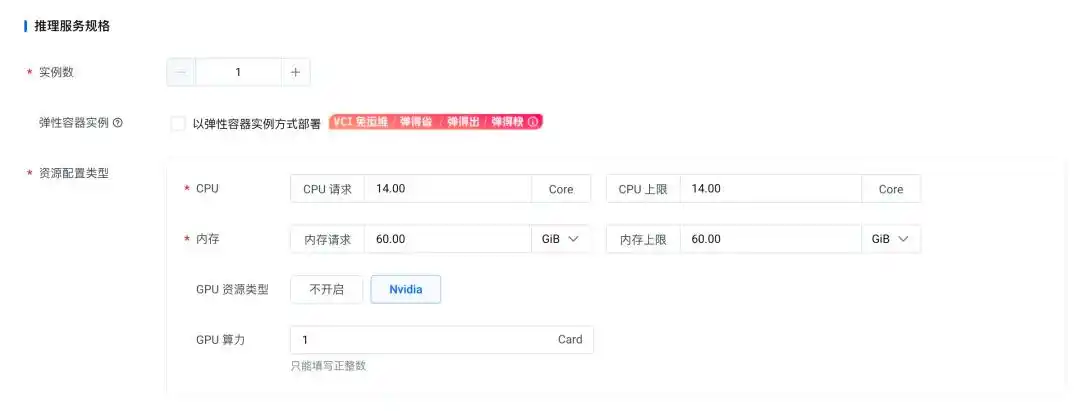
好了,服务配置完成后,咱们只需耐心等大约 5 分钟,DeepSeek-R1-Distill 的服务就能顺利部署完成。
步骤四:创建负载均衡访问推理服务
火山引擎的负载均衡 CLB 是一种可以将流量按策略分配给多个后端服务器的服务,这样可以增强系统的对外服务能力,避免单点故障,让系统更加稳定。我们接下来就用 CLB 来对外展示服务。
在 AI 应用页面,点击“访问设置”:
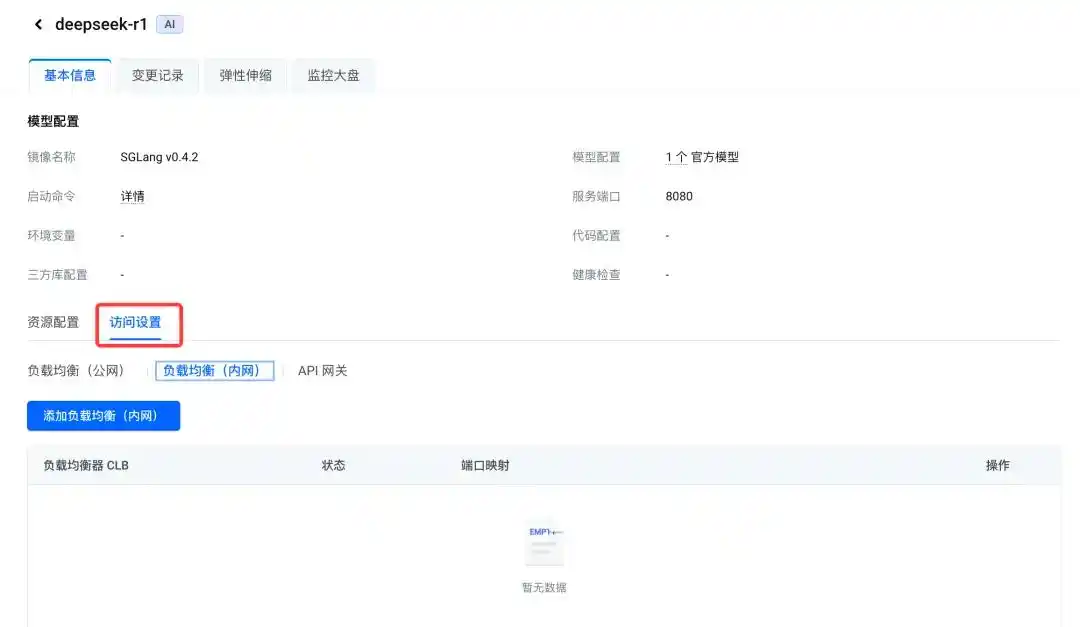
然后选择“添加负载均衡”,根据需要选“公网”或“内网”,这里我们以公网为例。如果没有公网 CLB,可以点击“创建负载均衡”:
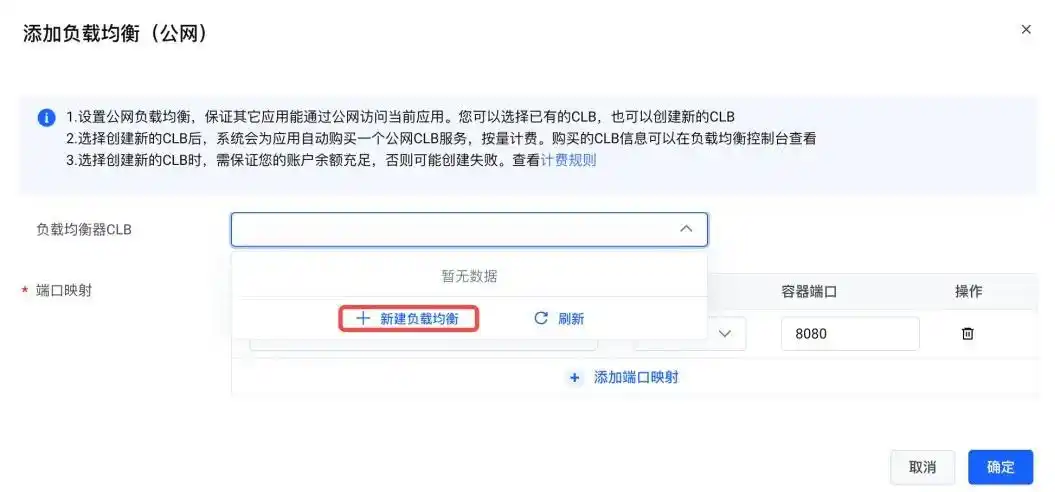
在创建负载均衡时,记得要选择和之前 VKE 集群相同的私有网络配置:
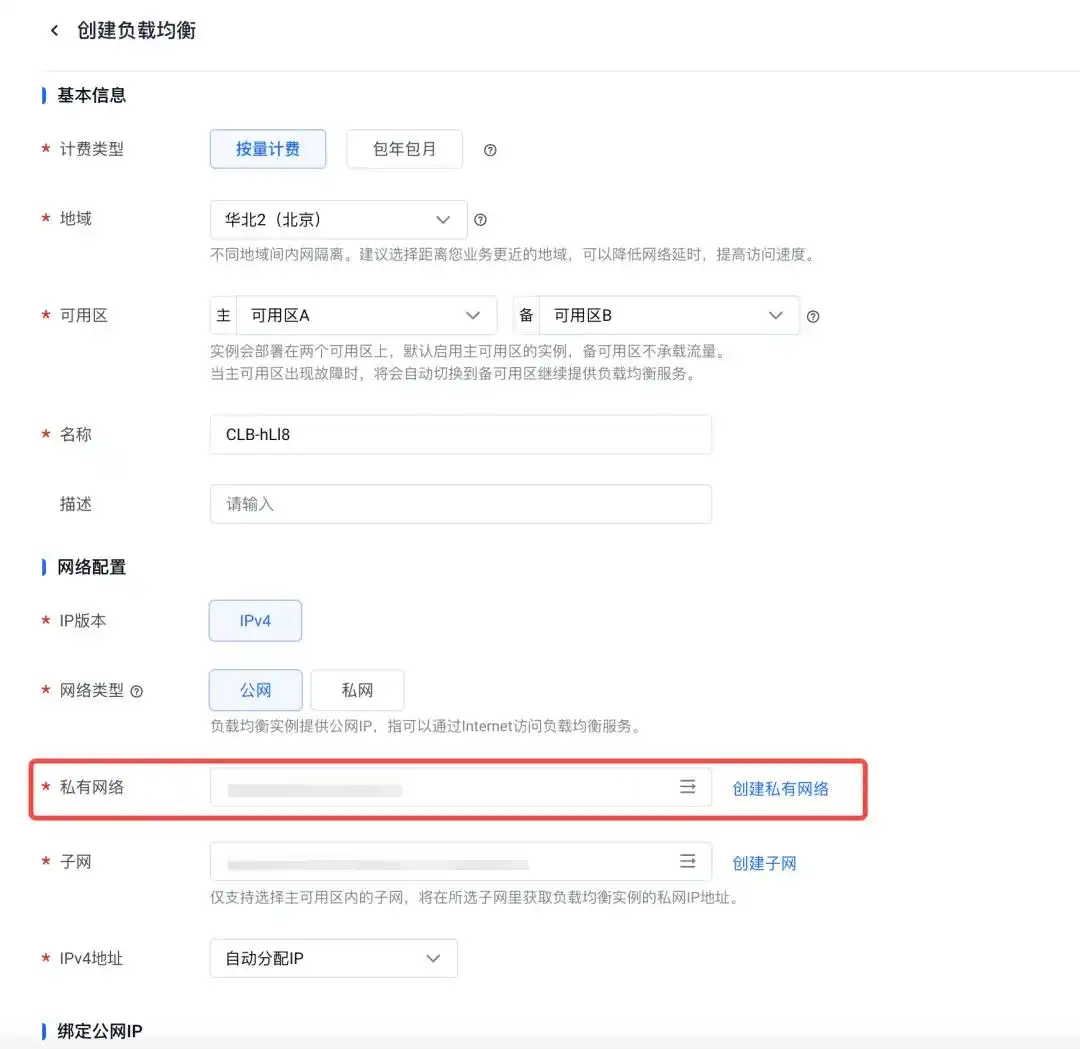
创建完成后,点击这个负载均衡,配置端口,确保容器端口与之前的应用端口一致即可:
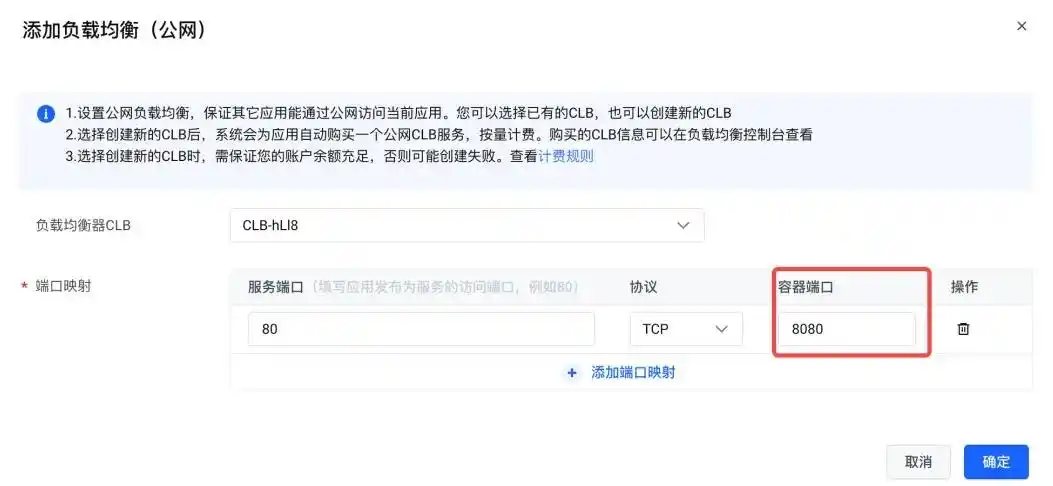
完成这些步骤后,在“访问设置”页面就能看到公网 IP 了:
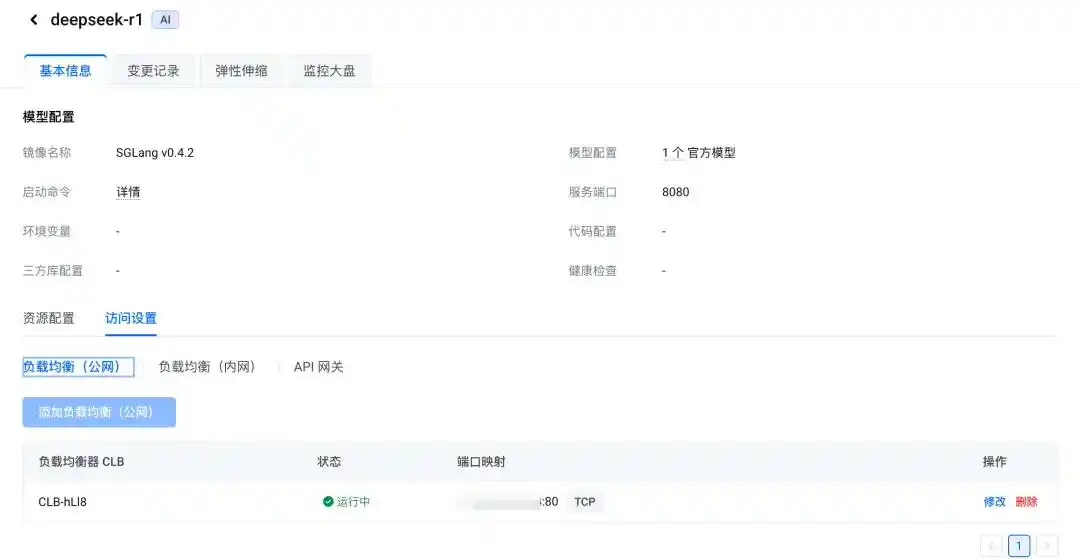
到这里,我们就完成了 DeepSeek-R1-Distill 的整个部署和对外服务,接下来可以用本地的 curl 命令来调用 API,体验一下大模型的问答能力,命令如下:
curl -X POST http://你的负载均衡IP/v1/chat/completions -H “Content-Type: application/json” -d ‘{
“model”: “/models”,
“messages”: [
{
“role”: “user”,
“content”: “你对DeepSeek的提问”
}
],
“stream”: false,
“temperature”: 0.7
}’

方案二:Serverless化部署
推荐的第二种方案是通过 Serverless 方式进行轻量化部署。火山引擎的函数服务 veFaaS 是一个事件驱动的全托管计算平台,使用它部署 DeepSeek-R1-Distill 时,用户无需担心底层资源的维护和自动扩展,只需编写代码并上传,便能以弹性、安全、可靠的方式运行。而且,费用只针对实际运行的资源和调用次数,代码不运行就不收费,特别适合需要灵活和敏捷业务的场景。
如果想通过函数服务 veFaaS 来部署 DeepSeek-R1-Distill,通常需要做好以下准备:
本地开发环境:
需要安装 Docker Desktop 或者 Docker:https://www.docker.com/get-started/
【可选】可以安装 ollama 命令行工具:https://ollama.com/download
火山引擎账户在 cn-beijing 区域开通以下服务:
函数服务 veFaaS (用于执行 Ollama 推理服务):https://console.volcengine.com/vefaas并且开通了 Serverless GPU 功能的试用
API 网关:https://console.volcengine.com/veapig
【可选】对象存储 TOS:https://console.volcengine.com/tos
步骤一:创建 Ollama 模型推理服务
进入火山引擎的函数服务 veFaaS 工作台:
https://console.volcengine.com/vefaas,创建一个“Web 应用”。在这里选择公共镜像的 Ollama 镜像模板进行部署,计算模式选 GPU 加速(如果是邀测功能,可以联系客户经理申请):
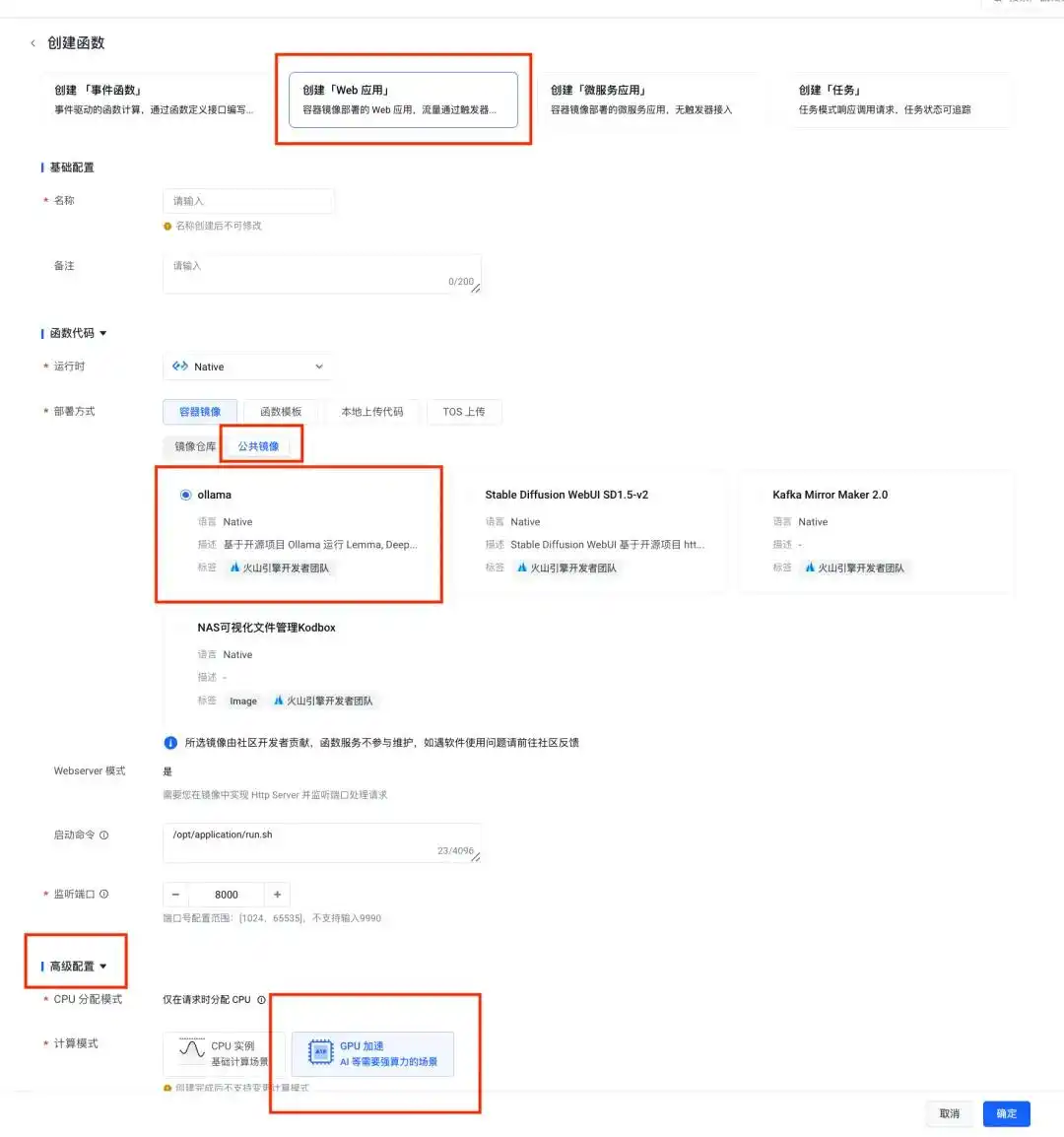
创建完成后,点击右上角的发布按钮,服务就部署好了:
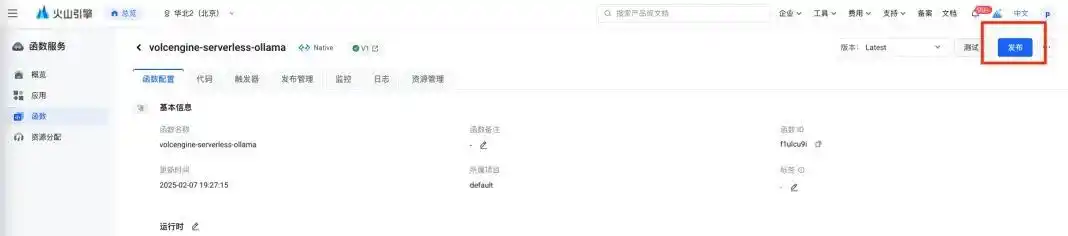
步骤二:创建 API 网关接入点
火山引擎的 API 网关 APIG 是一个基于云原生的高扩展性和高可用性的云上网关托管服务。它在传统流量网关的基础上,集成了丰富的服务发现和治理能力,能帮助用户实现微服务架构内外部网络的快速安全通信。我们将利用 APIG 来暴露 DeepSeek-R1-Distill 服务。
轻松上手火山引擎 API 网关:一步步教你如何创建和测试
首先,咱们从火山引擎的 API 网关 APIG 工作台开始,直接访问这个链接:
https://console.volcengine.com/veapig
在这里,你可以创建一个新的 API 网关实例。为了方便测试,建议选择 Serverless 网关,这样更易于使用。
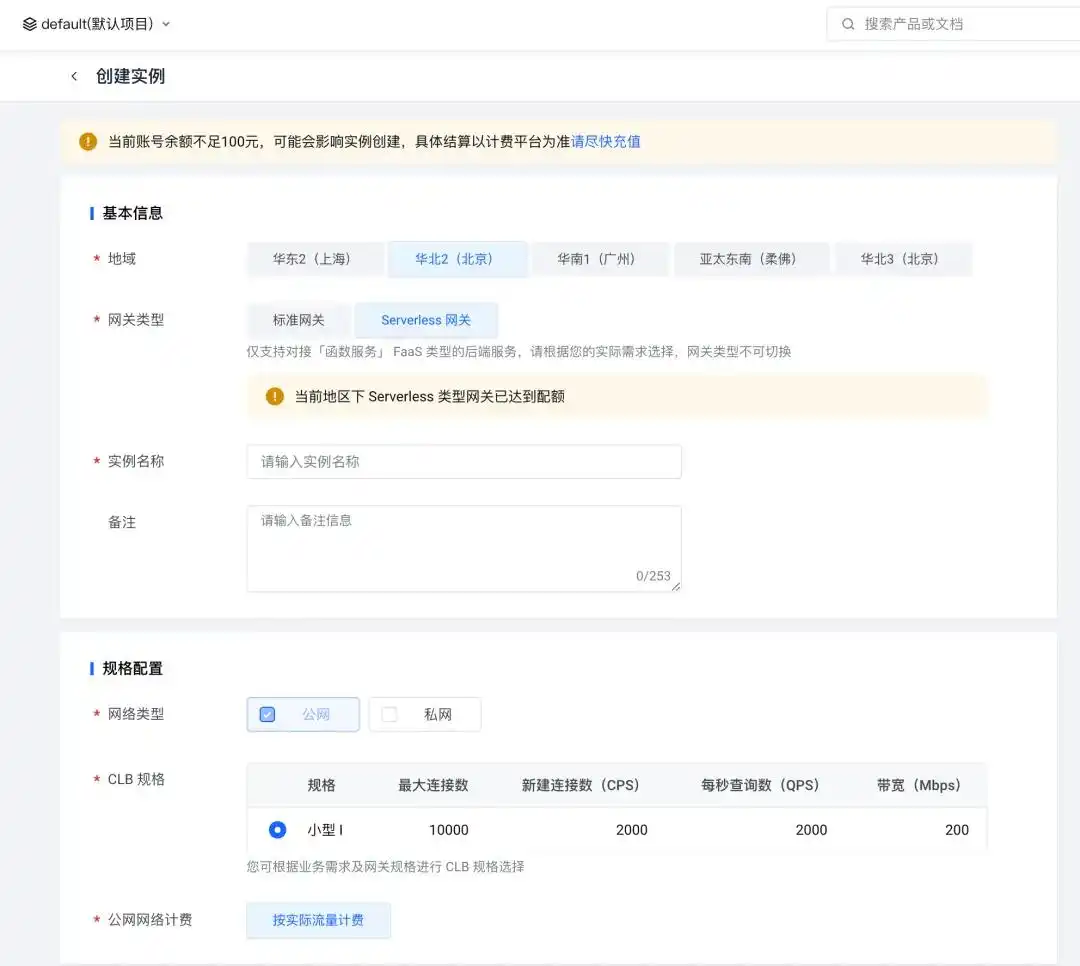
网关实例创建好之后,接下来的步骤就是新建一个网关服务,以便对外公开一个可以访问的域名。
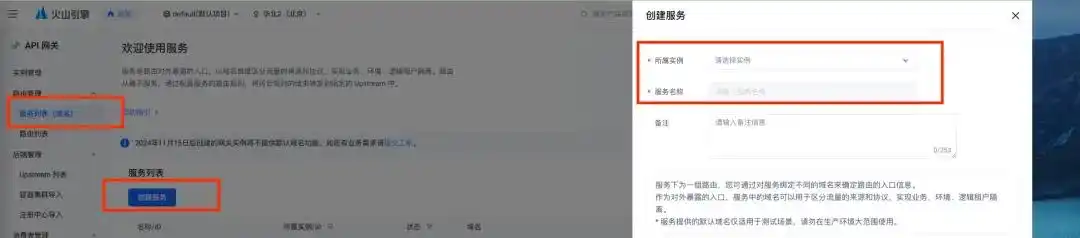
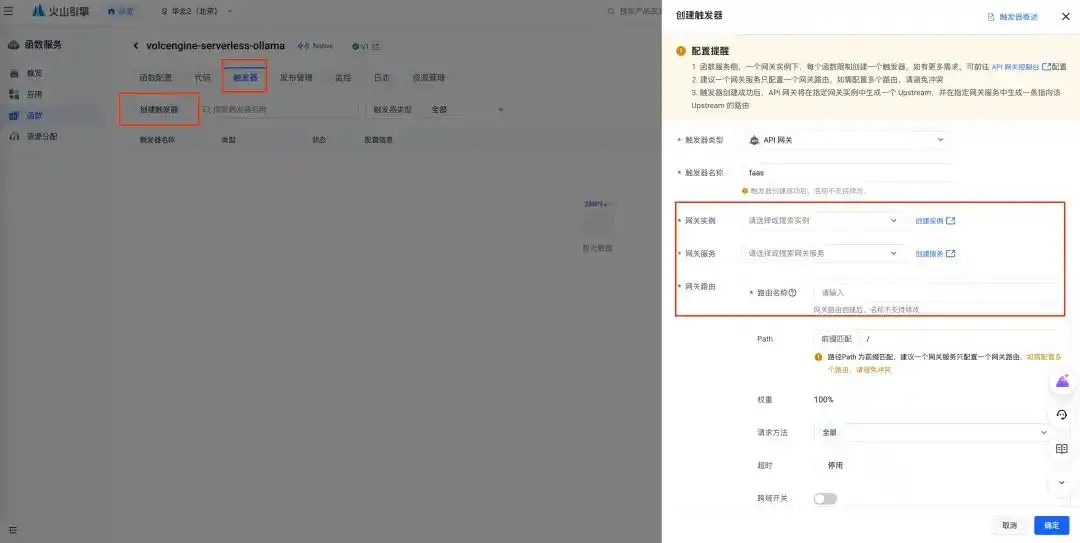
然后,回到火山引擎的 veFaaS 控制台,找到你刚刚创建的 API 网关实例和服务,接着创建 API 网关触发器。
Step3:在本地测试 open-webui
在这一步,我们将利用一个开源项目 open-webui(你可以在这里找到:https://github.com/open-webui/open-webui),在本地启动前端控制台,访问在步骤2和步骤3中配置的 Ollama 服务。
注意!启动参数中,我们需要做几件事情:
- 设定 open-webui 使用 ollama 作为推理后端,并填写 ollama 后端的地址;
- 关闭 openAI API 的访问;
- 关闭访问鉴权(这样测试会方便很多);
- 禁用 open-webui 自带的 embedding 模型和 whisper 模型的自动更新。
本地启动命令(确保你已经安装了 Docker Desktop):
docker run -p 3000:8080 -v open-webui:/app/backend/data --name open-webui-new --restart always --env=OLLAMA_BASE_URL=[这里替换为Step3 API 网关 地址] --env=ENABLE_OPENAI_API=false --env=ENABLE_WEBSOCKET_SUPPORT=false --env=ENABLE_RAG_WEB_SEARCH=true --env=RAG_WEB_SEARCH_ENGINE=duckduckgo --env=WEBUI_AUTH=false --env=RAG_RERANKING_MODEL_AUTO_UPDATE=false --env=WHISPER_MODEL_AUTO_UPDATE=false --env=RAG_EMBEDDING_MODEL_AUTO_UPDATE=false ghcr.io/open-webui/open-webui:main
完成这些后,打开浏览器,输入 localhost:3000 来访问你的服务。
(可选)Step4:添加并使用其他模型
公共镜像中已经包含了 DeepSeek-R1-Distill-Qwen-1.5B 模型。如果你想尝试其他的 DeepSeek 蒸馏模型版本,可以把模型下载到 TOS 对象存储,并挂载到相应的函数服务路径上。
关于 Ollama 模型,你可以查看这里:https://ollama.com/library;下面以 DeepSeek-R1-Distill-Qwen-7B 为例:
使用 Ollama 命令行工具下载模型文件:
ollama run deepseek-r1:7b
嘿,你好呀!很高兴见到你,有什么我可以帮忙的吗?无论是有什么问题、建议,还是想聊聊天,我都在这儿哦。😊
Ollama 模型文件默认会保存在 ~/.ollama/models 目录下
➜ ls -lb ~/.ollama/models
如果你看到这些内容:
total 0 drwxr-xr-x@ 22 bytedance staff 704B Feb 6 13:49 blobs/ drwxr-xr-x@ 3 bytedance staff 96B Feb 3 23:45 manifests/
关于函数服务挂载对象存储的详细信息可以参考这个链接:https://www.volcengine.com/docs/6662/1222882。记得,AKSK 需要拥有 TOS 存储桶的读写权限哦!
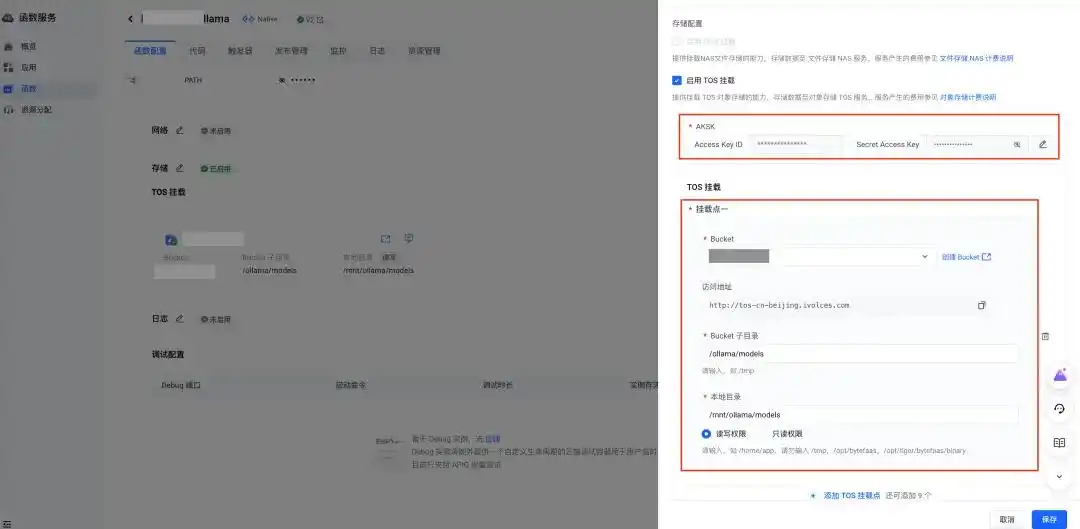
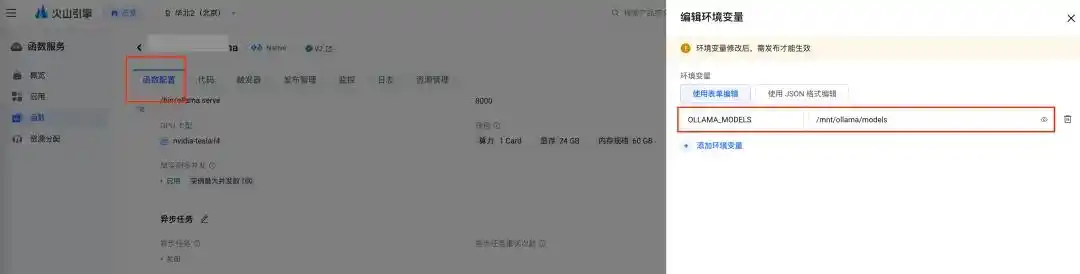
挂载完成后,别忘了设置环境变量 OLLAMA_MODELS 为模型的挂载路径。完成挂载和更新环境变量后,别忘了重新发布以使其生效:
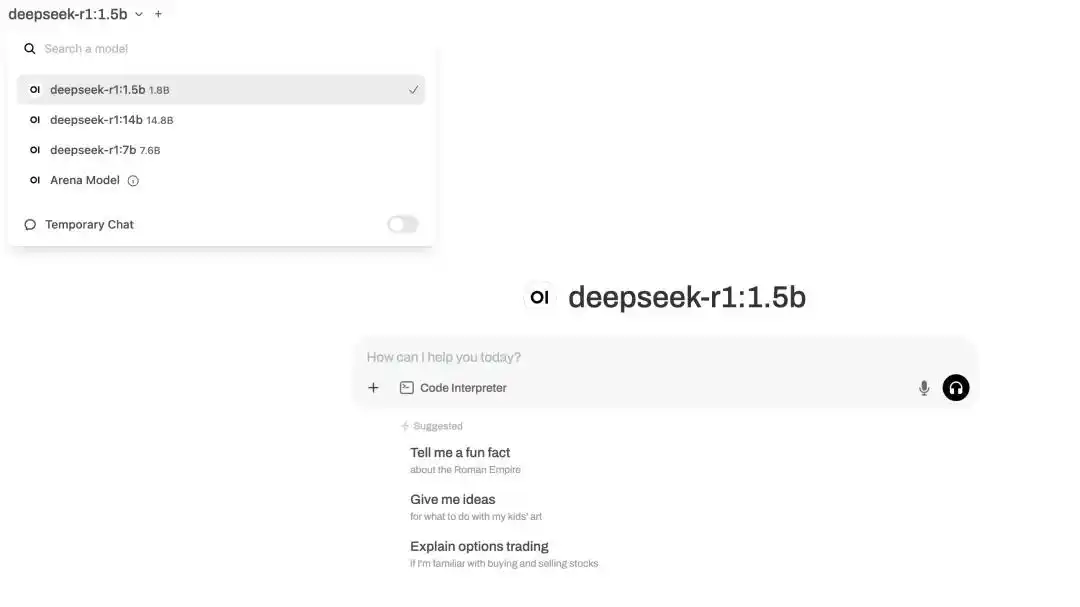
最后,重复一下 Step3 的本地测试步骤,你会发现多个模型选项已经出现了!
方案三:用 Terraform 一键搞定部署
说到 Terraform,这可是个开源的基础设施即代码(IaC)工具,专门帮助大家用声明式的配置文件来自动化创建和管理云资源,支持超过 300 家云服务商。这样一来,用户就能轻松实现多云架构的统一管理,真的很方便。
火山引擎为了积极融入开源生态,已经和 Terraform 进行了大量集成,用户可以通过 Terraform 来编排火山引擎上的各种云资源。因此,我们强烈推荐使用 Terraform 脚本来自动创建所需的云资源,进而实现 DeepSeek 的一键部署。
Step1:准备 Terraform 环境
首先,咱得安装 Terraform,并初始化使用环境,这样才能为接下来的 DeepSeek-R1-Distill 一键部署做好准备。
Terraform 是以可执行的二进制文件发布的,所以你只需下载官方版本的 Terraform,然后把可执行文件的目录加到系统环境变量的 PATH 中就行了。具体的操作步骤可以参考这个链接:https://www.volcengine.com/docs/6706/101977。
Step2:创建并执行 Terraform 脚本
接下来,创建一个名为 main.tf 的文件,把下面的代码粘进去,记得修改 ecs_instance 中的登录密码 password。然后执行 terraform init,接着执行 terraform apply,等它执行完就好了。
要注意的是,模型下载的速度和 ECS 所在的区域是有关系的。如果你把 ECS 实例和镜像/模型存储的位置设置为同一地区,会大大加快下载速度。当前的示例脚本是针对 cn-beijing 的,如果你需要切换区域,请修改 main.tf 文件里的 zone_id 参数,以及执行脚本时的 region 相关参数。
terraform {
required_providers {
volcengine = {
source = “volcengine/volcengine”
version = “0.0.159”
}
}
}
resource “volcengine_vpc” “foo” {
vpc_name = “acc-test-vpc”
cidr_block = “172.16.0.0/16”
}
resource “volcengine_subnet” “foo” {
subnet_name = “acc-test-subnet”
cidr_block = “172.16.0.0/24”
zone_id = “cn-beijing-c”
vpc_id = volcengine_vpc.foo.id
}
data “volcengine_images” “foo” {
image_name = “Ubuntu 20.04 with GPU Driver 535.154.05 and mlx 5.8-3”
}
resource “volcengine_security_group” “foo” {
security_group_name = “acc-test-security-group”
vpc_id = volcengine_vpc.foo.id
}
resource “volcengine_security_group_rule” “foo” {
direction = “egress”
security_group_id = “${volcengine_security_group.foo.id}”
protocol = “tcp”
port_start = 22
port_end = 8080
cidr_ip = “0.0.0.0/0”
}
resource “volcengine_security_group_rule” “foo1” {
direction = “ingress”
security_group_id = “${volcengine_security_group.foo.id}”
protocol = “tcp”
port_start = 22
port_end = 8080
cidr_ip = “0.0.0.0/0”
}
resource “volcengine_ecs_instance” “foo” {
instance_name = “深度搜索一键部署”
轻松部署深度搜索实例
我们这边有个描述,叫“acc-test”,其实就是用来标识这个实例的。
主机名也是“acc-test”,这样更方便识别。
接下来,关于镜像ID,我们会用到一张特定的图片,具体来说,就是从我们的镜像数据中获取的第一张。
这次实例的类型是“ecs.gni3cg.5xlarge”,算是个比较强劲的配置。
登录这个实例需要一个密码,当然出于安全考虑,这个密码我就不写出来了,记得自己设置一个安全的哦。
实例的计费方式是后付费的,这样你可以先用后付。
系统盘的类型是“ESSD_FlexPL”,性能和灵活性都有保障。
而系统盘的大小设置在500GB,基本上够用。
在用户数据部分,实际上是包含了一些脚本,用于初始化和配置这个实例,确保它运行顺利。
接下来是数据卷的配置,这部分同样选择了“ESSD_FlexPL”,同样是500GB的大小,确保存储需求得到满足。
标题:轻松配置你的ECS实例,体验大模型问答能力!
“`html
delete_with_instance = true
}
subnet_id = volcengine_subnet.foo.id
security_group_ids = [volcengine_security_group.foo.id]
project_name = “default”
}
resource “volcengine_eip_address” “foo” {
billing_type = “PostPaidByTraffic”
}
resource “volcengine_eip_associate” “foo” {
allocation_id = volcengine_eip_address.foo.id
instance_id = volcengine_ecs_instance.foo.id
instance_type = “EcsInstance”
}
步骤三:测试验证
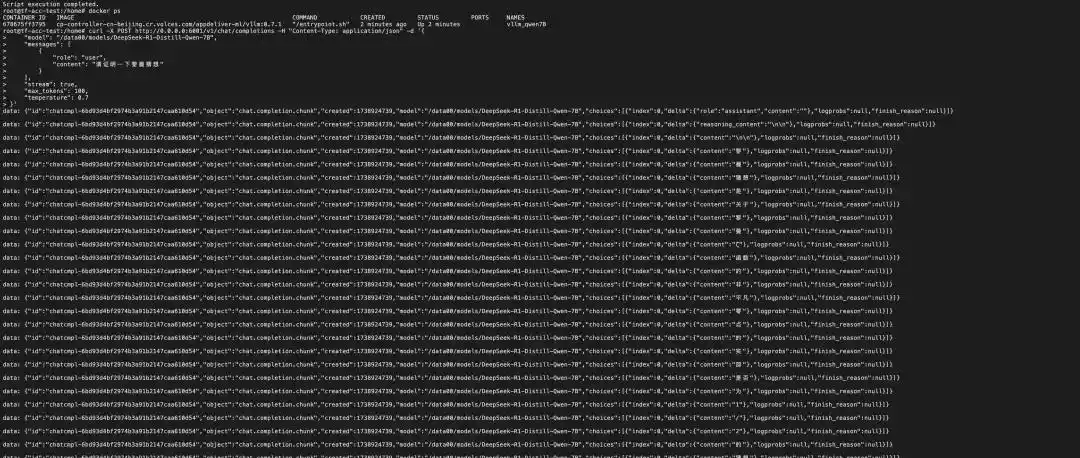
首先,登录到你创建的ECS实例,去看一下/home/result这个文件,直到你看到“脚本执行完成”的字样,这就意味着安装和启动容器的命令已经成功执行了。这时,可以用docker logsCONTAINER_ID来检查容器是否已经拉取到模型和权重。等一等,预期大约3-5分钟后就能准备好了。接下来,就可以用下面的命令来试试大模型的问答功能了:
curl -X POST http://0.0.0.0:6001/v1/chat/completions -H “Content-Type: application/json” -d ‘{
“model”: “/data00/models/DeepSeek-R1-Distill-Qwen-7B”,
“messages”: [
{
“role”: “user”,
“content”: “请证明一下黎曼猜想”
}
],
“stream”: true,
“max_tokens”: 100,
“temperature”: 0.7
}’
小提醒:有些朋友在执行curl命令时可能会看到连接被拒绝的提示(如下图所示),这通常是因为权重文件还没完全下载和加载完,稍等一下再重试就好。

(可选)步骤四:调整配置
为了提高模型的下载速度,建议大家根据你所在的地区选择离你最近的ECS实例。在上面的例子里,Terraform默认使用的是cn-beijing区域。如果你想在华北2(北京)以外的地方启动DeepSeek-R1-Distill实例,可以调整相关参数:

具体的调整方法是在执行脚本中修改对应字段,然后把整个文件进行base64编码,放到main.tf中的user_data字段里。修改完成后,再重新执行main.tf文件就行了。
DeepSeek-R1-Distill蒸馏版qwen-7B执行脚本:
#!/bin/bash
设置输出文件路径
RESULT_FILE=”/home/result”
touch RESULT_FILEecho””>RESULT_FILEecho“”>RESULT_FILE
echo “正在更新软件包列表…” >> RESULT_FILEsudoaptupdate>>RESULT_FILEsudoaptupdate>>RESULT_FILE 2>&1
echo “正在安装所需的包…” >> RESULT_FILEsudoaptinstall−yca−certificatescurlgnupglsb−release>>RESULT_FILEsudoaptinstall−yca−certificatescurlgnupglsb−release>>RESULT_FILE 2>&1
“`
轻松搞定 Docker 安装指南
首先,我们得给 apt 的密钥环准备一个目录。可以用这个命令:echo "正在创建 apt 密钥环目录..." >> RESULT_FILE; sudo mkdir -p /etc/apt/keyrings >> RESULT_FILE 2>&1。
接下来,我们要获取 Docker 的 GPG 密钥,执行这个命令:echo "正在获取 Docker GPG 密钥..." >> RESULT_FILE; curl -fsSL https://mirrors.ivolces.com/docker/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg >> RESULT_FILE 2>&1。
然后,别忘了添加 Docker 的仓库。可以这样做:echo "正在添加 Docker 仓库..." >> RESULT_FILE; echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.ivolces.com/docker/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list >> RESULT_FILE 2>&1。
接下来,更新 apt 并安装 Docker。运行这两个命令:echo "正在更新 apt 并安装 Docker..." >> RESULT_FILE; sudo apt update >> RESULT_FILE 2>&1 和 sudo apt install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin >> RESULT_FILE 2>&1。
然后,我们要添加 Nvidia 的仓库,执行以下命令:echo "正在添加 Nvidia 仓库..." >> RESULT_FILE; curl -s https://mirrors.ivolces.com/nvidia_all/ubuntu2204/x86_64/3bf863cc.pub | sudo apt-key add - >> RESULT_FILE 2>&1。接着,使用下面的命令来添加仓库:cat > RESULT_FILE 2>&1 然后输入 deb http://mirrors.ivolces.com/nvidia_all/ubuntu2204/x86_64/ /,最后加上 EOF。
继续更新 apt,并安装 Nvidia 容器工具包,使用这两个命令:echo "正在更新 apt 并安装 Nvidia 容器工具包..." >> RESULT_FILE; sudo apt update >> RESULT_FILE 2>&1 和 sudo apt install -y nvidia-container-toolkit >> RESULT_FILE 2>&1。
接下来,我们需要配置 Nvidia 的运行时为 Docker,使用这个命令:echo "正在配置 Nvidia 运行时..." >> RESULT_FILE; sudo nvidia-ctk runtime configure --runtime=docker >> RESULT_FILE 2>&1。
最后,重启 Docker,让一切生效:echo "正在重启 Docker..." >> RESULT_FILE; sudo systemctl restart docker >> RESULT_FILE 2>&1。
现在,你就可以开始运行 Docker 容器了!
轻松启动你的Docker容器!
其实呢,我们可以通过这条命令来运行Docker容器:“正在运行Docker容器…” 这句提示会被记录到RESULT_FILE里。接下来的那串命令就是真正的关键了,它包含了很多参数,比如网络配置、特权模式和GPU设置。这样一来,我们就能创建一个名为vllm_qwen7B的容器,并把模型路径、端口和模型名称都设置好,确保一切正常运行。哦对了,记得把模型镜像的地址也写上,最后再把结果输出到RESULT_FILE里,这样你就能看到运行的状态了哦!
任务完成!
执行完脚本后,我们还会在RESULT_FILE里写上“脚本执行已完成。”,这样就能一目了然了。
小结一下
总之,以上就是如何利用火山引擎的GPU云服务器、容器服务VKE、持续交付CP和函数服务veFaaS等工具,快速启动DeepSeek-R1-Distill模型服务的完整流程。如果你对这些服务感兴趣,随时可以开通体验哦!











用过DeepSeek的朋友们,有什么使用感受吗?想听听大家的真实体验。
这款模型的token处理量巨大,具体在实际操作中感觉如何呢?
好喜欢这个模型的设计,感觉用起来会很顺手。
如果能减少一些部署时间,用户体验会更上一层楼。
建议在文中加入更多的使用案例,便于用户参考。
实战体验如何?希望能多分享一些使用场景。
这款模型的设计简直太棒了,操作起来特别流畅,值得尝试!
实战体验很重要,希望能分享更多具体案例,帮助理解。
我在使用DeepSeek时发现,模型调优的过程也很重要,希望后续能有相关的指导。
DeepSeek的设计太赞了,感觉会让很多项目变得高效!