编者按:OpenClaw 把 AI 的主权从模型制造商转到了用户手中,但调教 AI 其实没那么简单,甚至有点让人心烦。这种背景也促使了 Harness 驾驭工程在市场上的共识。
Harness 这个词最初是指马具。马就像强大的 AI 模型,但由于它的黑箱特性,使用起来有些不可控;而 Harness 就像缰绳、马鞍和护具,是工程管理的象征;骑手则是人类工程师,他们负责明确目标、设计环境和建立反馈机制。
想象一下,你的客厅里出现了一条龙
在2026年2月,OpenAI 发布了一篇名为《Harness Engineering: Leveraging Codex in an Agent-First World》的技术博客[1]。这篇文章讲述了一个非常惊人的实验:一个由3名工程师(后来扩展到7人)组成的团队,竟然在5个月内利用 Codex Agent 生成了超过100万行的生产级代码,并合并了大约1500个 Pull Request,完全没有人类编写的代码。这篇文章真正引起行业热议的,不仅仅是“AI 写了 100 万行代码”这个数据,而是它提出了一种新的工程模式:Harness Engineering(驾驭工程)。
就像一篇在 Medium 上广为流传的文章所比喻的那样:我们的客厅里突然出现了一条龙。这条龙聪明且强大,现在看起来还挺温顺的。但龙总会长大,我们需要的可不是更粗的铁链,而是一整套完备的驾驭系统,包括缰绳、马鞍和护具,当然,还有一个懂得如何与龙相处的骑手。
工程的演变:提示词、上下文、驾驭
要深入理解 Harness Engineering(驾驭工程),我们得把视角放远一点,看看更广阔的技术历史。
▍工业革命:驾驭物理力量
蒸汽机释放了远超人类肌肉的物理力量,但它自己并不知道该如何运作,比如驱动什么、转速多快、什么时候停下。因此,人们发明了飞轮调速器、安全阀和传动系统等,这些就是工业革命时期的“Harness”。没有这些装置,蒸汽机不过是一个危险的热水壶。
▍信息革命:驾驭计算力量
计算机所释放的计算能力远超过人类大脑,但裸机不知道该计算什么。因此,人们创造了操作系统、编程语言和软件工程的方法论,从瀑布模型到敏捷开发,从汇编语言到高级语言,每一步都是在打造更好的“Harness”,以便更好地掌控计算能力。
▍AI 革命:驾驭认知力量
大语言模型的认知能力超越了人类个体,它可以自主规划、推理和生成。但模型本身并不知道该解决什么问题、遵循哪些约束,如何在真实世界中更可靠地工作。Harness Engineering 就是 AI 时代的操作系统和软件工程方法论的结合体,涵盖了 Agent 范式下的记忆、系统提示词、知识库和编排等功能,还有 OpenClaw 范式下的文本流,例如 Agent.md、Soul.md、User.md 等,都是为了更好地与模型对话。
Harness Engineering(驾驭工程)的出现,标志着 AI 驾驭系统的轮廓逐渐清晰。但谈到驾驭工程,我们不得不回顾一下提示词工程和上下文工程的演变。
▍提示词工程 Prompt Engineering
- 核心问题:如何与模型进行有效沟通?
- 人类的角色:用户需要精心设计每一句指令的措辞、格式和示例,试图从这个黑箱中引导出正确的答案。Few-shot、Chain-of-Thought、角色扮演……本质上是在一个固定的对话框中进行探索。
- 局限性:单次交互、无状态、高度依赖个人经验,更像是大师的手艺,而非真正的工程。
▍上下文工程 Context Engineering
- 核心问题:模型需要看到哪些信息?
- 人类的角色:角色发生了变化,从用户变成了 Agent Builder,Builder 们系统地设计、构建并维护一个动态系统,在 Agent 执行任务的每一步中提供合适的上下文,包括知识库、工具调用和记忆管理……关注点从用户应该说什么转向 Builder 们让模型看到什么,从而让模型更好地理解用户。
- 2025年6月,Andrej Karpathy 明确表示:上下文工程远比提示工程更为重要。
▍驾驭工程 Harness Engineering
- 核心问题:整个环境应该如何运作?
- 人类的角色:角色再次从 Agent Builder 变回到用户手中。通过设计完整的运行环境,包括约束、反馈机制、自动验证、熵管理和生命周期治理等。
- 我个人认为,驾驭工程能够在这个阶段引起共鸣,和 OpenClaw 的出现密切相关,它促使 AI 的主权从模型制造商转到了用户手中。权责对等,拥有调试 Agent 的权利,也需要学会如何驾驭,理解如何与 Agent 和谐共处。

图源:瑶池数据库举办的虾搞数据库杭州站
了解 Harness Engineering 的四个案例
读到这里,你可能会想:Harness Engineering 不就是把一些好的软件工程实践重新包装了一下吗?写好文档、建立反馈链路、做好持续集成,这些我们不是一直在做的吗?这个疑问值得深入探讨。让我们来看四个真实案例。
▍案例一:一个编辑工具的变革,让15个模型同时受益
独立开发者 Can Duruk 维护着一个开源编码 Agent 框架。他发现了一个被许多人忽视的问题:Agent 在修改代码文件时所用的编辑工具本身是一个巨大的失败源。
新一代编码工具的挑战与突破
现在,业界普遍使用的编辑方式大致可以分为三种:OpenAI 的 apply_patch(需要模型生成特定格式的差异文件)、Claude Code 的 str_replace(要求模型准确复现每个字符),还有 Cursor 训练的专用 70B 合并模型。不过,这些方式都有各自的不足之处,像 Grok 4 使用 patch 格式时,失败率竟高达 50.7%!
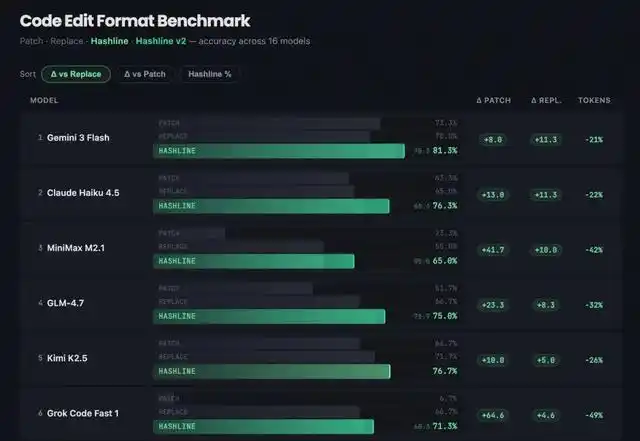
为了改善这种情况他提出了一个新方案,叫做 Hashline:在模型读取文件时,每一行都加上一个2-3个字符的哈希标签。这样,模型在编辑时只需引用这些标签,而不必一字不差地复述原文了。
// 模型看到的文件:11:a3| function hello() {22:f1| return "world";33:0e| }// 模型的编辑指令:"replace line 2:f1 with: return 'universe';"通过对16个模型、3种编辑工具和180个任务进行测试后,Hashline 几乎在所有模型上都表现得比传统方式更好。最惊人的结果是 Grok Code Fast 1,成功率从6.7%跃升到68.3%,也就是整整提升了十倍!而 Grok 4 Fast 的输出 token 数量也减少了61%。
在传统软件开发中,无论是用 VS Code 还是 Vim,都不会影响代码的质量。但在 Agent 的世界里,模型如何表达意图的接口设计,直接关系到它能否把正确的思路转化为有效的代码。Can Duruk 曾说过:“你在指责飞行员,但问题其实出在起落架上。”
▍案例二:技术债务的指数级扩展
有位独立开发者在52天内利用 AI Agent 独自写下了35万行生产代码。他发现一个在传统开发中不常见的现象:技术债务在 Agent 中会被成倍放大。
比如,当你做出临时妥协,直接查数据库或是硬编码一个数字,Agent 会把这种做法视为“先例”。下次再生成类似功能时,它就会系统性地复用这个模式。人类工程师通常会意识到某段代码有问题并避开,但 Agent 可不会,它只要看到某个模式就会认为这是合规的做法。
当好的编程实践占主导时,Agent 会放大这些良好的做法;而当捷径占主导时,Agent 则会放大这些捷径。
在传统软件开发中,技术债务是线性累积的,坏模式可能被几个开发者模仿,但传播的速度受到团队规模和代码审查的限制。而在 Agent 协作开发中,技术债务变成了一种自我复制的病毒:一个坏模式可以在短短几小时内扩散到整个代码库。
这就要求我们得有一种全新的“代码库卫生”策略,正如文章开头提到的 OpenAI 的实践:
定期运行的清理 Agent 就像垃圾回收器一样,OpenAI 团队曾把每周五的20%时间用于清理“AI 垃圾”,但后来发现这样不可持续。于是,他们把“品味”编码成自动化规则。
这里的“品味”包括:
- 倾向于使用共享的实用工具包,而不是手动编写的辅助工具,以便集中管理不变式。
- 不使用“YOLO 式”的数据探测,确保验证边界或依赖类型化的 SDK,避免智能体基于猜测的结构进行构建。
- 定期执行一组后台 Codex 任务,扫描偏差、更新质量等级,并发起针对性的重构 Pull Request。这些大多数都能在一分钟内完成审查并自动合并,类似于垃圾回收。
技术债务就像高利贷,采用小额偿还的方式总比让债务不断累积后痛苦解决要好。只要人类的“品味”被捕捉,就会在每一行代码中持续应用,这也促使我们每天发现并解决不良模式,而不是让它们在代码库中传播数天或数周。
▍案例三:子 Agent 的“上下文防火墙”功能
HumanLayer 团队在多个企业级项目中发现了一个普遍问题:Agent 的上下文窗口会随着工作进展而“腐烂”。每一次工具调用、文件读取、或者 grep 结果,都会在上下文中留下痕迹。当上下文膨胀到一定程度时,Agent 就会进入所谓的“笨蛋区”,即使是简单的任务也可能出错。
他们的研究表明,18个模型在 Terminal Bench 2.0 的测试中,随着上下文长度的增加,表现显著下降。而当上下文中混入低语义相关的信息时,退化得更加明显。
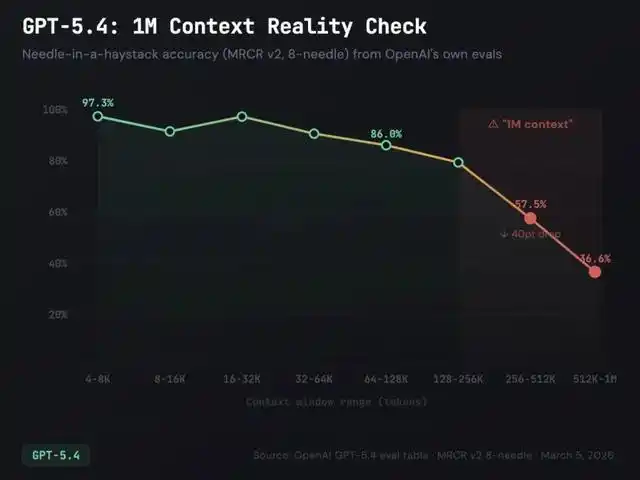
HumanLayer 提出的解决方案并不是简单地扩大上下文窗口,而是采用子 Agent 作为“上下文防火墙”:
- 父 Agent 负责整体规划和任务编排,使用高推理模型(如 Opus)。
- 子 Agent 在独立的上下文窗口中执行具体任务,使用更便宜的快速模型(如 Sonnet)。
- 子 Agent 只返回高度压缩的结果和源引用,避免污染父 Agent 的上下文。
- 父 Agent 始终保持在“聪明区”,能够在数十个子任务中保持连贯性。
最近阿里开源的 HiClaw 项目采用了 Manager-Workers 架构,这也可以看作是一种“上下文防火墙”,由 Manager 分配任务,每个 Worker 负责不同的职责,从而避免记忆溢出和污染,防止 Agent 进入“笨蛋区”。
打破界限:群体智能如何引领企业创新
在传统的软件开发中,上下文管理是我们大脑自然而然完成的事情。我们通常不用担心在翻阅大量代码后会忘记整体架构。但现在,LLM 的上下文窗口却是有限且逐渐减弱的资源。引入子 Agent 或多个 Agent 的上下文防火墙模式,可以看作是一种崭新的架构思路。这可不是简单的微服务、消息队列,或是任何已有的分布式系统概念,它专注于解决一个特定的问题:如何在注意力有限的情况下,完成那些需要无限关注的任务。
▍案例四:反馈回路的重新设计
HumanLayer 团队在早期犯了一个看似合理但其实不太聪明的错误:每次 Agent 修改代码后,他们都会运行所有的测试套件。结果呢?4000 行的测试结果涌入上下文窗口,导致 Agent 对新读到的测试文件产生了误解,失去了对当前任务的关注。
经过反思,他们总结出一个反常识的原则:“成功就应该是安静的,只有失败才需要被注意。”
于是,他们为 Claude Code 编写了一个 Hook 脚本:当 Agent 不再工作时,自动执行格式检查和 TypeScript 类型检查。如果一切正常,就保持沉默,不向上下文添加任何信息;如果失败了,便只输出错误信息,并用退出码通知 Harness 重新激活 Agent 解决问题。
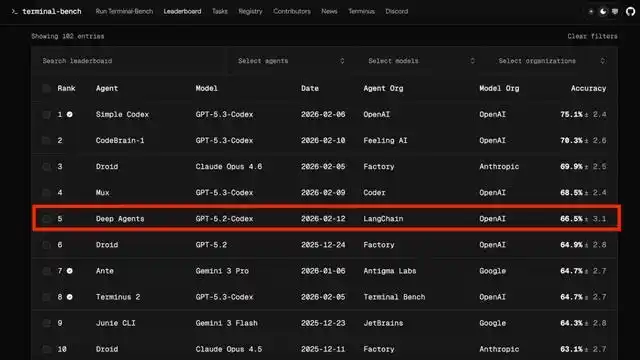
LangChain 的方法更进一步:他们设计了 PreCompletionChecklistMiddleware,在 Agent 提交结果时对其进行拦截,确保其与任务要求进行核对。同时,他们还引入了 LoopDetectionMiddleware,追踪同一文件的重复编辑次数,一旦达到 N 次,就会提示“也许换个思路会更好”,帮助 Agent 摆脱循环。
最终,LangChain 的编码 Agent 在 Terminal Bench 2.0 测试中,从前 30 名跃升至前 5 名。
传统的 CI/CD 反馈回路是为人类设计的:测试报告越详细越好,因为人类需要理解失败的原因。然而,Agent 的反馈回路则需要考虑上下文窗口的友好性,信息量必须严格控制,成功信号要压缩到无声,失败信号也要简化到最基本的操作单元。更有趣的是,“循环检测”和“强制验证”这两个功能是专门为非人类认知体的行为缺陷而设计的补救措施,人类工程师显然不需要被提醒“你已经改过同一个文件 10 次了”,也不必在提交前强制去对照需求文档。
同样的模型,搭配不同的 Harness,结果却截然不同。这四个案例告诉我们,Agent 的竞争优势不仅仅在于使用了什么模型,更在于你如何构建 Harness。Harness 就像一座护城河,保护的不仅是 Agent Builder,也为 Agent User 提供了保障。
提效率的故事已经不再吸引人,企业的真正动力在于业务创新。
Harness Engineering 不仅让单个 Agent 更加可靠,也在于优化多个 Agent 之间的协作效果,通过群体智能来推动业务创新。群体智能能够打破不同岗位之间的知识壁垒,抵消跨岗位合作带来的创意流失,从而提升企业的创新能力。
这一研究方向正在通过一系列开源项目不断向前推进。
▍CLI-Anything:实现群体智能的基础设施
虽然 AI Agent 能推理、写代码、搜索,但让它打开 GIMP 去除图片背景,或者用 Blender 渲染 3D 场景,却是它做不到的。GUI 是为人类设计的,而不是为 Agent 量身定制的。
CLI-Anything 是一个 Claude Code 的插件,它能够分析任意软件的源代码,自动生成一套生产级的命令行接口(CLI),可以调用真实的应用后端,例如通过 LibreOffice 生成真实的 PDF、用 Blender 渲染 3D 场景、用 Audacity 通过 sox 处理真实音频等。
只需一条命令就能完成所有操作:/cli-anything ,经过分析、设计、实现、测试、文档和发布这七个全自动阶段,最终输出一个可用 pip install 的 Python 包。
每个生成的 CLI 都附带 SKILL.md,这是一份机器可读的能力描述文件。这意味着 Agent 在运行时可以自动识别其他 Agent 的功能,灵活组建协作关系。这就构成了群体智能的基础设施。
▍HiClaw:群体智能的操作系统
不过,CLI-Anything 只是解决了部分问题。
想象一下,一个企业里有十多个关键部门:架构师、产品经理、前端开发、后端开发、市场、公关、供应链……每个部门都有其独特的技能和知识。在这种情况下,单体架构的 OpenClaw 要构建群体智能,就会遇到以下问题:
- 可扩展性差:用户不能随心所欲地组合,无法根据需要引入新的 Agent,只能依赖运维团队或 AI 中台重新部署。
- 模型不自由:所有 Agent 只能使用预设的模型,无法自由切换或进行效果对比。
- 成本高且效果差:多个 Agent 在一个环境中协作,记忆越长、技能越多,越容易出现信息污染。
- FinOps 难以实施:Token 消耗无法控制,无法通过灵活使用模型、共享文件等方式来实现 FinOps,投资回报率面临挑战。
- 打造灵活的 Manger-Workers 架构:用户可以随意创建不同角色的 Worker,甚至能够把公司自定义的 Agent 作为 Worker 加入其中。而且,所有 Worker 的技能和记忆都是独立存储的,这样就不会出现信息混乱的问题。
- 每个 Agent 都可以进行个性化配置:比如 OpenClaw、Copaw、NanoClaw、ZeroClaw 以及公司自行开发的 Agent,能够满足从养虾到开虾场的多种需求。每个 Agent 都能根据后端模型进行灵活设置,比如用百炼 Coding Plan 来生成代码,或者用本地的 Qwen 开源模型来撰写文本,让 FinOps 更加顺畅。
- 引入 MinIO 共享文件系统:通过这个系统,Agent 之间可以方便地共享信息,显著降低了多 Agent 协作所需的 Token 消耗。
- 集成 Higress AI Gateway:实现了访问控制和安全管理,确保每个 Agent 只能访问授权的资源。此外,它还集中管理用户的各种凭证和安全措施,保证后端稳定性(支持多模型接入、限流和降级),并统一管理技能,防止被恶意使用。同时,监控入口的情况(比如 QPS、鉴权失败率、Token 使用情况、服务延迟)以及进行安全审计(记录请求和操作日志),这些都是 AI Gateway 重要性的体现。
HiClaw:解决各种挑战的智能助手
HiClaw 的使命,就是为了应对这些问题。

接下来,让我们看看一个利用 HiClaw 实现群体智能的实际案例。某汽车制造商打算推出一款售价 700 万的豪华车型,他们设计了 N 个角色,通过进行 100 次的讨论来得出最终结果。

在这个案例中,我们挑选了三位具有不同身份的目标用户,让他们进行自由讨论。在这 100 轮对话中,他们从品牌认知、舒适需求、安全隐私、社交价值等多个角度展开了激烈的讨论。

由于内容丰富,有兴趣的朋友可以前往以下链接进一步了解。
https://github.com/alibaba/hiclaw/issues
Harness Engineering 旨在打造一个可以灵活管理、持续进化的数字智能团队。个人效率的提升是线性的,而群体智能的涌现则是指数级的。像 CLI-Anything 和 HiClaw 这样的开源项目,正是 Harness Engineering 在群体智能领域的探索和实践。
[1] https://openai.com/zh-Hans-CN/index/harness-engineering/
[2] https://blog.can.ac/2026/02/12/the-harness-problem/
[3] https://www.humanlayer.dev/blog/skill-issue-harness-engineering-for-coding-agents
[4] https://blog.langchain.com/improving-deep-agents-with-harness-engineering/