摘要
随着2025年大语言模型的能力迅速提升,IDE智能插件已经从简单的代码补全工具,转变为可以独立完成开发任务的“AI编程智能体”。本文的目标是探讨在现有技术条件下,是否真的可以实现“完全零代码”的复杂应用开发。我们在Windows 11 + PyCharm 2025.3的环境中,尝试构建一个基于LangGraph和Streamlit的多智能体辩论赛演示程序,并设定了严格的“1小时限时”和“零人工编码”要求,测试了通义灵码(国内的免费选手)、Qoder(国际新秀)和Junie(JetBrains官方与顶尖模型结合)这三款主流插件的自动化开发能力。
实验结果表明:Junie搭配Gemini 3 Pro展现了最佳的理解与执行能力,唯一实现了全流程自动化且几乎没有BUG;Qoder在性价比和架构理解方面表现均衡,但在前端交互细节上存在小问题;而通义灵码虽然具备前后端分离的设计理念,但在核心逻辑的实现上却存在明显缺陷。通过详细的实验记录和多角度对比,本文务实地分享了开发者在选择AI辅助编程工具时的参考建议。
2025-12-21更新:1)增加了后端使用Gemini 3 Flash和Claude Opus 4.5模型的实验。2)修正了之前对Gemini 3 Pro在花销计算上的错误,之前把余量当成了用量,导致结论完全错误……
前言
自从2023年ChatGPT问世以来,关于程序员会被AI取代的讨论就层出不穷。作为在代码和AI应用行业摸爬滚打了近10年的“老兵”,我对此其实心情复杂。一方面我担心自己的职业未来会因为AGI/ASI的出现而受到威胁,另一方面我又为我的孩子感到高兴,因为他们这一代或许能逃脱学习那些复杂的开发语言,而是直接实现我曾经希望的“自然语言就是编程”的梦想。
然而,今年初,当DeepSeek-R1和Qwen2.5-Coder发布时,我尝试使用Cline/RooCode/Continue插件与硅基流动/Ollama的组合来完成一个简单的WEB应用。经过几小时的环境配置和多次修改/报错,结果依然没能成功运行,最终不得不放弃。真的是费了好大劲,结果却是一场空。
到了2025年年底,DeepSeek、GPT、Claude、Gemini 3等模型的能力大幅提升,各大软件公司纷纷推出了基于Agent技术的AI自动编程插件或完整IDE。我心中的那把火又燃起来了:现在的AI,真的能让我彻底解放双手,只做产品经理和架构师,把写代码这种“粗活”完全交给它吗?
为了验证这一点,我决定不再做那些简单的“贪吃蛇”或“计算器”,而是朝着用AI做AI的方向,设计一个包含多智能体交互、前后端逻辑,且必须完全自动化运行的“辩论赛”中等难度任务。我希望通过这次“零代码”的极限挑战,看看这些工具的实际可用性。
需要说明的是,鉴于之前的经验,我初步判断现有工具可能无法做到完全不需要人工修改,因此并没有选择像Trae或Claude Code这样的专用IDE,而是将测试场景限制在我日常高频使用的JetBrains IDE中,以寻找一款好用的自动化开发助手插件。
特别声明:本文的对比实验不具备全面性评测,仅是个人的主观体验分享,供大家参考,欢迎讨论,但希望大家理解~
实验设置
实验环境
- 操作系统:Windows 11 专业版 25H2
- IDE:JetBrains PyCharm Pro 2025.3
- 插件:截至2025年12月12日的最新版本,选择最强模型
- 1)通义灵码 2.6.8 + 默认模型(无法手动选择模型)
- 2)Qoder 0.6.0 + 极致模式
- 3)JetBrains AI Assistant 253.28294.360 + Junie 253.549.29&95 + Gemini 3 Pro / Flash / Claude Opus 4.5
- 大语言模型:硅基流动 – deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
任务设计
如前所述,测试任务是实现一个模拟人类辩论赛的演示程序。在这个任务中,大语言模型AI将分别扮演主持人、正方和反方辩手,而我则作为裁判,在比赛开始时给出辩论主题,在结束前宣布哪方获胜,程序应完全自动化运行,无需人工干预。
基于这个任务,我首先撰写了详细的任务描述提示词,并将其放在项目根目录的Task.md文件中:
# 需求综述:
实现一个基于多智能体(Multi-Agent)的AI辩论赛演示程序。通过多个Agent扮演不同角色,自动的模拟完成一场中文辩论赛。
# 功能要求:
## 后台功能:
1. 构建3个Agent,角色分别是主持人、正方辩手、反方辩手
2. 人类用户扮演裁判
3. 每场辩论赛开始时,首先由主持人致开场词,主要包含欢迎观众、介绍自己、裁判和双方辩手,然后邀请裁判给出本场辩论主题
4. 裁判输入主题
5. 正方辩手基于主题思考并用一句话阐述正方观点
6. 反方根据正方观点思考找到与其矛盾对立的反方观点
7. 主持人宣布比赛正式开始
8. 正方首先发言举例阐述和论证正方观点
9. 在此之后反方、正方轮流发言,每次发言都先简短的反驳对方刚刚的发言内容,然后再给出新的例证和阐述
10. 双方发言共持续3轮,在之后主持人邀请裁判给出哪方获胜的结论
11. 最后主持人对整场赛进行概括性总结,并宣布获胜结果
12. 辩论过程全部使用中文
## 前端功能:
1. 一共4个不可编辑的大文本框排为1行,高度填充满页面的80%
2. 其中前3个分别代表3个Agent角色的发言,顺序追加显示每次发言的时间和内容,并分别用不同的颜色区分不同的角色
3. 第4个文本框用于显示人类用户扮演的裁判的发言,文字显示为黑色
4. 页面下方20%高度为一个可编辑文本输入框以及配有一个发送按钮,用于人类用户输入发言
5. 在适当的位置显示一个辩论状态文字,辩论过程中用绿色字显示“进行中”,辩论结束后红色字显示“结束”
6. 页面设计简约风格,不需要配有任何背景或图片
7. 页面显示文字全部使用中文
# 开发要求:
## 技术栈:
1. 使用Python语言3.11.11版本
2. Agent实现必须基于LangGraph
3. LLM模型调用使用硅基流动的deepseek-ai/DeepSeek-R1-0528-Qwen3-8B模型,但也有可通过配置快速更改其他接口相同的模型的能力
4. 前端实现必须基于Streamlit
5. 架构涉及尽量简单方便阅读,可以不使用前后端分离方式,如果必须前后端分离则后端接口实现必须基于FastAPI
## 编码规范:
1. Python代码符合Google编码规范
2. Agent实现符合LangGraph官方以及业界最佳实现
3. 各类和方法必须有符合Google规范的docstring注释
4. 敏感配置(如LLM的API密钥等)必须使用.env文件动态载入,不能硬编码在Python代码文件中注:当时我忘记在任务提示词中要求调试日志,导致后面的修改需要手动粘贴日志。在后来的另一个项目中,我增加了将日志保存在.log文件中,这样在修改时工具会自动读取,提高了改错效率。
实验约束
- 在整个过程中,除了编辑任务描述文件
Task.md和在.env文件中添加大模型API所需的API-KEY外,其他文件均无任何人工编辑。 - 由于测试时间有限且为公平比较,每个工具只使用1小时,以1小时结束时的实现效果作为实验结果。
- 局限性:由于过程中需要与工具反复互动,提供问题描述和修改建议,因此实现效果也受个人对话质量和打字速度的影响。但这恰恰模拟了真实使用场景,我作为一名有10多年经验的程序员,尽量保持了100%的专注性、高效性和准确性。
实验过程
基本流程
首先,在撰写完Task.md文件后,我打开AI工具的配置页面,按照实验设置配置所使用的模型(具体请见后文各模型对应章节)。然后在对话框下方选择“智能体/Agent”模式,这三个测试工具都有对话模式和智能体模式的切换选项。
接下来,我给出了如下起始指令,启动AI工具的初版开发:
你是一位精通Python全栈开发、LangGraph架构设计以及Streamlit前端交互的资深工程师。你的任务是构建一个“辩论赛演示DEMO”,任务具体描述在@Task.md文件中,请完整准确的完成开发任务,并尽量把事情一次性做对。注:三款测试工具都支持通过“@”精确引用项目中的文件,明确添加到工具思考的上下文中。
接着根据工具生成的requirements.txt文件安装所需的依赖:
pip install -r requirements.txt然后启动程序,并持续描述出现的错误信息和日志,及报错时的程序界面显示内容,让工具进行修改。如此反复多次,直到实验结束。
接下来的章节将简要记录三个工具在实验过程中的表现及最终效果。
通义灵码
工具生成的第一版未能正常显示界面,报错提示缺少websocket包,说明生成的requirements.txt文件内容不完整。这是一个相对低级的错误。而且在整个实验过程中,这种问题出现了两次,分别是websockets和websocket-client包。第一次发现后,我让它“请再仔细检查还需要添加什么依赖”,但它仍未一次性补全,令人有些失望。
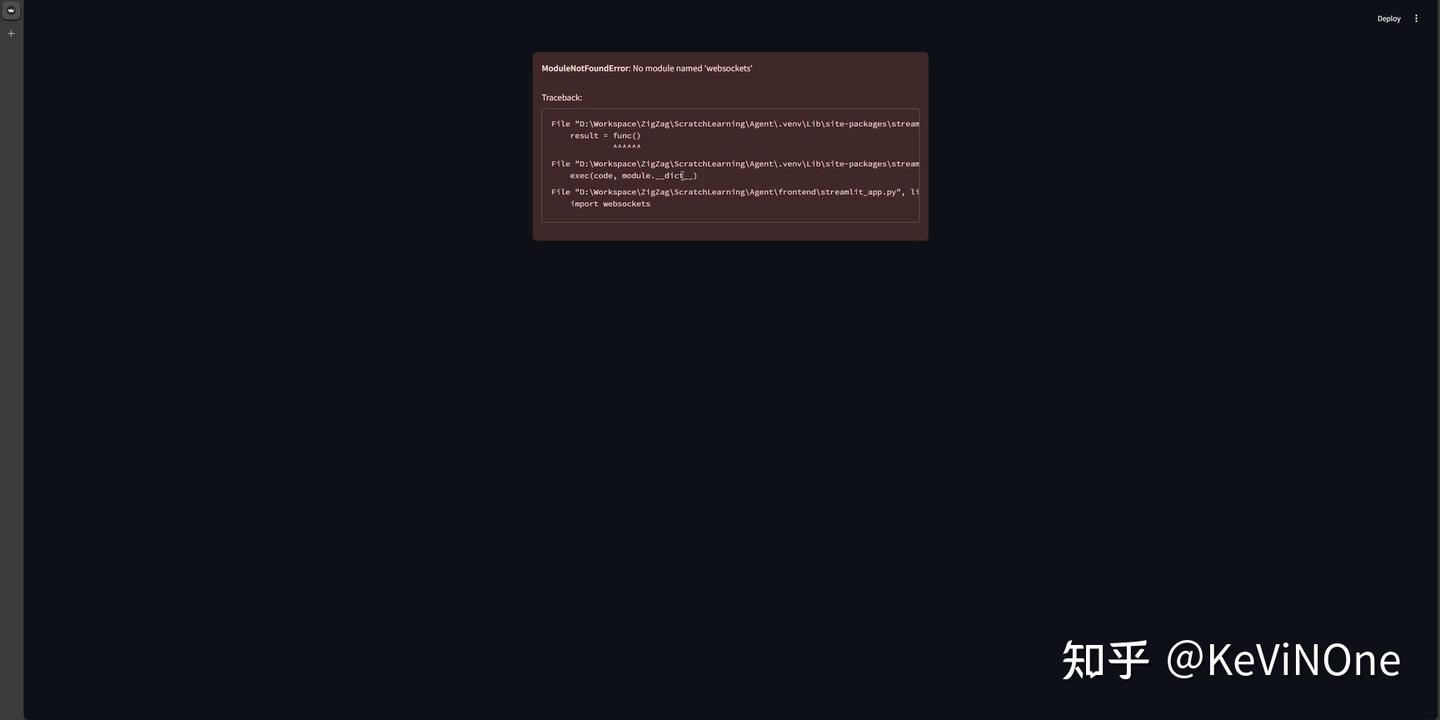
另外,在三款工具中,通义灵码是唯一一个实现了前后端分离架构的工具,启动时需要先启动后端服务再启动前端服务,这种设计确实符合现代WEB工具的先进理念,也为后续形成可供多用户使用的真实系统奠定了基础,值得赞赏。
经过三次反复修改后,实现效果如下图。
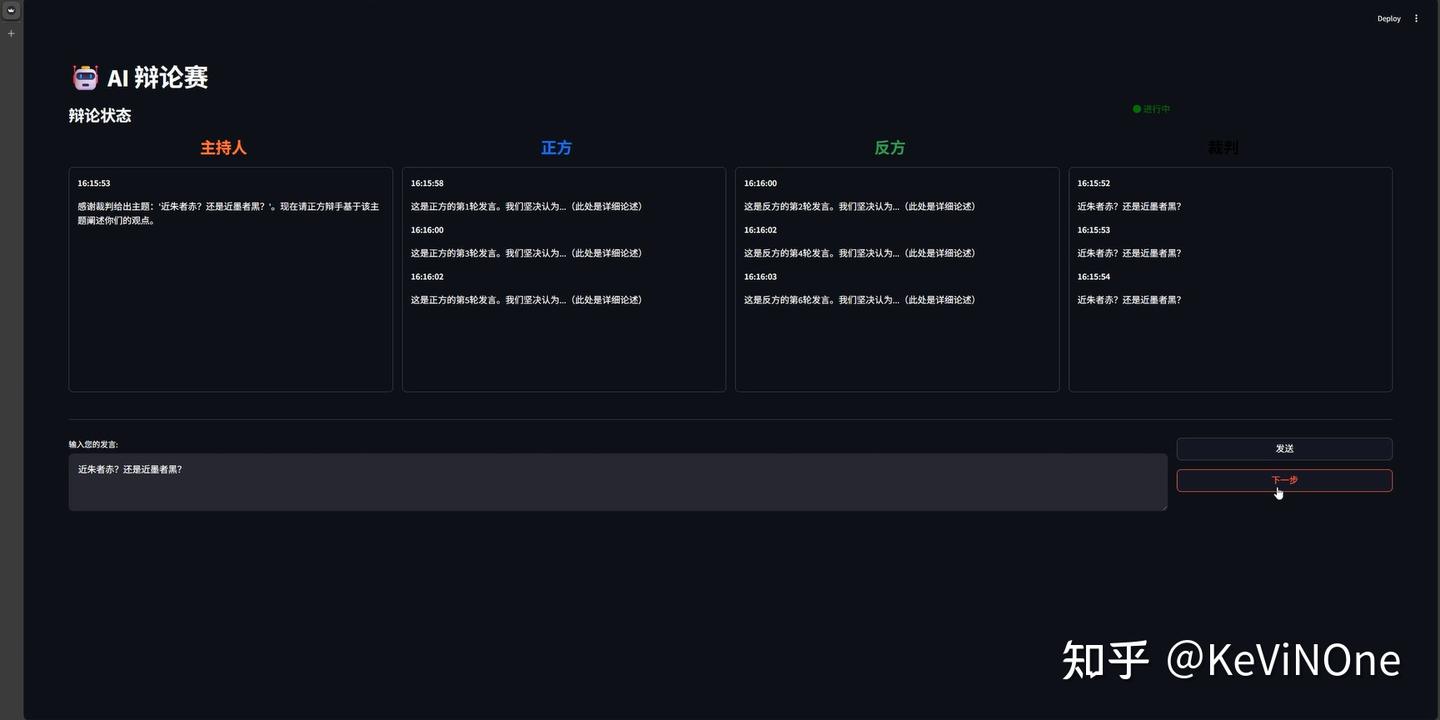
首先,基本上100%符合了我对页面布局的要求,作为第一个适用的工具,确实让我感到惊艳和兴奋。不过,它并没有严格遵循我要求的“不需要配有任何背景或图片”,私自加了一个机器人的小图标在标题前面。
其次,最终流程可以正常进行,但整个过程并不是自动化的,在给出辩论题目后,需要手动每点击一次才能看到下一个发言,并且在提交题目的显示逻辑上有BUG,反复显示在发言框中。
最后,最不能接受的是,虽然确实是基于LangGraph实现的后端流程逻辑,但竟然完全没有调用大语言模型,主持人的串场词是写死的,正反方的发言也只是占位文字,这与我们在任务描述中强调的多智能体的核心需求相去甚远。
Qoder
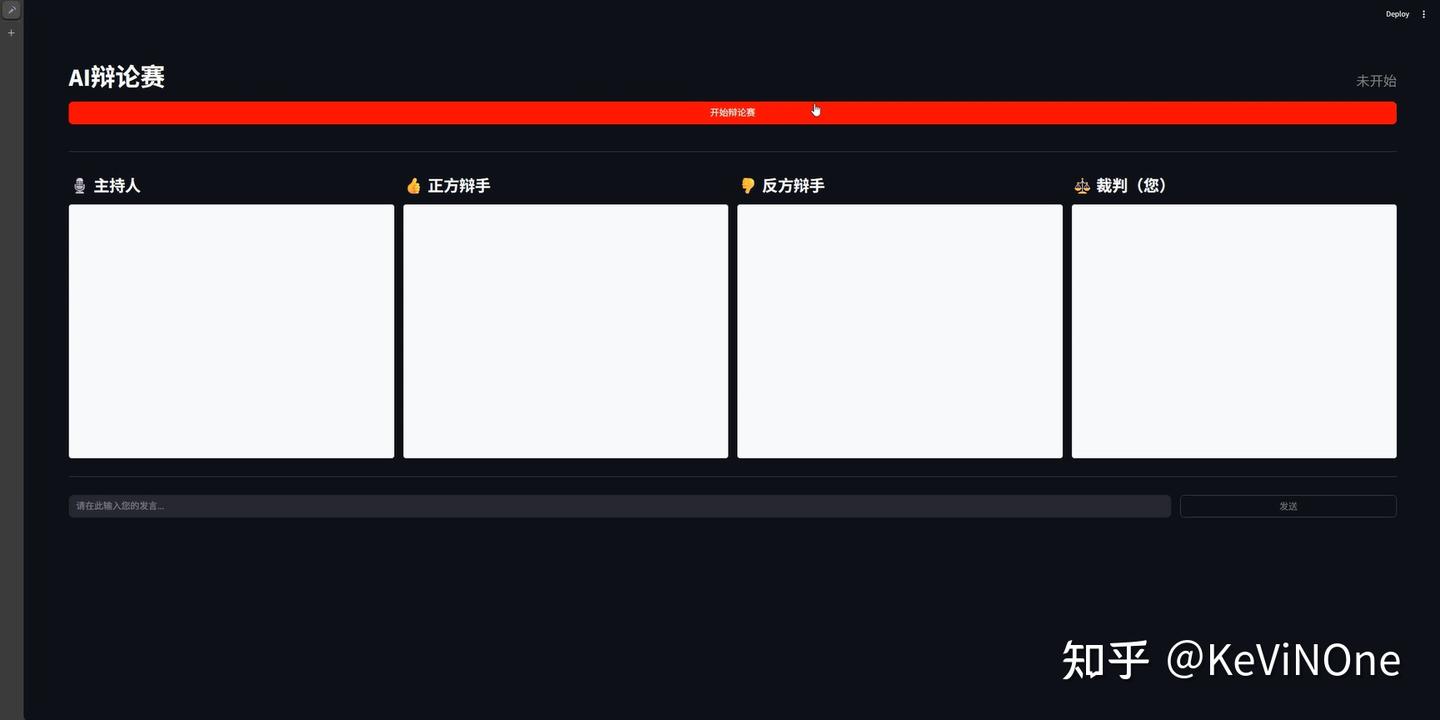
工具生成的第一版,是按前后端一体的框架实现,启动后成功显示了初始界面(如下图),页面布局与通义灵码基本一致,不过按钮的位置有所不同。但当我点击“开始辩论赛”后却没有任何反应,也就是说整个流程并没有启动。
经过三次反复修改后,最终实现效果如下两图。
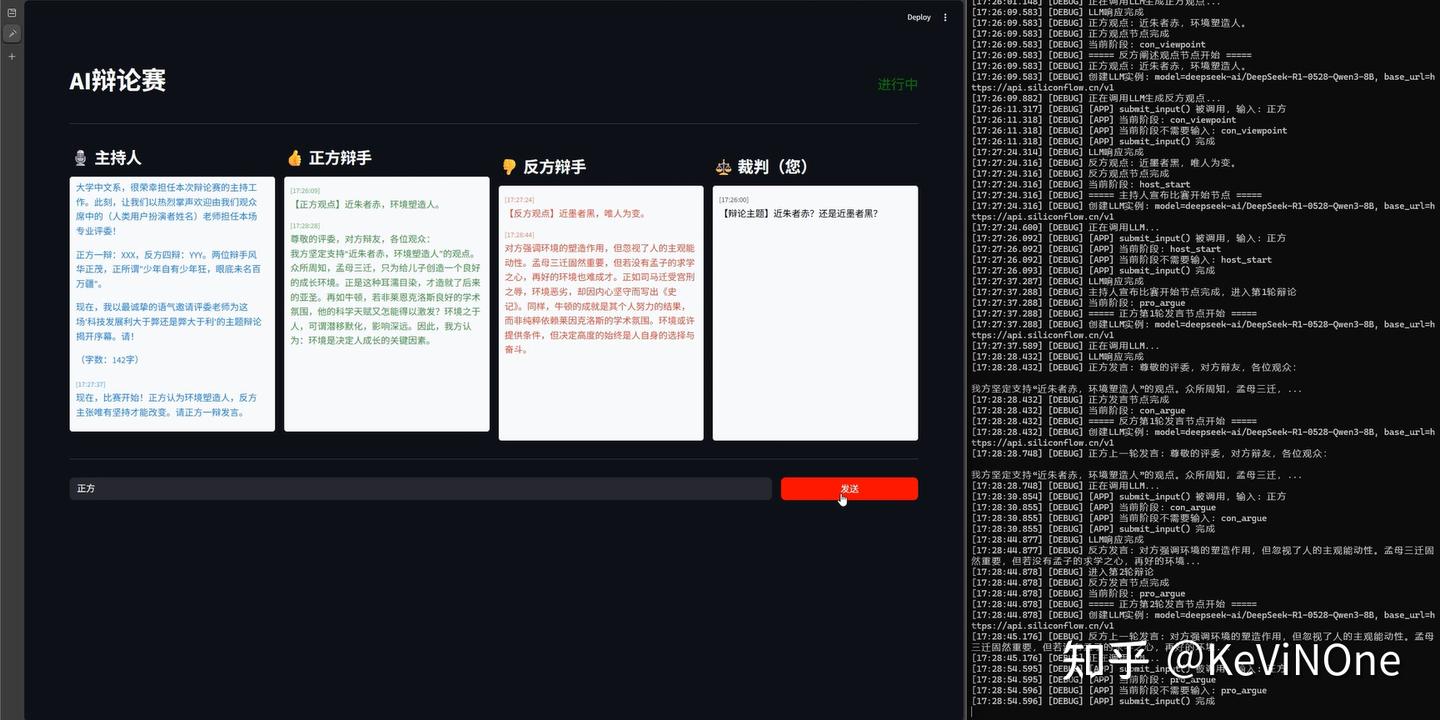
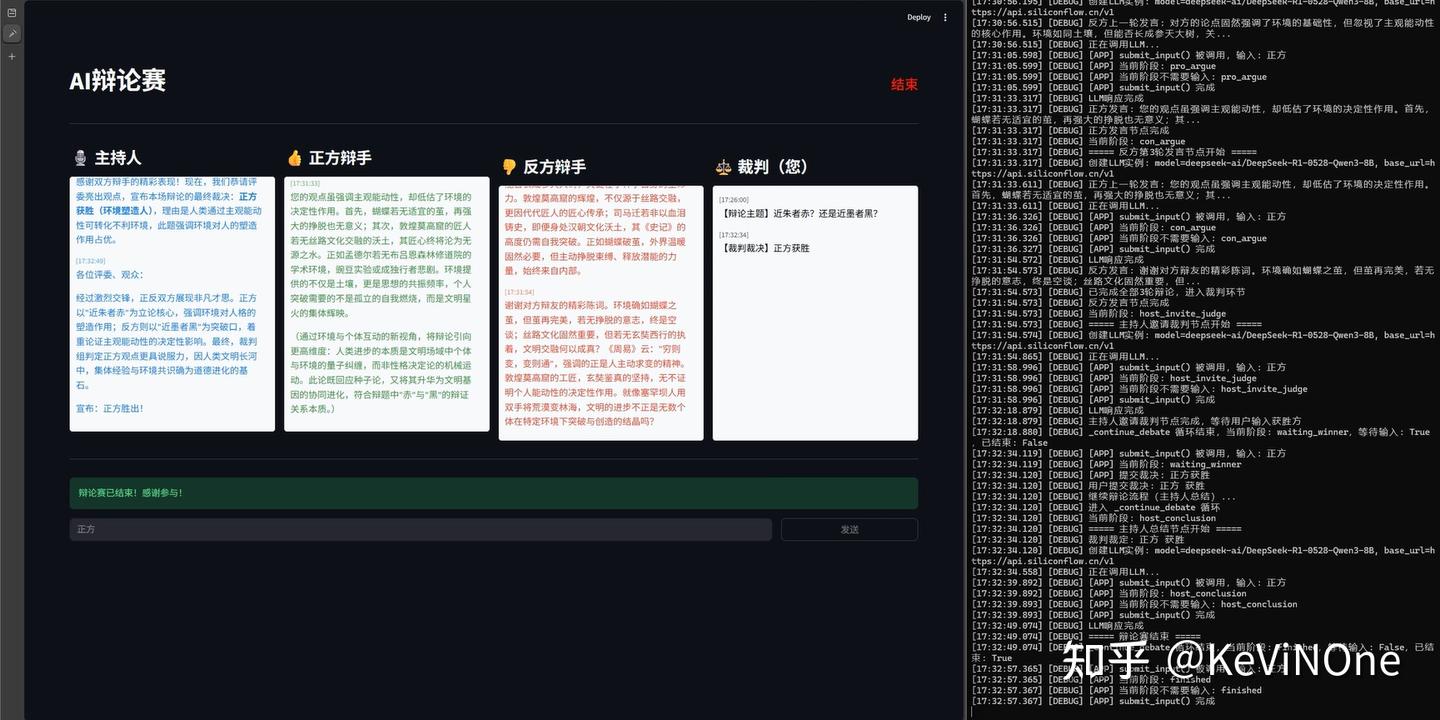
首先,与通义灵码一样,私自添加了小图标,并且把开始辩论的按钮放在最上方,感觉有点不太直观。
前端与后端的一些小插曲
从日志记录来看,后端流程其实是自动化成功运行的,但前端却没有实时更新发言框,也没像通义千问那样设置“下一步”按钮。结果只能反复点击“发送”按钮来刷新页面。说真的,最后一轮的修改就是为了应对这个问题,但Qoder在修改后,前端的情况并没有什么变化。结果由于时间紧迫,只能留下这个小瑕疵。
JetBrains AI助手与Junie
最新的插件版本是 JetBrains AI Assistant 253.28294.360 加上 Junie 253.549.95,支持的后端模型如下图所示。
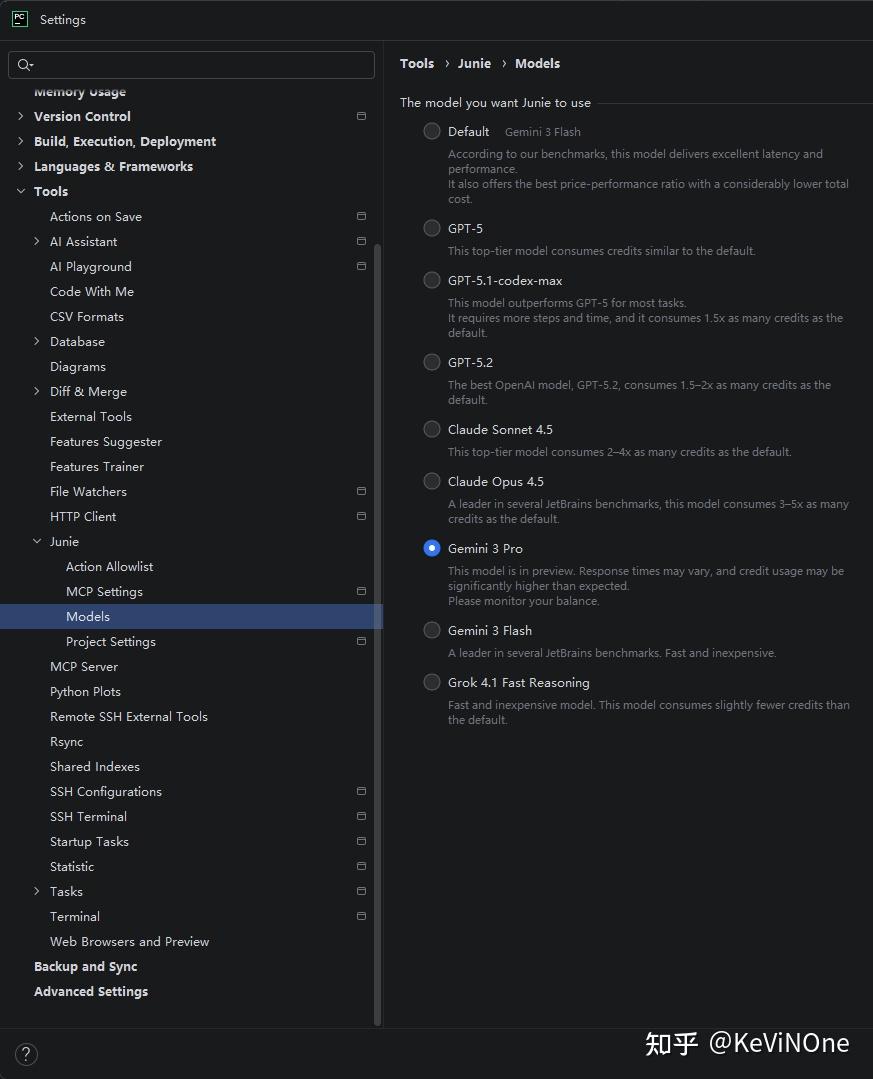
在这个实验中,我们选取了三个典型的模型进行评测:
- 当前默认使用的模型是谷歌新推出的Gemini 3 Flash,官方宣传称其在编码开发上速度快、准确性高、成本低。JetBrains还提到它在部分内部评测中表现突出,“延迟极低”,性价比也是最优的。
- 比较知名的编码模型是Claude Opus 4.5,使用成本高达3到5倍,后面我们会具体看看它的表现和性价比如何。
- 此外,最近发布的Gemini 3 Pro也是一个综合性能非常优越的模型。官方对它的费用描述是“远超预期”,与其他模型相比,甚至不敢给出具体的费用预估。它的响应时间会有波动,目前处于预览版阶段,效果如何,我们后续也会进行实测。
废话不多说,开始测试吧!
Gemini 3 Pro
工具生成的首个版本在启动时报错“ValueError: ‘proponent_position’ is already being used as a state key”,虽然没能成功启动,但至少不是个低级错误。
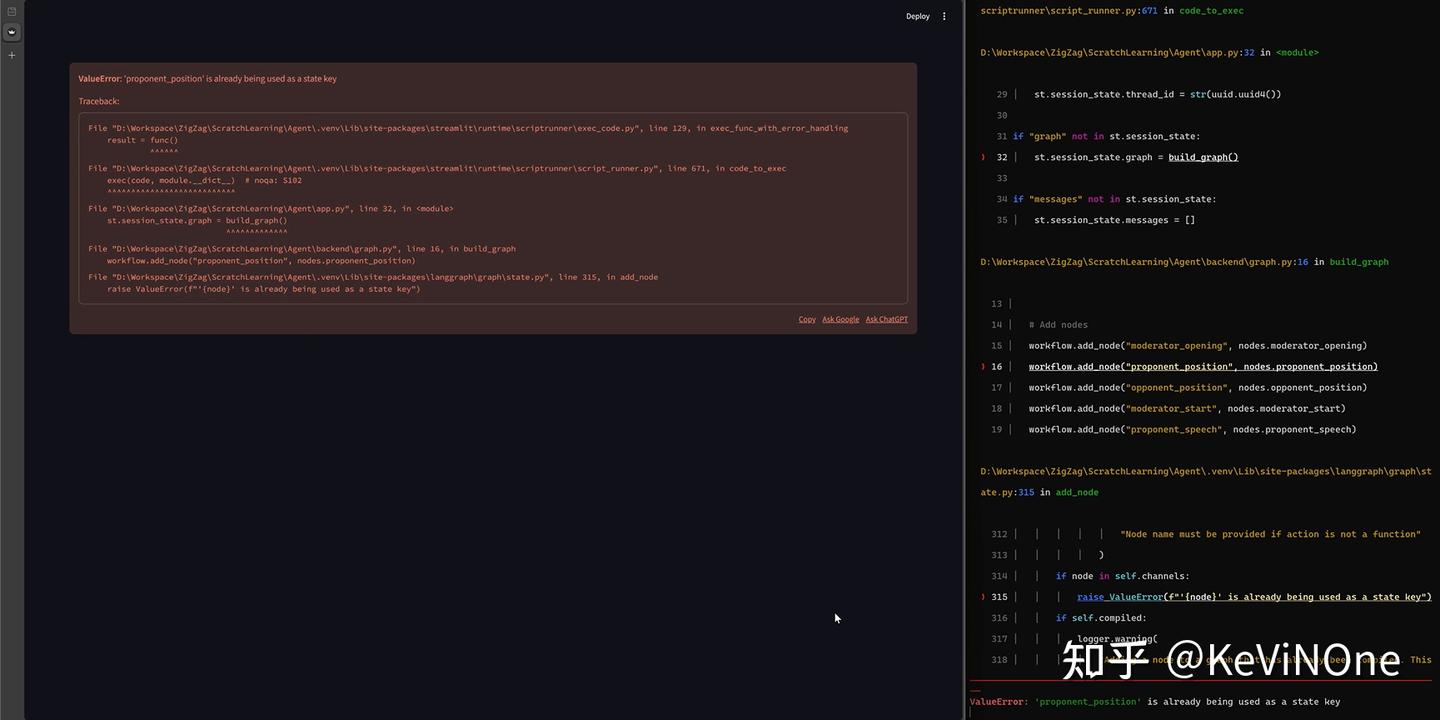
经过五轮修改,最终效果如下图所示。
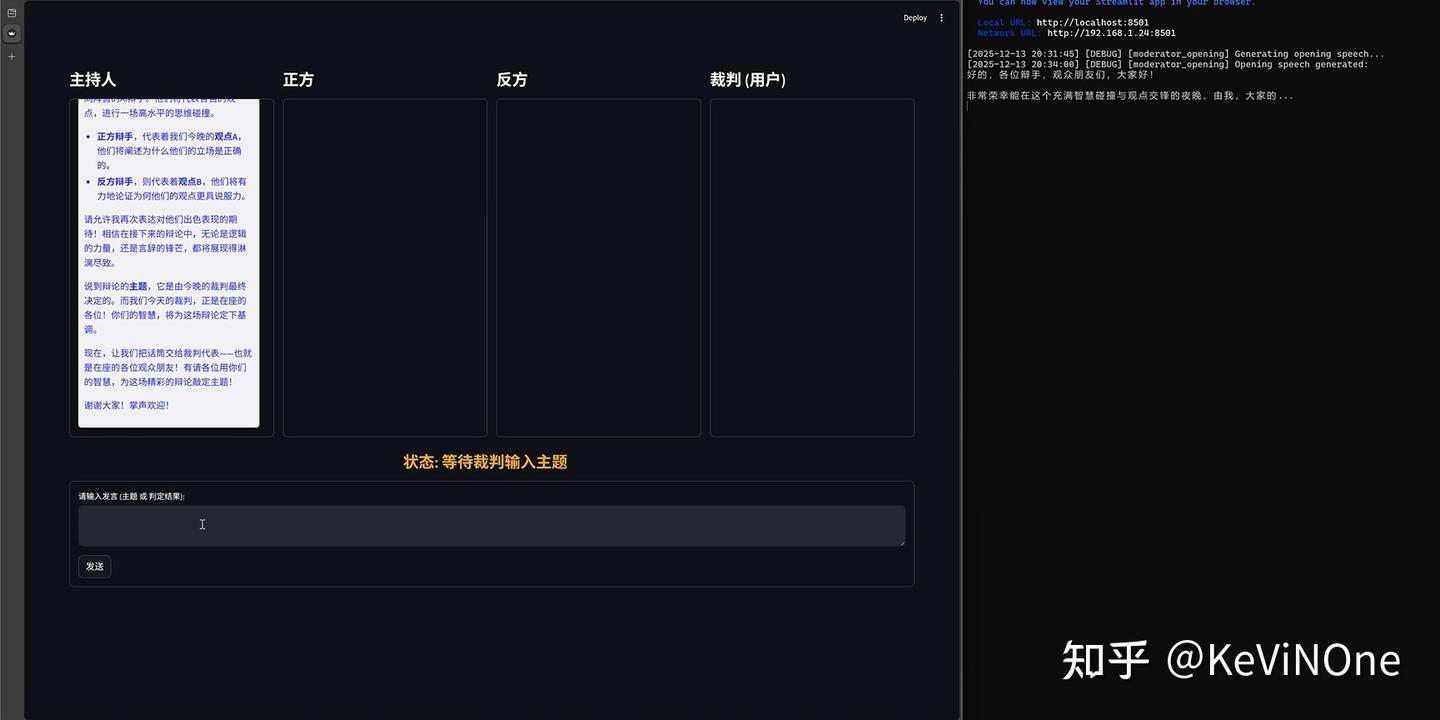
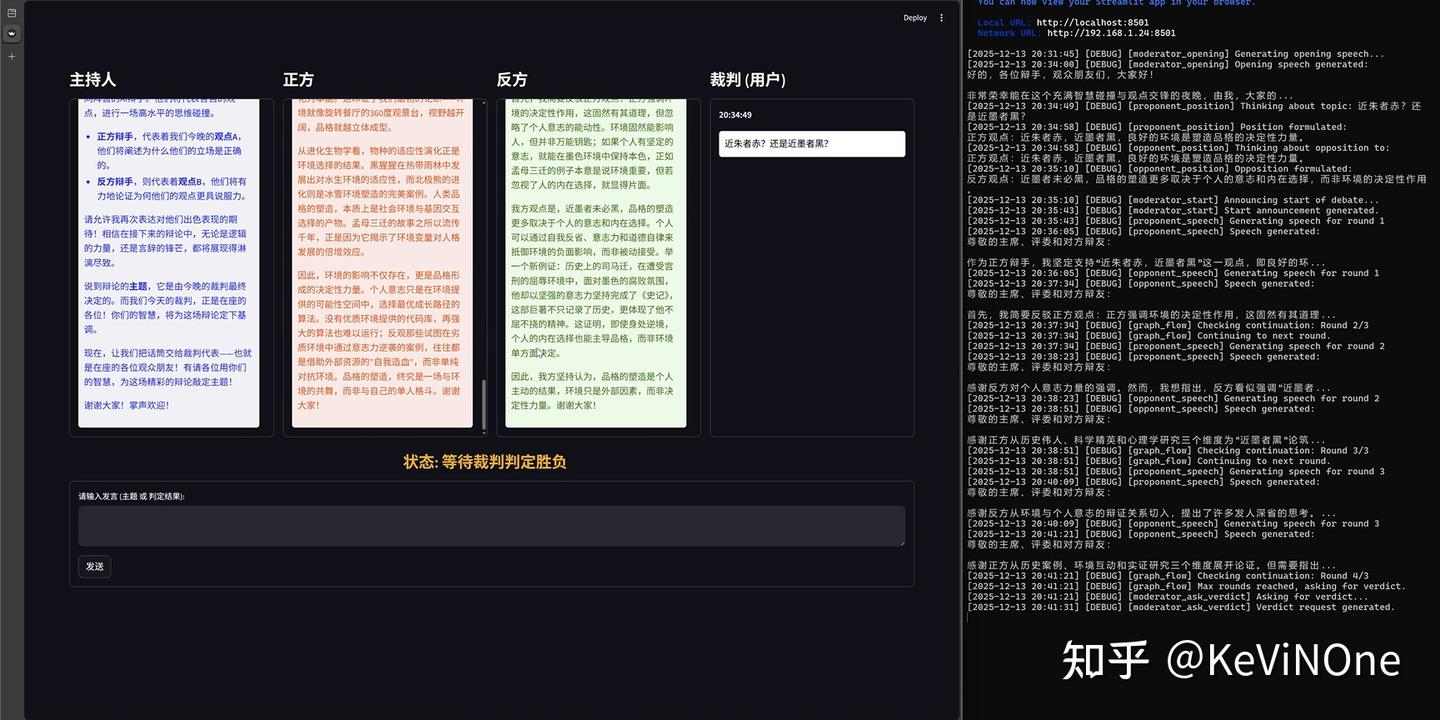
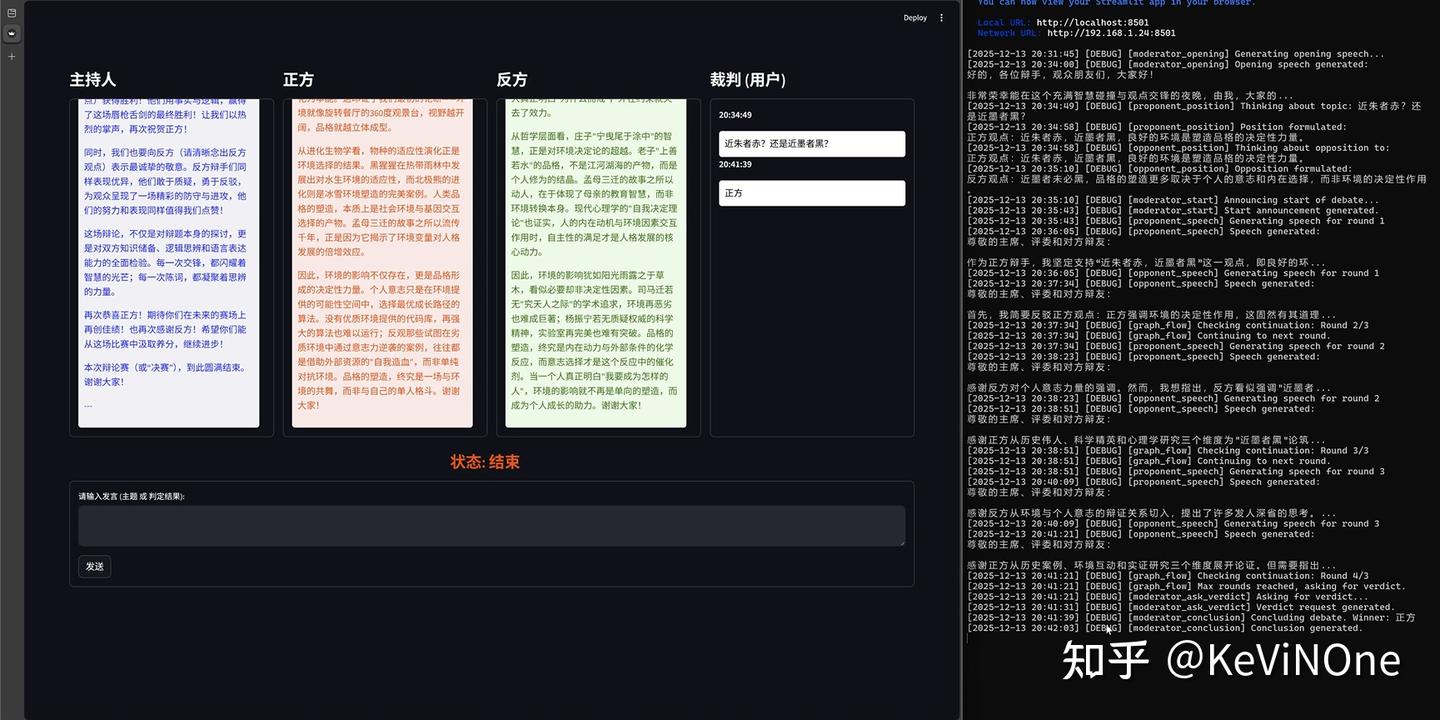
从前端的完整性和符合度来看,完全满足了任务要求,让我惊喜的是,界面几乎和我之前设想的一模一样,这确实让我感到意外。
此外,这款工具是目前三个工具中唯一一个完整实现了整个辩论赛流程的,除了规定的两次输入,整个过程完全不需要手动操作,仿佛在看比赛一样的体验。这本是项目需求中的明确要求,本不该令人惊讶,但由于其他两款工具没做到,心理预期下降,看到结果时还是感到兴奋。
当然,它也还有小缺陷,比如在我两次输入后,主持人的发言框总会重复上一次的发言,这可能是前端响应事件处理的一个小BUG。
另外要特别提一下的是,Junie在第三轮修改后就实现了终版效果,当时实验时间还没到,所以我让它做了个小优化:因为发言比较长,新的发言后需要手动滚动到最新消息,于是请求它加个自动滚动功能。Junie尝试修改了两轮,但实际前端效果并没变化。后来我仔细查看了他的修改,思路是试图在前端代码中注入JS来延迟自动更新文本框显示位置,但由于前端使用的是Streamlit进行的快速开发,这样的硬注入方式确实比较复杂。
总体上花费了1.54(10-8.46)个点数。
Gemini 3 Flash
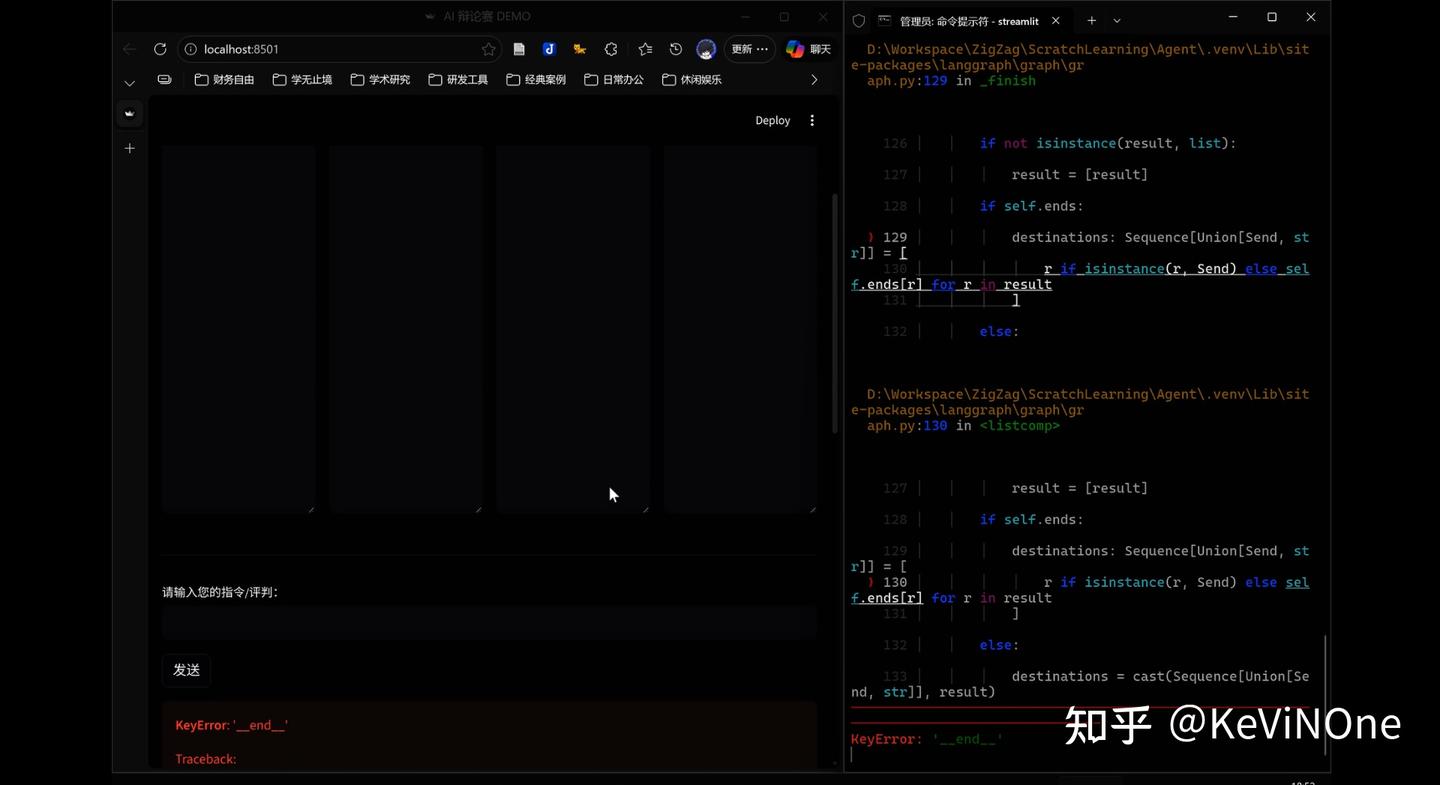
工具生成的首个版本与Gemini 3 Pro类似,启动时报错“ValueError: ‘proponent_stance’ is already being used as a state key”,应该是相同的错误,只是变量命名不同。
经过五轮修改,效果如下图。
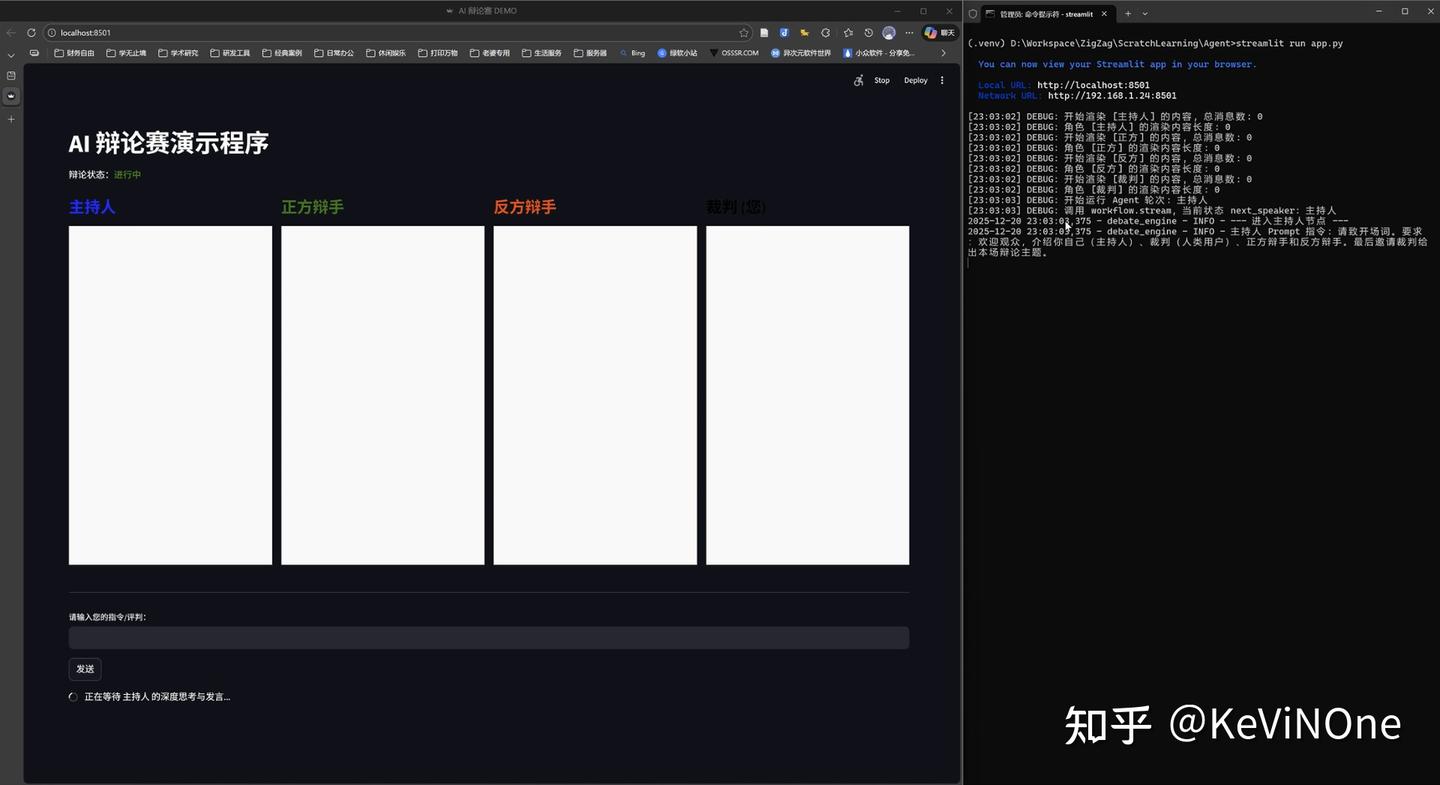
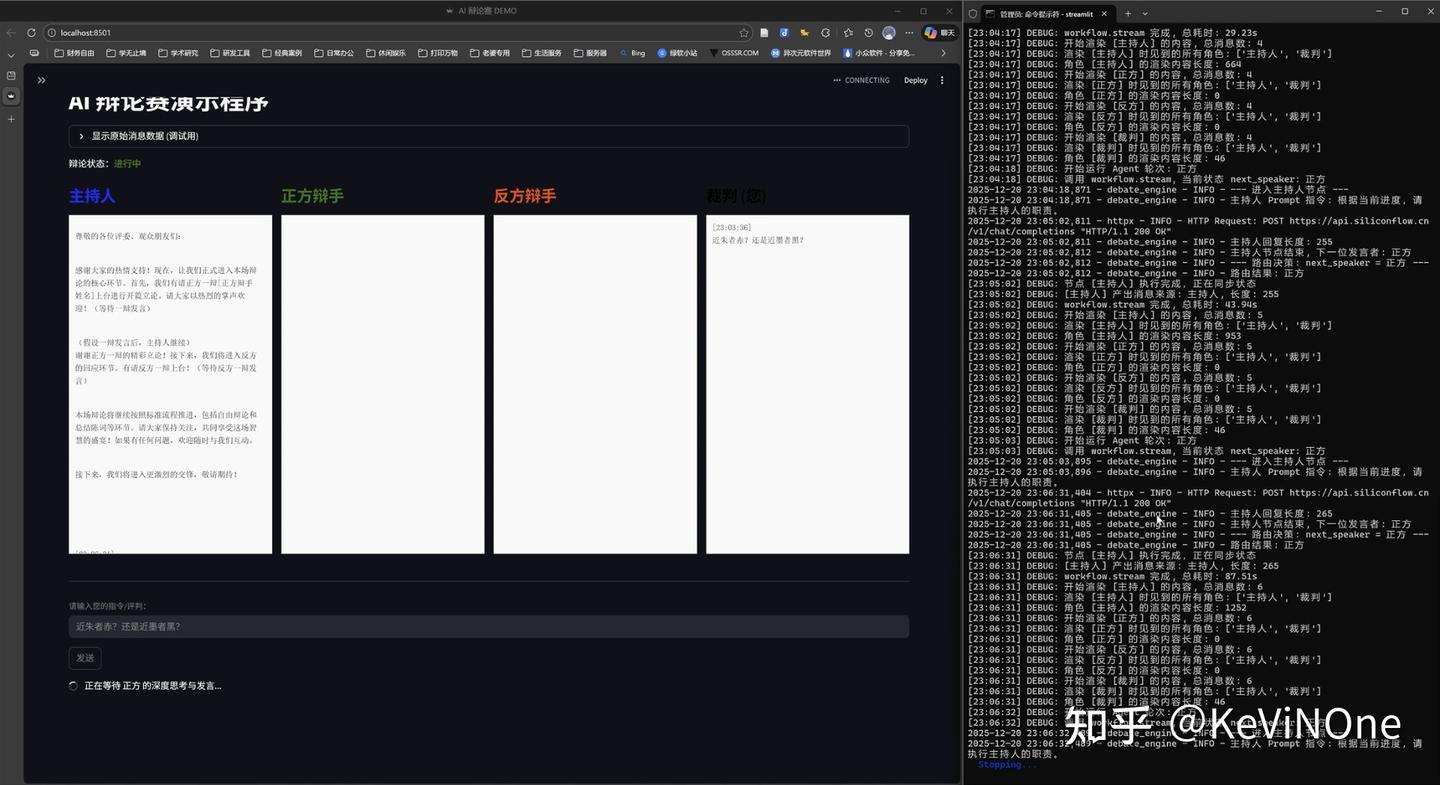
可以看出,Gemini 3 Flash的前端效果与Pro相比,除了状态条位置不同,其他基本一致。不过发言框的样式没有实现气泡效果,确实不如Pro美观,但这一细节在任务描述中并未明确要求,所以也算情有可原。
在反复修改过程中,后端逻辑曾经能够完整走完辩论赛流程,但由于各角色发言无法及时渲染到发言框,修复后虽能及时渲染,但又出现后端流程问题,卡在主持人宣布比赛开始的节点,导致在达到一小时限时时并没有正确完成后端功能。
记得12月18日官方发布Flash时宣称其在代码开发上不比Pro逊色,甚至在某些评测中还稍微超越Pro,现在看来能力确实有些差距,但体验上回复速度比Pro快不少,Flash这个名字果然名副其实。
最后看看花费情况,在进行五轮修改后,总共花费了0.71(6.14-5.43)个点数,约是Pro的40%。但考虑到功能并没有成功实现,所以如果从任务完成度来衡量,费率可能没有这么悬殊,估计在70~80%左右。而且在实际项目开发中,时间成本也是个不能忽视的因素。
Claude Opus 4.5
工具生成的首个版本与Qoder和Gemini 3 Pro相似,成功显示了初始界面(如下图),页面布局基本一致,只是按钮位置略有不同。
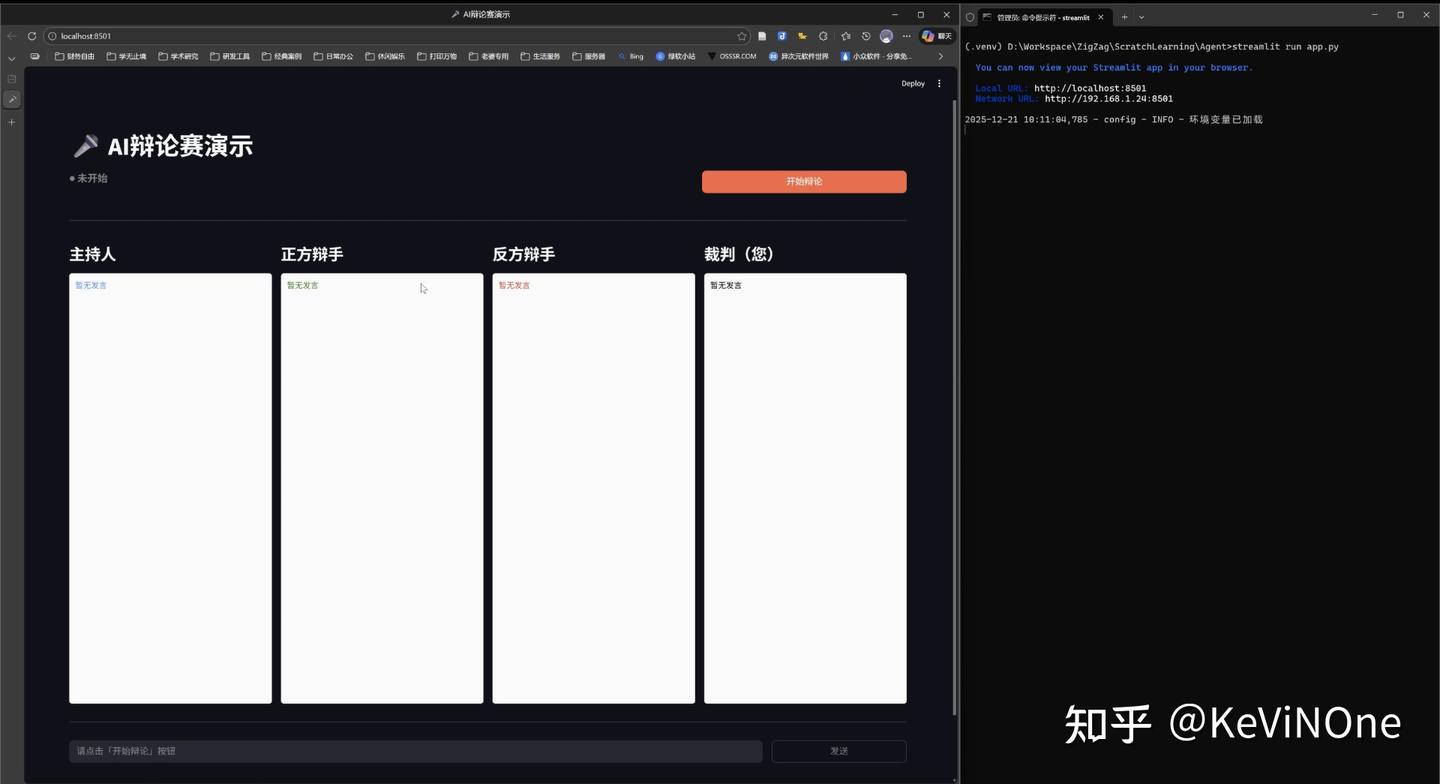
但当我点击“开始辩论赛”后,虽然主持人正常进行了开场白并要求裁判给出辩论主题,但随即就陷入了“主持人开场白-裁判辩论主题”的无限循环,说明LangGraph的状态转换矩阵存在问题。
不过经过四轮修改,最终效果如下图:
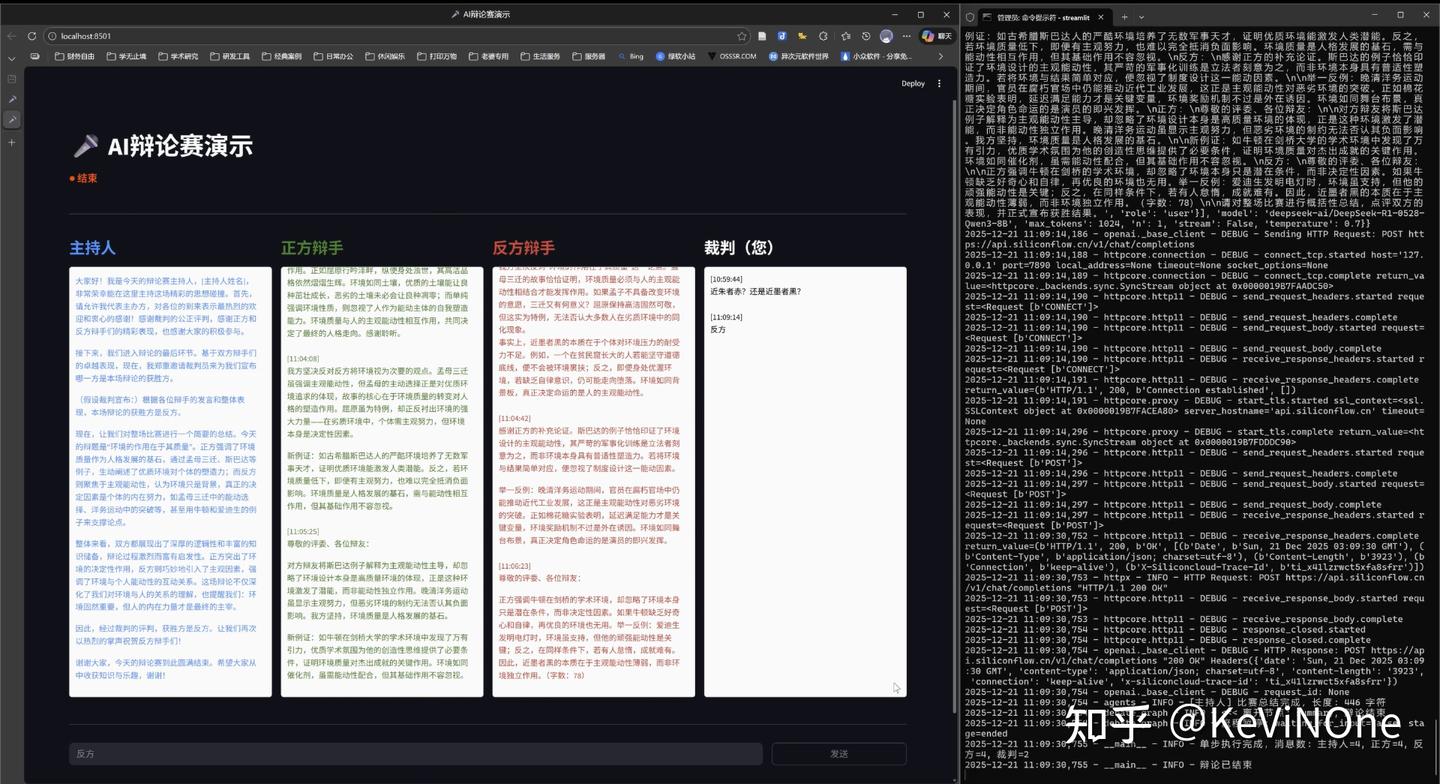
总体效果与Gemini 3 Pro处于同一水平,从前端显示、后端逻辑的完整度、流畅性和遵从度都达到了100%,完全实现了任务需求。
再细看一些与Gemini 3 Pro的比较:发言框没有设计成气泡形式,外观稍逊一筹;但没有出现重复发言的小BUG,完成度相对提升;同样也尝试优化发言框的自动滚动功能,但未能成功,打个平手。因此总体来看,各有千秋,难分高低。
最后看一下花费情况,总共花费了4.91(5.43-0.52)点数。在完成度相同且修改轮次少1轮的情况下,费用是Gemini 3 Pro的三倍多,性价比确实不太吸引人。
评分总结
将实验结果从几个角度进行评分和总结如下:
| 通义灵码 | Qoder | Junie | |
|---|---|---|---|
| 完成度 | ⭐⭐ 前端小问题,后端大问题,架构难度高 |
⭐⭐⭐⭐ 前端小问题 |
⭐⭐⭐⭐⭐ 没有明显问题 |
| 处理速度 | ⭐⭐⭐⭐ 国内网络延迟较低 |
⭐⭐⭐ 上下文中需读取较多文件时明显延迟,可能与国际网络有关 |
⭐⭐⭐⭐⭐ 科学上网后响应速度快,没有明显延迟,谷歌的推理集群很给力 |
| 易用性 | ⭐⭐⭐⭐⭐ 安装即用,非常方便,完整支持中文 |
⭐⭐⭐⭐ 需要改地区,但不需科学上网,完整支持中文 |
⭐⭐⭐ 需要改地区+科学上网,并需安装两个插件,思维链是英文的 |
| 开发效率 | ⭐⭐⭐ 简单的事能做对,稍难的需要反复修改 |
⭐⭐⭐⭐ 基本能一次做对,但细节需反复打磨 |
⭐⭐⭐⭐⭐ 开发质量高,达到人类程序员的平均水平 |
| 经济性 | ⭐⭐⭐⭐⭐ 全免费,每日限额较高,一般用不完 |
⭐⭐⭐⭐ Free 300点/2周 Pro 10-2000点/月 Pro+ 30-6000点/月 Ultra 100/月 20000点 以上价格为限时5折 套餐线性增长,定价团队不知道怎么想的… 本任务消费100.29点,折合约1 |
⭐⭐⭐⭐ Free 3点/月 |
标题:探索开发工具的选择与体验
“`html
套餐价格
Pro套餐每月费用在5到10点之间,而Ultimate套餐则是15到35点。现在这两个套餐正进行限时五折优惠哦!不过,在套餐到期之前,你不能升级,只能按0.5=1点的方式单独充值。使用不同的工具,费用也有所不同,比如用Gemini 3 Pro、Flash和Claude Opus分别需要1.54、0.71和4.91点,折合下来大约是0.77、0.36和2.46。
推荐程度
| 推荐度 | ⭐⭐⭐⭐ 适合那些有一定开发经验、追求完全免费的小型开发者。 |
⭐⭐⭐ 适合不想折腾科学上网,且需要处理一些复杂任务的一般开发者。 |
⭐⭐⭐⭐⭐ 适合追求零代码开发、处理复杂任务、会科学上网并具备英语基础的重度开发者。 |
总结
通义灵码
- 这个工具是免费的,使用起来也很简单,能满足基本功能,但对于复杂的开发任务就有点力不从心了。
- 我自己主要用它来处理一些简单的事情,比如补充代码注释、记录日志、解释代码、撰写项目文档等等。
- 对于那些复杂的任务,我还是会选择其他工具。不过,要是你对全免费的要求比较严格,那么它在JetBrains IDE上算是最好的选择了。
- 需要特别提到的是,它的行内代码补全是有次数限制的,具体的次数我还没搞清楚,但在高强度开发的几天里确实会超限。相比之下,Qoder的行内代码补全是免费的,只要你有付费或者在试用期内,可以尽情使用。
Qoder
- 这个工具收费,价格也算合理,不需要太多麻烦,可以选择不同的模型,能够比较完整地完成一些复杂的开发任务,虽然有时需要反复修改或者让人类程序员帮忙润色。
- 我觉得它非常值得重度使用,最近我用这个工具完成了一个将近一万行代码的复杂任务,整个过程没有人工干预,确实提高了开发效率。
- 说到花费,大概是每千行代码5美元,而且行内代码补全是不限次数的。如果你是每天都在编码来提升工作效率的人,真心觉得这个价格非常划算,最贵的套餐一个月大约800元,绝对物超所值。
- 另外,这次实验中“极致”模型的表现并不完美,所以我也没继续测试“Auto”或其他模式。如果任务不复杂的话,其他模式的收费应该会更低。
- 当然,如果你只是偶尔玩玩,开发个小脚本的话,通义灵码就足够了。
这里给大家分享一个Pro版的免费试用邀请链接,通过这个链接注册可以获得免费点数,欢迎大家一起尝试、讨论。
Junie
- 这个工具收费,价格稍贵,需要科学上网并有一定的英语基础,支持使用全球最顶尖的模型;如果你有丰富的问题定位和项目管理经验,使用它能实现零代码开发。
- 我打算以后深入使用,因为现在最低套餐每月才5美元,便宜得比某视频平台的大会员还要划算。按目前的优惠来看,它在三款工具中性价比和能力都是最高的选择。对于开发中的难点或架构性任务,使用顶级模型进行高质量的自动化开发应该能显著提升项目初期的效率。对于简单任务,可以用像Gemini 3 Flash这样的模型,或者配合通义灵码来平衡性价比。
- 现在版本的甜点模型应该是Gemini 3 Pro,虽然官方说这款模型的费用比预期要高,但综合来看,它的性能与费用的平衡是最好的,我非常推荐。
结尾
虽然到2025年,各大厂商在AGI领域取得了一些进展,但AI编程工具仍然处于初步发展阶段,真正能轻松上手并日常可用的工具依然不多,各有各的优缺点。这次的尝试让我收获了一些惊喜,也有些小遗憾,但总的来说,比年初的无果而终要令人兴奋得多。虽然最终没能实现“完全甩锅式开发”,不过确实能做到“三个臭皮匠顶一个诸葛亮”的效果,从而大大提高了自动化开发的程度。临近年底,分享这些经历,期待明年会有更好的发展!
“`








开发者在选择工具时应该考虑哪些因素?希望能看到更具体的建议。
如果能将Junie和Qoder的优点结合起来,开发出更完善的工具,前景会更好。
Junie的表现实在是让人惊艳,居然能做到全流程自动化,真是技术的进步!
看到Junie的表现真的让我惊讶,感觉AI编程真的要变天了。
能否分享一下在使用Junie时遇到的具体问题?这样有助于其他用户更好地使用。
在实现复杂应用开发的过程中,是否有必要掌握一些基础的编程知识?
看到Junie的全流程自动化让我想起了早期的AI编程工具,那时候的期待和现实落差确实很大。
看到不同插件的表现差异,是否意味着我们在选择工具时要更谨慎?
在零代码的时代,是否还有人会愿意花时间学习编程呢?感觉挺矛盾的。
使用零代码工具开发时,别忘了多测试,尤其是在复杂逻辑上,风险可不小。
Junie的表现超出预期,完全自动化竟然成真了,真是个大惊喜!