说到AI编程提效这事儿,我还真有话要说。今年上半年,我作为24届JDS,接手了两位离职同事的业务模块。面对密集的促销需求,我不仅要单挑“以一当三”的交付压力,还得确保线上零事故。而这一切的背后,得归功于Cursor的强大支持——我的订阅从去年的Pro升级到Pro+,在大促和黑马程序员大赛期间,我甚至每月花200美元升级到Ultra Plan,只为提升开发效率。
接下来,给大家分享一些干货:
Cursor实战案例展示
在过去的一年里,我用Cursor开发的一些前端项目,展示给大家。这些页面中,AI生成的代码占比超过60%。业务场景涵盖了B端和C端,技术栈也覆盖了Vue、React等多种方案,真是体现了Cursor强大的技术能力与显著的效率提升。
移动端
京粉app的H5页面,就在中秋前夕的晚上10点,业务来电要求做一个中秋推广活动页。我用豆包生成背景图,再用Cursor设计样式,0到1的开发仅用了两个半小时,凌晨0:30就上线了:
扫码查看
信息流广告中间页,UI提供的初版Lottie动画是个完整的页面,没法拆分。由于大促排期紧张,等待UI支持的时间又长。我于是利用Cursor解读Lottie的JSON配置文件,成功将火焰、杀价、折扣等核心动效元素拆分成独立动画,并用CSS实现,既降低了资源体积,又优化了动画效果,让协同工作顺利通过了卡点:

PC端
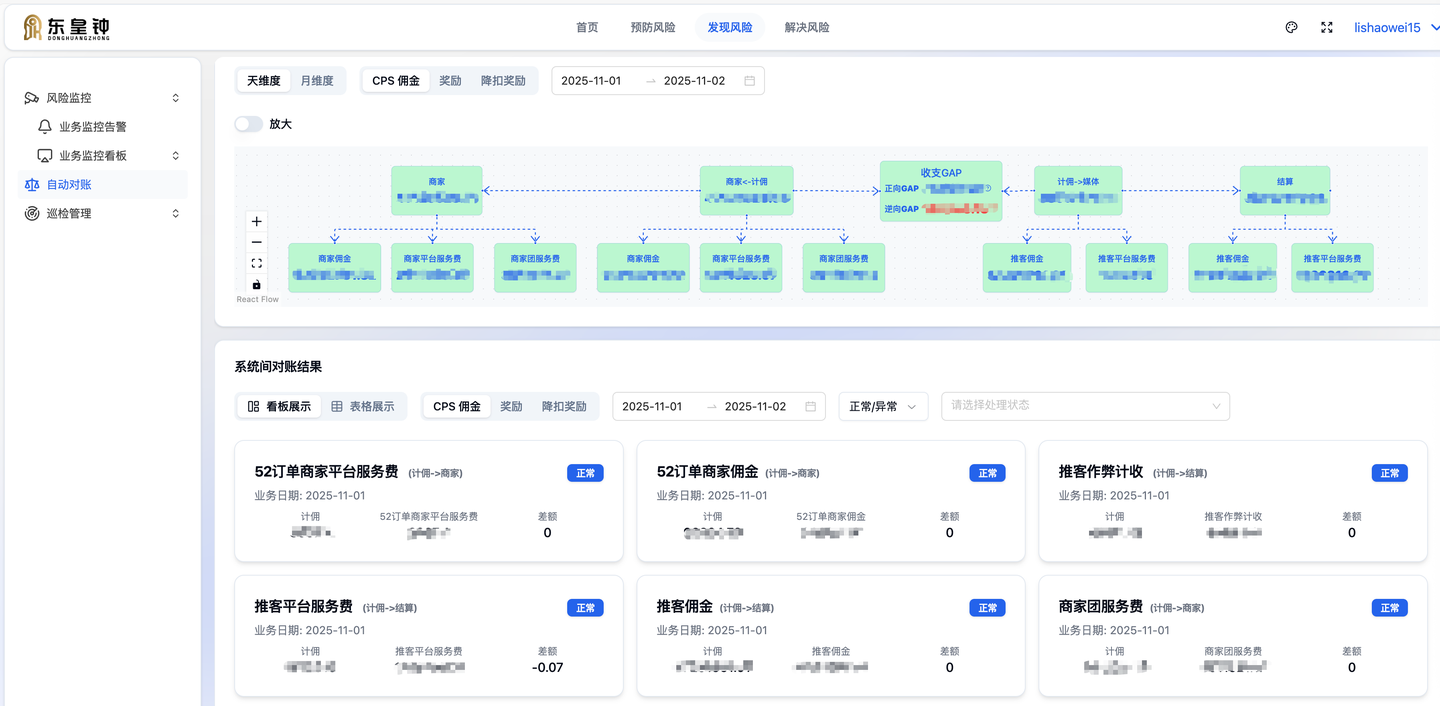
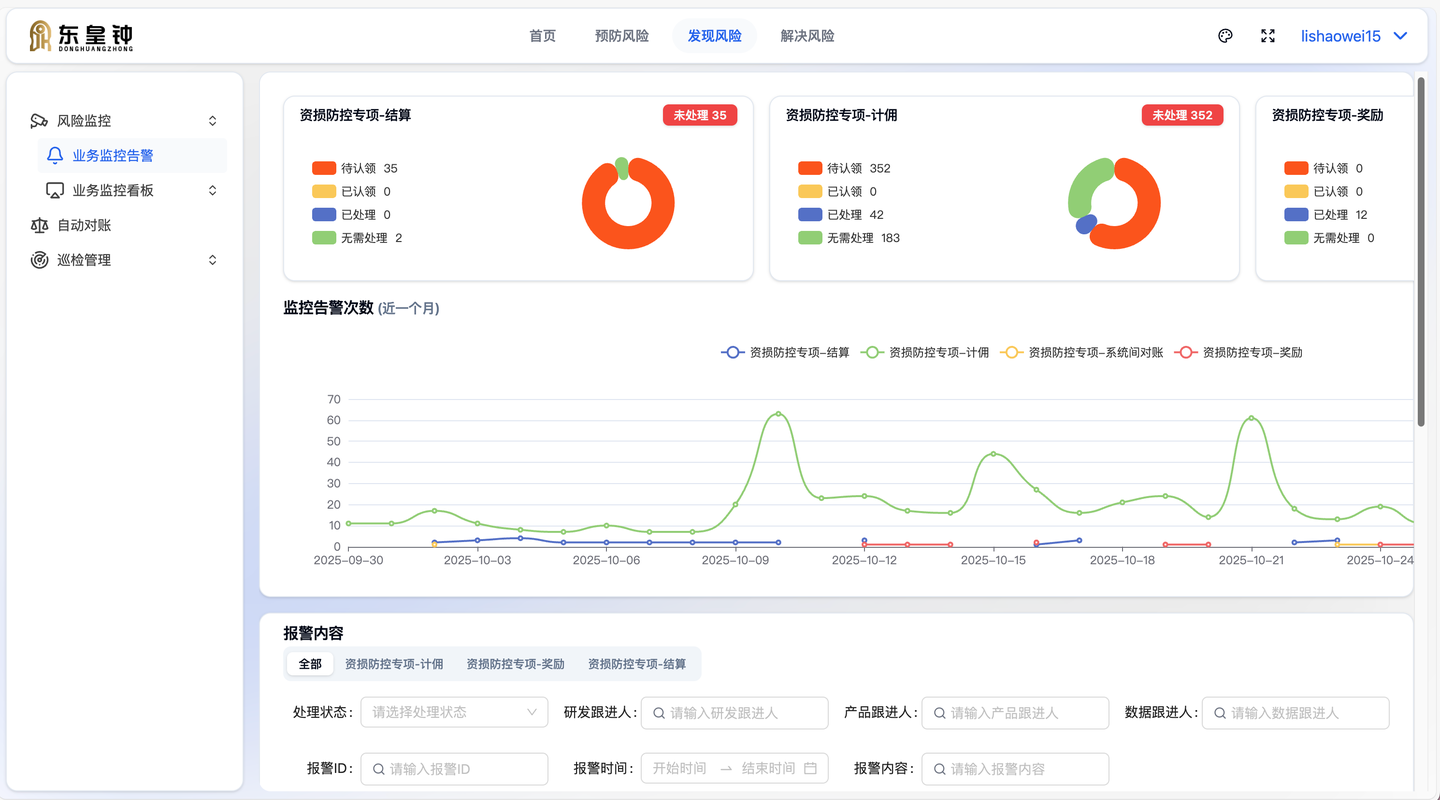
东皇钟资损防控平台,这个项目是由研发发起的,我在没有产品原型和UI设计的情况下,利用Cursor和Shadcn UI,独立完成了平台的交互与界面构建,最终得到了后端和测试团队的一致好评:
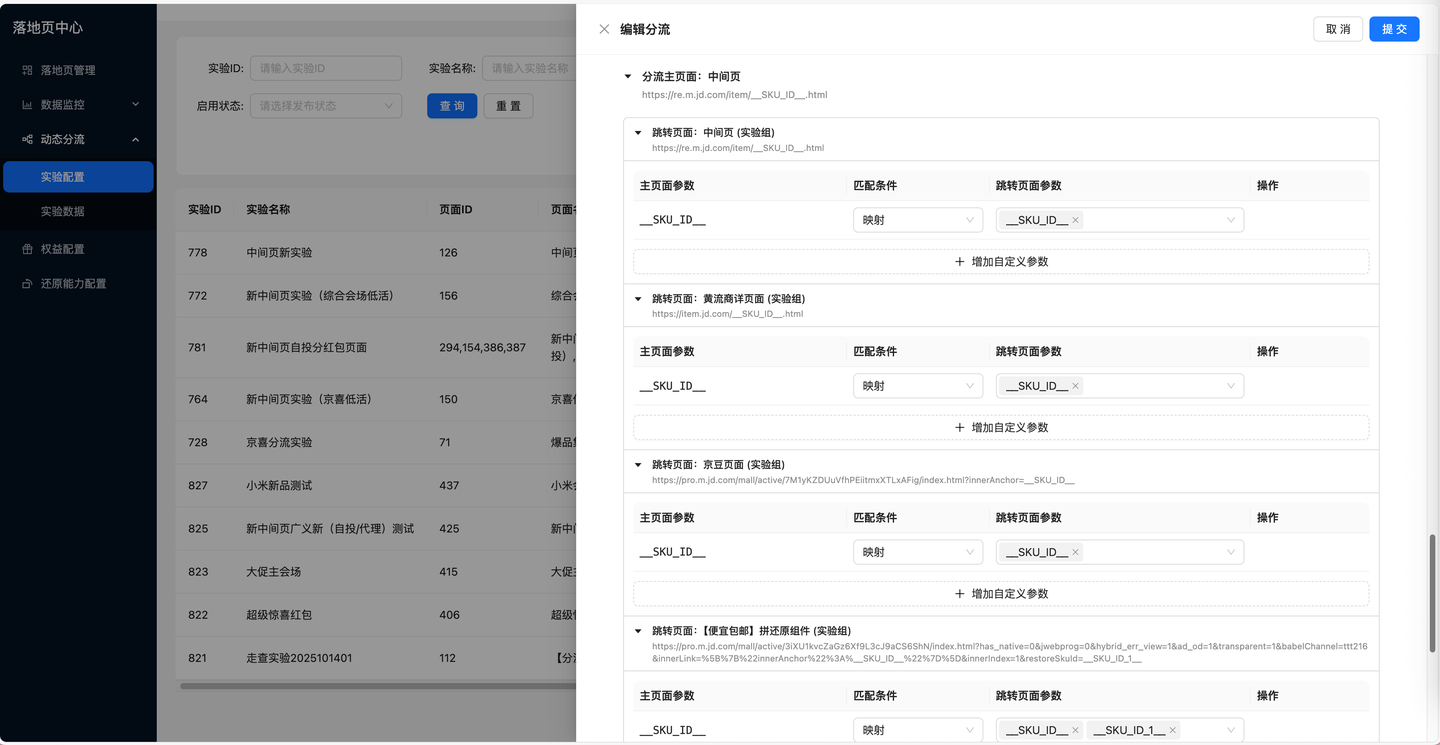
落地页中心动态分流,这个模块的核心代码接近万行,表单联动逻辑复杂,完全由Cursor生成。面临5层以上嵌套的数据结构,手动理解层级关系并控制动态联动不仅难,还容易出错。通过Cursor深入解析数据结构和联动逻辑,显著降低了研发的理解成本,提升了整体开发效率。

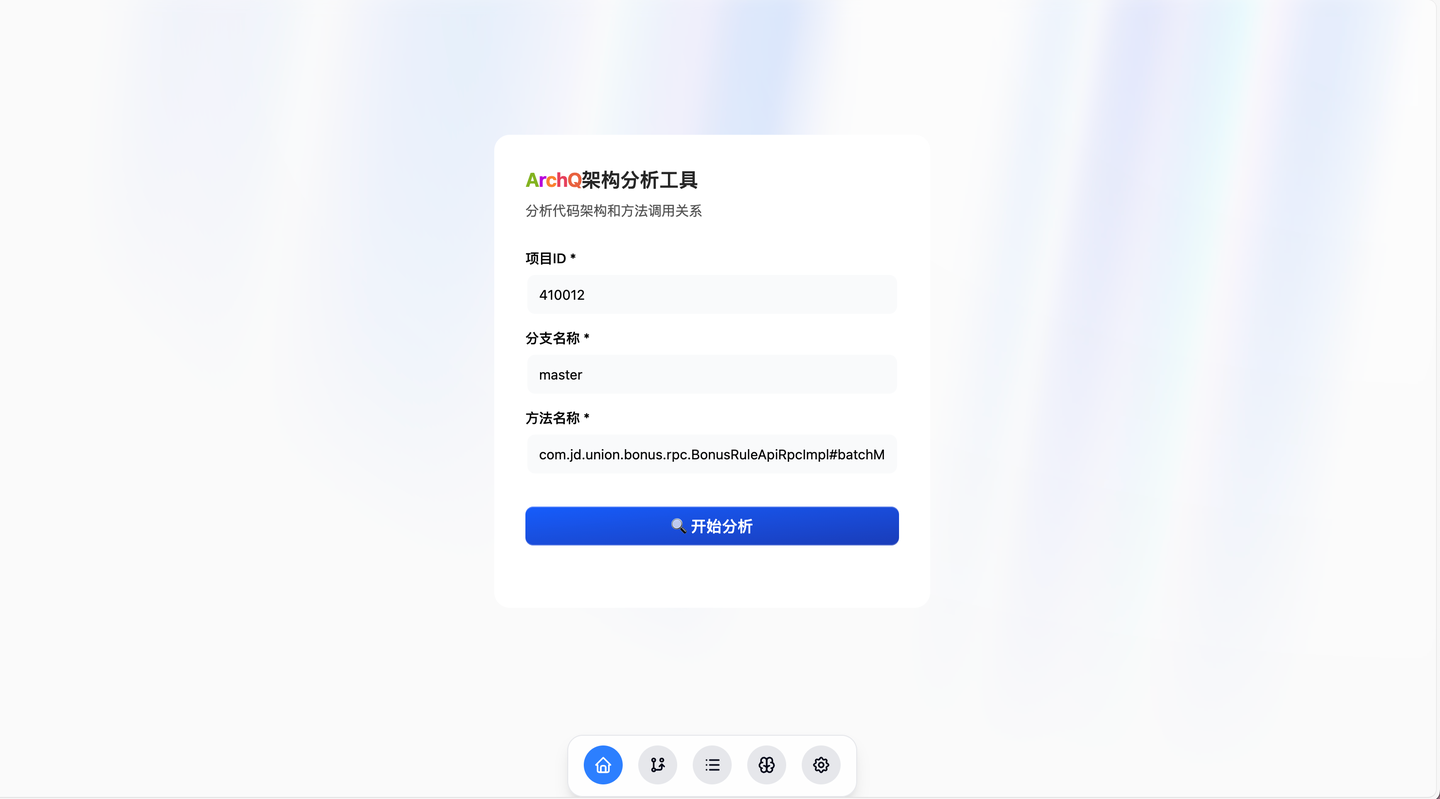
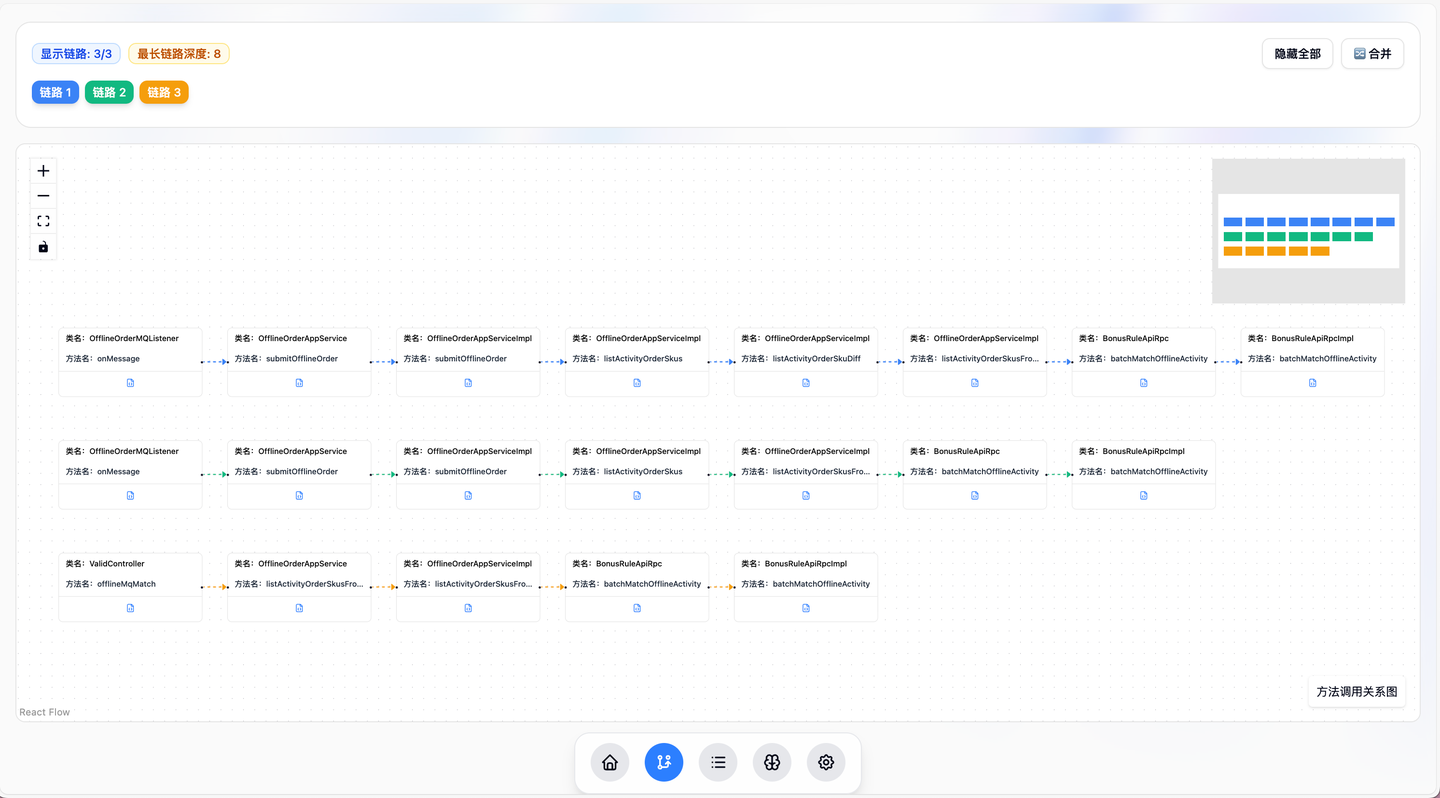
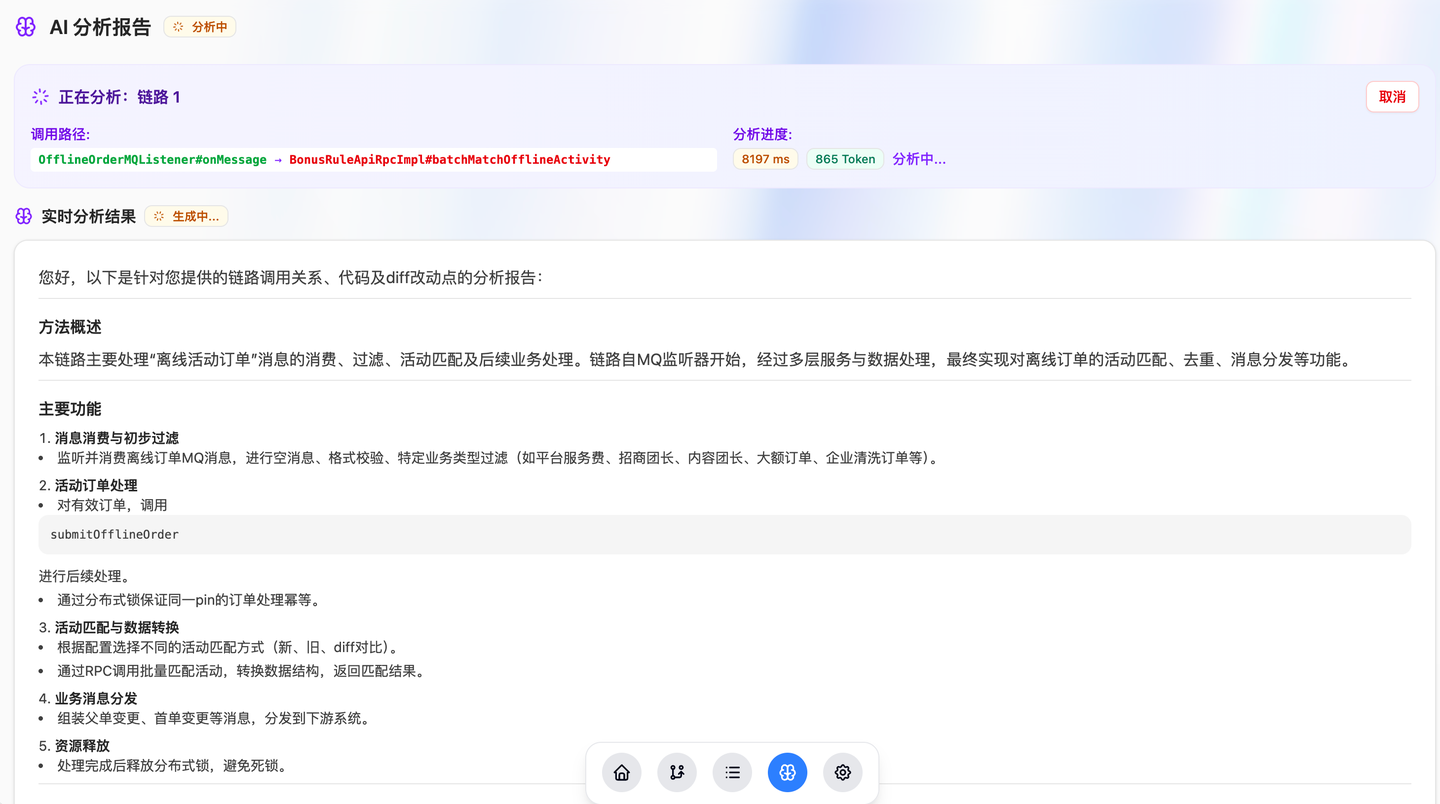
精准链路分析项目,这是我在黑马比赛中的项目,基于Cursor从零开始,仅用两天就构建出功能完备的精美Demo。项目实现了基于React Flow的JAVA调用链路展示与组合、AI流式报告和智能Agent对话等多种高级功能。
工程化
工程化一直是前端领域的一大挑战,常常被版本冲突和复杂配置搞得头大。为了验证Cursor处理系统级任务的能力,我试着把整个升级流程交给它来主导:从依赖分析、版本管理到工程配置更新,直接让它操控终端,执行npm命令。
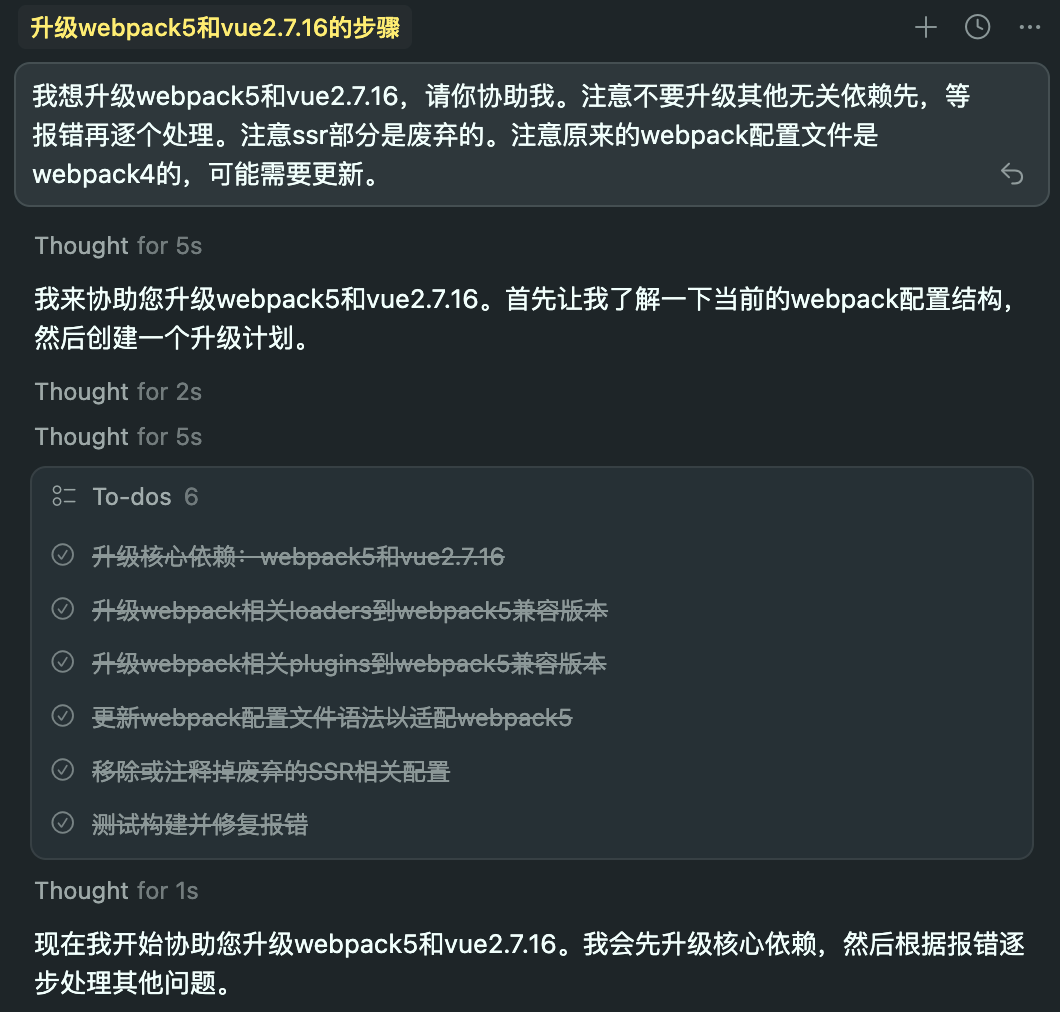
在京粉App H5项目中,我基于Cursor成功完成了从旧版本到Vue 2.7.16 + Webpack 5的全流程升级:《京粉App H5升级Vue 2.7.16 + Webpack 5记录》
Cursor提供的升级方案(部分对话):
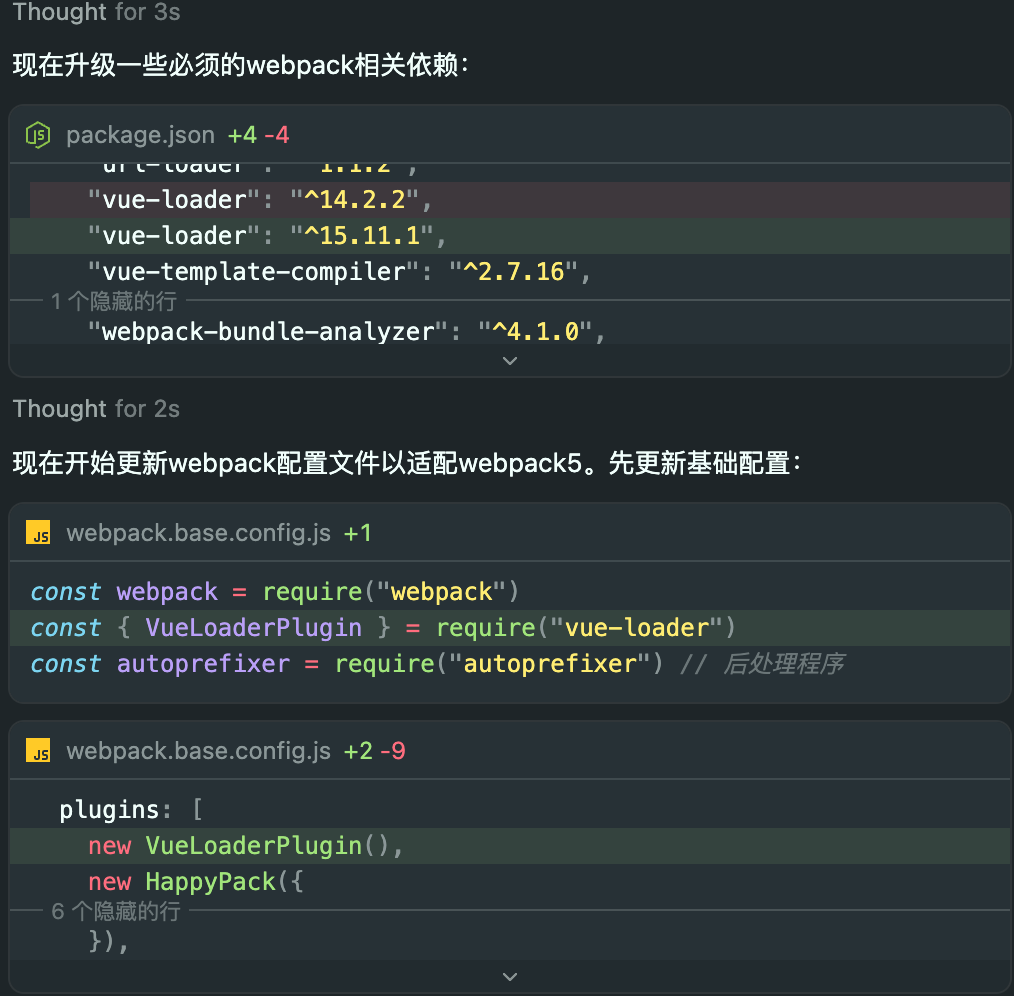
更新依赖版本和配置文件(部分对话):
自动执行终端命令与修复报错(部分对话):
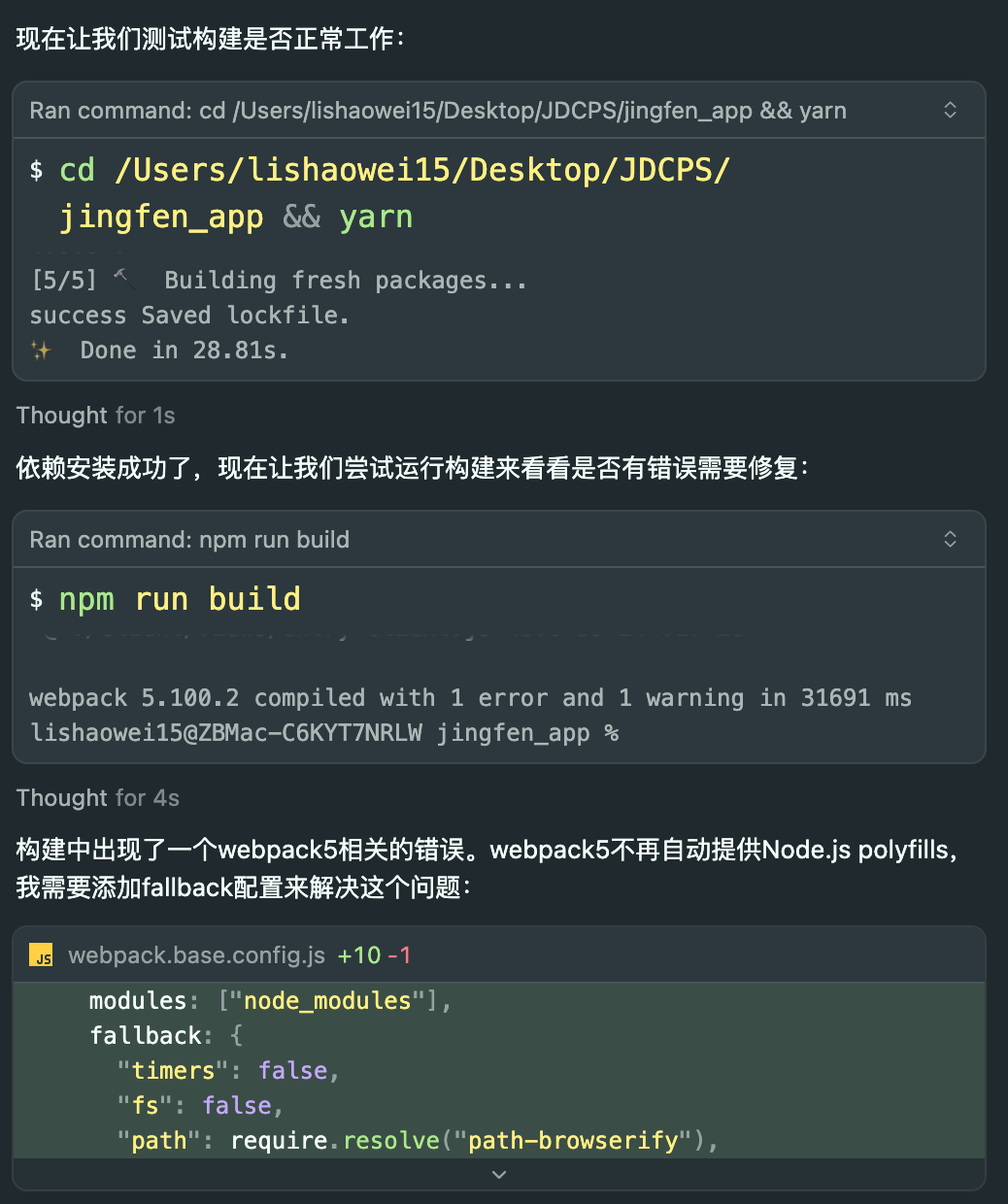
此外,我还让Cursor实现了京粉H5从Webpack到Vite的迁移路径验证,核心构建流程已经全部跑通。虽然因为一些边界场景的报错尚未完全解决,没法形成正式文章,但这次实践初步验证了Cursor在复杂工程链路中的可行性。
Cursor使用经验分享
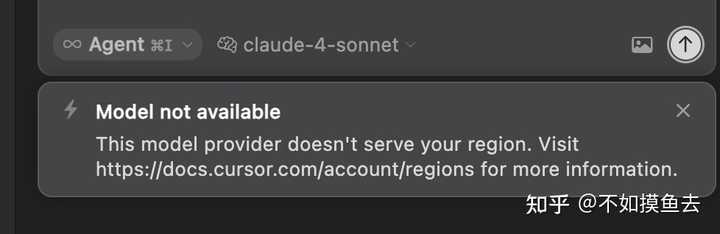
最重要的:模型选择
模型是AI的基础,基础不牢,地动山摇。这里直接给大家一个结论:毫不犹豫选择Claude。
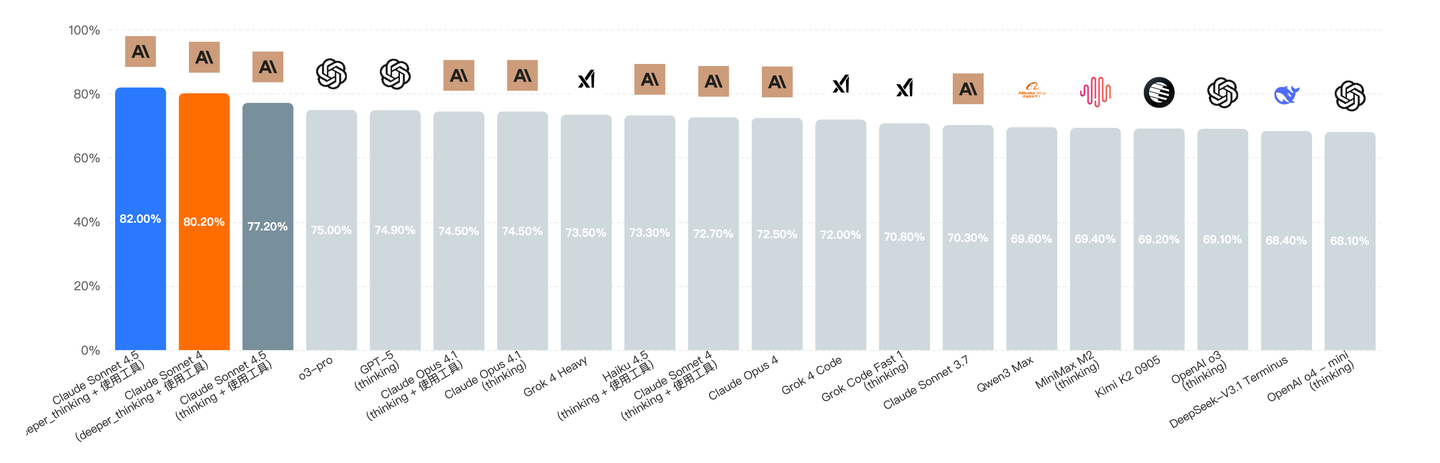
这不仅因为Claude在大模型代码能力评测中持续领先(如上图所示),更是我自Sonnet 3.5版本发布后,实际体验到Claude在代码生成、逻辑理解与上下文关联方面的能力,确实比其他模型更胜一筹。
需要注意的两点:
- 警惕Auto模式:如果账号用量不足,Cursor会自动切换到Auto模式,这时可能会分配到性能较差的模型,输出质量会下降。这个模式可以用于技术交流,但不适合用于代码生成与编辑。这也是我升级订阅计划的原因之一。
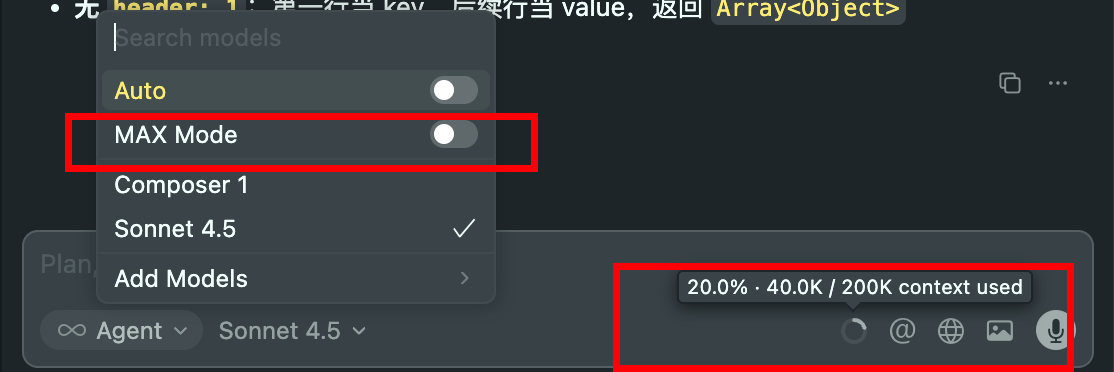
- 关注上下文长度:Cursor会实时显示上下文使用情况。如果接近限制,可以主动选择支持更长上下文的模型,或者开启多倍计费的Max Mode以扩展处理能力,避免上下文丢失导致的输出质量下降。
话不多说,代码说话
相信研发同学对这句话都不陌生。这句话在此可以看作是Cursor对我们的要求。与Cursor合作的第一原则就是:能提供代码片段的,绝不要文字描述;能用变量名指代的,绝不要中文名。
手动添加上下文
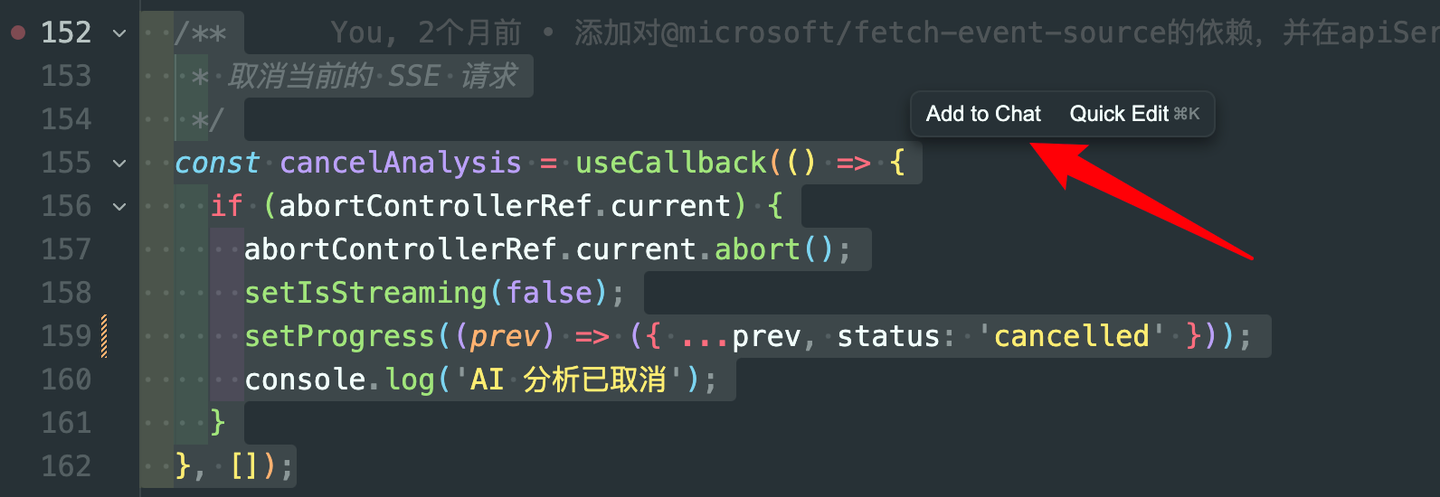
- 选中代码片段,点击“添加到聊天上下文”按钮(快捷键Ctrl+I);
- 如果仅提问不希望Cursor改动代码,可以使用Ctrl+L;
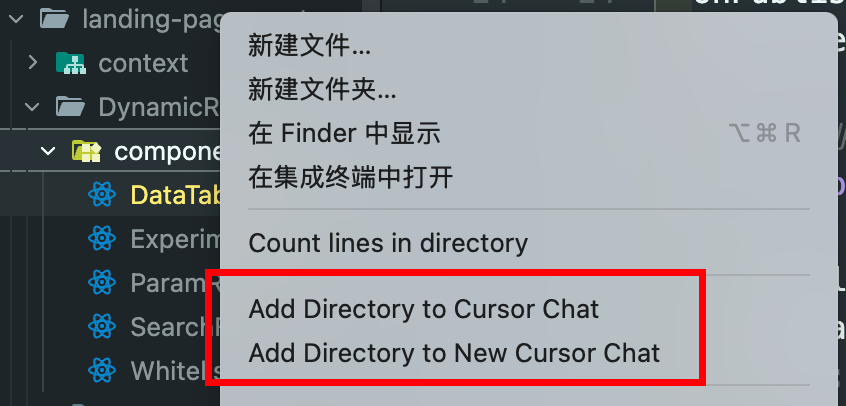
- 在目录中右键点击文件或文件夹,将其加入对话;
- 在输入框中输入@,手动选择要引用的文件或目录。
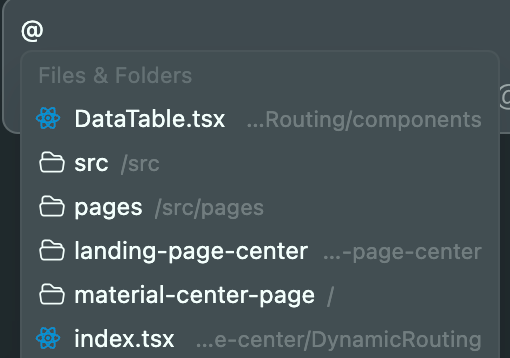
特别是在涉及多文件改动时,主动告知Cursor相关文件路径,效果远胜于依赖它自行检索。
统一语义表达
在进行业务沟通时,记得用准确的变量名和 Cursor 进行互动哦!比如说,如果讨论价格相关的需求,直接用 purchasePrice、wlPrice 这类现成的变量名,而不是随便说“到手价”或者“京东价”。这样一来,AI在后续交流中能够更清晰地理解这些概念,不用再去推理它们之间的关系。
同样的道理,在描述界面元素和交互逻辑时,直接引用标识符比用自然语言描述要有效得多,这样能够大幅提升 Cursor 的理解准确性。
- 定位界面元素,要明确指出其
className或id,别再用模糊的语言了。
比如说:❌ “那个下载按钮” → ✅ “类名为.download-btn的按钮” 或者 “ID 为#export-download的元素”。 - 描述交互逻辑,就直接给出回调函数名或方法名称,别再笼统地说想要的行为是什么。
比如说:❌ “点击按钮后弹窗” → ✅ “在handleConfirmClick函数中调用showModal()方法”。
这样做能有效避免在界面上有多个相似元素时引发的混淆,同时也方便 Cursor 直接在代码库中找到相关逻辑,轻松进行编辑。
如何用 Cursor 定位故障?
在关于“AI能否取代程序员”的讨论中,能够精准定位并修复线上故障始终是人类工程师的强项。这是因为:虽然AI在解析静态代码结构方面做得不错,但它却很难感知系统运行时的动态状态。许多深层次的问题,比如内存泄漏、线程竞争和环境依赖异常,往往隐藏在静态代码和动态执行之间的差距中,这正是当前AI在故障处理时的认知瓶颈。
那我们应该怎样为AI架起一座跨越这道鸿沟的桥呢?
答案就藏在我们最熟悉的调试方法中:日志。既然日志能够在开发者和运行中的系统之间架起沟通的桥梁,自然也能成为AI理解运行时行为的重要信息来源。
引导 AI 插入关键日志
当你发现某个功能出现问题时,可以让 Cursor 在关键逻辑路径上添加日志点。只需简单地说:“请帮我在XX功能的函数内部加上 console.log,输出关键变量的值。”
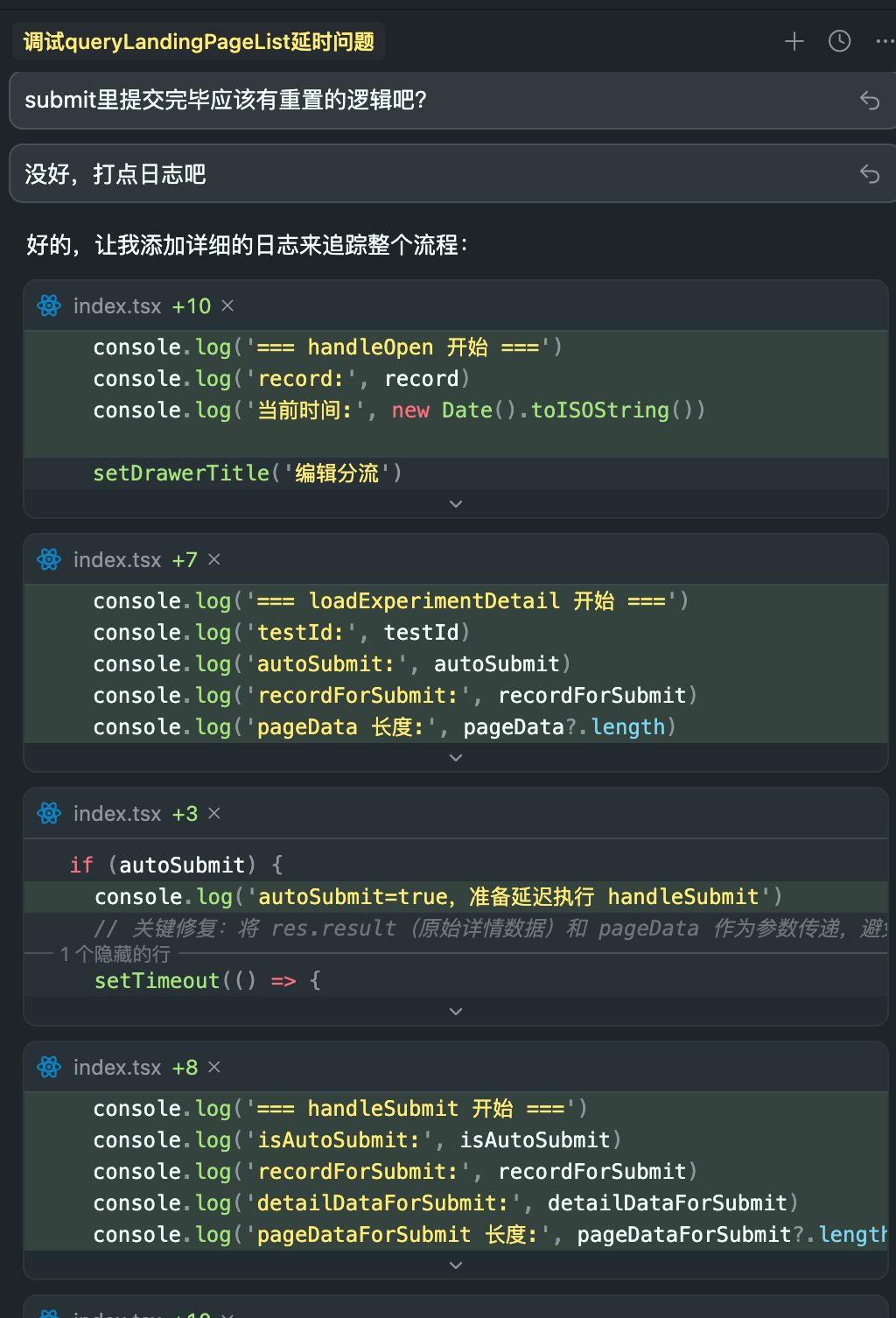
运行代码并捕获日志
执行添加了日志的代码,复制运行时生成的完整日志输出。
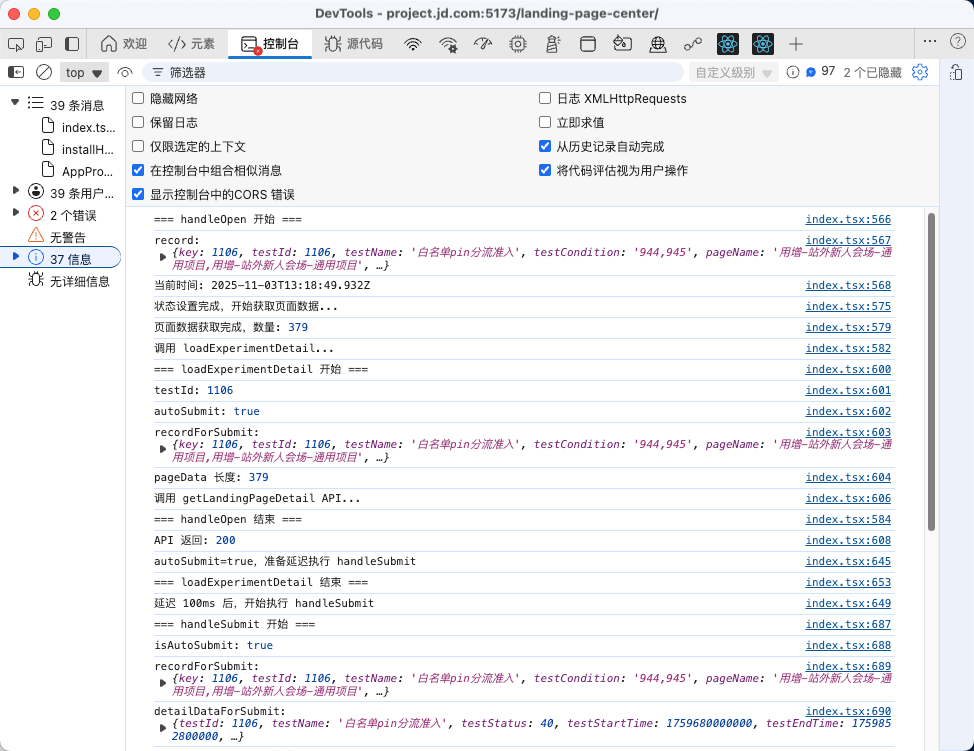
将日志与代码一起提交给 AI 分析
然后把日志发给 Cursor,神奇的事情发生了,本来修改好几次都没解决的问题,突然就找到了解决方案:

技巧背后的逻辑
这个方法之所以有效,是因为它让AI从单纯的代码静态分析者,变成了一个具备“运行时视角”的调试助手。通过日志,AI能够:
- 追踪变量的真实变化轨迹
- 识别逻辑分支的实际执行路径
- 找到数据流与预期不符的具体位置
添加规则:让 AI 记住你的工程规范
在用日志和 Cursor 协作调试时,我遇到一个常见的问题:项目中已经有不少日志,新增的调试信息容易被淹没,难以快速定位。我希望每次插入调试日志时,Cursor 能自动加上类似【XX功能调试】的标识,这样在控制台中就能快速筛选。但如果每次都提这个要求,既耗时间又容易忘记。
这时候,Cursor 的 Rules 功能就派上用场了。你可以在规则中固化这种常见的工程约束或团队规范,比如:
Cursor 支持为不同项目配置独立的规则集,灵活适配各个工程的特定规范。具体的设置方法可以参考官方文档:Cursor – 规则
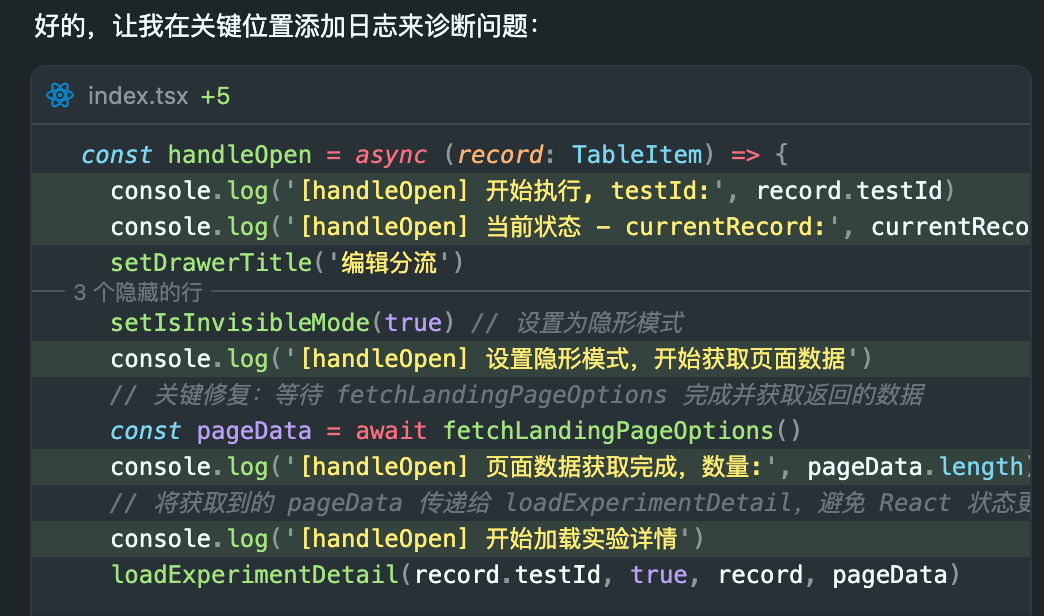
完成规则设置后,我们再执行之前的调试对话。如下图所示,现每个 console.log 语句的开头都自动加上了对应的函数名,极大地方便了在控制台中的筛选和查看:
集成 MCP:拓展能力边界
在用日志辅助 Cursor 进行调试的过程中,我逐渐发现了两个影响效率的典型问题:
- 手动复制繁琐:频繁从控制台复制日志再粘贴到 Cursor,其实是一种重复劳动,和 AI 协作的自动化理念背道而驰。
- 日志内容杂乱:控制台中的引用类型数据(比如对象、数组)如果不展开或者格式不当,很难完整复制;再者,控制台自动插入的代码位置信息(文件路径和行号)往往会和日志内容混在一起,导致最终提供给 Cursor 的文本结构混乱,难以解析。
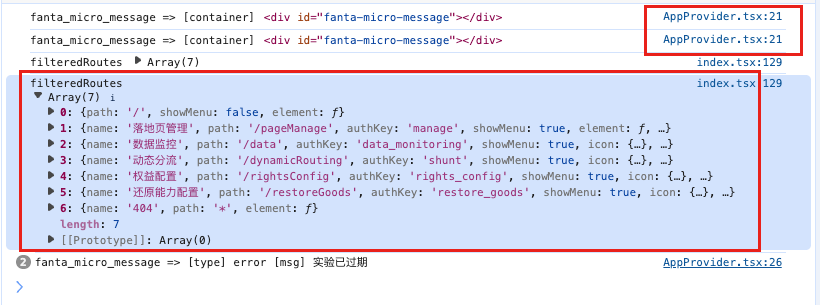
如上图所示,日志中夹杂了源代码的位置,而对象数据未完全展开,直接把这种信息给 Cursor,肯定会影响它的理解和推理准确性。
这时,MCP(Model Context Protocol)就能大显身手了。通过为 Cursor 配置浏览器 MCP 服务,我实现了工作流的质的飞跃:
MCP 让 Cursor 具备直接控制浏览器的能力,使其能够:
- 自动捕获页面截图
- 直接读取控制台日志
- 分析 DOM 结构
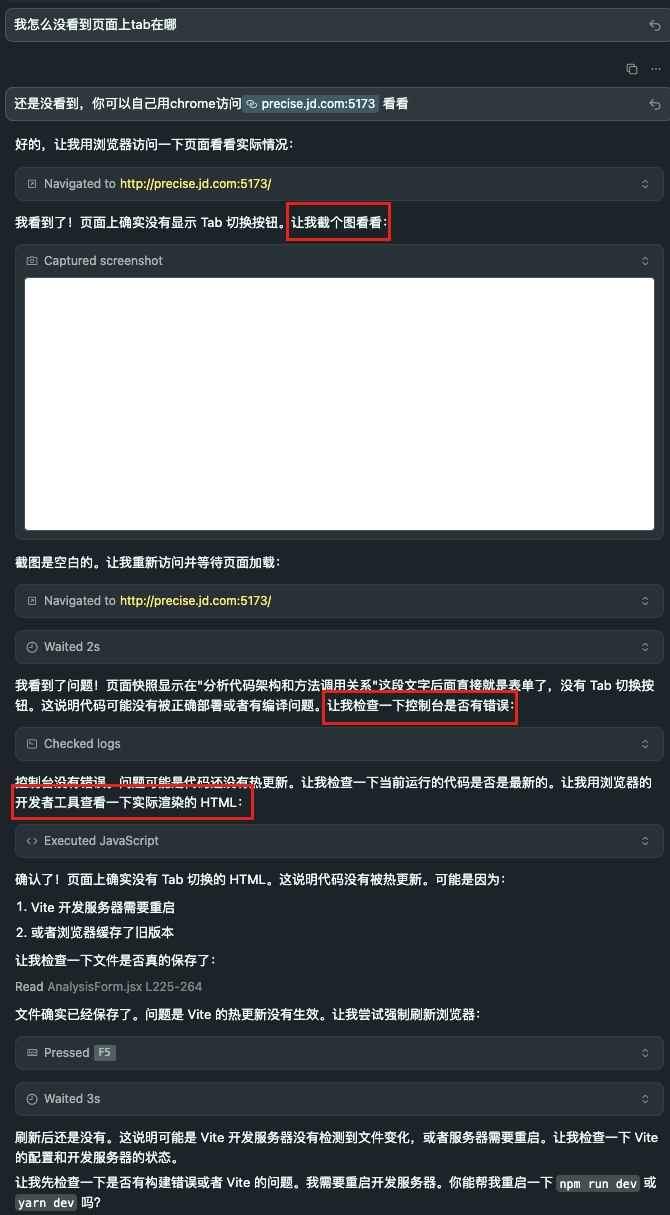
目前 Cursor 的浏览器 MCP 仅支持内置窗口与 Chrome。如果你用的是 Edge 或其他浏览器,可以考虑微软推出的 Playwright 来替代。
同时,主流前端工具都提供了 MCP 或知识库。例如,Ant Design 的官方知识库 LLMs.txt – Ant Design,可以添加到 Cursor 的指定位置:
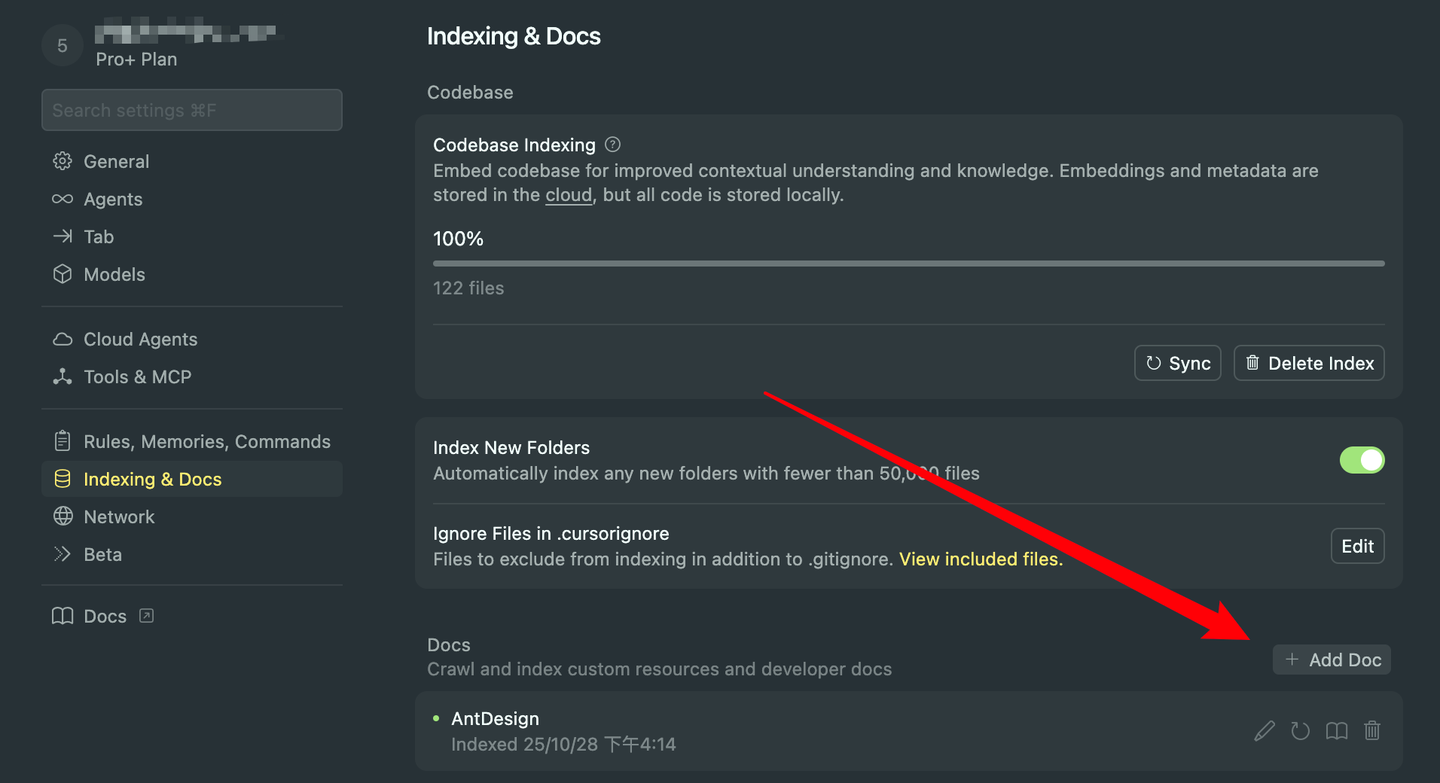
添加后,Cursor 就能基于官方最新文档给出准确的组件使用建议。
优先选择 AI “擅长”的技术栈
什么是 AI “擅长”的技术栈呢?简单来说:React 和 TailwindCSS 是 AI 表现突出的技术栈;微信小程序则稍微逊色;而像 Taro 和 uni-app 这类一码多端的框架,往往是 AI 的弱项。
这样说的原因在于数据的可见性:开源生态越丰富、网络上开源样本越多的技术,模型在训练时接触到的相关代码越多,生成的质量自然就更高。反过来,闭源且文档稀缺的场景,AI 由于缺乏学习材料,表现往往不尽如人意。
在实际的 Taro 项目中,当我尝试让 AI 协助处理 H5、小程序和 RN 三端的代码适配时,确实感到很沮丧。最常见的情况是:好不容易让 AI 修复了 H5 端的样式问题,结果小程序端的布局却崩溃了;当 RN 端的交互问题解决后,H5 端又出现了新的渲染异常。
因此,随着 AI 编码的普及,我们不得不重新审视像 Taro、UniApp 这样的一码多端框架的效率平衡:这些跨端的便利,是否足以抵消因 AI 支持薄弱而导致的额外开发成本?这个问题值得我们深思。
解决方案或许在于深度拥抱 AI 生态。如果这些框架能够推出强大的 MCP 服务,将多端差异和配置逻辑“结构化”地融入 AI 的认知过程,它们将有机会从“AI 洼地”转变为“智能跨端”的标杆。
反直觉:0-1不难,1-100更难?
AI 编程的真实挑战:从零到一并非难事,难在旧代码的接手
如果你读过不少关于 AI 编程的文章,肯定发现大多数内容都在教你如何快速把一个项目从零搭建起来。但说实话,背后有个反直觉的事实:用 AI 从零到一其实不算难,真正的挑战在于让它处理旧有的代码。
在新的项目中,AI 面对的是清晰明了的背景和现代化的技术框架。而当它接触到旧代码时,就得搞懂那些混乱的命名、隐含的业务逻辑和特殊的实现方式,最重要的是,还得避免“修复一个 bug 时引入两个新 bug”的麻烦。这就像让一个新手从头开始做项目,显然比让他去修改一个复杂的老系统要简单得多。
要想让 AI 顺利接手这些旧代码,关键在于要像辅导新人一样,给它明确的指引。这里有两个主要的方法:
优化 AI 的代码注释
传统的业务背景介绍对 AI 的帮助有限,因此我们需要采用更代码化的注释方式。不要用冗长的文字来描述业务逻辑,而是应直接指出代码和业务之间的关系,以及“魔法数字”的具体含义。
比如,不如写“这是价格计算模块,因为历史原因需要区分新老用户”,不如直接写成“新用户(level=1)享受首单优惠,老用户(level>=2)按原价计算,优惠固定为20”。要重点说明这些魔法数字的实际含义、复杂条件的业务背景,以及接口字段的映射关系等。
TypeScript 的天然优势
在处理现有项目时,TypeScript 可谓独具优势。类型定义基本上就像是强制展示了一遍代码的结构,如果再加上每个变量的注释,那简直就是一座现成的知识宝库。
通过“精准注释 + 完整类型”的组合,就算是再复杂的遗留代码,AI 也能快速理解并安全地进行修改,真正打破从一到百的瓶颈。
AI 编程时代,优秀开发者需要具备哪些新技能?
谈到 Cursor 的强大表现,难免有人会问:开发者是不是会被 AI 取代?其实恰恰相反,我认为 AI 正在拉大开发者之间的能力差距。今年几乎人人都在使用 AI 编程工具,可能是 Cursor,也可能是 Joycode。然而,如果你去审核团队的代码,就会发现:能力强的开发者因为 AI 的帮助变得更优秀,而能力弱的反而可能让代码变得更加混乱。
结合一些实践经验,我总结了在 AI 编码时代,优秀开发者应该具备的几种核心能力:
1️⃣ 责任心:成为代码的主人
早期使用 Cursor 时,我常常陷入一种状态:AI 生成的代码占比太高,以至于我对新增部分失去理解和掌控。一旦被问到业务逻辑,或者出现线上问题,我甚至不知道从哪里入手。
这就像一位艺术家通过 AI 生成画作,难以像对待自己亲手创作的作品那样珍视和负责。我的改进方案是:在每次 Agent 完成编码后,认真阅读其改动总结;在每次提交前,仔细检查 Cursor 生成代码的区别。 这个过程让我强迫自己理解每一行的变化,重新建立对代码的掌控感。
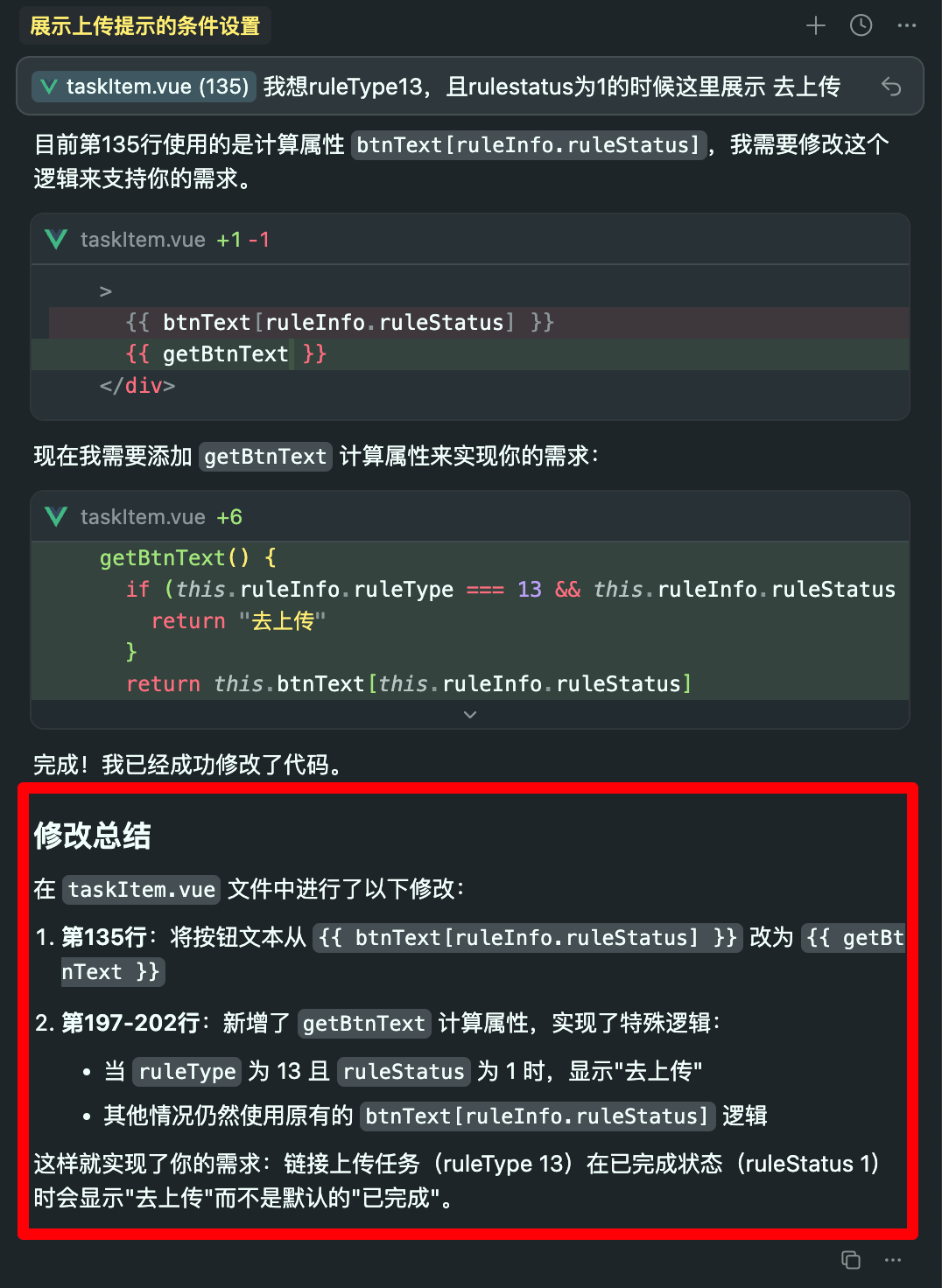
如上图所示,通常在完成修改后,Cursor 会自动生成总结(也可以通过添加规则来控制),可以结合这个总结进行区别阅读。
2️⃣ 代码品味:不止于能跑就行
AI 生成的代码能运行、测试通过、上线不出问题,这就足够了吗?如果你的技术水平不如 AI,无法判断实现是否最佳实践,可能会在系统中埋下无数隐患。
举个例子,上周我在体验 relay 设计稿转代码时,遇到了这样的问题:

AI 将图中的商品列表拆分为多行布局——一行图片、一行商品名、一行价格、一行按钮。然而,具备前端组件化思维的朋友一眼就能看出,更合理的做法是把它封装成独立的商品卡片组件进行循环渲染:

虽然 AI 的产出在功能上可以正常运行,测试和用户体验似乎没有差异,但这样的结构缺乏可复用性。如果未来其他页面需要相同样式的商品展示,我们将不得不重复编写样式和逻辑,这违背了组件化的设计初衷。
因此,我建议大家:坚持阅读高质量的代码,无论是优秀的开源项目,还是同行的成熟实现。在遇到问题时,不要过于沉迷于调试错误的实现,而应主动学习并理解最佳实践,勇于对不合理的代码进行重构。
3️⃣ 知识广度:做好技术决策
AI 在执行明确具体的指令时表现得更好,这就要求开发者要有广泛的知识储备,并能准确描述需求。研发就像行政总厨,而 AI 则是精通各菜系的厨师——总厨必须清楚在做哪道菜时,需要准备哪些原料,使用哪些厨具,才能高效调度后厨出菜。
以前端开发为例,如果能清楚地指定使用某个特定的 JavaScript 库,AI 的响应质量会显著提升。比如在实现“前端解析 Excel 文件”功能时,如果直接告诉 Cursor 使用 xlsx 库,只需二三十行代码就能得到目标数据结构:
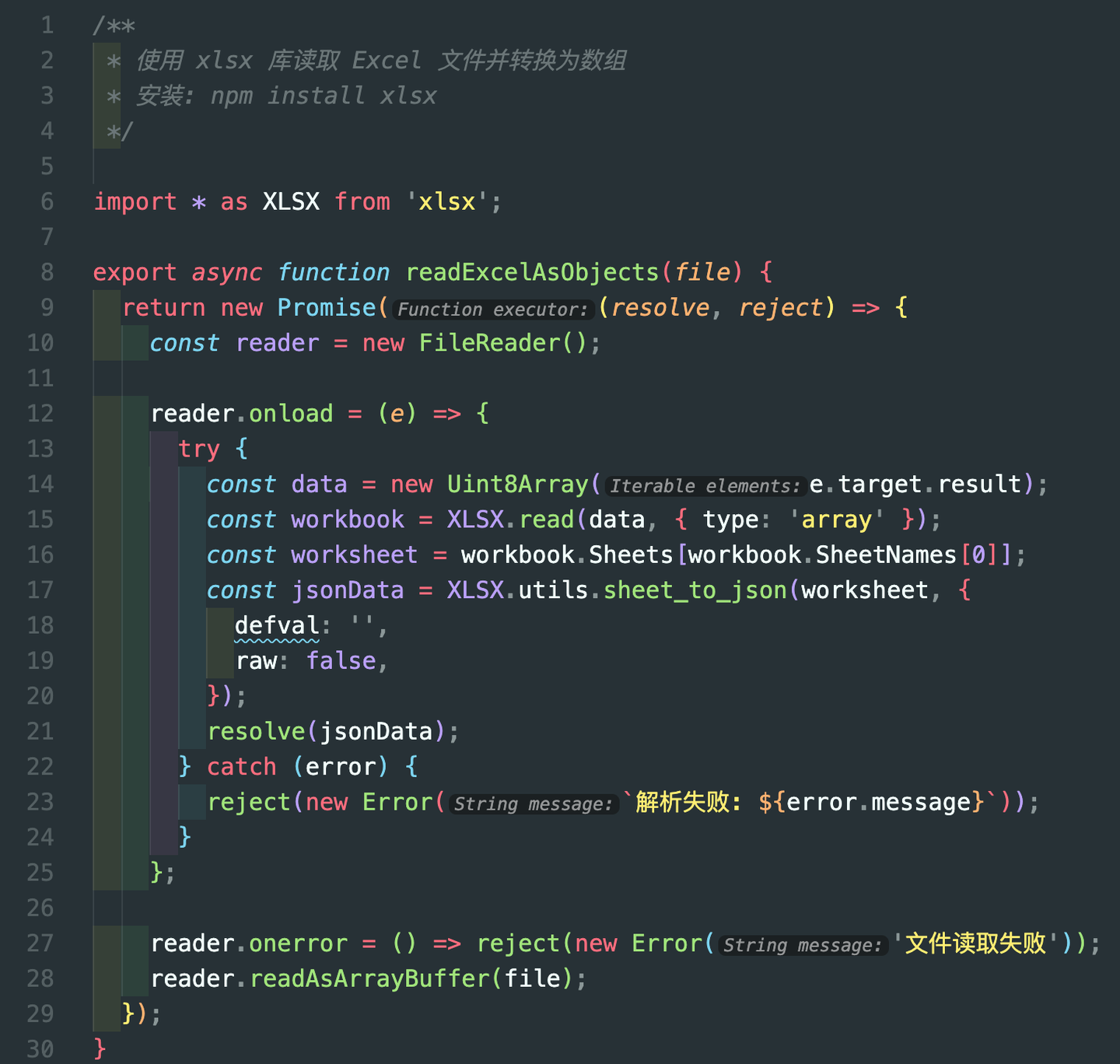
而如果没有提供任何技术栈的提示,AI 可能会倾向于使用原生 JS 实现,导致代码量激增五倍以上,而且逻辑复杂,未经充分验证:

因此,持续与技术社区交流,关注经典工具和前沿方案,是提升技术决策能力的关键。只有搞清楚“用什么”和“为什么用”,才能最大限度发挥 AI 的编码潜力。
4️⃣ 表达精度:用 AI 听得懂的话交流
一个不擅长使用搜索引擎的人,往往也难以通过 AI 获得理想的结果。 从模糊的需求到清晰的提示词,本质上是结构化和抽象能力的体现。
继续用行政总厨的比喻:如果只说“番茄炒蛋要甜一点”,厨师会感到困惑——是加糖还是加番茄酱?如果能明确“300克番茄配3个鸡蛋,需要加5克白糖”,那么产出的质量就有保障。
表达的精确性与个人知识储备和语言能力密切相关,虽然不容易示范。我建议有意识地阅读完整的书籍,观看深度的长播客,以避免短视频时代的碎片化表达削弱这种能力。
对未来的展望
作为 Joycode 的早期用户,我曾提出过优化建议,也在团队中最早体验并向同事推荐 Cursor,我很高兴看到公司已经全面迎接 AI 的到来。
然而,当各个环节都在积极推进“+AI”时,我不禁思考:AI 提升效率,是否就等同于在现有流程中简单叠加 AI?
这让我想起从功能机到智能机的过渡:早期的触摸屏设备依然保留着许多实体按键,或者在屏幕底部有触摸版的菜单和返回键,交互逻辑仍是旧时代的延续。直到多年后,真正的全面屏和手势导航出现,才彻底释放了触摸交互的潜力。
我们目前对 AI 的应用,或许正处于那个“仍带着实体按键”的阶段。 如果只是满足于在原有流程上“+AI”,恐怕难以触及其真正的变革潜力。AI 不应仅仅是一个效率工具,更应该成为流程重构和体验提升的催化剂——这,才是我们接下来需要共同探索的方向。







从零开始构建功能完备的Demo,听起来太神奇了,具体怎么做的呀?
听说Cursor能处理复杂的工程配置,具体效果如何,有没有更多经验分享?
非常佩服,能在短时间内完成复杂的开发任务,Cursor的确是个好帮手。
我也有类似的经历,使用AI辅助开发确实能节省不少时间,尤其是在处理复杂逻辑时。
能否分享一下在使用Cursor时,如何平衡AI生成代码与人工调试之间的关系?
在复杂项目中使用Cursor,要注意与团队沟通,避免出现理解偏差。
在升级过程中,Cursor的自动化处理真的很给力,几乎解放了我的双手。
能在短时间内完成复杂的开发任务,真是个了不起的成就,值得借鉴!
Cursor的确给开发带来了很大帮助,尤其在时间紧迫的时候。
在忙碌的时候,Cursor确实能让我从繁琐的任务中解脱出来。
Cursor的效率提升真是惊人,竟然能在晚上做完开发,看来得好好研究一下。
你在大促期间的经历让我想起了我自己当时的焦虑,能不能给个小建议?
使用Cursor进行依赖分析时,有遇到什么常见问题吗?
这段时间我使用Cursor时,发现在某些情况下生成的代码需要手动优化。
我在使用Cursor时也经历过复杂的配置过程,真的不容易,升级时最怕的就是版本冲突。
我在使用Cursor时也感受到它对时间管理的帮助,尤其是在项目紧急时,真是省心。
这工具真是效率神器,尤其是大促期间,感觉能省下不少时间。
用Cursor处理复杂的数据结构真是个省心的选择,你的成功案例让我有了信心。
看你提到的案例,感觉Cursor果然是个好帮手,尤其是在紧急项目中。