嘿,大家好!今天我想聊聊最近热议的GPT-5.2,这次它的三个版本一同上线,真的很有意思。尤其是在抽象推理方面,简直把Gemini都压得喘不过气来,70%的任务表现堪比人类专家呢。

在Gemini 3 Pro的强力竞争下,OpenAI终于在十周年之际推出了这一系列新产品,真是让人期待啊。
这次可没有进行灰度测试,直接就放出了GPT-5.2的Instant、Thinking和Pro三个版本,不仅在传统测试中重新夺回了冠军宝座,甚至在抽象推理和实际工作场景中也取得了不少突破。

但是,面对谷歌Gemini 3 Pro的稳定性优势,这场AI的竞争,到底谁能笑到最后呢?

传统测试中夺得双冠,数学和代码表现都很突出
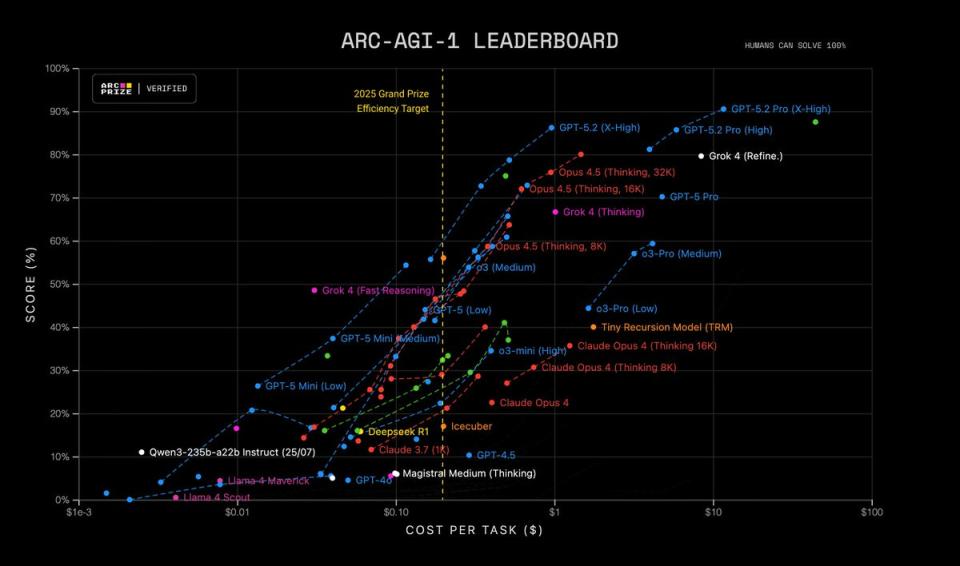
在老牌的测试中,GPT-5.2展现出了超强的实力,直接把Gemini 3 Pro甩在了后面。
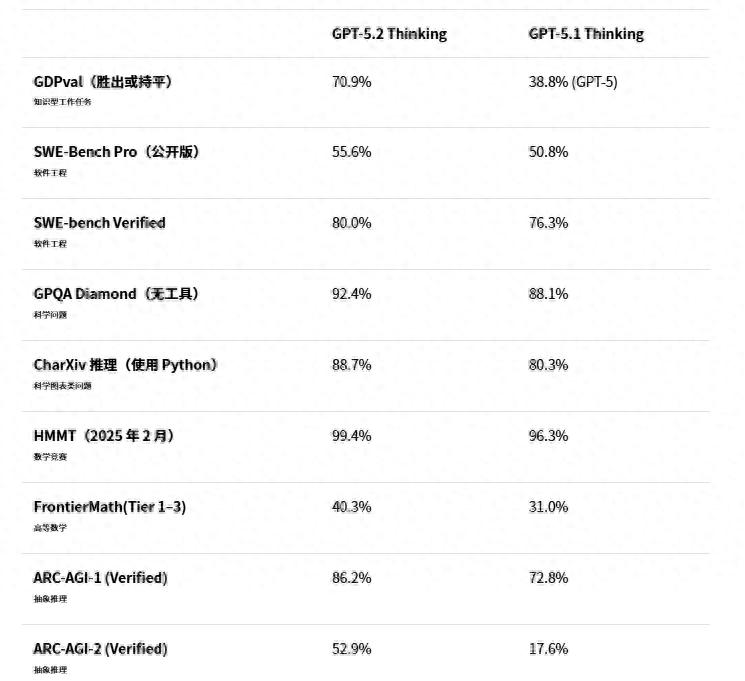
在AIME 2025数学竞赛中,GPT-5.2 Thinking版本没有联网,也不运行代码,完全依靠推理就取得了满分,而Gemini 3 Pro则得了95分。
AI在测试中表现亮眼,真有点“长脑子”的感觉
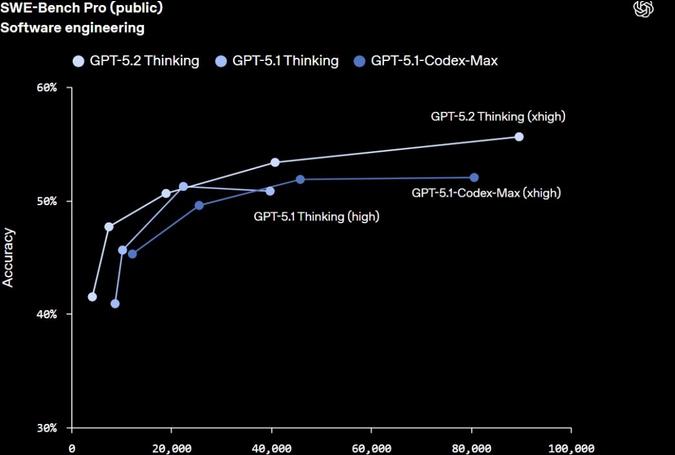
在软件工程测试 SWE-Bench Pro 里,GPT-5.2以 55.6% 的得分远超 Gemini 3 Pro 的 43.3%,显示出代码编写能力的显著提升。
不过,普通用户可能觉得这些分数的提升不太明显,真正的惊喜其实在其他两个测试中。

抽象推理能力提升三倍,AI真不简单
ARC-AGI-2 测试的进展,才是 GPT-5.2 的真正亮点。
这个测试是由 Keras 的创始人设计,专门用来评估不需要死记硬背的“流体智力”,里面全是新颖的抽象图形规律题。
前一代的 GPT-5.1 只得了 17.6 分,而 GPT-5.2 Thinking 直接飙升到了 52.9%,分数翻了三倍。
它不再只是单纯地预测下一个字,而是像人一样进行“假设-验证”,展现出更高层次的思维方式,让 Gemini 3 Deep Think 的 45.1% 看起来有些逊色。

完成70%任务超越专家,AI干活能力确实很强
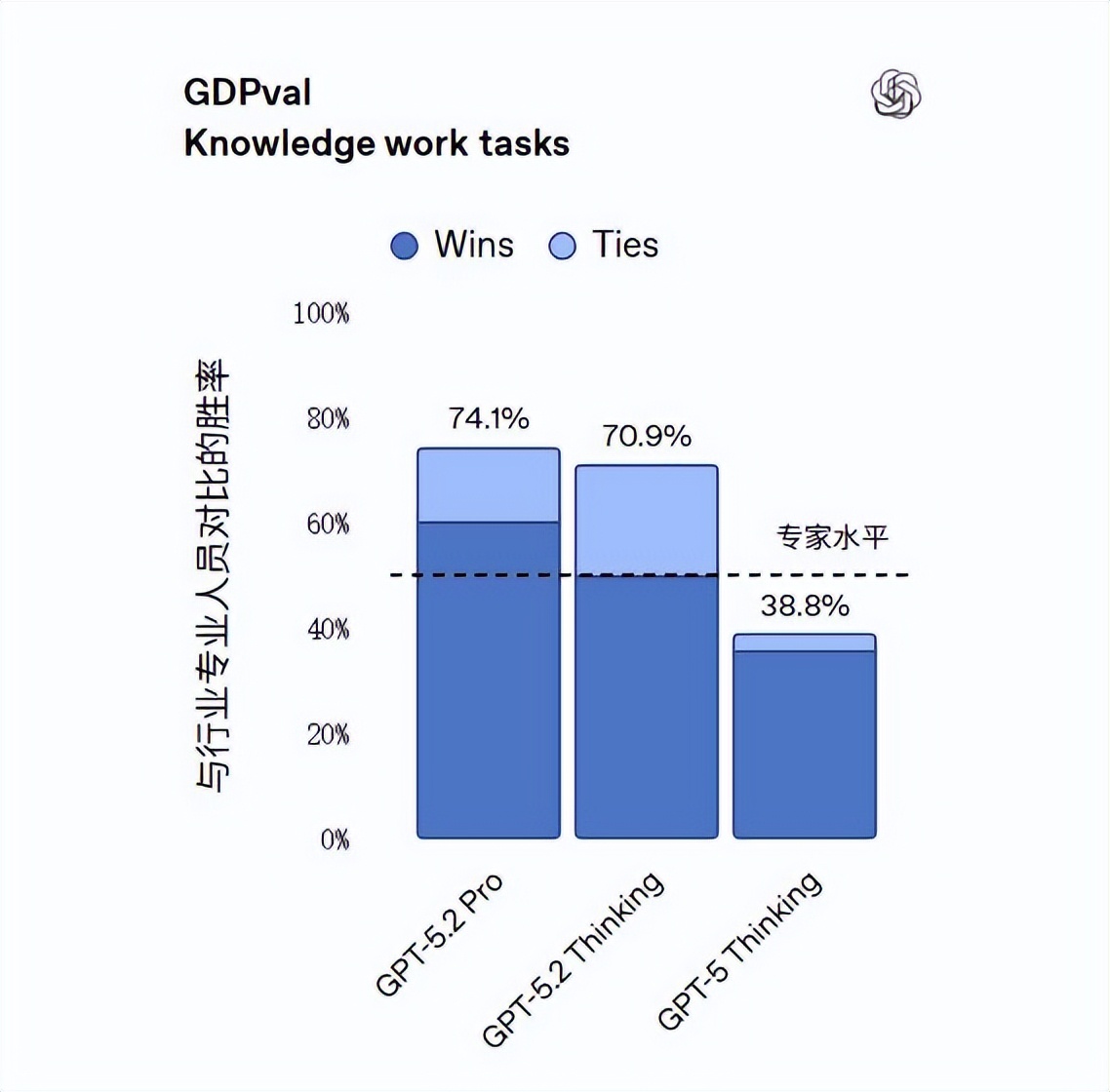
如果说 ARC 是测智商,那么 GDPval 就是评估赚钱能力的硬核测试。
这个测试是 OpenAI 联合哈佛的经济学家一起设计的,涵盖了9个高 GDP 行业的44个核心职位,都是基于真实复杂的工作任务。
GPT-5.2与Gemini 3 Pro的对比:谁更胜一筹?

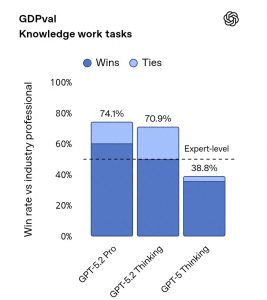
你知道吗?在很多任务上,GPT-5.2 Thinking 可不是一般的厉害,竟然在70.9%的情况下,被专家们评为“表现优于或持平”那些经验丰富的人类专家。
想想看,上一代的胜率只有38.8%,这次它在生成 Excel 公式和代码结构时,简直展现了无与伦比的专业性,真的是在帮助我们提高效率。

长跑翻车? Gemini 3 Pro 稳守优势
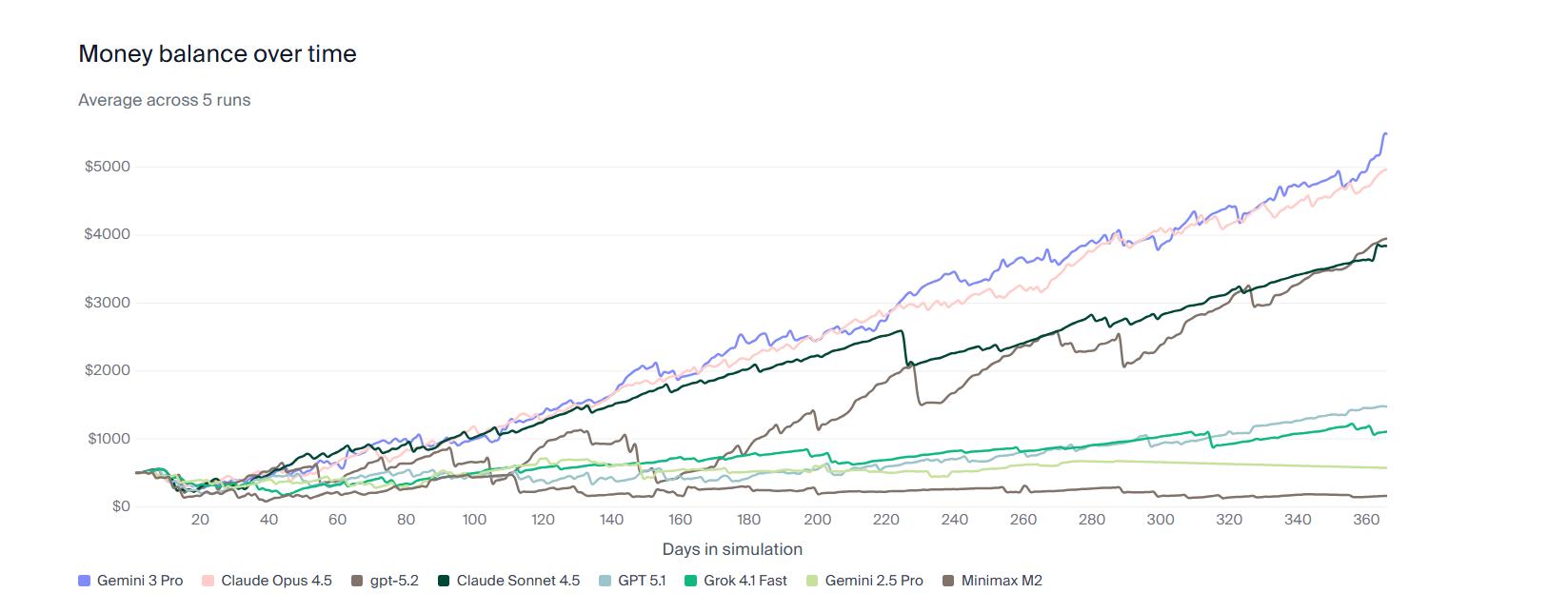
不过,GPT-5.2 也不是完美的,它在长期稳定性测试中暴露了不少短板。
比如,在 Vending-Bench 这个虚拟公司运营评测中,AI 需要模拟一整年的日常运营,这就考验了它的连贯性和记忆力。
而 Gemini 3 Pro 则凭借着一百万的上下文窗口,经营曲线稳步上升,决策始终清晰。
而 GPT-5.2 在初期表现得非常抢眼,但到了后期却常常出现“失忆”现象,忘记之前的订单,陷入死循环,甚至崩掉。
这引发了不少讨论:难道 GPT-5.2 是为了提高分数而陷入了“应试教育”的泥潭?它的长跑能力亟待提升。