最近你可能感觉到AI的表现是:能写能聊,可一到实际交付就得不断调整、反复检查——那么这次的 GPT-5.2 更新,或许正好击中了这个痛点。
OpenAI 对 GPT-5.2 的定位很明确:旨在支持专业工作和长期运行的智能体。这次的升级不只是让模型更聪明,而是更像是一次围绕实际工作场景的系统性提升:在长上下文整合、工具调用的稳定性、多步骤任务的可靠性和安全边界方面都有所加强。
01|GPT-5.2到底升级了些什么?关键不在于“更聪明”,而是更能交付
OpenAI 对 GPT-5.2 的描述非常凝练:这是他们迄今为止最强大的模型系列,并且专门为知识工作和智能体场景设计。
从官方提供的能力提升点来看,GPT-5.2 更像是在完善“工作流的最后一公里”:
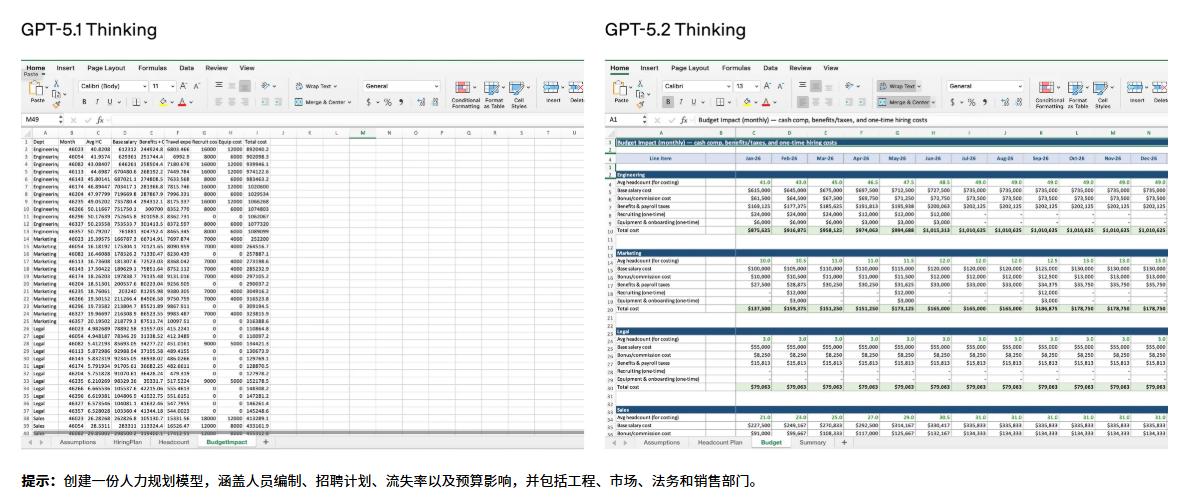
- ✅ 交付物更稳:电子表格、演示文稿和代码的质量都有提升
- ✅ 长文本理解能力增强:在整合、检索和推理长上下文方面表现显著提升
- ✅ 多步骤项目执行更可靠:复杂任务链和工具使用的能力得到增强
- ✅ 视觉处理更出色:图像识别、图表推理和软件界面的理解错误率降低
这个变化显示出一个趋势:模型能力的竞争,正从“单轮回答”转向“端到端交付”。
你需要的不再仅仅是一个会聊天的助手,而是一个更为稳定的执行系统。
02|数据不只是装饰:GPT-5.2用关键基准展示“专业能力”提升
OpenAI 在发布中提供了大量对比数据。挑选一些最能体现“实际价值”的数据,你会更容易判断这次升级是否值得。
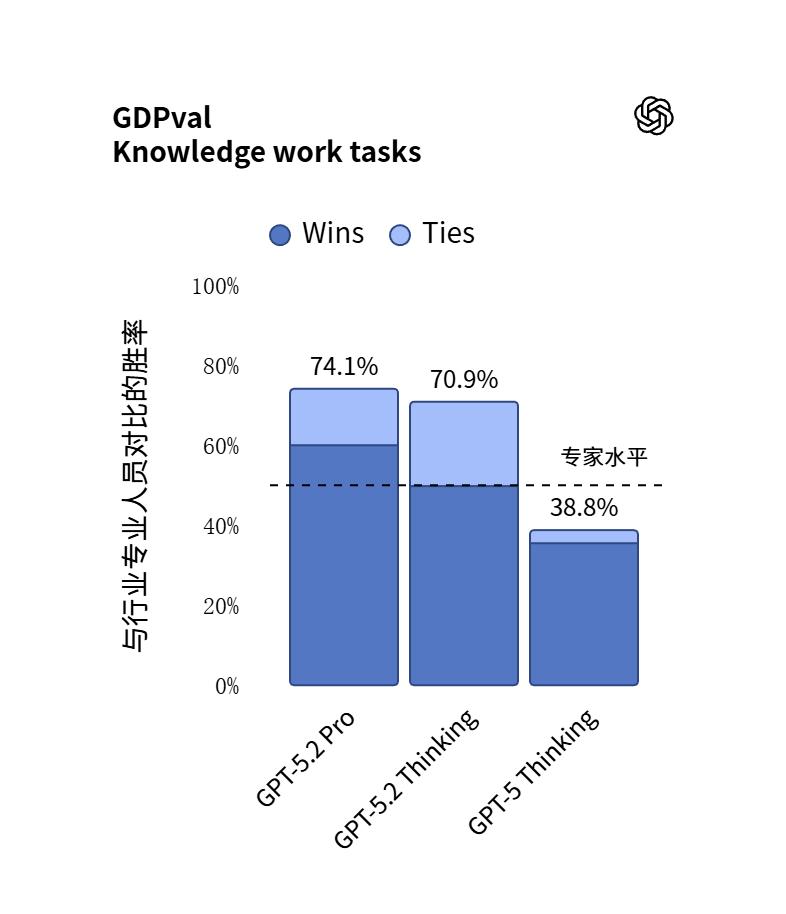
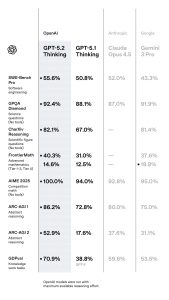
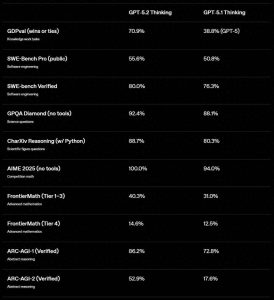
GDPval:在知识型工作任务中,首次达到或超过专家水平
GDPval 是一个涵盖44 个职业的知识工作评估。官方给出的结果是:
- GPT-5.2 Thinking:70.9%(持平或胜出)
- GPT-5.1 Thinking:38.8%(文中标注对比)
此外,OpenAI 还补充了一个很“商业化”的信息:
- 在GDPval的任务中,GPT-5.2 Thinking的输出速度比专家快11倍以上,成本却不到1%。注:官方强调速度和成本估算基于历史指标,实际使用体验可能会有所不同。
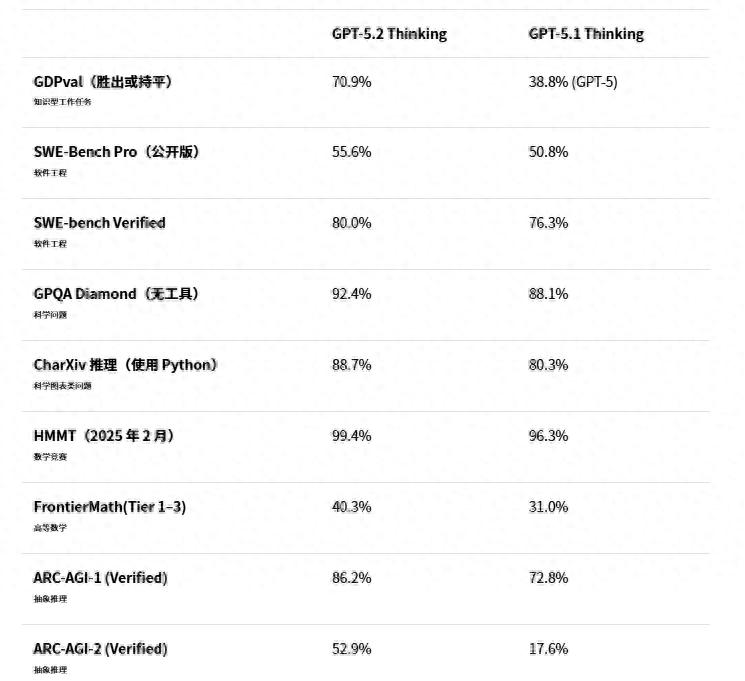
SWE-bench:软件工程更接近“端到端修复交付”
如果你关心“能否真正修复bug并通过测试”,SWE-bench 系列就是最直接的信号。
- SWE-Bench Pro(Public):55.6% (GPT-5.1 Thinking:50.8%)
- SWE-bench Verified:80.0% (GPT-5.1 Thinking:76.3%)
OpenAI 的解读也很清晰:这意味着在实际工程中,它更可能完成调试、实现和重构等任务,减少人工介入。
科学与数学:不仅更强,甚至出现了“参与新论文”的案例
OpenAI 在科学与数学领域强调:
- GPQA Diamond(无工具) GPT-5.2 Pro:93.2% GPT-5.2 Thinking:92.4%
- FrontierMath(Tier 1–3,使用 Python) GPT-5.2 Thinking:40.3% (GPT-5.1 Thinking:31.0%)
更值得关注的是他们提到的一个研究案例:GPT-5.2 Pro 被用来解决统计学习理论中的一个开放问题,并形成了一篇新论文《On Learning-Curve Monotonicity for Maximum Likelihood Estimators》,作者指出人类的工作重点在于验证与写作,而不是提供证明的框架。
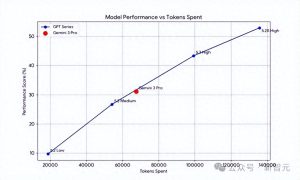
03|为什么说这次更像“工作流升级”?长上下文 + 工具调用成为基础
许多人对大模型最真实的抱怨是:短任务表现优秀,但长任务就容易出错——资料越多,关键点越容易遗漏,前后矛盾,或者中途“忘记了目标”。
GPT-5.2 的一个重要信号,就是 OpenAI 特别强调了长上下文整合的评估:
- 在 OpenAI MRCRv2(用于衡量整合长文档分散信息的能力)上,GPT-5.2 Thinking 明显领先
- OpenAI 指出:这是他们首次观察到模型在 4-needle MRCR 变体(最长 256k token)上接近 100%的准确率表现
更进一步,OpenAI 提到 GPT-5.2 Thinking 可以与 Responses /compact 端点结合,用于扩展有效上下文窗口,以支持更依赖工具的长时工作流。
️ 04|系统卡带来了哪些启示?安全边界不应该是“附加条款”,而是产品的核心能力
在企业使用AI的过程中,最棘手的往往不是“能否使用”,而是“如何掌控”。GPT-5.2的系统卡更新指出:它的全面安全机制与前几代的框架保持一致,并在几个关键领域上持续发力:
继续推进“安全补全(Safe Completions)”的方向
OpenAI提到,GPT-5.2沿用了GPT-5发布时的安全补全研究,这样在不突破安全边界的情况下,模型也能给出有效的回答。
提升对敏感话题的回应能力(心理健康/自残/情感依赖等)
OpenAI表示,他们在增强模型对敏感对话的回应能力上持续努力,目标是减少不合适的回复,并提升回应的安全性。
系统卡中还列出了对比数据(部分摘录):
- 心理健康:GPT-5.2即时版 0.995 vs GPT-5.1即时版 0.883
- 情感依赖:GPT-5.2思考版 0.955 vs GPT-5.1思考版 0.785
- 自残:GPT-5.2思考版 0.963 vs GPT-5.1思考版 0.937
推出“年龄预测模型”以保护未成年人
OpenAI提到,他们正在逐步引入年龄预测模型,目的是为了自动为未满18岁的用户实施内容保护措施,这是对现有未成年人识别和家长控制的进一步升级。
05|如何选择和使用:Instant / Thinking / Pro 的产品逻辑与API命名 在 ChatGPT 中:三条路径满足三种需求
OpenAI给出了非常明确的产品定位:
- GPT-5.2 Instant:日常使用的主力,效率高、解释清晰,适合信息查询/写作/翻译
- GPT-5.2 Thinking:适合更深层次的工作,尤其擅长编码、长文档总结、数学逻辑和规划决策
- GPT-5.2 Pro:最可靠,适合解决高难度问题和高质量要求,重大错误发生率更低
上线策略是逐步进行,优先考虑付费用户(包括Plus / Pro / Go / Business / Enterprise)。同时,GPT-5.1将以传统模型的形式继续提供一段时间,然后停止支持(官方说明为三个月的过渡期)。
在API中:命名和推理强度更加“工程化”
OpenAI提供的模型名称包括:
- gpt-5.2:Thinking(Responses API与Chat Completions API均可使用)
- gpt-5.2-chat-latest:Instant
- gpt-5.2-pro:Pro(Responses API)
还补充道:GPT-5.2 Pro和Thinking支持新的第五档推理强度xhigh(专为最高质量任务设计)。
 超实惠的AI模型价格一览
✅ 06|升级值得吗?给你一个“迁移决策”的思路 如果你想快速做出决定,可以试试下面这三个问题:
GPT-5.2的真正亮点在于,AI从聊天工具变身为可运行的系统 GPT-5.2传递出的信息很清晰:AI的竞争不仅仅是“谁更会说”,更是谁能稳定地完成复杂的任务链,谁更适合被整合进实际的业务系统中持续使用。 如果你正在进行企业落地、智能体应用、科研辅助,或者是高强度的知识工作,建议用GPT-5.2来重新设定你的标准:
|







GPT-5.2的升级让人期待,特别是在长文本理解和多步骤任务执行方面的提升,真的是朝着更实用的方向发展。希望能在实际应用中看到更好的表现!
GPT-5.2的稳定性和交付能力提升让人眼前一亮,尤其是在复杂任务执行和视觉处理上,实际应用前景非常广阔。期待它能在工作中大显身手!
这次GPT-5.2的更新真是令人振奋,特别是在长文本理解和复杂任务处理上的进步,感觉能大幅提升工作效率,期待在实际使用中能体现出这些优势。
GPT-5.2的升级真是突破,尤其在专业工作中的应用潜力巨大,让我对未来的工作流程充满期待。希望能看到更多成功的实际案例!
GPT-5.2的长文本理解和多步骤任务执行能力提升,让我对它在专业领域的应用充满信心,非常期待能在实际工作中看到它的表现!
GPT-5.2的更新让我看到了AI在工作中的更多可能,特别是在长文本处理和复杂任务执行方面的进步,真的让人期待它的实际应用效果。