
在12月12日的清晨,OpenAI 突然宣布了 GPT-5.2 系列的正式上线,这次发布直接对标谷歌的 Gemini 3 和 Anthropic 的 Claude Opus 4.5,真是AI界的“年末大戏”。这一代模型主要聚焦于专业知识的应用,官方称其为“目前最强的专业级模型系列”,实测结果也相当令人惊艳:
1. 基准测试全面领先,推理能力大幅提升
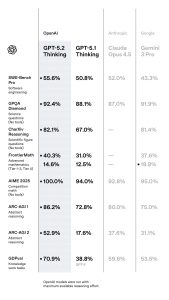
· 数学竞赛表现卓越:在2025年美国数学邀请赛 AIME 中取得了100%的满分,远超 Claude Opus 4.5 的92.8%和 Gemini 3 Pro 的95.0%;
· 专业能力超越人类专家:在涵盖44种职业知识任务的 GDPval 基准测试中,得分为70.9%,这意味着在大约70%的专业场景中表现优于人类专家,而上一代的得分仅为38.8%;
· 编程与科研表现突出:在软件工程的 SWE-Bench Pro 中得分为55.6%(最高竞品为52.0%),GPQA Diamond(研究生级科学推理)达到了92.4%,而 FrontierMath(高等数学)则为40.3%,均位于榜首。
2. 实用功能全面升级,精准解决专业痛点
· 超长上下文支持:支持256K Token窗口,能够一次性处理类似《三国演义》这样的大文档,合同、研究报告等长文本不再需要分段上传;
· 多模态能力显著提升:对 Excel 图表、工程图纸和软件截图的解析错误率降低了50%,空间关系和数据逻辑的识别更加精准;
· 幻觉率大幅减少:与 GPT-5.1相比,事实错误率降低了38%,在撰写报告和做决策时更加可靠;
· 工具集成更加流畅:可以帮助前端开发者直接生成3D海浪模拟、打字游戏等复杂应用,程序员在调试生产环境代码和重构大型代码库时效率提升了20%。
3. 三个版本如何选择?一张表看清差异与定价
这次 GPT-5.2 首次推出了“三版本策略”,根据不同需求提供专业化选择,定价也有所不同(API 调用价格):
版本 定位 核心场景 价格(输入/输出) 适合人群
Instant 速度优先主力模型 日常聊天、翻译、简单文案邮件 1.75/14 美元/百万 Token 学生、普通办公族
Thinking 深度推理专业模型 长文档分析、表格/PPT制作、编程调试 同 Instant(支持调节推理强度) 白领、分析师、程序员
Pro 极致可靠顶尖模型 学术研究、高难度算法、金融建模 21/168 美元/百万 Token 企业研发、科研人员、高端从业者
订阅权益:付费用户(Plus/Pro/Business)从12日起陆续推送,免费用户13日开放基础访问;GPT-5.1作为旧版将在3个月后下线。
4. 实测体验:哪些场景值得升级?哪些应当降低期待?
✅ 强烈推荐场景
· 专业文档处理:使用 Thinking 版本总结数十万字的报告,跨文件整合信息,结构清晰且重点突出,节省了约80%的时间;
· 编程与数据分析:无论是Python代码编写、多语言项目调试,还是复杂数据表格制作,尤其是前端3D效果与金融建模,Pro版本的稳定性表现出色;
· 学术与科研辅助:Pro版本能精准解答研究生级科学问题、推导数学公式,甚至可以辅助设计实验方案,文献综述的效率提升了一倍。
❌ 仍需谨慎的场景
· 常识推理与共情能力:在 SimpleBench(常识测试)中的表现甚至不如一年前的 Claude Sonnet 3.7,基础问题如“garlic 有几个 r”也可能答错,对话显得缺乏人情味。有用户反映,向模型倾诉“恐慌发作”,却得到了“很高兴听到这个消息”的回应;
· 创意与审美表现:在生成ASCII艺术和可视化图表时效果较为简陋,比如交通灯模拟仅呈现黑白火柴人,远不及 Claude Opus 4.5 的彩色动态效果;
· 安全机制略显僵化:曾拒绝转录哲学论文,回答“历史人物匹配”等无害问题,部分用户对此表示不满,觉得“把成年人当作幼儿园孩子对待”。
5. 涨价 40% + 口碑两极,是否值得入手?
GPT-5.2 的 API 价格较5.1上涨了40%,引发了不少讨论。是否值得升级,主要看你的使用场景:
推荐升级人群
· 专业工作者(程序员、分析师、科研人员):在核心工作场景的效率提升,远远超过成本的增加,长文档处理与复杂推理能力能够直接转化为生产力;
· 企业用户:Pro版本的可靠性和工具集成能力,适合嵌入内部系统,有效降低研发与运营成本。
⚠️ 不建议升级人群
· 普通用户:日常聊天和信息查询使用 Instant 版本就已经足够,免费额度基本满足需求,无需为溢价买单;
· 创意工作者:模型在艺术创作和情感对话等方面的表现有所退步,建议继续使用 GPT-4o 或 Claude Opus 4.5。
6. 行业趋势:AI 迭代进入“专业细分时代”
GPT-5.2 的发布,标志着生成式 AI 正在从“通用聊天工具”向“垂直生产力工具”转变:
· 迭代周期缩短:从 GPT-5.1 到 5.2 仅间隔一个月,OpenAI 以“红色警报”策略应对竞争,行业进入“月度迭代”的节奏;
· 能力分化加剧:模型不再追求“全知全能”,而是专注于专业领域的突破。未来选择 AI 工具时,将更关注“是否匹配自身行业”而非“综合性能”;
· 安全与体验的平衡难题:OpenAI 为了强化企业级安全,部分牺牲了用户体验,这也是所有 AI 厂商面临的共同挑战——如何在合规的同时保持模型的灵活性与人性化?
总结
GPT-5.2 是一款“偏科明显但优势突出”的模型:在专业场景的推理、编程和文档处理能力上遥遥领先,堪称专业人士的“超级助手”;然而在常识、共情和创意等方面仍有明显短板,普通用户可能难以察觉升级的价值。
如果你的工作需要处理复杂任务,并且能够接受40%的价格上涨,这次升级值得考虑;若只是日常使用,可以等后续优化,或继续使用 GPT-5.1 过渡。AI 迭代日新月异,适合自己的,才是最好的。





GPT-5.2的专业能力提升令人印象深刻,尤其是在数学和编程方面,真是科技进步的体现。期待它在实际应用中的表现!
这次GPT-5.2的多模态能力提升让我很惊喜,尤其是在处理复杂文档和数据逻辑方面,看来它会大大提高工作效率。
GPT-5.2在专业知识应用上表现得非常强大,尤其是对人类专家的超越,让我对未来的工作充满期待。希望它能在更多领域展现出色的表现。
这次推出的三个版本策略很贴心,能够根据不同需求选择合适的模型,特别是对普通用户来说,Instant版本非常实用。
GPT-5.2的超长上下文支持真是个大亮点,处理长文档再也不用分段上传了,这对科研和专业领域的工作帮助很大。
这次GPT-5.2在编程调试和科研方面的表现真让人刮目相看,特别是能显著提高效率,未来的工作将更加轻松。
GPT-5.2在处理长文档时的能力让我感到震惊,特别是256K Token的支持,让信息整合变得更加高效,真是科研人员的福音。
GPT-5.2在专业能力上的提升很明显,尤其是在数学竞赛中的表现,超越了许多人类专家。这为各行各业提供了新的可能性,期待它的实际应用效果。