
作者|冬梅
如今,全球人工智能的竞争愈演愈烈,谷歌和 OpenAI 在同一天都发布了重磅更新,引发了业内的高度关注。
就在昨晚,谷歌推出了全新的“重新构想”版本的 Gemini Deep Research,并首次开放了嵌入式研究智能体的 API。
几乎与此同时,OpenAI 也正式推出了人们期待已久的 GPT-5.2(代号 Garlic)。这两家公司在智能体的未来、基础大模型的能力边界以及应用生态的主导权方面的竞争,正在进入一个前所未有的紧张局面。
这次的时间点几乎是完美重合,让外界能够更清楚地看到这两大 AI 巨头之间的战略博弈。

1 谷歌推出全新 Deep Research Agent
谷歌最新发布的 Gemini Deep Research 工具是一款智能代理,能够整合大量信息并处理提示信息中的上下文数据。谷歌指出,用户可以利用 Deep Research Agent 执行从尽职调查到药物安全研究的各种任务。
而且,谷歌还表示,这款新的 Deep Research Agent 将很快集成到他们的各种服务中,比如谷歌搜索、谷歌财经、Gemini 应用和广受欢迎的 NotebookLM。这意味着谷歌正在朝着一个未来迈进:未来,人类可能不再需要自己搜索任何内容,而是由人工智能来替我们完成这些工作。
那么,Deep Research Agent 具体具备哪些能力呢?
在这次更新中,谷歌不仅对 Deep Research Agent 进行了架构上的重新设计,还基于 Gemini 3 Pro 构建了一个更加稳定、准确且可追溯的深度研究系统。新版 Deep Research Agent 的能力提升可以归纳为三个关键点:模型升级、推理稳定性突破和交互能力的全面增强。
首先说说模型升级。新版 Deep Research Agent 完全基于 Gemini 3 Pro 构造,而谷歌认为 Gemini 3 Pro 是他们迄今为止最“真实”、最可靠、最适合进行长链推理的旗舰模型。谷歌强调,这不仅是性能的提升,更是研究型智能体“可依赖性”的质变。
为了实现这样的智能体,谷歌采用了一种多步强化学习的训练策略,目标是让 AI 在复杂的研究任务中保持推理路径的稳定,减少出现错误的概率,并确保连续决策的一致性。
传统的 LLM 在长链推理中常常面临一个问题:每一步推理都可能引入误差——只要一个节点出错,整个结果就可能失效。谷歌在新版 Deep Research 中取得了重大突破:
-
优化决策序列的多轮强化学习
-
在冗长的任务链中显著减少逻辑偏差
-
更稳定的检索—分析—推理—引用闭环
新版的 Deep Research 让我们能做一些以前 LLM 无法完成的事情,比如进行跨天级的研究、政策评估、整合多种数据源,甚至是全流程的尽职调查,这真是太厉害了!
说到这次更新,Deep Research Agent 还有一个非常出色的特点,就是它的超大规模上下文处理能力。借助 Gemini 3 Pro 的强大支持,它可以一次性处理比以往更多的数据,包括各种学术论文、官方报告、甚至是长篇的网页内容。更重要的是,谷歌为 Deep Research 加入了一项“研究级标准能力”:每一个观点和结论都会自动附上可追溯的引用来源。这可不是简单的链接,而是精准指向原文中的关键段落,确保了输出的可信度和观点的透明性,用户还可以进行进一步的调查和审核。因此,Deep Research 的输出不仅仅是“生成内容”,而是“提供有证据支持的研究结果”。
这次的版本更新可不仅仅是功能的提升,谷歌其实是在构建一个“研究型智能体生态”系统。除了 Deep Research Agent 的更新,谷歌还推出了两项重要的新功能:全新开源网络研究智能体基准 DeepSearchQA 和交互 API。
在当前的行业中,网络研究智能体缺乏统一的评估标准。为此,谷歌创建了一个新的基准测试,名为 DeepSearchQA,专门测试智能体在复杂多步骤信息检索任务中的表现,而这个基准测试也是开源的。
DeepSearchQA 的开源地址:
https://www.kaggle.com/benchmarks/google/dsqa/leaderboard
DeepSearchQA 涵盖了17个领域的900道“因果链”任务,每一步都依赖于前面的分析。与传统的事实测试不同,DeepSearchQA 更注重全面性,要求智能体生成详细的答案集。这不仅考量了研究的准确性,还评估了信息检索的效果。
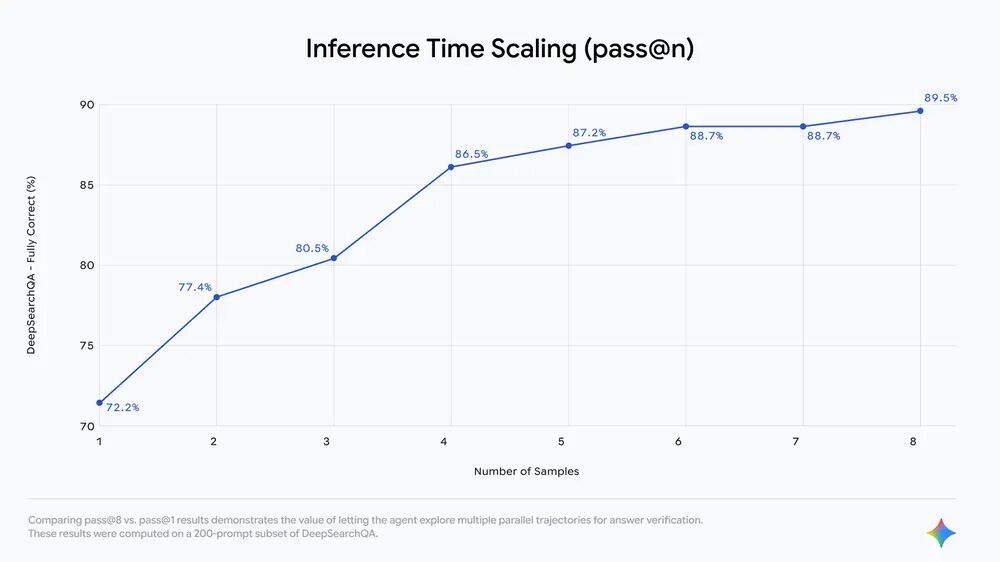
通过对比 pass@8 和 pass@1 的结果,可以看出让智能体同时探索多条路径来验证答案的价值,这些数据是基于 DeepSearchQA 的 200 个提示子集得出的。
全新的 Deep Research Agent 在“人类最后的考试”(HLE)和 DeepSearchQA 测试中取得了很好的成绩,并在 BrowseComp 测试中表现出色。它经过优化,能够更低成本地生成高质量的研究报告。
基准测试的结果令人惊喜。它基于 Gemini 3 Pro 核心构建,但采用智能体的工作流程来实现出色的性能。看看这些数据(来自图表):
-
人类的最后考试(HLE): 46.4%(大幅领先于 GPT-5 Pro 的 38.9%)
-
DeepSearchQA: 66.1%(稍微超过 GPT-5 Pro 的 65.2%)
-
BrowseComp: 59.2%(与 GPT-5 Pro 不相上下)

Gemini Deep Research 在“人类最后的考试”(HLE)数据集上取得了 46.4% 的成绩,在 DeepSearchQA 上获得了 66.1%,在 BrowseComp 上高达 59.2%。
Interactions API 是谷歌此次发布的一项重磅新功能,它让开发者首次能够以结构化的方式控制智能体的行为、推理步骤、长链任务的执行以及中间状态的存储。也就是说,以前开发者只能“问模型问题”,而现在他们可以“指导智能体如何完成任务”。
### 网友们怎么说?
谷歌推出新版 Deep Research Agent 后,技术界的反应引人注目。你看看在 Hacker News 和 Reddit 上,很多开发者都对谷歌这次把智能体真正做成工程化产品表示赞同。
在 Reddit 上,有个朋友感慨这项技术的进步,直言:“太不可思议了!我觉得我们还没有完全意识到!过去三年取得的进展真是让人难以置信!”
还有网友提到,谷歌首次在产品层面强调“可验证引用”和“端到端多步推理稳定性”,这在 AI Agent 领域算是一大步前进。一位从事合规审阅的用户表示:“如果 Deep Research 真能做到逐步链路可审计,那可是大厂第一次把 Agent 从玩具变成了生产工具!”
当然,也有一些声音持谨慎态度。一位 Reddit 用户批评道:“谷歌用自己设定的标准证明自己最强,这种情况可是屡见不鲜。我们需要的是在真实网页和任务中的第三方测试。”
谷歌的新 Agent 正好和 OpenAI 的 GPT-5.2 同一天发布,自然少不了网友们的比较。在 Reddit 上,有人询问这款 Deep Research Agent 和 GPT-5.2 的区别,另一位用户回复说,虽然用途不同,但 GPT-5.2 更出色。
为了更清楚地对比,网友们还找到了 OpenAI 研究员 Sebastien Bubeck 在 LinkedIn 上的发文。Bubeck 提到,GPT-5.2 在人类最后考试(HLE)中的得分是 45%,而谷歌的新 Agent 则是 46.4%,略微领先于 GPT-5.2。
谷歌与OpenAI的竞争日益激烈,你怎么看?
最近,谷歌和OpenAI的竞争越来越引人注目。有人甚至打趣道:“谷歌刚推出Deep Research,OpenAI立马就把Garlic(GPT-5.2)给端上来了,这俩公司简直是在争着发新闻。”
还有人总结说:“现在的竞争已经不仅仅是模型的较量,更是发布会的较量。”
模型能力的“贴身肉搏”愈演愈烈。
其实,基础模型的能力一直是这两家公司争夺的核心。
2025年初,谷歌推出了Gemini 3 Pro,凭借其更“真实”、更可靠和更低幻觉率的特点,力图在长链推理和专业任务中重树优势。Gemini 3 Pro还特别强调了检索增强、多模态处理能力和大规模上下文处理能力,在科研、法律和金融等高可信场景中表现得特别出色。
与此同时,OpenAI最新发布的GPT-5.2(Garlic)在逻辑一致性、工具调用稳定性以及智能体行为的自主性上也进行了强化,进一步提升了跨任务的泛化能力。内部的基准测试显示,GPT-5.2在推理、代码生成和多轮工具调度方面,依然保持着对Gemini的领先,特别是在OpenAI自研的“连续推理一致性Benchmark”中表现尤为突出。
现在,业界普遍认为两者的能力差距已经细微到“毫厘级别”,这意味着差距主要体现在特定的任务上,而不再是整体的优势。
基础模型决定了智能体是否能够思考,而智能体平台的能力则决定了它是否能有效执行任务。
谷歌对Gemini Deep Research Agent的全面重构,标志着其正式参与智能体战争的重要时刻。
新版Deep Research Agent有三大亮点:
-
基于Gemini 3 Pro全新重写的推理链路
-
采用多步强化学习训练,确保长链任务中的决策一致性,大幅降低幻觉概率
-
提供全链路引用,能够追踪每个观点的证据来源
这样一来,它不仅是一个“报告生成工具”,更是一个“能够执行完整研究任务的专业智能体”。而且,谷歌还推出了一个结构化控制智能体行为的Interactions API,允许开发者对智能体的每个阶段和子任务进行高度可控的调度和状态管理。这意味着Deep Research Agent不仅是谷歌产品线的一部分,而是一个通用的智能体执行引擎。
相比之下,OpenAI的智能体体系则更加注重通用性和灵活性。
Agent API、OpenAI Swarm、BrowserAgent和CodeAgent已经形成了一个完整的智能体开发框架,加上GPT-5.2在推理一致性上的提升,让其在自动化任务执行、工具调用复杂性和环境适应性上保持领先。
总的来说,双方竞争的关键在于:未来的软件开发将围绕智能体展开,而掌握智能体框架标准的公司,将主导新一代计算范式。
参考链接:
https://ai.google.dev/gemini-api/docs/deep-research?hl=zh-cn
Google launched its deepest AI research agent yet — on the same day OpenAI dropped GPT-5.2
声明:本文为InfoQ翻译整理,不代表平台观点,未经许可禁止转载。
今日好文推荐
InfoQ老友!请留步!极客邦1号客服上线工作啦!










谷歌的新智能代理真是突破性进展,未来可能彻底改变我们获取信息的方式。期待Gemini能带来更多惊喜!
谷歌的Deep Research Agent具备了强大的信息整合能力,未来的研究工作将变得更加高效,这真是让人期待!
谷歌的新Deep Research Agent的能力提升真让人惊叹,尤其是在复杂研究任务中的推理稳定性,未来或许能大大减少我们的工作负担。
谷歌的新Deep Research Agent确实令人兴奋,特别是在执行复杂任务时的稳定性和准确性,期待它如何改变我们的研究方式。
谷歌的Gemini Deep Research Agent看起来真的很有潜力,它的多步强化学习策略让我对长链推理充满期待,希望能减少错误率。
这次谷歌的更新真是大动作,Deep Research Agent的跨数据源整合能力让人印象深刻,未来的研究可能更加高效。
谷歌的Deep Research Agent在长链推理上的突破让我倍感振奋,未来能否真正实现高效的智能研究,值得期待。