你听说过吗?AI现在可以自动修复bug,成功率居然达到了44%!这可是全球开源模型的新高峰呀。
这个新模型是由蚂蚁团队推出的,它在SWE-bench Lite的测试中,竟然超越了所有的开源方案,性能上也和一些闭源模型不相上下哦。

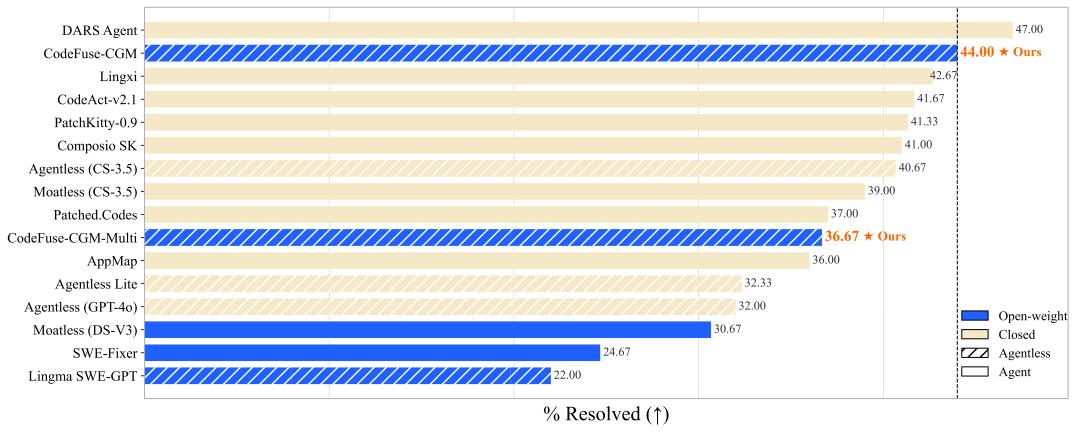
具体来说,在SWE-bench Lite上,这个新模型的表现非常亮眼:
- 在所有开源模型中,它的排名是 第一;
- 在所有开源系统中,它排在第六;
- 总体排名则是第14;
- 比现在排行榜上最优秀的开源模型“KGCompass”高出7.33%!
他们的创新之处在于将仓库代码图模态融入大模型(Code Graph Model, CGM),这样大语言模型就能更直接地理解代码图,从而更高效地修复bug和补全代码。
这意味着我们不再依赖那些黑盒模型(像GPT-4或Claude 3.7等)和复杂的Agent工作流程,简化了整个过程,实现了更加可控、透明和安全的自动化软件工程。
值得一提的是,CGM完全依赖开源模型。开源模型在SWE-bench上的表现通常不太理想,以前几乎所有顶级方案都是基于闭源模型的。而CGM基于Qwen模型,成功达到了与闭源模型相当的水平。
CGM只需要四个简单步骤就能迅速定位和生成补丁,省去了Agent方案中繁琐的编排过程,效率提升显著。

让AI真正理解大模型代码库
自从大模型的趋势兴起后,AI编程的速度也在飞速提升,特别是在处理一些简单任务,比如写函数方面,很多模型在HumanEval等基准测试中,准确率已超过90%了。
不过,真实的软件工程可没那么简单,仅仅“写一个函数”可不是全部。比如,修复Bug和增强功能这类工作,往往需要在多个文件和模块之间进行操作,还要理解项目里复杂的结构、依赖关系和类的继承体系。
现在很多人都在用基于闭源模型的Agent,这些工具能模拟程序员的行为,比如看代码、调用工具和进行多轮对话等,从而完成任务。
不过,这种方法也有一些问题:
- 行为路径难以控制,容易造成推理错误;
- 依赖于GPT-4、Claude等闭源模型,私有部署或者定制很麻烦;
- 工程成本高,效率不够理想。
而且,现在使用开源模型的方案,基本上很难达到最佳效果。
因此,研究团队提出了一个问题:有没有可能只用开源模型,不依赖Agent,来解决仓库级的任务呢?CGM就是在这样的背景下诞生的。
图结构与大模型的深入结合
CGM采取了一种类似于视觉语言模型(VLM)的跨模态建模方法。它将传统LLM的文本理解能力和代码仓库的结构图结合,形成了一种图-语言的多模态模型。这个模型的核心融合了两个方面:
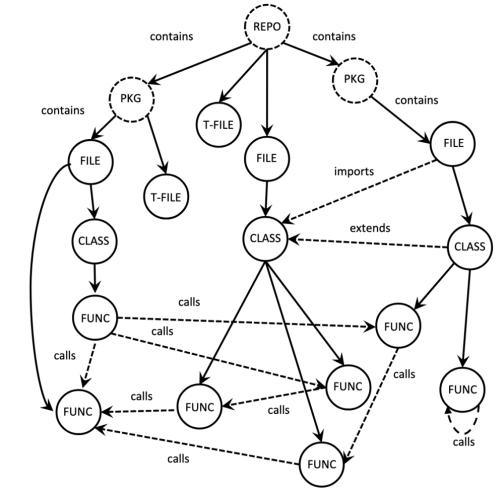
- 图模态:将仓库构建为结构化图,节点包括函数、类、文件、包等七种类型,边则表示调用、包含和继承等依赖关系;
- 语言模态:用户输入的自然语言描述和代码提示,推动模型生成补丁或回答。
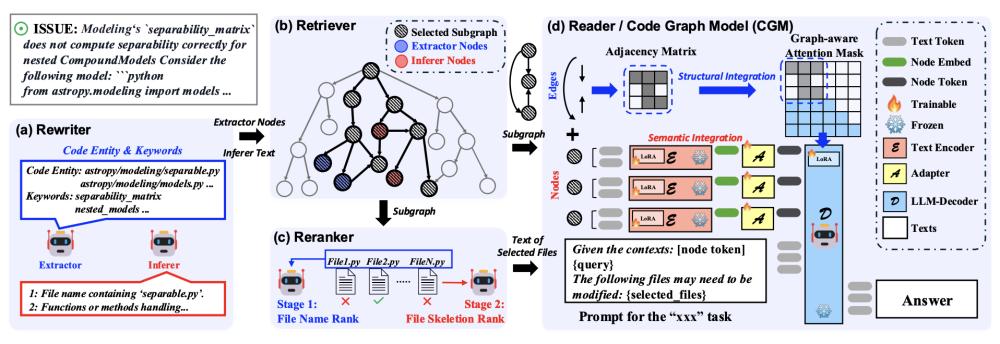
这个模型的输入是代码图和文本形式的提示,会在LLM中进行结构和语义的双模态对齐。
具体的结构融合方法如下:
使用小型编码器(CodeT5+)对每个节点进行编码,然后压缩成单个“节点token”,每个节点最多包含512个token的文本块。
接着通过一个适配器(一个两层的MLP)将编码后的节点表征映射到LLM的输入嵌入空间中。这相当于将LLM的上下文扩展了512倍,更好地处理海量代码仓库的上下文。
另外,还引入了图感知注意力掩码(Graph-aware Attention Mask),替代LLM中原有的因果注意力,使得注意力机制仅作用于相邻节点之间。就像GNN的消息传递机制一样,让LLM可以直接感知并利用代码的结构依赖关系。
两阶段训练:结构理解与问题泛化
基于这样的模型架构,团队通过两阶段的训练方式让LLM能够理解代码图的拓扑结构。
阶段一:子图重构预训练
为了让CGM能够有效捕捉代码图的语义和结构信息,团队设计了一个“图生代码 (Graph-to-Code)”任务。这个任务是从大型代码图中随机抽取子图(限制节点数量以控制输出代码长度),然后模型需要根据这些子图(只包含节点类型和连接关系,而没有完整的代码内容)重建出原始的代码片段。
随后采用层级化的方法,保持重建代码的结构一致性和可读性。根据拓扑排序和行号顺序来拼接仓库上下文:高级别节点(比如REPO、PACKAGE)放在输出序列或文件的开头;文件节点通过拓扑排序决定顺序;而文件内的节点(比如CLASS、FUNCTION)则按行号顺序拼接。
阶段二:噪声增强微调
在这个阶段,使用真实的GitHub问题-修复补丁数据对CGM进行微调。
模型学习如何基于两项输入生成代码补丁:(i) 一个相关的代码子图;(ii) 一段文本提示,指明需要修改的实际文件。为了提高模型的鲁棒性,提示中特意加入了10%的噪声输入:比如,提示中可能包含一个实际上不需要修改的不相关文件,或者遗漏至少一个应该被修改的关键文件。这样在训练中引入的受控噪声,有助于模型更好地适应信息不完整或受到干扰的实际输入场景。
推理阶段:Graph-RAG框架替代Agent
最后,为了进一步提升实际应用能力,CGM构建了一种无Agent的轻量化框架Graph-RAG。
这个框架还原了人类程序员修复Bug的工作流程,但效率比现有的Agent方案更高。
核心模块数量从10个精简到了4个:改写器→检索器→重排器→生成器(CGM模型)。
改写器(Rewriter):负责改写问题描述,提取关键词和相关文件;
检索器(Retriever):通过语义和结构进行检索,从代码图中抽取连通子图;
重排器(Reranker):对检索结果进行排序,选择最关键的文件用于生成;
生成器(Reader):结合子图与提示生成最终的修复代码。
基于这些,CGM在多个测试基准中取得了优异的成绩。具体来看——
实验结果
研究团队在多个主流基准上对CGM的性能进行了系统评估,涵盖了两个主要任务类别:(1)代码修复和(2)代码补全。
仓库级别的代码修复
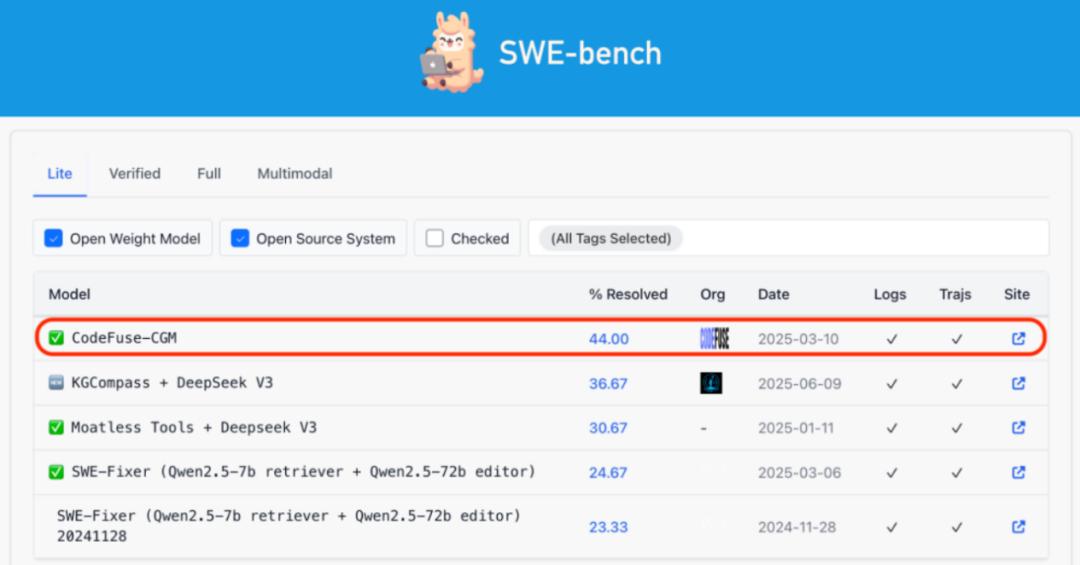
在SWE-bench Lite Leaderboard上,CGM以44.00%的成绩在开源权重榜单中位列第一。
CGM的强大表现与开源潜力
在SWE-bench Verified的评测中,CGM的表现真是让人眼前一亮,它比起最佳的开源基线提高了10.20%,达到了50.40%;
针对Java项目,CGM在SWE-bench-java Verified的得分是14.29%,这比最佳开源基线又提升了4.4%。
这些数据表明,CGM能够高效处理跨语言、跨项目的大型仓库中的Bug修复任务,展现了它卓越的结构理解和泛化能力。
仓库级别的代码补全
在复杂的代码生成任务中,CGM在ComplexCodeEval和CrossCodeEval的表现也远超同类开源模型,尤其是在需要跨文件推理和补全的情况下,效果更是惊人。
此外,研究团队还将CGM部署在不同的基座模型上(如CodeLlama-7B和DeepSeek-Coder-7B),并与最新的RAG系统进行了比较。结果显示,CGM具备出色的通用性,能够适配多种基座模型,并且在性能上超越了传统的RAG方法。
总的来说,CGM不需要复杂的Agent系统,首次将代码图模态与大模型结合起来,让AI像人类一样理解仓库中代码和文本之间复杂的依赖关系,真正实现了对项目的深刻理解。
更重要的是,它基于开源模型的设计,不拘泥于特定的模型,为企业和开发者提供了灵活、透明且可控的解决方案。
最后,CGM的技术论文、核心代码、模型权重和训练数据都已开源,对这些内容感兴趣的朋友可以进一步了解。
- 技术论文:链接
- 开源代码:链接
- 模型权重:链接
- 训练数据:链接
团队的过去工作:
最新技术动态:探索前沿的代码与语言模型
- 代码LLM的精彩综述:Awesome-Code-LLM(TMLR)
点击查看:Awesome-Code-LLM
- 图形与LLM的前期研究:GALLa(ACL 2025)
想了解更多?访问:GALLa
- 高效的注意力架构:Rodimus(ICLR 2025)
详细内容见:Rodimus
- 代码多任务微调框架:MFTCoder(KDD 2024)
获取信息请访问:MFTCoder
这篇文章来源于微信公众号“量子位”(ID:QbitAI),作者是明敏,经过36氪的授权发布。