想过没有,能够拥有一个理解你需求的助手,不仅能帮你写代码,还能洞悉整个项目的架构,修复那些难以发现的Bug,甚至从头开始构建一个完整的系统?
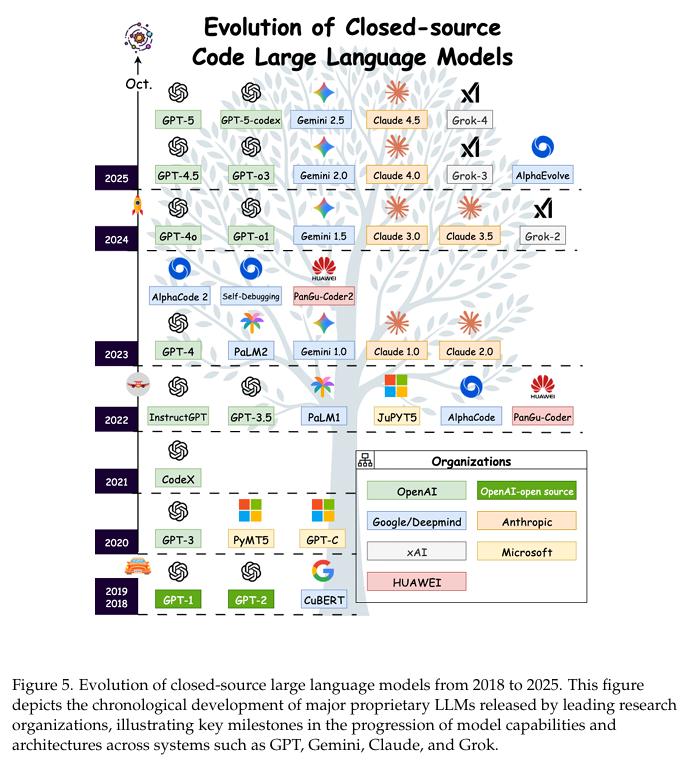
这已经不再是科幻小说中的情节,而是我们正在经历的现实。最近,有50位来自字节跳动、阿里巴巴、腾讯等科技巨头的AI研究人员,联手发表了一篇长达300页的论文,系统性地探讨了代码模型和智能体的相关领域。

图片
这篇论文的标题是《从代码基础模型到智能体与应用:全面调查和代码智能的实用指南》,它为我们展示了代码大语言模型(Code LLMs)如何从简单的辅助工具,逐步演变为能够独立执行复杂软件工程任务的智能体。
不仅仅是“补全”:代码大语言模型的演变之路
早期的编程辅助工具更像是“代码猜词工具”,只能根据上下文给出几个字词的提示。
图片
而现在的Code LLMs,已经具备了理解、推理、规划和执行的能力。研究指出,代码模型的发展经历了四个重要阶段:
- 第一阶段:专注于代码理解的编码器模型(比如CodeBERT),擅长代码分类和漏洞检测。
- 第二阶段:生成模型的出现(例如CodeT5),实现了代码的生成与翻译。
- 第三阶段:开源大模型的崛起(像StarCoder、Code Llama),在多个基准测试中与闭源模型相当。
- 第四阶段:走向智能化和超大规模的混合专家模型(MoE),这些模型不仅能编写代码,还能调用工具、与环境交互、完成多步骤的软件工程任务。
例如,DeepSeek-Coder-V2 拥有2360亿个参数,支持338种编程语言;而Qwen3-Coder已经具备调用浏览器、终端和编辑器的能力,形成智能工作流。这意味着,AI不再只是一个打字工,而是逐渐转变为真正的软件工程师。
模型是如何训练成“编程高手”的?
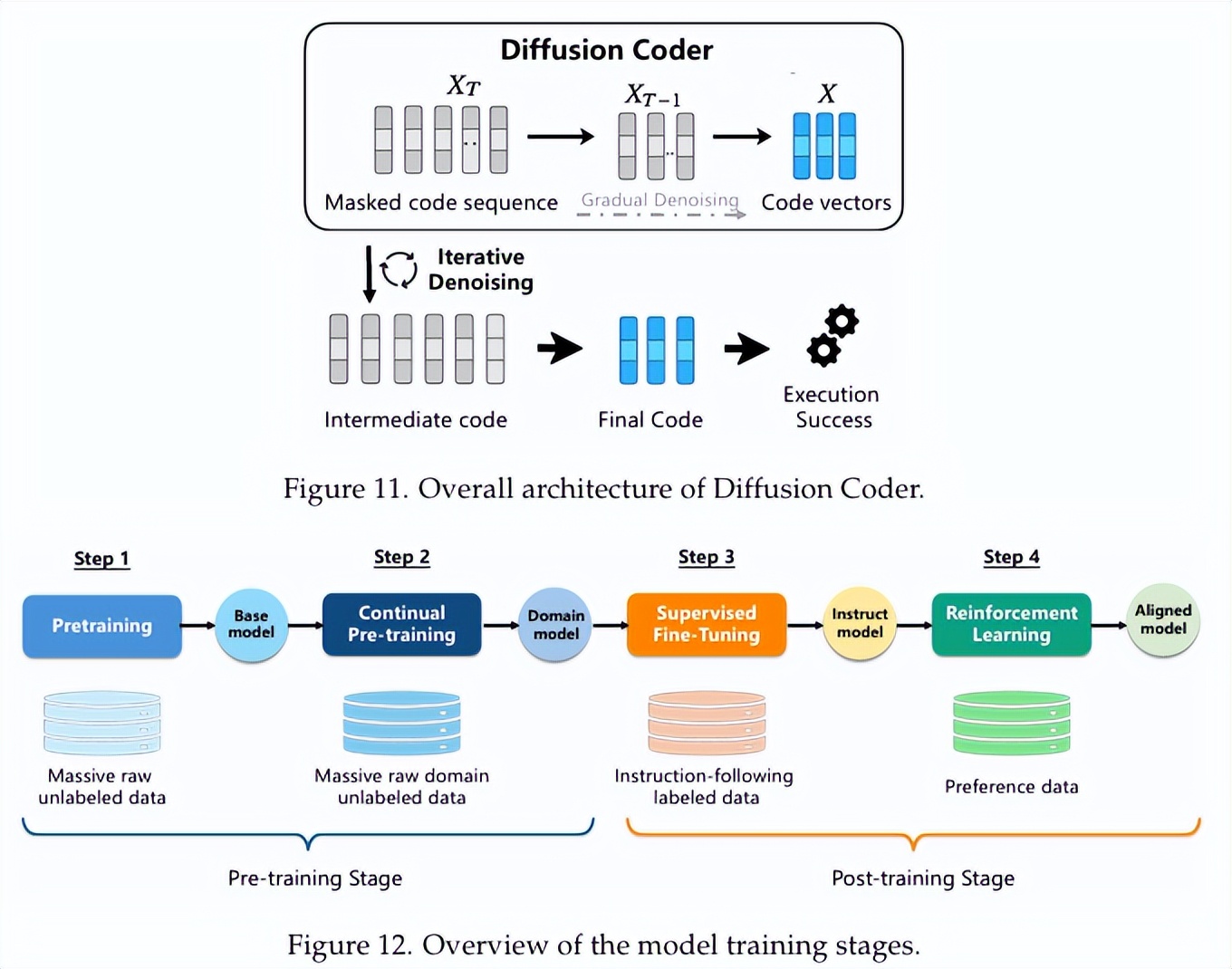
这项研究深入分析了Code LLMs的训练过程,分为两个主要阶段:
图片
未来编程新趋势:让AI成为你的编程小助手
- 首先,模型的预训练就像是给它提供了一个无尽的代码库,让它“阅读”各种编程语言的语法和逻辑。像The Stack v2这样的数据集覆盖了600多种语言,庞大的32TB数据经过严格筛选,确保了内容的高质量和合规性。
- 接下来是对齐训练,简单来说,就是通过监督微调和强化学习,让模型能够明白人类的指令,生成既正确又高效的代码。其中,基于可验证奖励的强化学习特别重要:模型生成的代码会被即时测试,通过与否来决定奖励,从而促使它不断提升。
这就像一个程序员的学习过程:先是学习经典代码,然后通过不断编写、运行和测试代码来提升实际能力。
评估AI的编程能力,不能只看代码能否运行
那么,怎么判断AI生成的代码是不是优秀呢?研究发现,评估标准已经不再是简单的“通过/不通过”,而是多维度的考量:
- 功能正确性:基本要求,得通过单元测试。
- 代码质量:包括效率(时间和内存使用)、安全性、可读性和标准符合性。
- 上下文理解能力:能否理解项目的整体结构,包括跨文件和跨模块的情况?
- 智能体能力:能否在真实环境中执行任务,比如终端、浏览器和GUI等?
比如,SWE-bench基准测试要求模型处理真实的GitHub工作任务,修复Bug或实现新功能。而Terminal-Bench则要求AI在真实终端中完成像“从源码编译Linux内核”这样的系统级任务。这些测试显示,AI编程正逐步从“模拟环境”走向“真实世界”。
这项研究的重要性在哪里?
这项研究不仅在于“整理现状”,更重要的是为未来指明方向。
- 为研究者提供了一幅全景路线图:系统梳理了从数据准备、模型架构、训练方法到评估标准的完整技术链,帮助减少重复探索的时间和资源。
- 为开发者揭示了实用的趋势:指出代码AI正朝向“专业化”(针对特定任务优化)、“智能体化”(具备自主交互和执行能力)、“科学化”(遵循可预测的扩展规律)三个方向发展。
- 推动行业应用与伦理安全:研究特别强调代码模型的安全性、合规性以及偏见问题,说明在追求能力的同时,必须建立数据追溯、漏洞防护和伦理对齐的机制。
总的来说,这项研究标志着“代码智能”领域从技术爆发期走向了系统化、工程化的成熟期。AI不仅是一个辅助工具,而是逐渐成为软件工程生态中的合作伙伴、自动执行者,甚至是创新的催化剂。
未来已经来临:你的AI编程伙伴正在路上
未来的软件开发,可能会呈现出“人类架构师 + AI执行者”的合作模式:人类负责需求提出、架构设计和代码审核,而AI则专注于实现细节、查找漏洞以及自动化测试和部署。
这项研究描绘的正是这样一个日益靠近的未来。同时,作为研究者,我们或许应该开始思考:如何更好地与AI协作?在学术研究和内容分析中,许多研究者正在利用智能化平台,将繁琐的数据处理、编码和分类工作交给AI来完成,而自己则专注于研究设计、逻辑框架和深入洞察——这与软件工程中“人类规划,AI实现”的理念不谋而合。