导读:现在通过先进的量化技术和模型优化,开发者能在普通的笔记本或台式机上运行强大的大语言模型,甚至当你的内存或虚拟内存不足8GB时。
很多人一提到大型语言模型(LLMs),脑海中往往浮现出那些庞大的云服务器和高昂的费用。
不过,现在人工智能的浪潮已经变得触手可及了。实际上,得益于量化和模型优化的进步,你完全可以在自己的电脑上运用这些强大的LLMs,哪怕你的RAM或VRAM不够8GB。接下来我们一起讨论如何将这些先进的AI技术带到你的本地机器上,还有哪些模型在行业中脱颖而出。
量化揭秘:小型LLM如何适应一般硬件
在我们深入了解最佳模型之前,先来解析一下推动本地LLM实现的技术背景。
关键在于量化,这是一种将模型权重从16位或32位浮点数压缩到4位或8位整数的技术,这样就能显著减少内存需求,同时保持质量几乎不变。
举个例子,一个原本需要14GB FP16的7B参数模型,通过4位量化后,仅需4-5GB的内存就能顺利运行。

关键技术概述:
- VRAM与RAM的区别:
VRAM(显存)速度快,适合用于LLM推理,而RAM(系统内存)虽然速度较慢但容量更大。为了实现最佳性能,建议将模型存放在VRAM中。
- GGUF格式:
- 量化类型:
- 内存开销:
- Ollama:
- LM Studio:
- Llama.cpp:
轻松搞定本地LLM的使用指南
量化模型的最佳选择,适合大多数本地推理引擎,操作起来真心方便。
说白了,Q4_K_M在质量和效率之间找到了很好的平衡;而Q2_K或IQ3_XS则更节省空间,但可能会牺牲一些输出质量哦。
记得留出模型文件大小的1.2倍来应对激活和提示上下文的需求,这样才能保证运行顺利。
开始使用:本地LLM的实用工具

这是一款专为开发者设计的命令行工具,可以在本地运行LLM。速度快、可脚本化,还可以通过Modelfile打包自定义模型,特别适合程序员和自动化爱好者。
如果你喜欢图形界面的话,LM Studio绝对是个不错的选择。它提供了精美的桌面应用,内置聊天功能,能够轻松从Hugging Face下载模型并调整参数,特别适合新手和不太懂技术的朋友。
这可是许多本地LLM工具背后的C++引擎,专为GGUF模型进行了优化,还支持CPU和GPU加速,真是个厉害的工具。
推荐:十款最佳小型本地LLM(全都低于8GB!)
1、Llama 3.1 8B(量化版)

ollama run llama3.1:8bMeta推出的Llama 3.1 8B可谓是通用AI的佼佼者,背后是庞大的训练数据和智能调优。
量化版本比如Q2_K(3.18GB文件,约7.2GB内存)和Q3_K_M(4.02GB文件,约7.98GB内存),让它在大部分笔记本上也能顺畅运行。它在对话、编码、摘要和RAG任务上都表现得相当出色,尤其适合批量处理和代理工作。
2、Mistral 7B(量化版)

ollama run mistral:7bMistral 7B是为了速度和高效而生,利用GQA和SWA技术达到顶尖性能。量化版本的Q4_K_M(4.37GB文件,6.87GB内存)和Q5_K_M(5.13GB文件,7.63GB内存)特别适合8GB的系统。
这个模型在实时聊天机器人、边缘计算设备以及商业应用中表现优异(使用Apache 2.0许可证)。
3、Gemma 3:4B(量化版)

ollama run gemma3:4b谷歌DeepMind推出的Gemma 3:4B虽然体积小,但性能却相当强大。它的Q4_K_M版本(1.71GB文件)在仅需4GB VRAM的情况下就能运行,非常适合移动设备和低配电脑,尤其适合文本生成、问答以及OCR任务。
4、Gemma 7B(量化版)

ollama run gemma:7bGemma 7B的性能可不容小觑,尽管它的体积相对较小,但在编程、数学运算和推理方面展现出了强大的能力。更棒的是,它能在8GB VRAM的设备上运行,Q5_K_M版本的文件大小为6.14GB,而Q6_K版本则为7.01GB。这个模型在内容创作、聊天以及知识工作中都会给你带来很大的帮助。
5、Phi-3 Mini(3.8B,量化版)
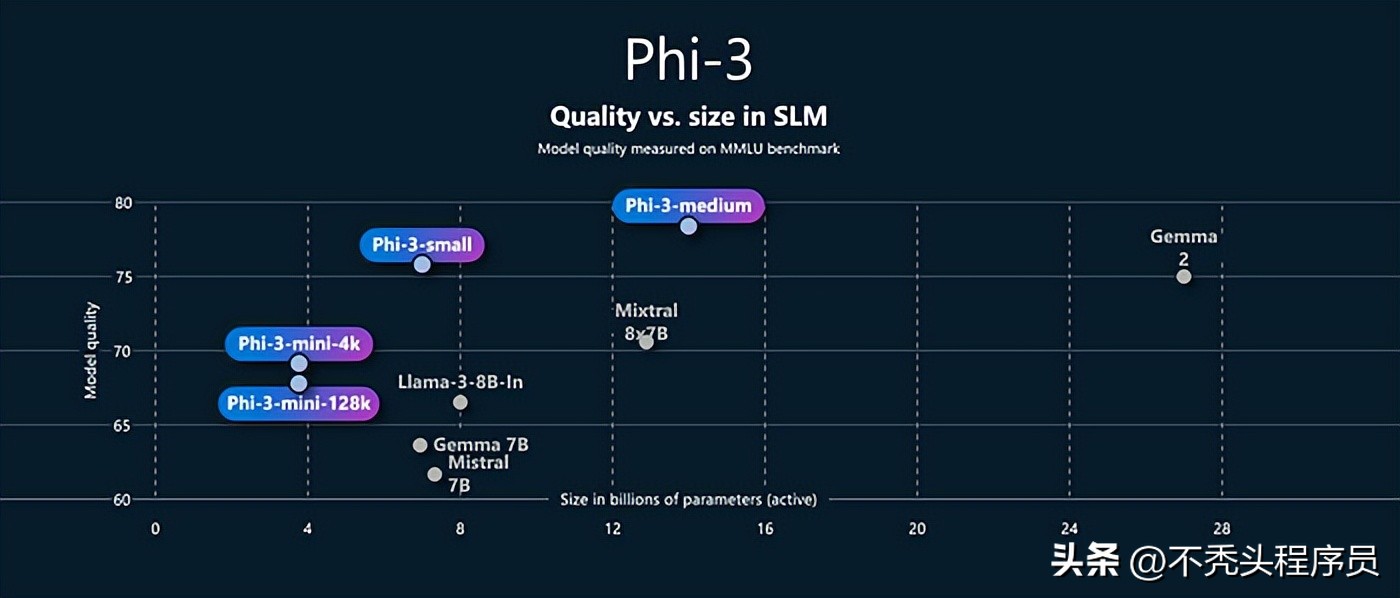
ollama run phi3微软推出的Phi-3 Mini是一款小巧却功能强大的工具,特别适合逻辑推理、编程和数学问题。它的Q8_0版本文件大小为4.06GB,内存使用在7.48GB之内,完美适配8GB的限制。无论是聊天、移动设备使用,还是需要低延迟处理的任务,它都能轻松应对。
6、DeepSeek R1 7B/8B(量化版)
ollama run deepseek-r1:7bDeepSeek的7B和8B型号,以其卓越的推理和代码处理能力而闻名。R1 7B的Q4_K_M版本文件大小为4.22GB,内存需求为6.72GB,而R1 8B则为4.9GB文件和6GB VRAM,两者都能在8GB的设备上顺利运行。这些模型非常适合中小企业、客户服务以及复杂的数据分析任务。
7、Qwen 1.5/2.5 7B(量化版)

ollama run qwen:7b阿里巴巴推出的Qwen 7B模型,不仅支持多种语言,还能处理丰富的上下文信息(32K tokens)。其中,Qwen 1.5 7B Q5_K_M的文件大小是5.53GB,而Qwen2.5 7B则是4.7GB(需要6GB VRAM),这些都非常适合用于聊天机器人、翻译和编程支持。
8、Deepseek-coder-v2 6.7B(量化版)
ollama run deepseek-coder-v2:6.7bDeepseek-coder-v2 6.7B简直是程序员的福音!经过专门的调整,它主要用于代码的生成和理解。只需3.8GB内存(6GB VRAM),就能成为本地代码补全和开发工具的最佳选择。
9、BitNet b1.58 2B4T

ollama run hf.co/microsoft/bitnet-b1.58-2B-4T-gguf微软的BitNet b1.58 2B4T是一款效率惊人的模型,采用1.58位权重,运行只需0.4GB内存。它特别适合用在边缘设备、物联网和纯CPU推理的场景,比如设备上的翻译和移动助手。
10、Orca-Mini 7B(量化版)
ollama run orca-mini:7bOrca-Mini 7B是基于Llama和Llama 2构建的灵活模型,适合聊天、问答和执行指令。无论是Q4_K_M(文件大小4.08GB,内存需求6.58GB)还是Q5_K_M(文件大小4.78GB,内存需求7.28GB),在8GB的设备上都能顺畅运行。它是开发AI代理和对话工具的绝佳选择。
结语
这些模型,如Llama 3.1 8B、Mistral 7B、Gemma 3:4B和7B、Phi-3 Mini、DeepSeek R1、Qwen 7B、Deepseek-coder-v2、BitNet b1.58以及Orca-Mini,都证明了其实你并不需要一台超级计算机,AI也能轻松驾驭。
这些成果得益于量化和开源的创新,使我们能够在日常的普通硬件上运行尖端的语言模型。
总结一下,为什么大语言模型的本地化运行如此重要:
为什么选择本地AI模型?
- 隐私性:
数据保存在本地,不依赖云端,安全更有保障。
- 成本降低:
不需要额外的订阅费用或云服务支出,省钱又实惠。
- 速度快:
反应迅速,即使在离线情况下也能保持流畅。
- 灵活性:
可随意进行实验、定制,部署到任何你想要的地方。
随着量化技术和边缘AI的不断进步,未来我们会看到更多强大的模型在更小的设备上运行。让我们一起深入探索,勇于尝试,找到最适合自己工作流的大语言模型吧!
参考:
https://garysvenson09.medium.com/10-must-try-small-local-llms-that-run-on-less-than-8gb-ram-vram-aea836d8a85b