Cursor 刚刚发布了一个新概念叫 “动态上下文发现” (Dynamic Context Discovery)。这听起来很技术,但其实是它变聪明、变快、变省钱的关键。
简单总结就是:Cursor 不再让 AI “死记硬背”,而是教会了它“随查随用”。

一个比喻秒懂(核心原理)
以前(静态上下文): 就像让学生去考试,必须把所有的教科书、笔记、参考资料全部背在身上带进考场。包太重(Token 消耗大),找资料翻半天(反应慢),而且书太多容易看岔眼(信息干扰导致回答不准)。
现在(动态上下文): Cursor 允许学生带一台可以查阅“图书馆索引”的终端。学生只需要记住目录,遇到难题时,再去书架上精准调取那一本书。既轻松,又精准,还省脑子。
这个“黑科技”带来了哪 5 个大变化?
Cursor 现在的逻辑是:把一切复杂信息都存成“文件”,AI 需要时自己去读文件,而不是一股脑塞进对话框里。

超长报错不再被截断:以前报错太长,AI 只能看到一半,经常瞎猜。现在 Cursor 把长日志存成文件,AI 可以自己去翻阅文件的最后几行,看清楚完整的错误原因。
记忆力超强提升:聊太久了,前面的对话会被“压缩”成摘要,容易丢细节。现在 Cursor 把完整聊天记录存成文件,AI 觉得摘要看不懂时,会自己去翻“历史档案”,找回遗忘的细节。
工具再多也不卡:以前加载一堆插件/工具会让 AI 变慢。现在 AI 只看工具的“名字”,只有确定要用某个工具时,才去读它的具体说明书。(这让 Token 消耗直接减少了近一半!)
技能包按需加载:不同的编程任务需要不同的技能(Skills)。现在这些技能像“外挂”一样存着,AI 只有在需要时才会挂载对应的技能包,而不是时刻背着所有技能。
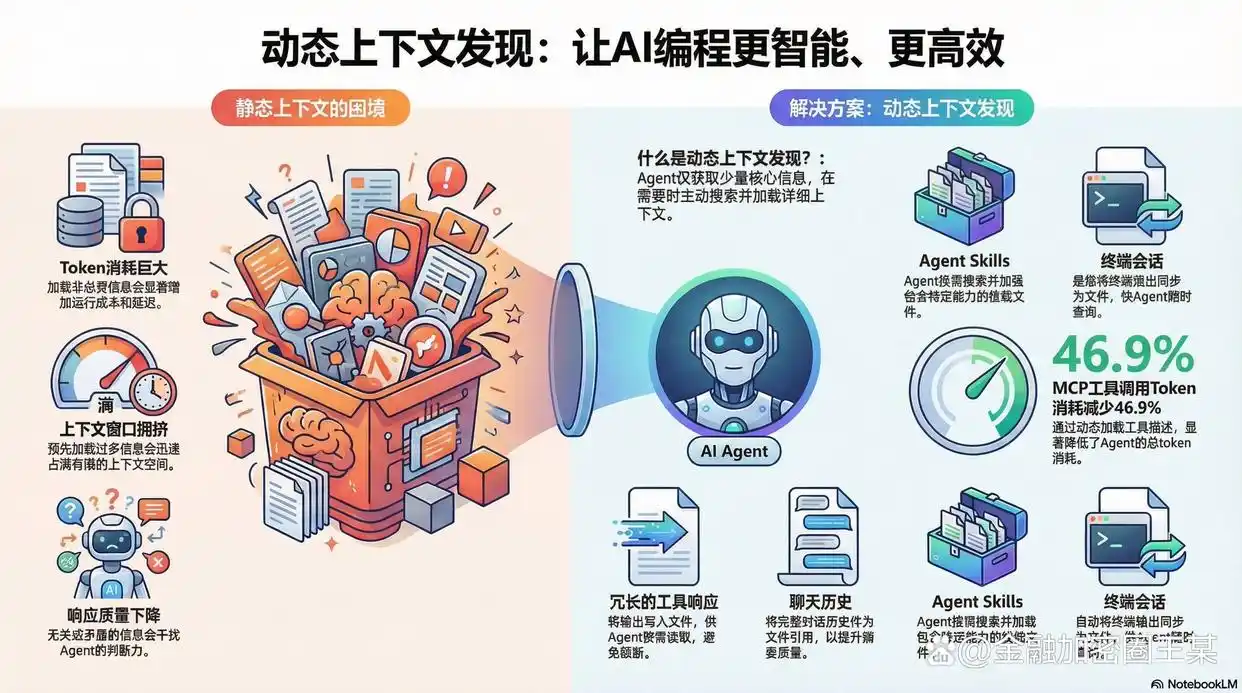
不用再复制粘贴终端报错:你在终端(Terminal)里的所有输出,Cursor 都自动同步成了文件。AI 可以直接“看到”你的终端发生了什么,不用你手动复制报错信息给它。
声明:
文章来自网络收集后经过ai改写发布,如不小心侵犯了您的权益,请联系本站删除,给您带来困扰,深表歉意!









这个动态上下文发现的概念非常有趣,确实能让AI更智能、更高效,期待它的实际应用效果。
虽然这个新概念听起来不错,但我还是有点担心它在复杂场景下的表现,能否真正做到精准调取信息呢?
建议在使用时提供更多的示例,帮助用户更好地理解如何利用这个新功能,提高上手的便利性。
动态上下文的操作方式确实很新颖,但希望在实际操作中不会因为文件管理而影响使用体验。
动态上下文发现的思路很不错,但我担心在信息量大时,AI能否有效管理和调取这些文件,是否会导致反应变慢?
希望在更新中能增加用户操作指南,特别是针对新手用户,让大家更快掌握这个动态上下文的使用方法。
这个新概念确实很有潜力,让AI更灵活。但也希望在后续的迭代中注意文件安全性,避免数据泄露的风险。