最近,Cursor 更新了版本,结果不再能像以前那样轻松“薅羊毛”了,真让人怀念啊!有没有什么解决办法,或者更好的使用方式呢?
大家好,我是十二,专注分享AI编程的内容,欢迎大家来关注我哦。
你可能感兴趣:想轻松掌握cursor编程?来听大瑜聊聊AI!
就在不久前,Cursor 推出了最新的 OpenAI Codex 模型,名为 GPT-5.1-Codex-Max,并且宣布在 12 月 11 日之前都可以免费使用,真是个好机会呢!
此外,Cursor 团队还特意撰写了一篇文章,讲述为了让 GPT-5.1-Codex-Max 模型在 Cursor 中能更顺畅地工作,他们做了哪些优化。
这篇文章内容挺有趣的,里面有很多实用的细节,咱们一起来看看吧。
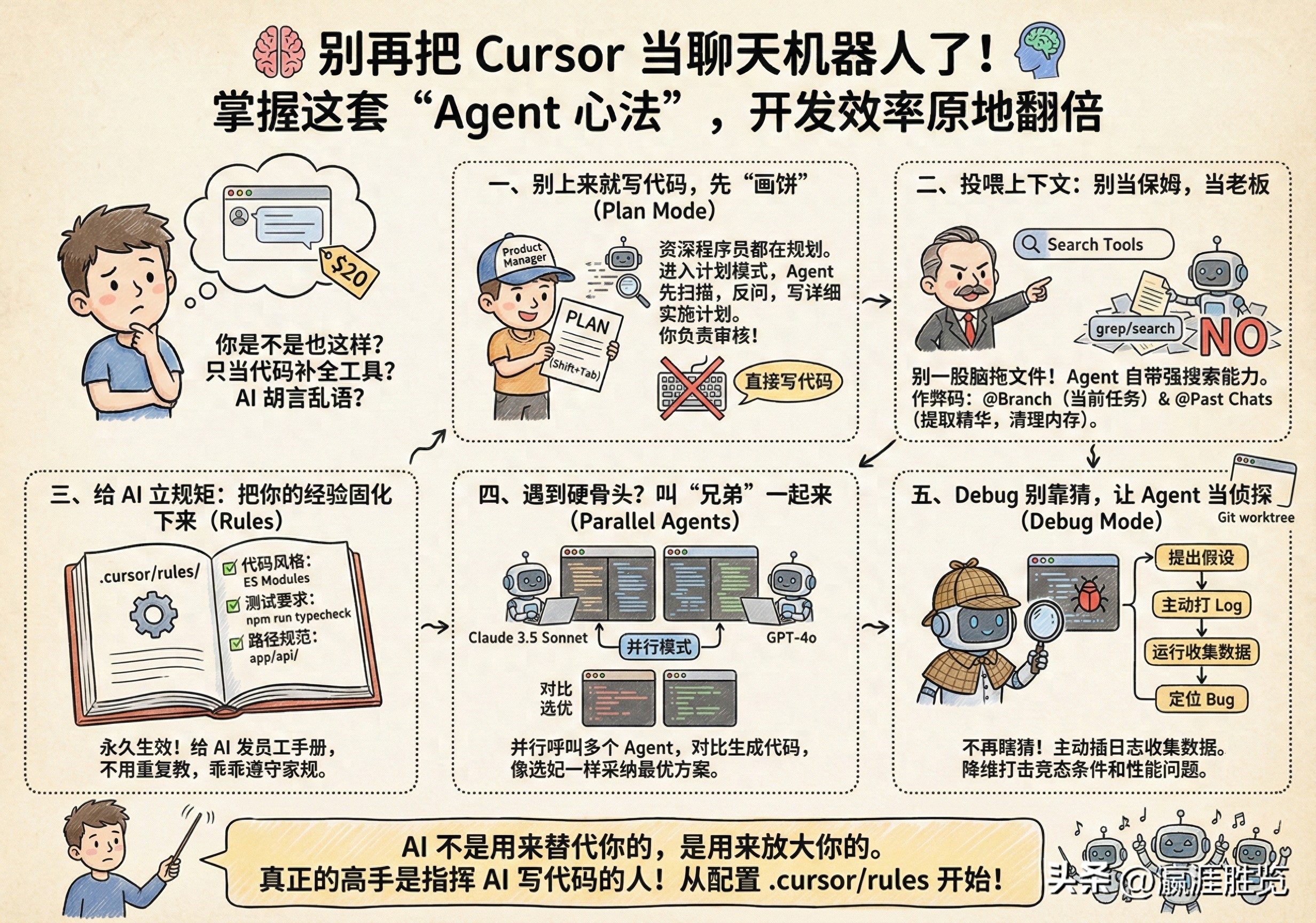
构建强大的 agent harness
在 Cursor 中,harness 是一个非常重要的 agent,每个模型都需要特定的指令和针对性调整,以提升输出质量,避免模型偷懒,并更有效地调用工具。
直接上线模型往往会出现问题,因为模型在训练时接触到的内容各不相同,所以 Cursor 团队需要对这些模型进行一轮本地化的调校。
他们会利用像 Cursor Bench 这样的内部评测工具,不断测试模型,最终通过成功率、工具调用能力以及用户的反馈来判断模型是否准备好上线。
Cursor 团队为 Codex 进行的重要更新
OpenAI 的 Codex 系列模型是他们最新前沿技术的一些变体,专门为 agentic 编码场景进行训练。为了确保 Codex 在 Cursor 中稳定运行,Cursor 团队做了不少调整。
1. 更贴合 shell 的操作习惯
Codex 的训练更偏向于命令行(CLI)或 shell 的工作流,它习惯用 shell 来查找文件、读取文件和进行编辑。
为了避免 Codex 在 Cursor 中随便运行 shell 命令,Cursor 团队将工具名称改得更像 shell 工具(比如 rg),并明确告知模型:如果有工具可用,优先使用工具,而不是直接用 shell 命令。
此外,Cursor 的沙箱机制能确保即使 Codex 真的执行了 shell 命令,也不会造成安全隐患。这种设计既不影响 Codex 的使用习惯,又增强了操作的可控性。
2. 控制“推理摘要”的输出
在执行过程中,Codex 会输出一些“推理摘要”。Cursor 团队希望这些信息能帮助用户了解进度,但又不想太冗长,于是他们在提示中进行了规定:
推理摘要保持在 1–2 句
仅在发现新信息或策略切换时出现
不要写“我正在解释给用户听”这种元话语有趣的是,Cursor 团队发现,减少这些中途沟通的要求后,Codex 的最终输出质量反而提高了。
3. 处理 linter 错误
Cursor 团队为 agent 提供了读取 linter 错误的工具。理论上来说,模型在修改代码后应该主动检查 lint,但实际上,单单提供工具定义是不够的,还需要明确告诉模型“什么时候该用这个工具”。
因此,Cursor 团队直接给出了非常明确的指令,例如:
在进行实质性编辑之后,使用 read_lints 工具检查最近编辑的文件是否存在 linter 错误。如果你引入了任何错误,并且你能很容易地找到解决方法,就去修复它们。这种直接的说明方式反而最有效,让 Codex 能够主动执行标准化流程。
4. 保留推理轨迹
这一点非常关键。Codex 在调用工具时需要依赖内部推理轨迹来维持计划的连贯性。如果这些轨迹丢失,模型就会忘记之前做过什么,甚至不知道为什么这样做,这样性能自然会大幅降低。
实验显示,推理轨迹丢失会导致 Codex 性能下降约 30%。
为了避免这种情况,Cursor 团队加入了一个机制,确保推理轨迹能够在多轮中正确传递,让模型的计划始终保持连贯。
5. 引导模型主动解决问题
Cursor 的目标是,除非用户明确表示“不要动代码”,否则 agent 应该主动尝试解决问题,而不是反复询问。
Cursor 团队在提示中清楚地写道:
除非用户明确要求查看计划或其他明确表示不应写代码的意图,否则假定用户希望你进行代码更改或运行工具以解决问题。在这些情况下,把拟议解决方案输出为消息是不合适的,你应该直接去实现更改。如果遇到挑战或阻塞,你应该尝试自行解决。这样的调整使得 Codex 的行为更加果断,减少了用户的等待时间,整体体验也变得更加流畅。
6. 避免提示之间的冲突
由于 OpenAI 模型非常依赖提示的顺序(系统提示 > 用户提示 > 工具提示),Cursor 团队必须非常谨慎地处理系统提示中的每一句话,以免无意中压制模型完成任务的积极性。
他们举了一个例子:如果系统提示强调“节省 tokens”,这条信息可能会影响模型执行更复杂任务的意愿。
有时,Codex 会固执地说,“我不应浪费 tokens,我觉得这个任务不值得继续!”
因此,Cursor 团队调整了 harness,确保 Cursor 提供的提示不会无意中与用户的请求相矛盾。否则,Codex 可能会陷入一种不愿意满足用户请求的状态。
总结
通过这次 Codex 的适配过程,我们可以看到,模型的能力越强、agent 的行为越复杂,对工具链、提示设计和推理轨迹的管理要求就越高。
Cursor 团队的做法值得我们借鉴——既关注模型本身,也关心模型在实际应用中的稳定性,这样才能充分发挥每个模型的潜力。






推理摘要减少了,输出质量反而提高,这个结果真是让人惊讶。是什么原因导致的呢?
我尝试过使用Cursor的沙箱机制,确实感觉安全性大幅提高,值得推荐给大家。
希望未来能看到更多关于优化过程的具体案例分享,这样大家都能更好地理解这些改进。
我记得之前用Cursor时,有些命令会直接出错,现在有了linter工具,感觉编程效率提升不少。
Cursor的更新让我想起了以前薅羊毛的日子,真是怀念啊!希望能找到新的使用技巧。
听说新模型的使用体验提升了不少,谁能分享一下实际效果如何?
我在使用过程中发现,如果适应新的推理摘要规则,实际上可以更快地理解代码执行情况。
这个更新让我想起了之前的使用体验,有没有其他人也觉得怀念?
我觉得减少中途的沟通确实能让输出更集中,能否再分享一下其他的使用心得?
更新后使用体验的确有变化,特别是对linter错误的处理,算是个进步。
这个更新让我想起了之前薅羊毛的乐趣,有没有人找到新的薅法?
感觉新版本处理 linter 错误的确不错,之前总是被这些错误搞得头疼。