记者闫俊文 编辑张晓迪
在2月份的论文“撞车”事件后,梁文锋和杨植麟又在新的大模型领域相遇了。
4月30日,DeepSeek推出了他们的新模型DeepSeek-Prover-V2,专门用于数学定理的证明。
Prover-V2的参数规模达到了671B(6710亿参数),相比之前的V1.5版本的7B,增加了近百倍,这使得它在数学测试集上的效率和准确性都得到了显著提升,比如,这个模型的miniF2F测试通过率高达88.9%,并且成功解决了普特南测试中的49道题目。
有趣的是,在4月中旬,月之暗面也发布了一个用于形式化定理证明的大模型Kimina-Prover,这是Kimi团队与Numina共同开发的产品,并且开源了1.5B和7B参数的模型蒸馏版本。这个模型在miniF2F测试中的通过率为80.7%,在普特南测试中解答了10道题。
从比较来看,DeepSeek-Prover-V2在miniF2F测试和普特南测试的表现都超越了Kimina-Prover的预览版本。
值得留意的是,两家公司在技术报告中都提到了强化学习。例如,DeepSeek的报告标题为《DeepSeek-Prover-V2:通过子目标分解的强化学习推动形式数学推理》,而月之暗面的则是《Kimina-Prover Preview:基于强化学习技术的大型形式推理模型》。
在2月的那两篇“撞车”论文中,梁文锋和杨植麟都是作者,这两家公司都聚焦于Transformer架构中的注意力机制,特别是如何让模型更有效地处理长上下文。
作为中国大模型领域备受关注的创业者,他们也面临着各自的挑战。
对梁文锋来说,自从R1模型发布超过三个月后,外界对DeepSeek的关注度似乎在减弱,阿里巴巴的开源模型正迅速迎头赶上并可能超越DeepSeek,大家都在期待他们能尽快推出R2或V4模型,以巩固他们的领先地位。
而对于杨植麟和月之暗面,Kimi正在面临字节跳动的豆包和腾讯元宝的竞争,他们也必须不断创新以保持市场活力。

编程与数学,通向AGI的两条路
谈到AGI的实现之路,2024年,DeepSeek的创始人梁文锋在接受《暗涌》采访时表示,他们确实在三个方向上有所布局:首先是数学和代码,其次是多模态,最后是自然语言本身。数学和代码就像围棋一样,是一个封闭且可验证的系统,可能通过自我学习实现高智能;而多模态则需要与人类真实世界的互动学习。他们对所有可能性持开放态度。
这次Prover-V2模型的发布,确保了DeepSeek各个模型的同步进化。
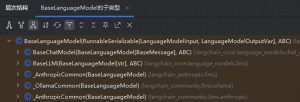
Prover系列模型从2024年3月开始发布,到了2024年8月更新为DeepSeek-Prover-V1.5(简称Prover-V1.5),2025年4月再升级到DeepSeek-Prover-V2。
DeepSeek的代码系列模型Coder从2024年4月开始更新,6月升级为Coder-V2-0614,7月再次升级,9月DeepSeek-V2-Chat和DeepSeek-Coder-V2合并,形成了新的DeepSeek-V2.5,2024年12月更新至V3,今年3月升级至V3-0324。

通用推理大模型,以1月20日发布的R1模型为例,具有较低的价格,自然语言推理能力出色,在数学、代码和自然语言推理等任务上,表现不亚于OpenAI的o1正式版。
从Prover-V2的技术报告来看,它与DeepSeek其他模型的进化是相互关联的,DeepSeek-Prover-V2-671B是基于DeepSeek-V3进行微调的。在冷启动阶段,DeepSeek-V3会将复杂问题拆分为一系列子目标,接着解决这些子目标的证明会被整合到一个思维过程链中,结合DeepSeek-V3的逐步推理,形成强化学习的初始冷启动。
算法工程师、知乎用户“小小将”告诉《中国企业家》,推理模型在进行推理时需要复杂的思考,而代码和数学模型恰好可以验证推理大模型的能力进展,因为数学和代码的结果是可检验的。
他认为,Prover-V2的发布与新模型R2或V4的上线并没有直接关系,更像是独立的模型更新。
他预测,R2模型的开发过程可能会比较快,类似于GPT-o1到o3的演变,尤其是在强化学习能力提升方面,DeepSeek可以基于V3来提高后续的训练效果。而V4则可能是一个大版本的更新,研发周期较长,因为预训练的工作量和训练方法可能会有所变化。
目前市场对DeepSeek的新模型充满了期待和想象。
市场上有传言称R2模型将基于华为的昇腾系列GPU芯片推出,但一位行业人士表示,这个消息不太靠谱。因为在英伟达H20芯片被限制后,昇腾系列芯片在市场上也显得供不应求,“如果用于大模型研发,昇腾的鲁棒性可能不够强”。
DeepSeek与Kimi的未来究竟如何?
有创业公司的人士向《中国企业家》透露,华为的昇腾芯片在训练大模型方面效果并不理想,主要是因为其生态系统还不够成熟。不过,用于大模型的推理和部署,倒是没啥问题。

DeepSeek能否继续领先?
作为备受瞩目的初创公司,DeepSeek和月之暗面在激烈的市场竞争中面临着被大企业赶超的压力。
就拿月之暗面旗下的Kimi来说,根据QuestMobile的数据,Kimi上线不到一年,到了2024年11月,月活跃用户突破了2000万,仅次于豆包的5600万。
截至2025年2月底,AI原生应用的月活跃用户排名发生了变化,前几名从豆包、Kimi、文小言变成了DeepSeek、豆包和腾讯元宝,用户规模分别为1.94亿、1.16亿和0.42亿。
2月中旬,腾讯元宝宣布与DeepSeek合作,紧接着,凭借超级产品微信的引流和大量的广告支出,腾讯元宝在用户数量上已超越Kimi,成为第三大AI产品。根据AppGrowing的数据,今年第一季度,腾讯元宝的广告投入达到14亿元,远超Kimi的1.5亿元。

如今,Kimi正在测试社区功能,旨在增强用户的粘性。
而DeepSeek同样面临着大企业带来的竞争压力。最近,阿里巴巴在大模型领域展现出了强大的实力。
在4月29日,阿里巴巴发布了新一代的通义千问模型Qwen3,这个模型被称为“混合推理模型”,它结合了“快思考”和“慢思考”,参数量仅为DeepSeek-R1的三分之一,性能全面超越了R1和OpenAI的o1等同类产品。
蔡崇信曾对DeepSeek做出评价,说明了开源的重要性。公开数据显示,阿里通义已经开源了超过200个模型,全球下载量超过3亿次,千问的衍生模型数量超过了10万个,已经超越了美国的Llama,成为全球开源模型的领导者。
一位AI创业者向《中国企业家》表示,DeepSeek受到了过多的关注和赞誉,其实中国的大模型市场需要两到三个世界级的大模型,而不是仅仅一个。这个领域的竞争和创业应该得到鼓励。
百度也是一个重要的竞争者。4月25日,百度推出了文心4.5 Turbo和深度思考模型X1 Turbo,这两个模型的性能更强、成本更低。李彦宏也提到DeepSeek,他指出DeepSeek并非全能,处理的内容主要是文本,无法理解声音、图片和视频等多媒体信息,且在某些场合的幻觉率较高,使用时需谨慎。
李彦宏在发布会上直言:“DeepSeek最大的问题是速度慢和价格高,目前市场上大多数大模型的API价格都更低,反应速度更快。”
尽管如此,百度还是决定向DeepSeek学习。今年2月,百度宣布将在6月30日开源文心大模型4.5系列。
越来越多的公司参与到大模型的开源竞争中,但只有技术最先进的公司才能引领标准的制定。
最近的热门新闻:
被丈夫抛弃的山东女性,凭借卖饺子年收60亿,成为“水饺皇后”!
⭐记得关注华尔街见闻,精彩内容不容错过⭐
以上内容不构成任何投资建议,也不代表平台立场。市场存在风险,投资需谨慎,请自行判断和决策。









梁文锋和杨植麟的竞争真是越来越激烈,DeepSeek-Prover-V2的表现让人期待,数学定理证明的效率提升确实很重要。希望他们能继续引领这个领域的创新。
DeepSeek-Prover-V2的参数规模和表现都让人惊叹,数学领域的进步离不开这样的创新。期待这场竞争能带来更多突破。
DeepSeek-Prover-V2的参数大幅提升真是令人振奋,这样的进步对数学定理证明来说至关重要。希望未来能看到更多的突破。
DeepSeek-Prover-V2在数学证明领域的表现令人印象深刻,参数增长如此显著,期待它能为更多数学问题带来解决方案。
DeepSeek-Prover-V2的推出标志着数学证明领域的一次重大飞跃,671B的参数规模让人对未来的可能性感到兴奋,期待它能解决更多复杂问题。
DeepSeek-Prover-V2的推出让人看到了数学证明领域的新希望,671B的参数规模无疑是巨大的进步,期待它能解决更多复杂问题。
DeepSeek-Prover-V2的参数规模真是让人刮目相看,671B的设计让数学定理证明的效率有了质的飞跃,希望未来能看到更多创新成果。
这场DeepSeek与月之暗面的较量真是让人期待,特别是两家在模型参数和测试成绩上的差距,未来谁能脱颖而出呢?