文 | 字母AI
最近,九坤投资旗下的至知创新研究院推出了一个名为IQuest-Coder-V1的开源编程Agent模型。虽然至知在AI圈子里的名气不算大,但这个模型的基准测试数据却毫不逊色于行业顶尖水平。
而且,九坤投资作为一家量化私募,发布的时间恰好是在1月,这让人不由得联想到去年DeepSeek R1发布时的情景。
实际上,去年DeepSeek R1登场时也是类似的情况,一个相对不知名的公司推出了一个行业领先的模型。
那么,IQuest-Coder-V1会不会成为下一个“DeepSeek时刻”呢?
这个问题目前还没有明确的答案。
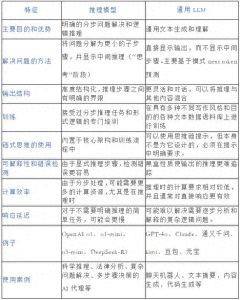
根据JetBrains发布的《2025开发者生态系统现状报告》,全球有85%的开发者已经在使用AI工具,而41%的代码都是由AI生成的。不过,现有的工具大多只是辅助性质。
从OpenAI到Anthropic,各大公司在2025年底推出的Agent产品,代码是它们的切入点。
所以可以肯定,编程Agent将会是未来的重要趋势。
01
IQuest-Coder-V1并不仅仅是一个简单的代码补全工具,它是一个可以独立完成软件工程全流程的大型语言模型。
以往的AI编程助手主要是帮你自动补全代码,比如你写到一半,它来接上。而IQuest-Coder-V1则可以从零开始,理解需求、设计架构、编写代码、测试调试,甚至进行多轮优化迭代。
IQuest-Coder-V1有三个非常重要的技术特点。
首先是40B的参数规模。与GPT-5和Gemini 3等动辄上千亿参数的模型相比,40B的参数量显得微不足道。
这意味着,IQuest-Coder-V1能够在性能相对较好的消费级硬件上运行,而无需依赖专业的数据中心级算力。
第二个特点是Loop架构。
这个名字很直接,模型会对自己的输出进行循环迭代。就像程序员在写完代码后会回头检查和修改一样,Loop架构使模型在生成代码后能进行反思和改进。
不过,Loop架构并不是简单的重复调用,而是将迭代优化过程深度融合到模型架构中。简而言之,IQuest-Coder-V1会超额完成任务,确保最终结果能够满足用户需求。
Loop版本让模型在相同的神经网络中“走两遍”,就像你在阅读文章时可能会回头重读关键段落,第二遍往往能发现第一遍遗漏的问题。
第三个特点是code-flow训练范式。
传统的代码模型主要学习代码片段,关注的是静态语法和API调用模式。简单来说,AI可以完美复刻学习到的代码,却不理解为什么这样写。
而IQuest-Coder-V1则关注软件如何逐步演变,学习的是动态的逻辑过程。这使得模型不仅能理解“这段代码是什么”,还明白“这段代码为什么这样写”、“下一步应该如何改进”。
IQuest-Coder-V1使用了32k条高质量轨迹数据进行强化学习,这些轨迹是通过多代理角色扮演自动生成的。
系统模拟用户、Agent和Server三方的互动,用户提出需求,Agent编写代码,Server返回执行结果,整个流程无需人工干预。训练的目标并不是单次代码生成,而是完整的软件演化过程。
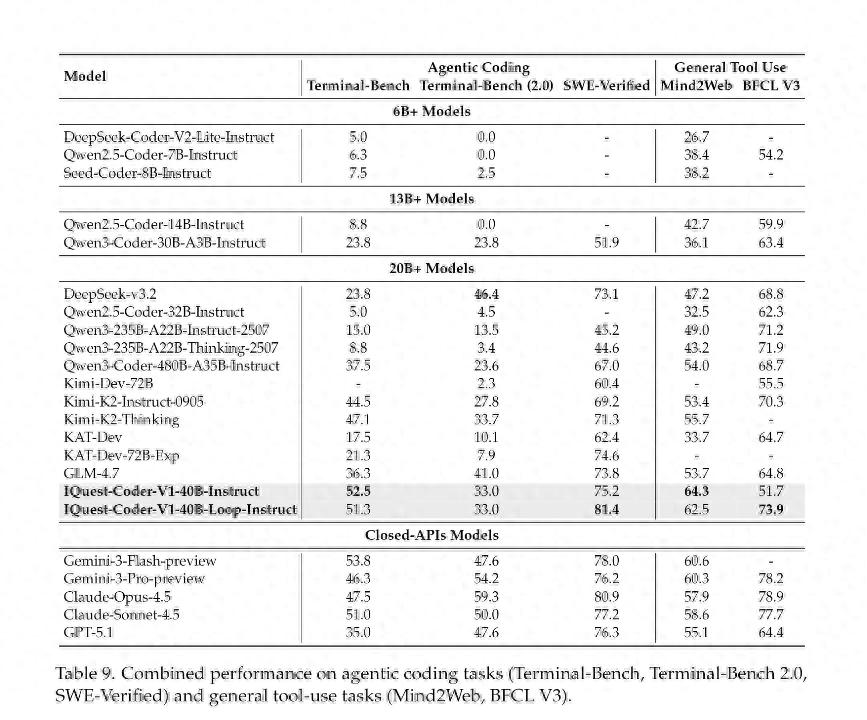
这些技术设计在基准测试中得到了验证。在SWE-Bench Verified的测试中,IQuest-Coder-V1的准确率达到了81.4%,超越了Claude Sonnet 4.5的77.2%。在LiveCodeBench v6中,它的表现为81.1%,在BigCodeBench上为49.9%。
IQuest-Coder-V1是由九坤投资创始团队设立的至知创新研究院开发的。这个研究院独立于九坤的量化投研体系,专注于多个AI应用方向的研究。
九坤投资是中国较早的一批量化私募,成立于2012年,目前管理规模超过600亿人民币,与明汯、幻方、灵均并称为量化“四大天王”。
创始人王琛是清华大学数学物理学士和计算机博士,曾师从图灵奖唯一华人得主姚期智院士。联合创始人姚齐聪则拥有北京大学数学学士和金融数学硕士的背景。
两人都曾在华尔街顶级对冲基金千禧年工作,2010年他们看好中国股指期货上市的机会,于是选择回国创业。
自2020年起,九坤开始建设名为“北溟”的超算集群,内部设有AI Lab、Data Lab和水滴实验室。
这些基础设施最初是为了支持量化投资业务,现在也为大模型的研发提供了计算能力。
量化机构本身就具备大规模算力集群和数据处理能力,这与大模型训练的需求非常匹配。同时,在人才结构上,量化投资和AI研究都需要数学、计算机背景的人才,这为量化机构进入大模型领域奠定了基础。
从量化投资到开源大模型,这一转型并不令人意外。
量化机构本身就拥有大规模算力和数据处理能力,这与大模型训练的需求高度契合。此外,量化投资与AI研究在人才结构上的重叠,使得这些机构在进入大模型领域时更具优势。
因此,从发展角度来看,IQuest-Coder-V1更像是九坤在AI领域的自然延伸,而不是单纯的跟风。
02
尽管如此,IQuest和DeepSeek之间的相似性依然显而易见。
它们都来自中国的量化基金,展现了在资源有限的情况下,如何通过工程创新实现技术突破的能力。但细细一看,两者却选择了截然不同的发展方向。
DeepSeek追求的是“广度”。从DeepSeek-V3到R1,梁文锋团队致力于打造通用的对话能力,目标是成为中国的GPT。
它希望能够回答各种领域的问题,写诗、讲故事、分析时事、解决数学题,力求覆盖尽可能多的应用场景。
而IQuest-Coder-V1则专注于“精度”。它在代码这个垂直领域内追求极致,在SWE-Bench等专业测试中力求做到最好。它不关注能否写诗,只在乎能否像真正的程序员一样理解需求、设计系统和解决bug。
有趣的是,就在IQuest-Coder-V1发布的同一天,DeepSeek团队也有新动态。
包括创始人梁文锋在内的19位研究者发布了关于mHC(流形约束超连接)架构的论文,解决了超连接网络在大规模训练中的不稳定性问题。
尽管DeepSeek团队在研究方面保持一定的更新频率,但在产品方面却显得有些滞后,至今仍未推出R2和V4。
到2025年,AI领域的竞争焦点将集中在对话能力和推理能力上,大家争的是谁能更好地回答问题,谁的推理过程更清晰。而到2026年,这个焦点转向Agent能力,比拼的是AI能否自主完成复杂的多步骤任务。
Agent能力的核心在于“执行”,而不仅仅是“理解”和“回答”。
举个例子,一个对话型AI可以告诉你如何修复代码中的bug,但Agent则能直接帮你修复代码、运行测试和提交修改,这完全是不同的能力层次。
DeepSeek团队在研究方面确实表现活跃,不断发表论文推进底层技术。然而落实到产品时,DeepSeek仍然主要是一个对话型AI,用户提问,它则给出答案,这是它的主要使用场景。
目前,DeepSeek还没有推出真正的Agent产品,无法像IQuest-Coder那样自主完成整个软件开发流程。
当然,DeepSeek在Alpha Arena等AI炒币/炒股比赛中表现出色,证明了量化基金训练的模型“确实懂市场”,能够解析K线、解读新闻并做出交易决策。
而量化投资的本质就是利用算法理解市场规律,寻找价格波动中的模式,这也进一步说明DeepSeek具备“理解复杂系统”的能力。
不过要说清楚的是,尽管在金融市场上表现不俗,这种能力还是停留在“理解”和“分析”的层面上。DeepSeek虽然能分析市场和提供建议,但作为一款产品,它还没完全具备自主交易的能力。
从股市投资到编程,幻方和九坤的AI都在展现一种共同的趋势,那就是更注重执行力。这可能就是量化基金在AI领域取得成果的原因,因为他们的核心理念是“让算法自主做决策”,而不是单纯“让算法回答问题”。
现在关于AI的竞争,不仅仅是看谁的论文多,关键是能把技术转化为用户可以直接使用的工具。
市场已经等得够久了,梁文锋该推出新产品了。
03
IQuest-Coder-V1的目标是对标Claude Opus 4.5,这一定位非常明确,81.4%对80.9%的基准数据确实很出色。
再看看Anthropic在华的强硬态度,也让大家对Quest-Coder-V1寄予了更多期待。但“是否能取代Claude Opus 4.5”这个问题,还是需要冷静分析。
Claude Opus 4.5的强项不仅在于模型能力,更在于其完整的产品生态。它有原生的VS Code扩展,还有Claude Code这样的交互式开发工具,支持MCP协议的生态系统,还有企业级的安全合规标准,以及经过实际项目打磨出来的用户体验。这些优势可不是一个新发布的模型能短时间内复制的。
更重要的是用户习惯。Claude早早就发布了,程序员们已经习惯了它的“工作方式”,知道什么时候该信任它,什么时候该插手,如何高效协作。
这种习惯的养成是需要时间的,要经过无数次试错才能建立起来。即便一个新模型的基准数据优于其他,也需要很长时间来赢得用户的信任。
基准测试和实际应用之间确实存在差距。
虽然SWE-Bench Verified测试的是在真实代码库中解决问题的能力,这比单纯的代码补全要复杂得多。但即使在这样的测试中表现优秀,也并不意味着在日常开发中能无缝替代人类程序员。
实际工作中的需求往往是模糊的,产品经理和开发者之间沟通时,需求常常会发生变化,而这些在基准测试中是没有体现的。
不过,IQuest-Coder-V1也有它的机会。它是开源的,这意味着企业可以自行部署,可以根据需要进行调整和优化,免去担心数据被第三方服务商获取的顾虑。对于金融、医疗、国防等对数据安全有严格要求的行业而言,这可是相当重要的价值。
这种开源代码模型的体验和Claude的用户完全不同。Claude的用户更习惯云服务,愿意为便利性支付费用,对数据隐私没有过于苛刻的要求。而IQuest-Coder-V1的潜在用户则是需要数据自主可控的企业、想要深度定制的技术团队,或者喜欢折腾开源工具的开发者。
就像做量化的九坤和幻方一样,他们的算法可是企业的命脉,绝对不能放到公有云上。
当然,开源也有它的问题。没有专门的产品团队来打磨用户体验,也没有客服来解决使用过程中的问题,遇到bug时只能自己想办法或者等社区来修复。这些都是开源模型相对于商业产品的劣势。
有一种观点认为,像IQuest-Coder-V1这样带有一定代理功能的代码大模型,可能是通向通用代理和AGI的第一步。
这个观点的逻辑在于,编程任务是结构化且逻辑清晰的,与其他开放性任务相比,更容易验证对错。测试结果是否通过,这种二元反馈为代理提供了明确的学习信号。
更关键的是,编程任务所需的能力恰恰是通用代理所需要的核心能力。
从SWE-Bench这样的基准来看,它测试的不仅是代码生成能力,还有理解需求、规划步骤、调试错误、迭代改进等能力。这一过程与解决其他复杂任务的模式是相通的。
代码环境为训练提供了一个相对可控的场所,一旦在这里证明了它的代理能力,技术扩展到其他领域的路径就会更加清晰。
因此,九坤可能也在谋划一盘大棋。