最近,DeepSeek 成为了科技界的热门话题。这款工具以其低成本就能实现顶尖模型的性能,吸引了不少人的目光。除了出色的推理和问答功能外,DeepSeek 还特别关注提升代码编写的效率,推出的 DeepSeek Coder 正在引发开发者们的热烈讨论。
简介
DeepSeek Coder 是 DeepSeek 团队精心开发的一个代码生成项目,大家可以在
https://github.com/deepseek-ai/DeepSeek-Coder 找到它的仓库。这个项目结合了多个代码语言模型,每种语言都使用了多达 2T 的海量 token,并且提供从 1B 到 33B 不同规模的模型,达到了多语言编程领域的领先水平。

DeepSeek Coder 拥有以下几个亮点:
- 丰富的训练数据:它使用了 2T 的 Token 来进行训练,数据来源中87%是代码,13%是自然语言(中文和英文)
- 灵活性与扩展性:提供1B、5.7B、6.7B和33B等不同规模的模型,用户可以根据需要选择使用
- 卓越的模型表现:在 HumanEval、MultiPL-E、MBPP、DS-1000 和 APPS 等基准测试中,已经在公开的代码模型中取得了优异的成绩
- 高级代码补全能力:支持项目级别的代码补全和填空任务
二、使用:简单几步,轻松上手
其实,使用 DeepSeek Coder 并不难,只需按照以下几个步骤,开发者就能快速体验到它的强大功能。
- 安装依赖:在使用之前,先得安装必要的依赖。打开命令行工具,执行以下命令:
pip install -r requirements.txt这样就完成了依赖的安装和环境配置。
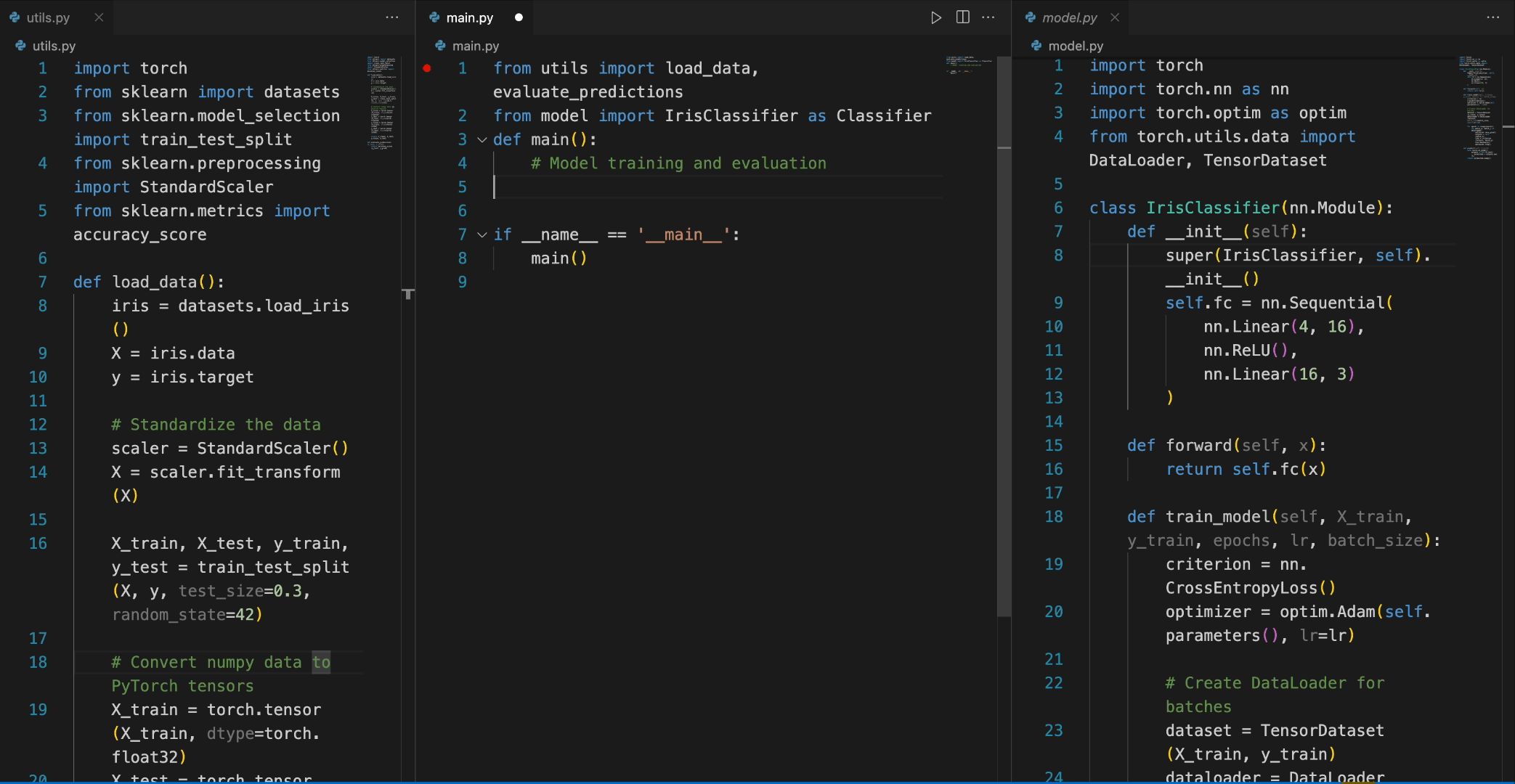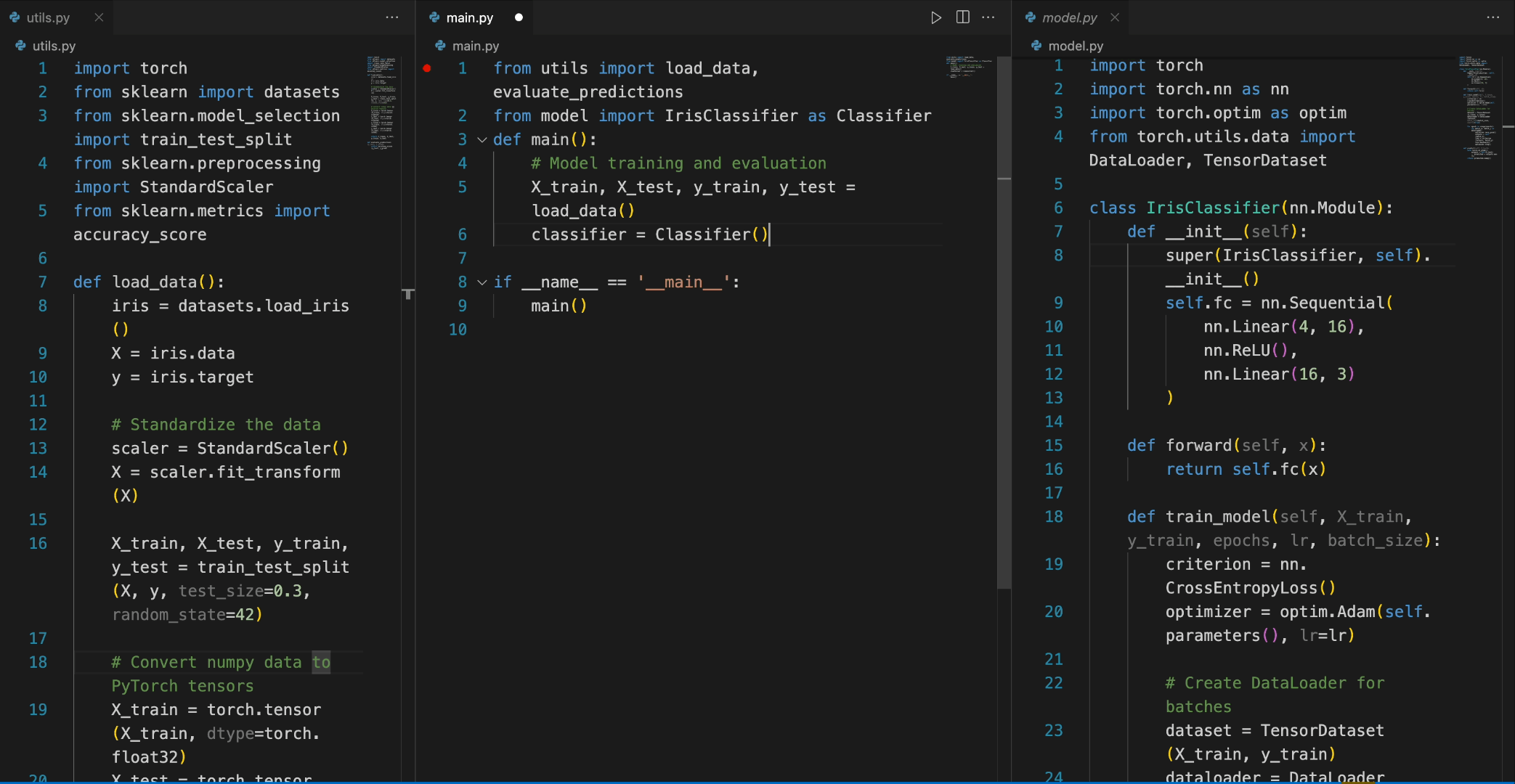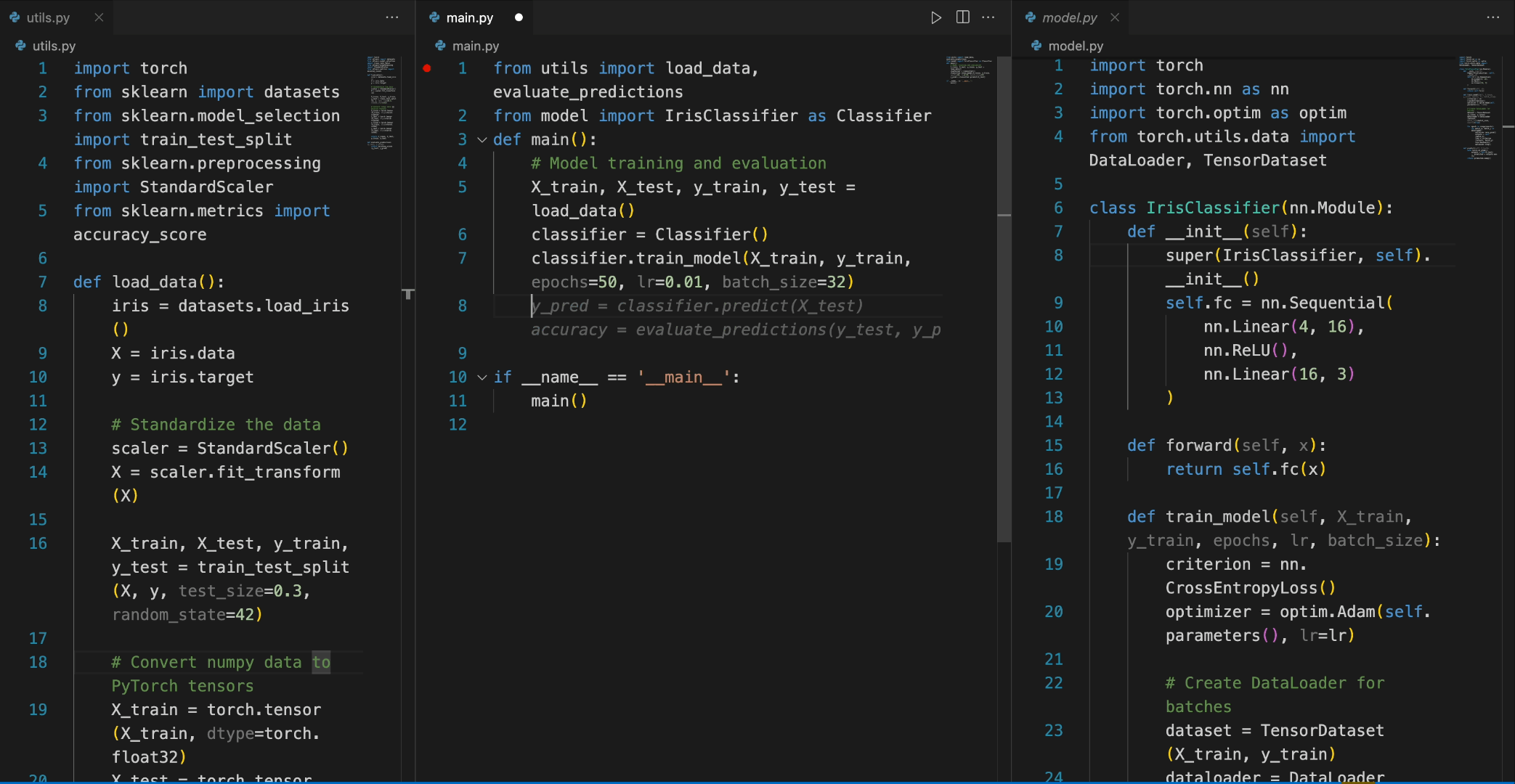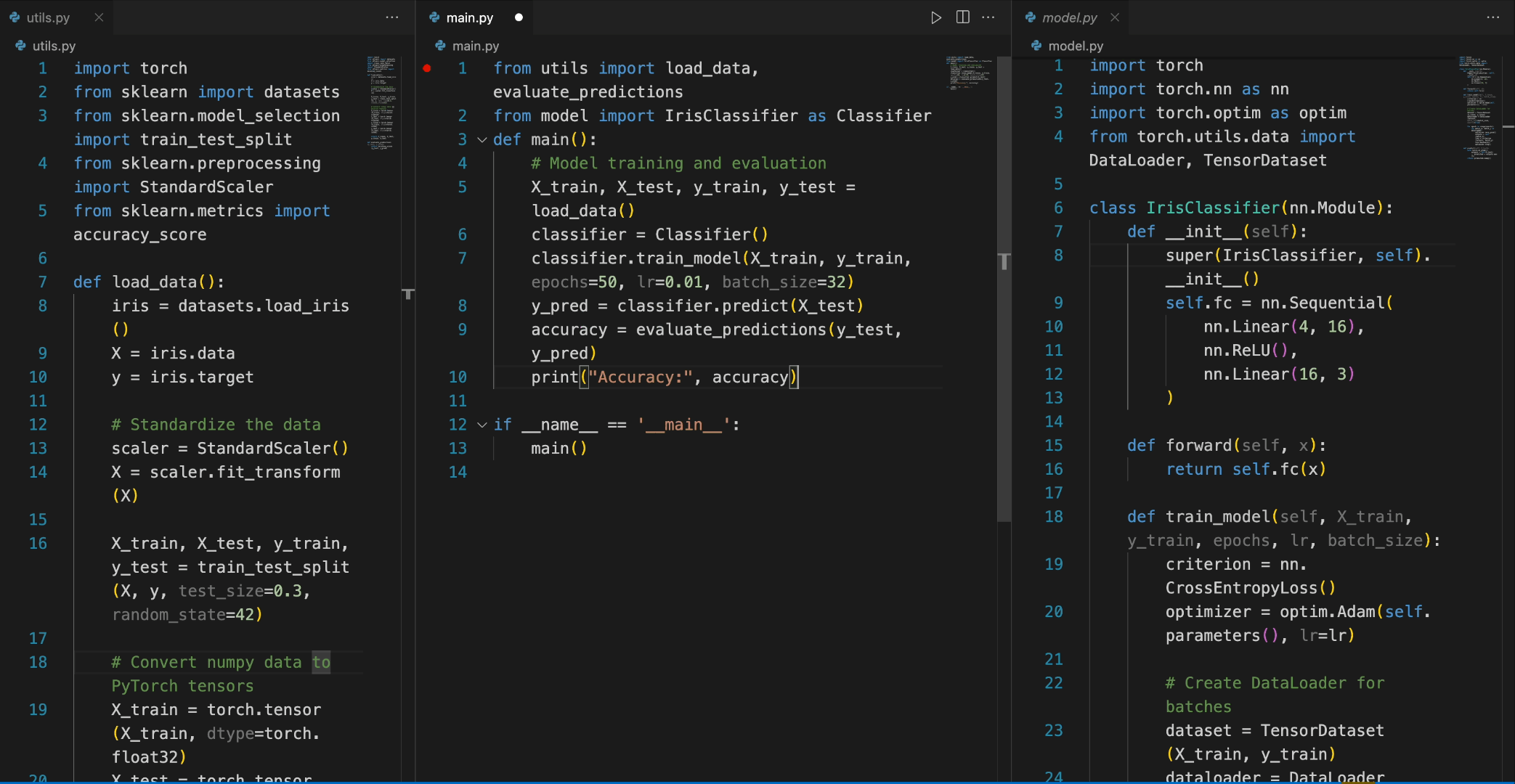
- 代码补全:以 Python 为例,首先导入所需的库,然后初始化模型:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()接下来,输入文本,经过 tokenizer 解析后,将其放入模型中进行生成,最后得到一个快速排序的算法代码:
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))运行这段代码后,模型将输出快速排序算法的 Python 实现:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
for i in range(1, len(arr)):
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)3. 代码插入:只需提供需要插入代码的源代码块,经过模型生成,便能自动补全缺失的代码:
让代码生成变得轻松有趣
你知道吗?只要运行这一段小代码,模型就能快速生成一个Python实现的快速排序算法。看看这段代码,简单又实用:
for i in range(1, len(arr)):接下来,我们来聊聊如何与DeepSeek Coder进行交互,像聊天一样生成代码。通过发送一条简单的消息,模型就能理解你的需求并给出相应的代码。下面是一段示例代码:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))运行之后,你会得到一段包含代码的富文本消息,像这样:
Sure, here is a simple implementation of the Quick Sort algorithm in Python:
def quick_sort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0]
less_than_pivot = [x for x in arr[1:] if x pivot]
return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot)
# Test the function
arr = [10, 7, 8, 9, 1, 5]
print("Original array:", arr)
print("Sorted array:", quick_sort(arr))
This code works by selecting a 'pivot' element from the array and partitioning the other elements into two sub-arrays, according to whether they are less than or greater than the pivot. The pivot element is then in its final position. The process is then repeated for the sub-arrays.
最后,DeepSeek Coder的代码补全能力非常强大,甚至能处理整个代码仓库的补全,帮助你更高效地编写代码,真是个神奇的工具!
轻松微调模型,提升你的编程体验
其实,DeepSeek Coder 给用户提供了一些脚本,方便在后续的任务中对模型进行微调。你可以在
finetune/finetune_deepseekcoder.py 找到相关脚本,它支持使用 DeepSpeed 进行训练。首先,你需要安装一些依赖:
pip install -r finetune/requirements.txt接下来,准备训练数据时,记得遵循示例数据集的格式哦。每一行都应该是一个 json 序列化的字符串,包含两个必填字段:.instruction 和 output。数据准备好后,就能使用示例脚本来微调参数了。
总结一下
DeepSeek Coder 的出现,真的是给代码开发带来了不少便利。它低廉的成本和卓越的性能,让它成为了开发者们无法忽视的编程工具。
对于开发者来说,DeepSeek Coder 可以迅速补全代码,减少那些重复和基础的代码编写,显著提高开发效率。而对于初学者而言,它就像一个随时待命的编程老师,帮助你学习编程知识和理解代码逻辑。
在 DeepSeek 的强大支持下,DeepSeek Coder 未来将在编程领域中扮演重要角色,值得广大开发者深入挖掘和使用!









DeepSeek Coder的出现真是个好消息,特别是对于提高代码编写效率有很大帮助。不同规模的模型选择也很灵活,期待它能在实际项目中大显身手。
DeepSeek Coder的多语言支持和强大的补全能力让人耳目一新,特别适合开发者日常使用。使用简单,真心推荐!