简单来说,OpenCode就像把AI变成一个听话的程序员,任你指挥。
你只需对它说一句“帮我做一个业务数据分析系统”,它可不会简单地给你几段代码,而是会:
-
加载项目的背景和历史对话
-
自动生成系统提示
-
调用AI进行推理
-
判断是否执行命令、修改文件或查找代码
-
进行权限检查和安全拦截
-
完成后保存会话、更新数据库,并实时推送到前端
从理解你的需求、规划任务,到使用bash、edit、grep、git等工具,最后生成可运行的代码,它能够完整地处理这一流程。
可以说,它更像是一种工程化的架构,而不是普通的插件或小玩意:
前端有Web、桌面和终端TUI;中间层包含API网关、权限控制和会话管理;核心层涉及Agent编排、工具系统和存储层;底层则连接各种LLM,完全不限制厂商。
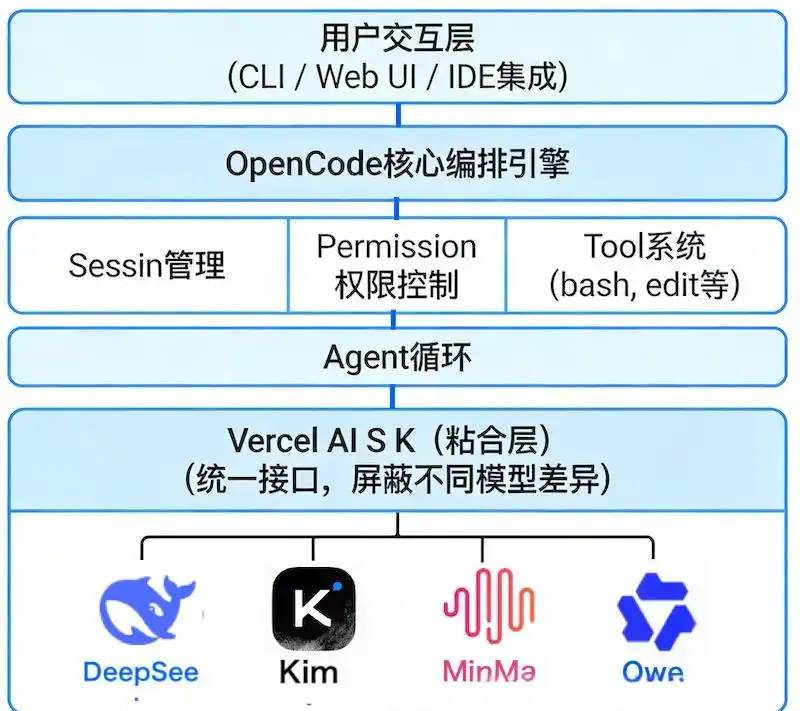
通俗点说,别的AI编程工具只是“辅助打字”,而OpenCode已经迈入了“自主研发”的阶段。

国内研发团队面临的挑战,其实很具体:
代码敏感,绝对不能放到云端;海外模型经常不稳定,网络也常常卡顿;企业需要合规、审计和权限管理;希望使用国产模型,但工具的支持差异很大;想要集成现有流程,却被闭源工具限制。
OpenCode几乎完美地解决了这些痛点。
2.1 ▍ 本地优先,安全与隐私深入设计
对金融、政府和智能制造等团队来说,代码不上云不是选择,而是生存的关键。
OpenCode从一开始就着眼于本地优先:
会话、代码和命令执行都是在本地进行;数据保存在本地SQLite,不会上传到任何第三方服务器;支持容器隔离、最小权限运行和操作审计。
这一点,让许多海外流行的AI编程工具无法进入企业的大门。
2.2 ▍ 模型中立,避免强制绑定
许多AI编程工具看似好用,实际上却强制绑定模型:使用它就得用某个公司的API,价格、速度和稳定性都没有选择余地。
而OpenCode采取了完全开放的策略:
-
内置提供者抽象层,统一对接各种LLM
-
支持OpenAI、Claude、Gemini等大模型
-
支持自定义提供者或兼容层(如在
opencode.json中配置provider字段),轻松对接国内大模型:Qwen、Kimi、DeepSeek等 -
可以接入本地模型或私有部署模型
团队可以自由选择组合:复杂任务用强大的模型,简单脚本用轻量级模型,成本自行掌控,不会被某个厂商限制。
2.3 ▍ 真实的工程化设计,适合生产环境
一个工具是否能在团队中推广,关键不在于演示的花哨,而在于架构的稳健。
OpenCode的结构非常清晰:
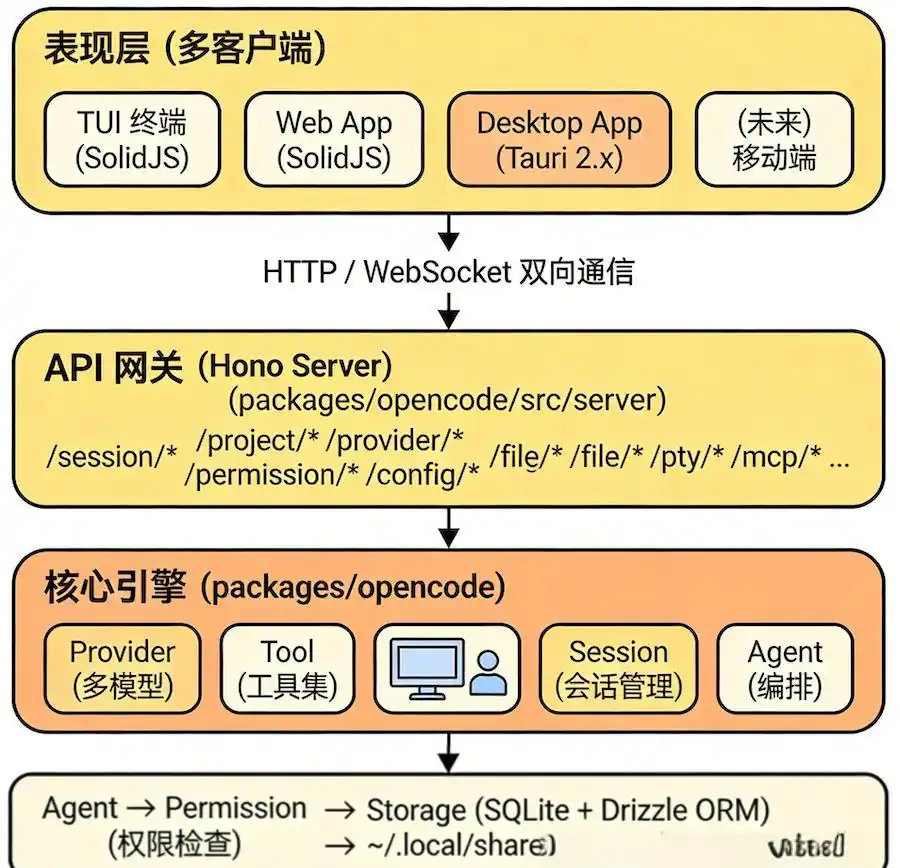
它不是一个单一的工具,而是一整套可部署、可管理和可扩展的研发基础。
团队可以实现:统一部署,所有人都能使用;按角色分配权限,危险操作需经过审批;会话可以分享、回溯和快照;接入内部系统、规范和知识库。
这就是企业级使用的标准,而不是个人玩具。
2.4 ▍ 完全开源,透明可审计
国内企业特别看重的一点就是自主可控。OpenCode是开源透明的,使用MIT许可证,100%开源的特点赋予团队前所未有的自由。
源代码完全可见,可以审计;可以自己修改、编译和加固;无论是适配公司内部的特定开发流程、集成私有代码仓库,还是与国内流行的研发管理工具(如禅道)对接,OpenCode都提供了无限可能;能够做出内部定制版,适配公司标准;没有隐藏收费、后门风险和版权陷阱。对于需要长期投入、进入生产环境的团队来说,这一点至关重要。
2.5 ▍ 提供Plan与Build双模式,智能且可控
-
Plan模式:只读分析模式,可以深入理解陌生的代码库,提供实施方案的建议,适合快速学习项目或代码审查,而不直接修改代码,风险可控。
-
Build模式:具备完全访问权限,能够智能生成和修改代码、执行命令,自动完成多步骤开发任务,极大提升开发效率。
用户可以根据需要切换模式。
2.6 ▍ 丰富的内置工具与灵活的扩展性
OpenCode的Tool系统是AI智能体执行任务的“手臂”。团队可以利用它连接内部系统和国产工具。
内置工具:熟练运用bash、edit、grep、codesearch等内置工具,AI能完成绝大部分的代码操作;比如先用codesearch查找相关代码,再用read阅读文件内容,最后用edit进行修改。
编写自定义工具:
-
CI/CD工具:编写一个
ci_trigger工具,让AI在代码修改后自动触发公司内部的Jenkins/GitLab CI或腾讯云CODING CI/CD流水线。 -
内部知识库:编写一个
query_wiki工具,让AI能够访问公司内部的Confluence或自建知识库获取业务逻辑或技术规范。 -
数据平台:编写一个
query_db工具,让AI能够查询公司内部数据仓库,帮助分析问题或生成报告。
2.7 ▍ 精细化权限管理,防止AI误操作
OpenCode提供了细致的权限系统(Permission系统)。团队可以为AI Agent配置精确的权限规则,比如允许执行特定的bash命令、限制文件写入范围,甚至在敏感操作时请求用户确认,有效防止AI代理误操作,保障代码安全。
细粒度规则:可以为不同AI Agent(如build、plan)配置不同的权限规则;例如plan模式的Agent只能read和grep文件,禁止edit和bash。
安全策略:通过配置opencode.json中的permissions字段,可以禁止AI访问敏感目录(如node_modules/.git);限制AI只能修改特定类型的文件(如.ts/.js);对高风险操作(如bash:rm -rf)强制要求用户手动确认。使用技巧:巧妙运用allow、deny和ask三种权限动作,构建符合企业安全策略的权限链。
它的成功并不是依靠营销,而是真实场景的解决方案:能够解决痛点、适合生产环境、不被限制,自然会被企业悄然采用。适合生产的理由:
这套架构真是分层清晰,核心逻辑也很稳定,耦合度还低;权限系统相当完善,能有效避免AI出现误操作的情况。此外,本地部署让数据安全可控,符合各种合规要求;而且模型切换也很灵活,外部服务的不稳定不会干扰研发工作。支持会话快照、回滚和审计,出问题时也能追踪到源头;无论是终端、网页还是桌面,多端学习的成本都很低。GitHub上它的热度相当高,国内的开发者也占了不少份额;在金融科技、互联网、制造和政企等领域,已经有了不少实际应用案例。很多团队将它作为内部AI编程的基础,进行进一步的开发。如今,越来越多的技术团队在选择时,把OpenCode视为首选。如果你的团队具备基本的部署和运维能力,OpenCode就能够从“个人玩具”变成“团队基础设施”。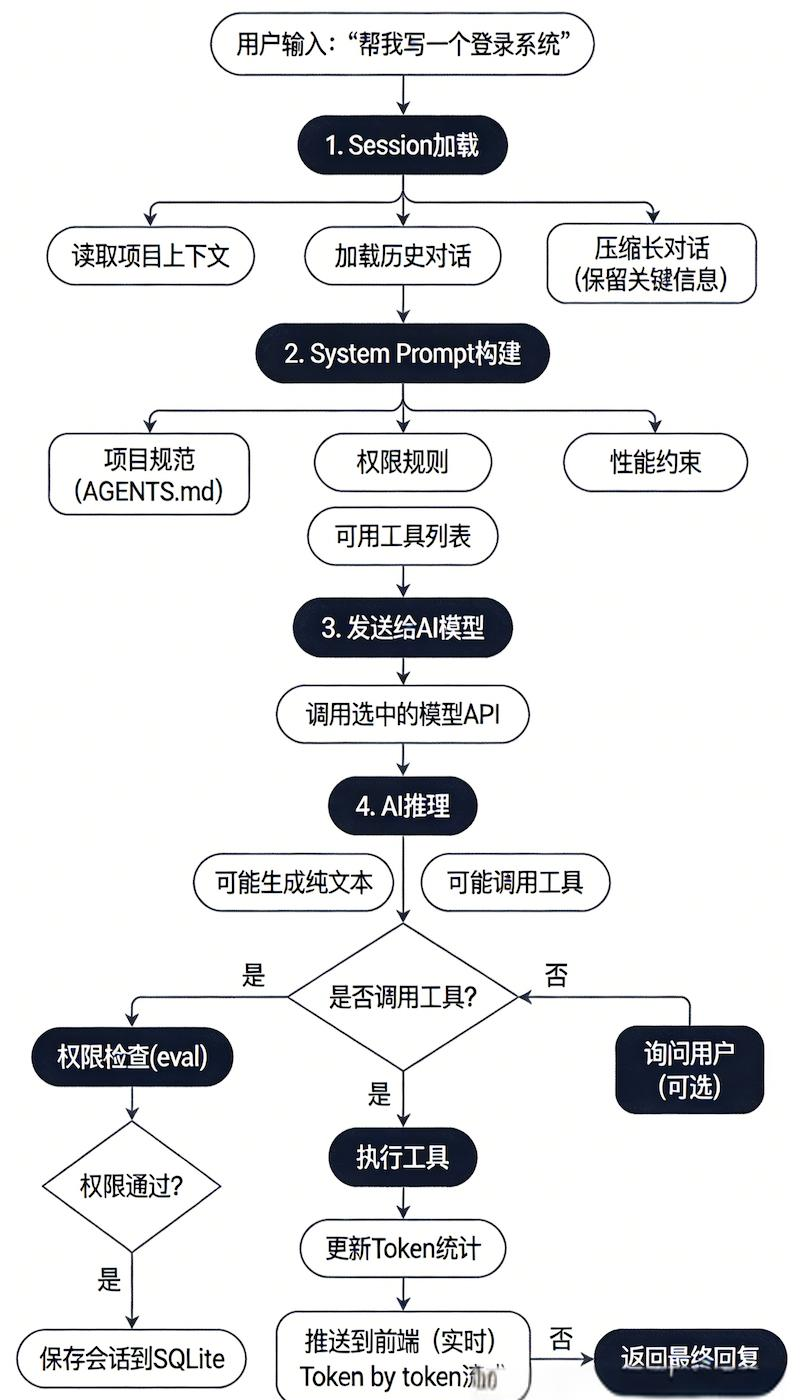 (应用流程示意图)
(应用流程示意图)
说实话,过去一段时间,国内的团队在AI编程方面一直处于被动状态:好用的工具在海外、稳定的模型无法使用,安全性差的又不好用,开源的工具更是没个体系。OpenCode的出现,正好填补了这一块空白:它开源且免费,优先支持本地部署,安全可控,模型也中立,兼容国产的大模型,架构成熟,团队可以自己部署,能直接投入生产,扩展能力也强,能适配企业的流程。这不仅仅是个效率工具,更是一整套属于国内团队的AI自主编程基础设施。如果你所在的团队正在进行AI研发转型,纠结于工具的选择,担心合规问题、隐私顾虑,希望能实现自主可控,那么OpenCode或许就是你一直在寻找的答案。









用过其他AI编程工具的朋友,能不能分享一下跟OpenCode的对比体验?
有考虑过OpenCode的安全性和隐私问题吗?这点很重要。
希望OpenCode能够提供更好的文档支持,帮助用户更快上手。
之前用过类似的AI编程工具,OpenCode的界面设计确实更友好一些,使用起来很顺畅。
希望能看到更多关于OpenCode的用户评价,才能更全面了解。
想知道OpenCode对不同编程语言的支持程度,是否能完全替代现有的开发工具?
我对OpenCode的稳定性有点担心,尤其是在大型项目中。用过的人觉得它可靠吗?