最近,全球最大的AI模型API聚合平台OpenRouter发布了一组数据,真的是在国内外引起了不小的轰动哦。
截至2026年2月28日,这个平台上前十名模型的Token消耗量已经超过了28.7万亿,而其中国产模型贡献了超过14.69万亿,这是中国模型首次在单月Token调用上占据了超过一半,实力反超美国模型。
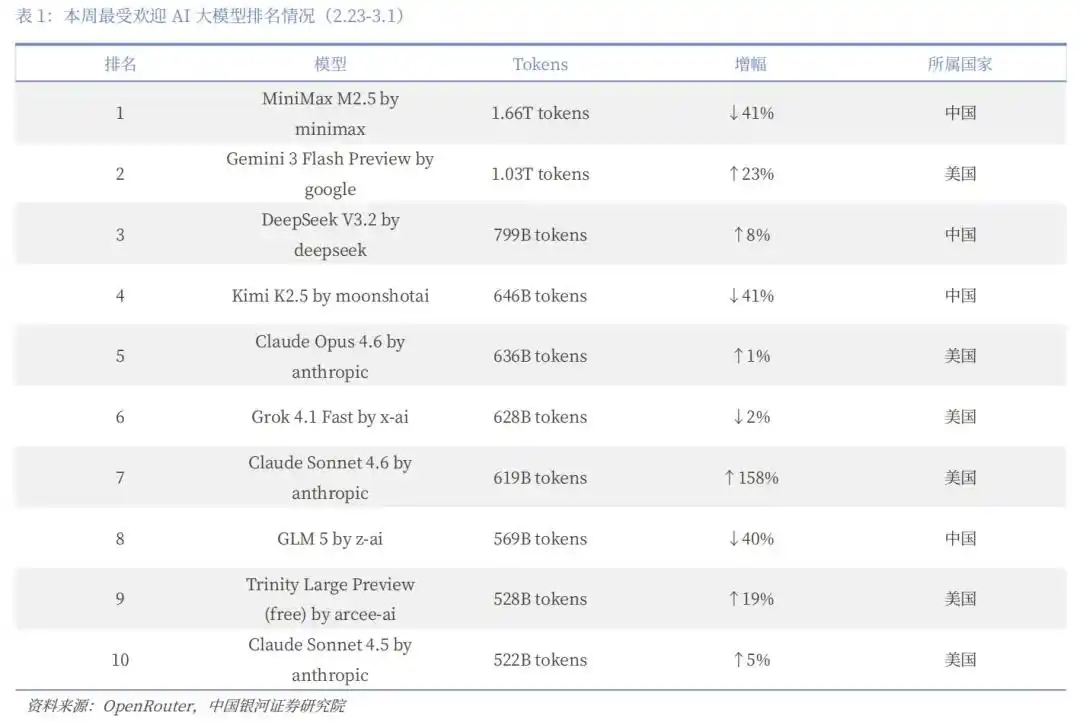
从周的数据来看,2月16日至22日,中国模型的周调用量达到了5.16万亿Token,而美国模型则降到了2.7万亿,中国的市场份额达到了61%。在调用量前五的模型中,中国的MiniMax M2.5、月之暗面Kimi K2.5、DeepSeek V3.2和智谱GLM-5占据了四个席位。
虽然接下来的一周,中国模型的调用量有所回落,超越的时间也不长,但能在全球最大API聚合平台上与美国模型进行正面竞争并短暂领先,已经足以证明其实力了。
此外,OpenRouter的用户中,美国开发者占了47.17%,而中国开发者只有6.01%。还有报告显示,80%的美国人工智能初创公司在开发产品时使用了中国的开源模型。
这说明,推动中国模型崛起的主力军,其实是来自硅谷和欧洲的海外开发者,而不是国内市场的自我陶醉。
因为大型模型的竞争已经不再是单一的“谁更聪明”,而是进入了“谁聪明、谁省钱”的多维比拼阶段。
一、真香定律:美国开发者为何青睐中国Token
中国的AI模型在全球调用量上超越美国,背后其实是多种因素叠加形成的系统性优势,而其中最直接的原因,就是价格便宜。
看看这些数据吧。
长江证券的研究报告显示,输入价格方面,MiniMax M2.5和智谱GLM-5都是0.3美元/百万Token,而Anthropic的Claude Opus 4.6则是5美元,竟然是中国模型的16.7倍。
输出价格更是夸张,MiniMax-M2.5的费用为1.1美元/百万Token,智谱GLM-5为2.55美元/百万Token,而Claude Opus 4.6的价格高达25美元/百万Token,分别是前两者的22.7倍和9.8倍。就拿最近发布的阿里Qwen 3.5来说,它的百万Token价格直接下降到0.8元人民币,相当于谷歌Gemini的十八分之一。
在很多日常场景中,尤其是随着Agent时代的到来,用户对便宜且强大的算力需求,已经压过了对“顶级智商”的需求。
今年2月,开源框架OpenClaw大受欢迎,AI开始从“聊天工具”变成能自己干活的“数字员工”。
一个Agent任务的Token消耗量动辄就有几十万到百万,按量付费的API成本一下子成了开发者的主要开支。月之暗面顺势推出了KimiClaw,支持一键部署,结果Kimi K2.5在发布20天内的调用量就超过了去年一整年的总和,收入也超越了2025年的总和。
这也是Google和Anthropic禁用那些在订阅制下进行全自动调用的账户的原因,因为订阅费用远远无法覆盖全自动调用的算力成本。
当消耗量呈指数级增长时,单位Token的价格优势便成了竞争的关键。
这种成本优势可不是凭空而来的,底层是电力和工程的支撑。
算力的底线就是电力。
中国工业用电的成本比美国低30%至40%,中西部的绿电甚至低50%至70%。再加上中国的工业用电基数大,可以充分利用谷电来训练模型,这就形成了中国AI企业的物理成本护城河。
另一方面,工程能力的提升也是被迫的。从2024年4月起,中国AI企业在尖端芯片供应受限的情况下生存,拿不到最好的芯片,就把现有的芯片用到极限。
中国模型普遍采用混合专家架构,这种技术路线重构了算力消耗的逻辑。一个几千亿参数的模型在处理简单问题时,只激活其中一小部分“专家网络”,这种“按需激活”的模式不仅省电,还节省算力。
最后,开源生态的良性循环也在持续进行。
过去一年,中国大模型在全球的Token消耗占比增长了421%。斯坦福的报告显示,从2024年8月到2025年8月,中国开发者贡献了Hugging Face总下载量的17.1%,略高于美国的15.8%。
开源生态降低了全球开发者的使用门槛,也让中国模型在技术反馈中迅速迭代,能力和价格的综合优势在不断扩大。正如硅谷投资人Aditya Agarwal所说:“超过50%的大模型调用都是通过廉价的开源模型完成的,中国的模型实际上支撑了大部分AI应用,美国同行甚至无法替代。”
中国AI模型的出海成功,是技术架构创新、极致成本控制、开源生态和场景适配共同作用的结果,体现了系统性优势的集中爆发。
二、出海模式:从应用到算力、生态
如果说调用量的数据展示了中国AI的“强大”,那么接下来要聊的是:这些Token到底是怎么流向全球的呢?
过去几年,中国AI出海的主要方式是“应用输出”,也就是说把AI能力封装成APP,送到海外用户手中,比如字节的Gauthmath、美图的影像产品、快手的KLING AI,都是走这一条路。
如今,这条路依旧为企业带来可观的用户规模和收入。
以Talkie为例,这款情感陪伴类应用覆盖全球200多个国家,在北美Z世代中的渗透率持续提升。用户在与AI角色聊天的过程中,每一句话都在消耗Token。这类C端收入占Minimax收入的70%以上,并且还在快速增长:2026年2月的日均Token消耗量达到了2025年12月的6倍以上。
字节的Gauthmath在美国的拍照搜题市场中拿下了47%的市场份额,成功替代了老牌产品Mathway,也是同样的逻辑。
这种模式不直接按Token向用户收费,而是通过订阅、内购和广告来实现变现。但从底层来看,它们依然消耗的是中国的算力,构成了中国AI出海的“用户基础”。
如果把AI出海比作一条产业链,那么应用就是下游,算力则是上游。中国企业先在下游做产品和流量,然后再向上游发展,做基础设施。
一方面,通过API管道式输出,直接把算力做成水电煤。
海外开发者通过OpenRouter等聚合平台调用中国大模型的API,推理在中国本土的数据中心完成,按Token付费。整个过程,算力和电力都不出境,只有价值通过Token实现跨境交付。
这就像是典型的“卖水卖电”的生意。开发者无需自己部署模型,也不用购买显卡,就能让应用在中国的模型上运行。
据报道,月之暗面负责API服务的团队近期快速扩编,并以独立业务分支的形式直接向总裁张予彤汇报。这样的组织调整足以说明API业务的重要性正在迅速上升。
从商业角度来看,这种模式的优势在于可规模化,且利润率可观,而且随着Agent时代的到来,单次任务的Token消耗量呈现指数级增长,API业务的潜力也在不断扩大。
另一方面,通过构建开源生态,为算力输出铺路。
阿里通义千问、DeepSeek系列选择了一条看似“免费”的路径:把模型权重、工具链和工程范式全部开源,海外开发者可以免费下载并在本地服务器上部署。
这个免费的策略旨在让中国模型进入全球开发者的默认工具箱,成为他们技术栈的一部分。当开发者熟悉了开源模型后,未来开发商业应用时,自然会优先考虑调用同系列的API。
基于阿里和DeepSeek开源模型的衍生模型上传量,已经超过了基于美国主流模型的数量。这意味着全球开发者正在中国开源模型的基础上,发展出一个庞大的技术生态。一旦生态形成,迁移成本将非常高。
可以说,如今的中国AI出海已经不再是单一的“应用输出”,而是一个三层结构:底层是开源生态,通过开放换取开发者的心智;中间层是API算力输出,直接把Token卖给全球开发者,成为商业化的核心引擎;顶层是应用输出,通过产品触达终端用户,既是流量入口,也是算力消耗的重要场景。
这三层相互支撑,共同表明中国的算力正在成为全球AI的基础设施。
三、下半场考验:商业优势面临规则壁垒
OpenRouter平台的数据确实吸引眼球,但它并不能代表全部的情况。
在消费级市场(开发者、初创公司、Agent应用)中,决策链条较短,核心指标是性价比和上手速度。开发者选择哪个模型,往往是他们自己说了算。在这种情况下,中国模型的“便宜且量多”无疑是绝对优势。
但企业级市场可就不一样了。政府、金融、医疗和关键基础设施的决策链条很长,涉及合规、安全、审计和供应商稳定性等多重因素。
在海外的企业级市场,这种复杂性更是显而易见。
因此,有一个问题无法避免:在国际竞争中,单靠纯商业的竞争优势,比如好用、成本低,可能还不够。
比如,之前的英伟达H200被禁止出口。尽管现在可以重新进口英伟达H200,但在AI竞争上,美国的政策随时可能出现反复,而当前推理集群还是依赖于英伟达的H100/H200。
当然,封锁有其双面性,一方面会导致训练成本上升,模型迭代速度放缓;另一方面,也正是这种背景,迫使工程优化提升效率,国产芯片也取得了进展。
但风险同样存在。银河证券的研究报告指出,全球模型的迭代周期正在缩短,主流模型的更新频率已经从半年缩短至数月。如果核心能力的提升速度放缓,成本优势在高端市场可能迅速失去吸引力。
摩根士丹利首席经济学家邢自强认为,Token出海肯定是有市场的,但不要过分夸大中国开源大模型和Token出海借助电力优势的前景,而忽视了地缘政治和安全的考量。
他举了个例子:中国在5G设备领域同样具备性价比和技术优势,但从2018年、2019年后,欧美不少电信网络中的中国5G基站仍然被替代了。
在企业市场中,那些对价格特别敏感的中小企业可能会被中国模型的高性价比吸引,但在政府、金融、医疗等涉及数据主权和关键基础设施的领域,准入的标准可不是单靠“便宜”就能打动的,而是要看“合规性、信任度和品牌影响力”。
美国正在通过投资审查、制定标准以及数据主权相关的法规,逐步提高企业市场的准入门槛。
这意味着,地缘政治的限制正在逐渐增强。
到2025年12月,美国政府提出了所谓的“硅和平倡议”,声称要把那些拥有顶尖科技企业或其他资源的国家联合起来,从而确保“供应链的安全”。
专业人士认为,这实际上是在试图通过规则、投资和项目清单来重塑全球技术分工与资金流向,看似是在构建新的生态,实际上却是一种排他性的整合方式。
至于这个“他”指的是谁,自然不言而喻。
从芯片封锁到“硅和平倡议”,美国的策略是通过规则输出和遏制发展,来重新定义游戏规则、巩固话语权。
因此,模型调用量反超虽然是个阶段性的成就,但这也只是故事的一部分。
AI出海的下半场,除了要保持成本优势,还得面对更多更复杂的问题。有些问题可以通过提升模型性能、系统效率和竞争力来解决,但也有些问题是没有现成答案的。
想了解更多精彩内容,欢迎关注钛媒体的微信号(ID:taimeiti),或者下载钛媒体App!










看到那么多国外开发者使用中国模型,感觉我们的技术被认可了,真不错!
听说美国开发者都转向中国模型了,这背后有什么深层原因吗?
便宜又好用的模型是王道,看来开发者们真的很聪明!还有哪些新模型值得关注呢?
我也发现开发者们在选择模型时,性价比越来越重要,尤其是中小企业。
看到中国模型的价格优势,想起之前使用过的一些AI工具,成本确实是个大问题。
建议关注一下中国模型的后续更新,技术进步快,可能会有更多惊喜。
对于中国模型的崛起,我觉得是市场需求驱动的结果,尤其是小型企业在资金上的压力更大。
看到价格差异,感觉之前用的某些模型真是浪费钱,选对工具太重要了。
便宜又好用的中国模型,看来未来会有更多开发者加入,值得关注。
美国开发者为什么突然转向中国模型,这背后是不是有什么不为人知的故事?