
在Trae工具中,“上下文”其实就是指它在解答你的提问或帮助你编码时,能够“看见”和“理解”的信息范围。这个范围有助于Trae更准确地给出回应。
1. 代码索引管理
通过对工作区的代码进行全面索引,在你发起#Workspace提问时,它会自动搜索与问题相关的跨文件上下文,从而提供更契合项目的答案。

我们来看看当前项目里有哪些文件:
- 先到GitHub上克隆一个开源项目,我选择了dify项目。
- 然后用Trae打开这个项目。
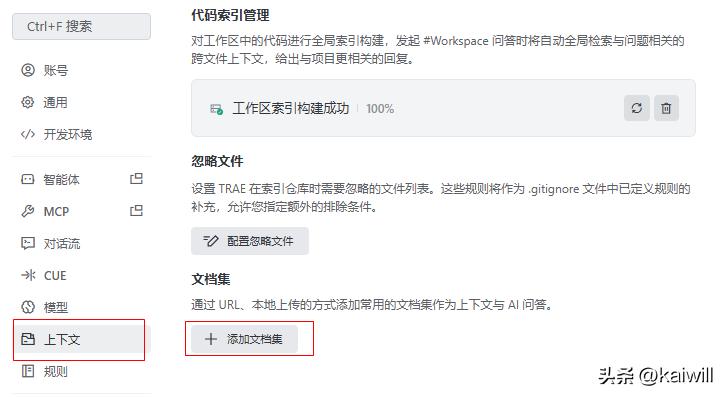
- 确认索引是否已经构建完毕。你可以按照路径:设置 -> 上下文,点击[构建]。
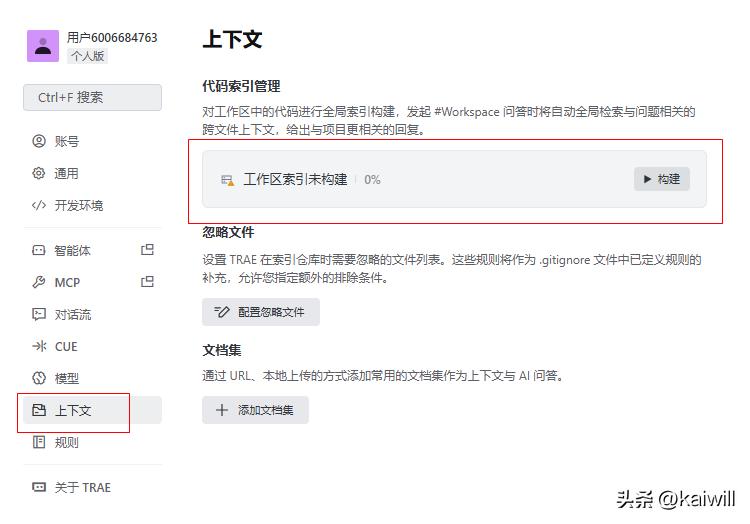
如果项目文件较多,索引构建可能会比较慢,请耐心等待。
- 引用workspace,使用#workspace,这样就可以针对当前项目进行操作了。
2. 忽略不需要的文件
其实呢,#workspace是用来管理当前项目下的所有文件的,但有些文件其实我们并不想让Trae去处理,这个时候就得把它们加入忽略列表。
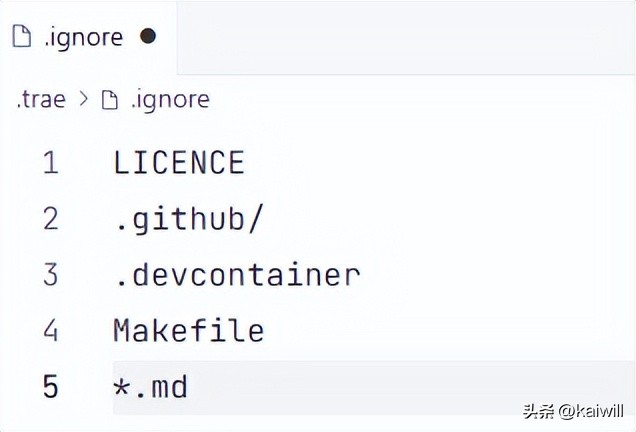
你可以通过在根目录添加一个.ignore文件来指定哪些文件或文件夹要被忽略。
这样一来,索引的速度就能提高了,特别是那些不必要的依赖目录(比如: node_modules/、vendor/)、构建输出目录(比如: build/、out/),以及一些大媒体文件(例如:.mp4、.mov、*.avi)。
操作步骤为:配置 -> 上下文 -> [忽略配置文件]
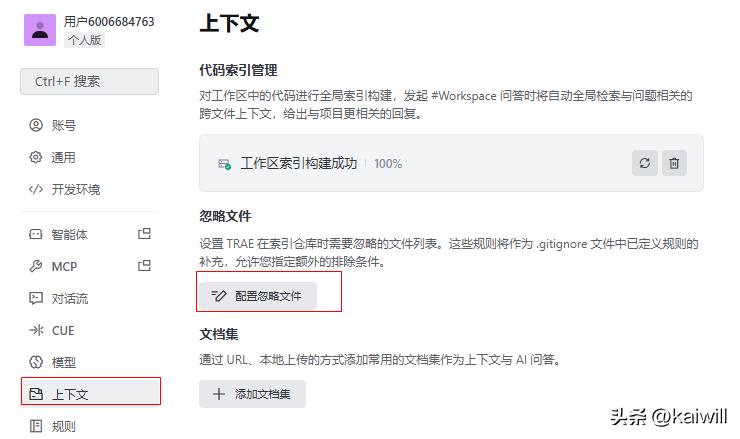
要特别注意,不要把这个.ignore文件和git的.ignore搞混了。Trae的.ignore文件应该放在.trae目录下。
如果你对忽略文件进行了调整,记得要重新构建工作区的索引哦:
让我们聊聊如何管理文档集吧!
其实呢,像大模型这种智能工具,它本身并不懂项目的具体内容。这就像给它配了一个知识库——文档集。Trae会先从这个文档集中找出相关的信息,然后再把这些信息传递给大模型,让它来思考和回答。
你可以通过URL或者直接上传文件的方式,把常用的文档集添加进来,帮助AI更好地回答问题。
操作很简单,路径是:设置 -> 上下文 -> 【添加文档集】。
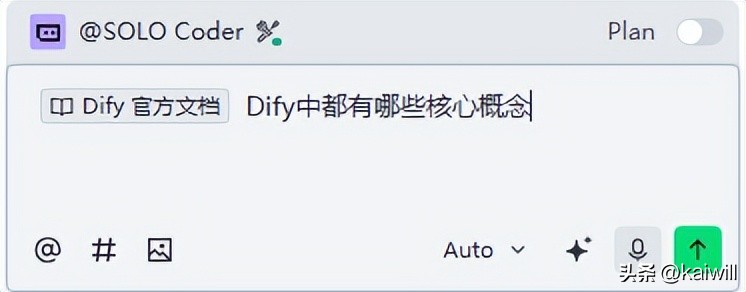
接下来,我们可以把dify的官方文档地址添加到文档集中,链接是:
https://docs.dify.ai/zh/use-dify/getting-started/introduction。这样一来,系统就会自动把最多三层的页面内容整合进来。

稍等片刻,你会发现这三个文档已经成功添加了。如果觉得数量不够,还可以继续添加更多哦!
轻松管理文档,随时添加本地文件!

当然,你也可以把本地的文件直接加到文档库里哦。
现在试试,用 #Doc 来引用文档集吧。

4. 规则
在这个部分,Rules是用来为Trae AI生成的结果设定一些规则和限制,确保生成的代码符合团队的标准。主要功能有:
- 规范代码风格(例如强制使用驼峰命名、要求方法添加注释等)
- 限制技术选择(比如优先使用某种技术/框架/库,禁止某些组件/框架/库)
- 预设配置参数(像是提前设定数据库连接方式、账号密码等)
操作路径:配置 -> 规则

4.1 个人规则
在这里,你可以设定一些个人使用习惯,比如:TRAe输出的语言、生成代码时是否默认添加注释等,TRAe在对话时会遵循这些个人规则,即使你切换项目也能继续生效。
4.2 项目规则
规则会存放在
.trae/rules/project_rules.md文件中,仅在当前项目中有效。
4.3 具体示例
我们来看看项目规则的一个例子,专门为SpringBoot项目设定一些规范:
- 本项目是一个基于Spring Boot 3.2 的 RESTful 后端服务。
- 包结构遵循:
com.kaifamiao.mydemo
|-config
|-modules
|- users
|- controller
|- service
|- mapper
|- entity
|-common
- Controller层只负责HTTP映射和参数校验,不包含业务逻辑。所有请求/响应使用 DTO (Data Transfer Object),禁止直接暴露Entity.
- 遵循标准的Java命名规范:类名用 PascalCase,方法和变量用 camelCase,常量全大写加下划线
- 所有public 方法必须包含完整的 Javadoc注释,包括@param、Creturn 和@throws.
- 优先使用不可变对象和final关键字(如 final class、 final fields)
- 避免使用Lombok;显式编写 getter/setter和构造函数。
- 异常处理应具体,避免捕获通用 Exception,优先抛出或记录有意义的异常。
- 使用SLF4J进行日志记录,而不是System.out.
- 依赖注入使用 Spring Framework (如适用),偏好构造器注入而非字段注入。
- 单元测试使用JUnit 5 + Mockito,每个业务类都应有对应的测试类。
规则写好之后,随便输入一句:“帮我写一个简单的用户注册功能”,生成结果后,你会发现,生成的代码基本都是按照你设定的规则来的:

5. #符号用法
- #File 和 #Folder:用来引用项目中的特定文件或文件夹,作为上下文
- #Code:可以把相关函数或类的代码作为与AI助手交流的背景
- #Doc:用于引用文档集合
- #Workspace:用于引用整个工作区域
- #Web:可以将在线网站的内容作为AI的背景信息
- #Problems:在对话框中输入#Problems符号并发送给AI,它会分析问题标签中列出的所有问题并给出解决方案








这个工具的上下文管理功能很强大,但我觉得在索引构建时应该提供进度条,让用户更清楚等待时间。
Trae的功能确实很实用,尤其是代码索引管理部分。不过,建议增加对不同编程语言的支持,以便更广泛的开发者使用。
Trae的上下文管理和代码索引确实很有帮助,但我对它的文档集管理功能有些疑问,是否会影响到性能?
Trae的上下文管理功能很不错,但在文档集的管理上,能否提供更详细的使用教程?这样可以帮助新用户更快上手。
Trae的上下文管理功能很强大,但我建议在文档集添加时增加对链接有效性的检查,避免无效链接影响使用体验。
Trae的规则设定功能很有用,但我建议增加更多预设模板,方便用户直接应用,提升效率。
Trae提供的文档集管理功能挺不错的,但希望能有更全面的错误处理机制,比如在添加文档时提醒用户文件格式问题,这样可以避免后续使用中的困扰。
Trae的代码索引管理功能非常实用,但我建议能否在索引构建时提供更详细的进度指示,避免用户不确定等待时间。
Trae的代码索引管理功能很棒,但在处理大型项目时,索引构建速度可能会影响用户体验。希望能优化构建算法,加快速度。
Trae的规则设定功能很有用,但感觉在设置规则时,界面操作稍显复杂,希望能简化一下流程,让用户更容易上手。
Trae的上下文管理功能确实很强大,但在文档集的管理上,能否提供更详细的使用教程?这样可以帮助新用户更快上手。
Trae的上下文管理确实很棒,但在处理大型项目时,索引构建速度慢的情况可能会让人沮丧,建议考虑优化处理速度。
Trae的文档集管理功能有潜力,但希望能加入对文档内容的自动分析,帮助用户更好地选择相关文件。
Trae的上下文管理功能非常有帮助,但我对索引构建的速度表示担忧,尤其是在大型项目中,建议优化性能以提升用户体验。
Trae的上下文功能非常实用,但在文档集的管理上,能否增加文档内容的自动索引功能?这样用户能更快找到所需信息。
Trae的规则设定功能很有用,但希望能增加一些示例,让用户更直观地理解如何设置规则,这样上手会更快。
Trae的代码索引管理功能很强大,但在处理大量文件时构建速度较慢,建议增加索引进度提示,这样用户可以更好地掌控进度和耐心等待。