最近我在想一个问题:为什么国内的AI大模型总是说自己很领先,但在实际写代码的时候,程序员却更倾向于用像GPT、Gemini这样的国外模型呢?
先来聊聊AI编程模型的能力,以及我们该如何评估它们。现在主要有三个问题:
1. 随着模型能力的提升,评估这些能力的方法也变得更加复杂。如今的AI模型,简单地进行对话、做个产品展示或者写个数据分析脚本,基本上各大模型都能做到不错,这些任务上并没有太明显的差距。真正考验模型的,还是在处理复杂项目和棘手bug时的表现。
2. 评价标准开始出现饱和的问题。比如MMLU这个标准用久了之后,升级版的MMLU-Pro中大部分模型的分数都超过了80,而AIME2025的榜单上已经有10个模型的分数超过了90分。因此,单纯看某个标准的得分,已经不能很好地反映模型之间的真实差距了。
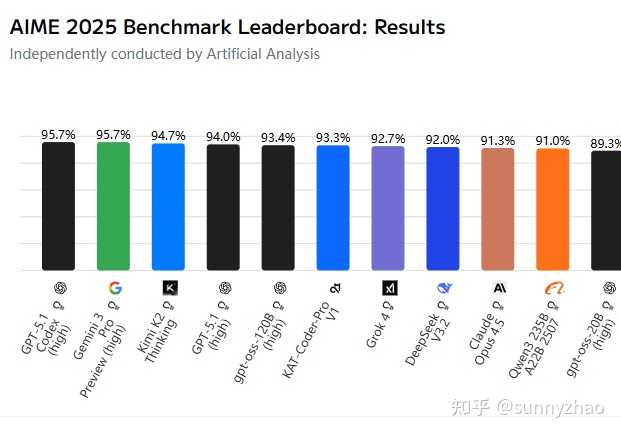
3. 测试场景与实际应用场景有很大不同,尤其是在编程领域。模型训练的数据大多来源于开源代码的issues或者pr,这些问题往往是局部性的,而真实场景则复杂得多。此外,现在的强化学习训练成本仍然偏高,导致对真实问题的训练和复现还没有找到很好的解决办法,加上上下文和记忆管理还不够成熟,因而模型在解决实际编码问题时的能力仍显得不足。
基于这些情况,我们可以从两个方面来分析,为什么国产模型在实际使用中不如国外模型普遍。
首先,模型的能力差距还是个关键因素。在评估编程能力的标准中,swe-bench verified是专门针对处理真实GitHub问题的测试,这对评估模型的编程能力至关重要(不过实际上只有500个经过人工验证的样本,这也显示了评测覆盖度的不足)。目前排名最高的是claude opus 4.5(80.9分),紧随其后的是claude-sonnet-45(77.2),gpt-5..1(76.3),gemini-3-pro(76.2)。而国内模型中最强的是DeepSeek-v3.2,得分73.1,其他的国内模型依次是kimi-k2 thinking(71.3),qwen3-max(69.6),minimax-m2(69.4),glm-4.6(68.0)。由此可见,国内模型与75+的国外模型相比,仍有明显差距。
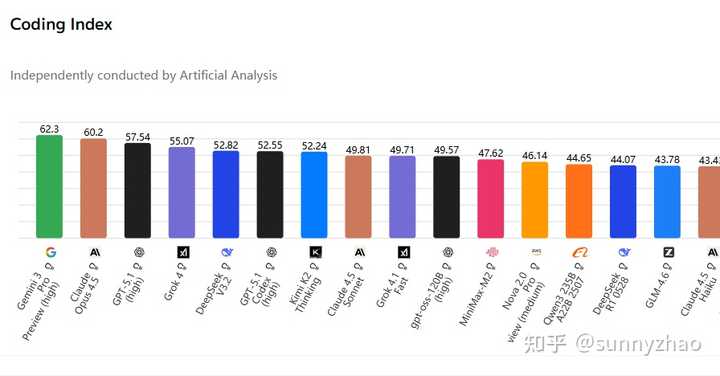
再看一下综合的scicode(科学编程)、livecodebench(相对较新的编程竞赛)、terminal-bench-hard(终端复杂编程问题)的coding index评测,前四名都是国外模型(分数55以上),DeepSeek-v3.2得分52.82,排在第四,算是开源中的一桩小成就,超越了gpt-5.1-codex(高分)。因此,通过这些真实编程任务的评测成绩,我们可以直观地判断出模型之间的能力差距。
第二个问题则是关于编程工具的技术栈和生态差异。claude和codex很早就开始建立基于自家模型的命令行编程工具,而国内的qoder、atra、codebuddy等工具则是在最近三个月才推出的。在编程场景的知识积累、产品优化和强化训练方面,国内工具显然还有一段追赶的路要走。
总的来说,虽然大部分模型在处理简单编程问题上没有太大障碍,但即便是一些前沿模型的能力,仍然未必能应对复杂的实际编程挑战。而国内模型在代码能力上与国外顶尖模型相比,确实还有差距,但这一差距正在逐渐缩小。






从文章中可以看出,国内模型在实际应用中还有不少提升空间,期待未来有更好的表现!
编程工具的生态差异是不是国产模型的软肋?值得思考。
文章提到的编程工具生态差异,真的是个很重要的因素,值得关注。
从文章看,国产模型在编程能力上跟国外的比还有差距,真令人失望。
编程能力的评估标准是不是还需要更新一下?总感觉现在的标准有点不够全面。
这个生态差异问题,真的是让人捉急,如何改善呢?
文章讨论的内容很好,尤其是关于评估标准的部分,确实需要反思。
国外模型在复杂问题上的表现真是让人咋舌,国产模型何时才能追上呢?
对比下,国产模型在实际编码问题上的表现真的需要提升,希望能加快进步。
这篇文章让我反思,国产大模型在编程工具的使用中还有哪些具体的不足之处,谁能给出一些实际例子?