先和大家聊聊我的需求和我对其他工具的试用感受吧。
1、Slack
有位前辈告诉我,利用Claude官网的API,在Slack上配置一个应用后,就能直接在工作区里使用Claude模型了。而且,工作区内还有GPT4可以使用哦。
不过实测发现,回复速度相当慢,而且使用次数有限。对于那些习惯用Cursor进行上下文理解的用户,可能不太合适。不过如果你想尝试一下,加入需要一些特殊的环境(要自己准备),加入后在频道@Claude应用就行了。
工作区加入链接:https://h5ma.cn/jxn
2、Trae
这是字节跳动推出的AI代码编辑工具,跟Cursor有些相似。毕竟Trae今年一月才正式上线,所以在功能和体验上还没法和Cursor比,特别是国际版(国内版就不多说了)。国际版同样需要特殊的环境(得自己搞定)。
3、Cursor设置应用代理方式(特殊环境全局模式)
这部分就不多聊了,大家在公司上班的都懂,设置后会带来不少问题,所以我没考虑这个方法。感兴趣的可以自己去找找教程。
最后,想请教一下各位大佬,还有没有更好的方法,让上班变得更轻松愉快,求助啊~~~~
客户端竞争的实质是资源调度方式的重塑,谁能在「冯·诺依曼架构」与「神经形态计算」之间找到平衡,谁就能胜出。
©作者|neo
来源|神州问学
一、认知熵增:数字文明的致命弱点
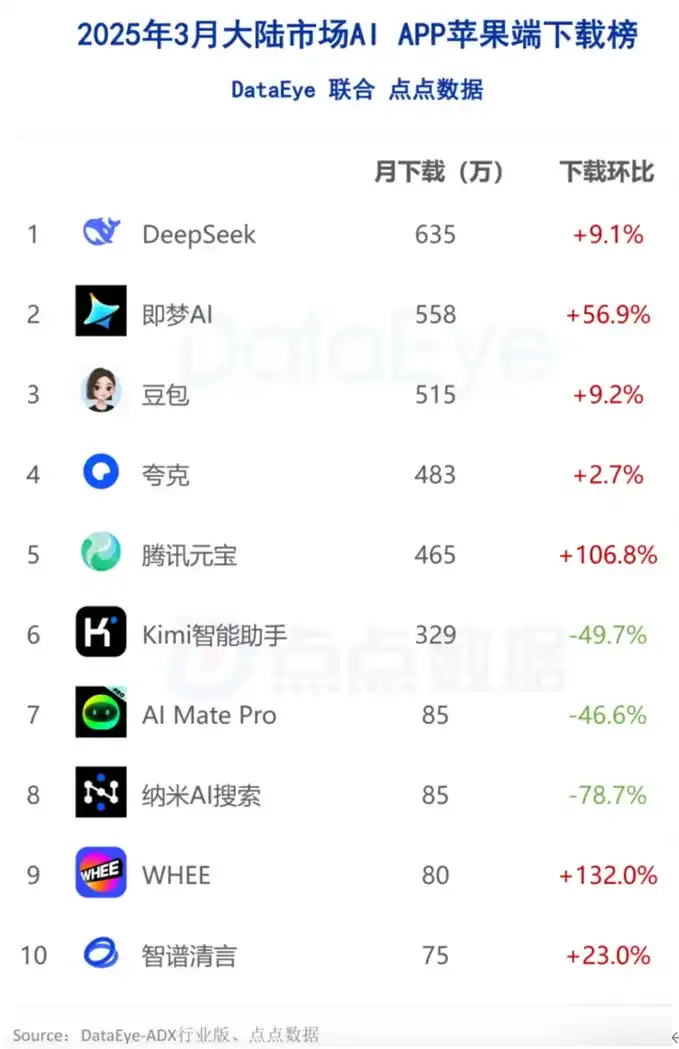
到了2025年3月,苹果平台的AI应用下载排行榜揭示了生态之间的暗斗:DeepSeek以635万的下载量位居榜首,即梦AI和豆包则分别增长了56.9%和9.2%,腾讯元宝的增速更是高达106.8%……这份榜单不仅反映了用户的选择,更是AI客户端“趋势博弈”的缩影——谁在技术和生态的协同中占据优势,谁就能掌握用户认知的入口。
腾讯研究院的《2025认知过载白皮书》揭示了数字时代的残酷现实:普通中国人平均每天接收信息高达9.3GB——这意味着,现代人一天所接收的信息量,已经超过了15世纪一个人一生的认知总和。更令人惊讶的是,尽管用户平均安装3.7个AI助手(QuestMobile数据显示年增长达到208%),认知过载指数却飙升了37%。这并不是说“工具不够用”,而是底层架构的“代际矛盾”——冯·诺依曼的线性计算模式根本无法满足人脑的非线性认知需求,就像用“马车轨道”强行适配“汽车车轮”,这种结构上的不协调注定效率会崩溃。
数据也揭示了技术失败的细节:寒武纪的MLU370 – X芯片在端侧推理市场的渗透率达到68%(IDC 2025Q1),却无法阻止Token消耗的激增——豆包用户的日均Token消耗是插件型AI的2.4倍。这说明,AI越“智能”,信息到决策的转化链条就越混乱,熵增失控才是效率危机的本质:用户在信息海洋中迷失,难以找到真正有价值的决策锚点。
当OpenAI关闭了中国的API服务,这场战争彻底揭开了“工具竞争”的伪装——国产AI必须在技术自主(打破架构限制)和生态开放(适应用户需求)之间走钢丝。这不再是简单的产品竞争,而是关乎文明存续的战略博弈:谁能重构“信息-认知-决策”的熵减链路,谁就能定义下一代人机协作的底层逻辑,让人类在数据洪流中重新夺回“思考的主权”。
二、五强裂变:从功能堆砌到熵减效能
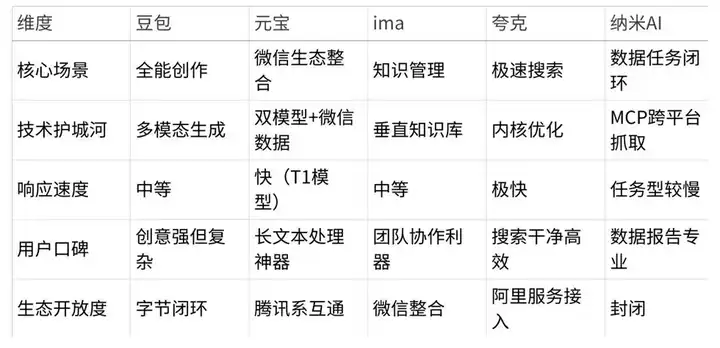
●夸克(阿里系):凭借M6多模态引擎,物流查询、学术搜索等操作压缩到“一步完成”——只需输入快递单号就能跳转到物流页面,学生在搜题时响应时间仅为0.8秒。1.48亿的月活跃用户(QuestMobile 2025Q1)背后,是“AI超级框”的精准预判。然而,代价却不小:在处理百页论文摘要时,精度比元宝落后23%,暴露了“极速搜索”与“生态闭环”之间的熵增矛盾——越追求效率,越难兼容多元的数据生态。
●DeepSeek(技术新锐):以1.94亿月活跃用户登顶增速榜(年增427%),凭借“多头潜注意力技术(MLA)”在端侧计算力上取胜:20B参数模型在骁龙8 Gen4芯片上的显存占用减少了40%,生成Python代码的延迟低于300ms,在医疗场景中,甲状腺超声报告解析的时间缩短了50%。但用户吐槽“没有情感的手术刀”——功能的极致与体验的温度之间出现了熵增冲突,暴露了技术派的致命短板。
●豆包(字节系):依靠抖音的6亿流量池,稳居1.16亿的月活跃用户。云雀模型的多模态创作,让小红书的博主在3分钟内制作带BGM的带货视频,创作时间减少了70%。但复杂的界面让人抱怨:“功能比双十一的规则还要深奥”——创意的熵减代价是体验的熵增,反映了字节系“流量驱动功能堆砌”与“用户体验简化”之间的深层矛盾。
●腾讯元宝:4164万月活跃用户证实了“长文本处理的刚需”。混元T1+DeepSeek双模型架构将百页PDF的摘要时间从23分钟压缩到5.2分钟;fNIRS脑成像实验揭示出“认知黑科技”:使用者前额叶激活区减少62%,海马体的记忆熵增仅为17%——通过预测编码降低认知负担,证明了腾讯系“生态协同+硬件优化”的熵减实力。然而,微信生态的“高墙”也让它的优势难以渗透到外部场景。
●纳米AI:虽然仅有838万的月活跃用户,却通过“MCP跨平台抓取”重塑了专业决策流程。金融分析师利用它处理财报,17步操作瞬间变为3步:自动抓取京东财报、小红书舆情、证监会公告,并生成带有动态估值模型的PPT。香农熵模型验证了“决策熵降低89%”——将“攀登金融数据的珠峰”变成了“电梯直达”。但封闭的垂直数据壁垒让它难以破圈,成为全民级工具,陷入“专业熵减”与“生态扩张”的两难境地。
三、技术革命:神经形态计算的破壁之战

金融分析师小王曾在财报分析的“信息熵地狱”中苦不堪言——爬取京东供应链数据、抓取小红书消费舆情、人工比对历史报表、用Excel绘制趋势图……每次分析至少需要3小时,冗余信息如同乱麻般让决策路径陷入混沌。如今,纳米AI的MCP跨平台抓取系统成为了破局的关键:当他发出“分析新能源汽车财报”的指令,拥有13亿参数的Bert-MCP模型瞬间拆解用户意图——京东股价波动反映出供应链脉络,小红书评测的情绪熵值映射出消费信心,证监会公告的关键词共现网络揭示政策风险。更令人震撼的是脉冲神经网络协处理器(神经形态计算的核心组件),它以0.2瓦的超低功耗驱动十亿个脉冲事件,借助类脑脉冲时序编码,适配金融数据“多源流式、动态变化”的特性,让酒店比价、研学推荐、流行病预警等多源数据如同神经簇般动态协同,仅需3分钟就能生成带有预测折线的交互式PPT。香农熵模型显示,决策路径的熵值暴跌89%——神经形态计算通过“类脑信息整合”,将金融分析从“数据攀爬”转变为“认知传送”,开启技术革命的序章。
科研领域的熵减革命同样深刻。曾有实验室研究员在一篇百页的《量子场论》文献综述中挣扎,在17篇文献中耗费了23分钟,如今腾讯元宝智能研究平台的“双引擎认知压缩”,本质上是神经形态计算对科研模式的底层重构:混元T1依托类脑并行架构,像人脑处理碎片化知识一样,200毫秒级闪电梳理文献摘要;DeepSeek-R1借助神经簇跨模态推理,5分钟构建公式推导树。fNIRS脑成像验证,使用者前额叶激活区缩减62%——神经形态计算让“类脑高效科研”从理论照进现实,真正实现了“读《相对论》像刷朋友圈一样轻松”。不过,数据生态仍面临“阿喀琉斯之踵”——当比较《财新》与《经济观察》对美联储降息的观点时,传统模型因训练数据偏差会产生42%的情感极性误判,暴露出跨信源一致性建模的技术短板。
2026技术奇点预测
用波函数Ψ描述用户意图的动态演化,将数据孤岛、生态割裂等约束抽象为势阱V(data)(可以理解为“数据协同的阻力场”),构建决策熵减的“薛定谔-需求方程”:
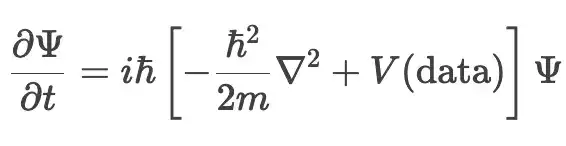
(注:Ψ为意图概率幅,V(data)表征数据孤岛与跨域协同阻力,方程揭示意图演化受数据生态约束的量子化规律,神经形态计算通过“类脑脉冲突破势阱”,实现决策熵减)
三阶段技术跃迁
1. 2025Q4:类脑芯片突破冯氏瓶颈(寒武纪MLU580量产)
想象一下,借助 IBM TrueNorth 架构的神经形态芯片,它能以仅仅 0.2 瓦的功耗,精准地调度多达十亿次的脉冲事件。这种脉冲时序编码就像神经元的放电序列一样,能够灵活应对酒店比价、研学推荐、流行病预警等多样化的任务。当你搜索“三亚亲子游”,这个芯片就像人脑一样,迅速调出记忆碎片,自动激活与之相关的地理位置、消费习惯和天气预警等模块。通过生物激励式的任务规划,它能把信息的复杂度降低到 0.38 bits,而传统的引擎则高达 5.72 bits。更让人兴奋的是,3D 堆叠的忆阻器技术,就像给芯片装上了类脑的突触,让内存访问的能耗从 61% 降到 9%,知识图谱的延迟也仅为 5 毫秒,几乎达到了人脑神经突触的信息传递速度。这为未来的联邦学习和量子-经典混合架构打下了坚实的基础,使神经形态计算从单一技术逐步提升至全栈能力。
2. 2026Q2:联邦学习打破零数据限制(纳米 AI 实验室原型)
我们聚焦于跨信源一致性建模这一难点,纳米 AI 凭借神经形态计算的“脉冲语义对齐”能力,创造出了一种全新的数据协同模式。在无需共享《财新》和《经济观察》的原始数据的情况下,神经形态芯片驱动的脉冲神经网络能够像人脑那样整合来自不同渠道的信息,精准对齐二者的观点。通过脉冲时序编码模拟神经元对语义的分布式表征,模型可以理解《财新》的“鹰派表述”与《经济观察》的“温和解读”在美联储降息分析中的情感差异,将分析的情感误判率从 42% 降至可接受范围。神经形态计算为联邦学习提供了“类脑语义理解”的基础支撑,成功破解了数据孤岛问题,让跨信源的协同不再是空谈,推动神经形态计算从硬件层面深入到算法层面。
3. 2026Q4:量子-经典混合架构商业化(阿里达摩院进展)
阿里达摩院在反事实预载机制上进行了升级,让神经形态计算成为连接量子与经典世界的“认知桥梁”。通过分析用户的行为轨迹,借助神经形态芯片的类脑模式识别,提前 3 小时预判出“股市暴跌应对”等潜在需求,实现信息供给与决策需求之间的“量子纠缠”。在处理“上海-东京差旅”任务时,文化与经济因素构成了一个多维能量场,神经形态计算驱动的混合架构就像人脑在复杂约束下快速决策一样,让决策路径在 12 个量子态内收敛(而传统算法则需遍历 27 个状态),效率提升超过 50%。基于薛定谔-需求方程,通过波函数Ψ描述意图的演变,量化社会规训与资源约束,神经形态计算让“读相对论如同刷朋友圈”的认知飞跃变得商用,成功完成从技术突破到实际应用的闭环,真正引领神经形态计算的进步,重塑人类的决策方式。
在神经形态计算的基础上,认知交互的量子化革新正从理论走向商业现实。当技术的熵减突破临界值,神经形态计算就像神经突触一样,连接了硬件、算法和场景。人类的认知将穿越信息的黑暗森林,迈向决策的殿堂——这并不是科幻,而是在神经形态计算推动下,技术革命必然发生的结果。
四、生态博弈:联邦熵减的文明契约
在 AI 生态中,衡量的标准从“功能是否完善”转向“认知熵减率是否高”。胜负的关键就在于玻尔兹曼熵变公式:
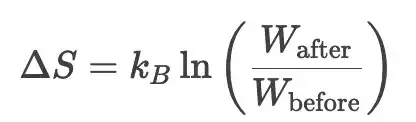
在公式中,W 代表技术迭代后的可能性空间,kB 是生态竞争的“胜负常数”——谁能压缩可能性空间、把 ΔS 压到最小,谁就掌握了生态的话语权。
▪豆包:通过多模态创造实现降维打击(WW↑ 但 ΔS 波动大)
▪纳米AI:通过约束优化实现熵减(ΔS≈−0.38kB)
▪终极赢家:在 ΔS→0 时仍保持演化能力的产品
五强对弈:熵减战场的生态角力
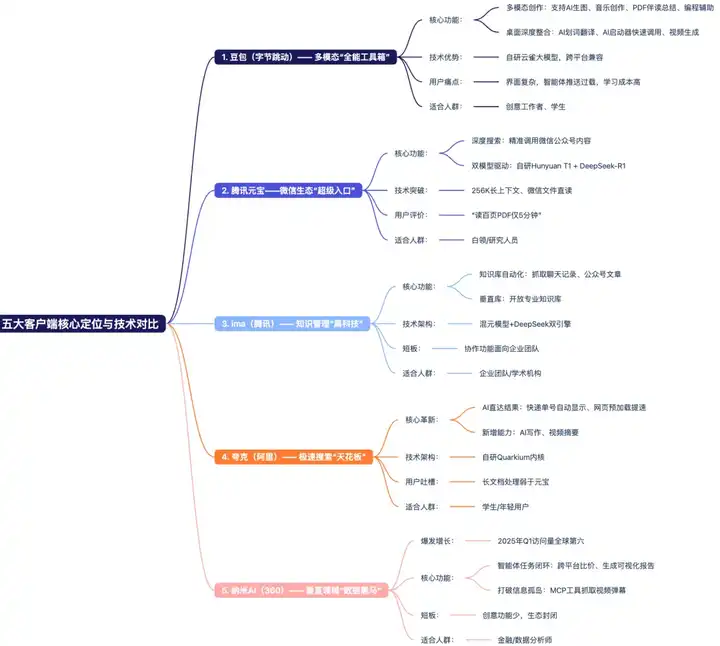
(一)豆包:多模态降维冲击
作为五强之一,豆包通过“多模态创造”发起了降维打击。它的异构内存池(HMP)专门为抖音的流量洪峰设计,让小红书的博主在 3 分钟内产出带 BGM 的带货视频;但多模态交互也让用户陷入“功能迷宫”,需要在“体验熵增波动”中找到平衡点,锁定 C 端内容的入口,依靠短视频、直播等场景来争夺用户的“认知第一触点”。在创意领域,豆包成为创作者突破内容生产瓶颈的首选,过去三天的工作现在几小时就能完成,帮助用户腾出更多时间去创作,成为五强中“创意熵减”的代表选手。
(二)纳米 AI:约束优化锁垂类
纳米 AI 在五强的生态博弈中,走的是“约束优化”路线,实现了 ΔS≈−0.38kB 的熵减。它依托 IBM TrueNorth 类脑架构的脉冲神经丛林,在金融和电商这些强约束领域(如合规和预算)中精准匹配需求。当你查询“三亚亲子游”时,能联动酒店比价、研学推荐和流行病预警三大神经簇,锁定 B 端的垂直生态,专注于“精准需求匹配”的难题。在这些细分领域,纳米 AI 凭借对任务闭环的严格把控,成为金融从业者和电商行业里的“垂直专家”,是五强中专注于垂直熵减的重要力量。
(三)夸克:极速体验筑壁垒
夸克作为五强之一,主打“极速体验”。它通过 RISC-V 指令集驾驭持久化内存(PMEM),将网页预加载时间压缩至 47 毫秒,成为内存优化领域的佼佼者,让用户上网时不再卡顿,力求实现“上网别卡壳”。然而,在论文分析等场景中,知识图谱的碎片化使其精度比元宝低了 23%。尽管如此,夸克凭借“极速熵减”在极速浏览和日常信息查询的生态位中依然占据一席之地,成为五强中“效率体验派”的典型代表。
(四)元宝:生态协同谋全局
腾讯元宝在五强中以“生态协同”著称。其双模型路由网关就像精密的神经交换机——混元 T1 处理简单咨询迅速如子弹,DeepSeek-R1 则能够稳稳地处理百页 PDF。不过,在微信生态的高墙外,42% 的数据误差率依然是一个难题。然而,在办公场景中,元宝利用微信文件解析和会议纪要管理等能力,成为职场人压缩办公流程熵的得力助手。在五强中它是“综合协同王”,试图通过全局生态布局掌控熵减竞争的节奏。
(五)ima:知识深耕筑高地
作为五强中专注于知识管理的玩家,ima 建立了文博知识库等专业知识矩阵,深耕垂直知识领域。无论是专业知识查询还是长文解析辅助,ima 凭借其“知识深度”,为研究者和知识探索者提供熵减服务,力求在知识管理的生态位上,以精准、专业的知识供给,降低用户获取知识的认知熵,是五强中“知识深耕派”的代表,默默夯实知识生态的熵减基础。
价值密度强化设计:五强熵减博弈的“破局三板斧”
在 AI 生态的熵减竞争中,豆包、纳米 AI、夸克、元宝和 ima 五大玩家,分别通过数学模型、技术黑箱和实验方法构建了“价值密度强化体系”,用可量化、可验证的手段来定义“谁能真正让用户的认知更高效”。以下是具体的拆解:
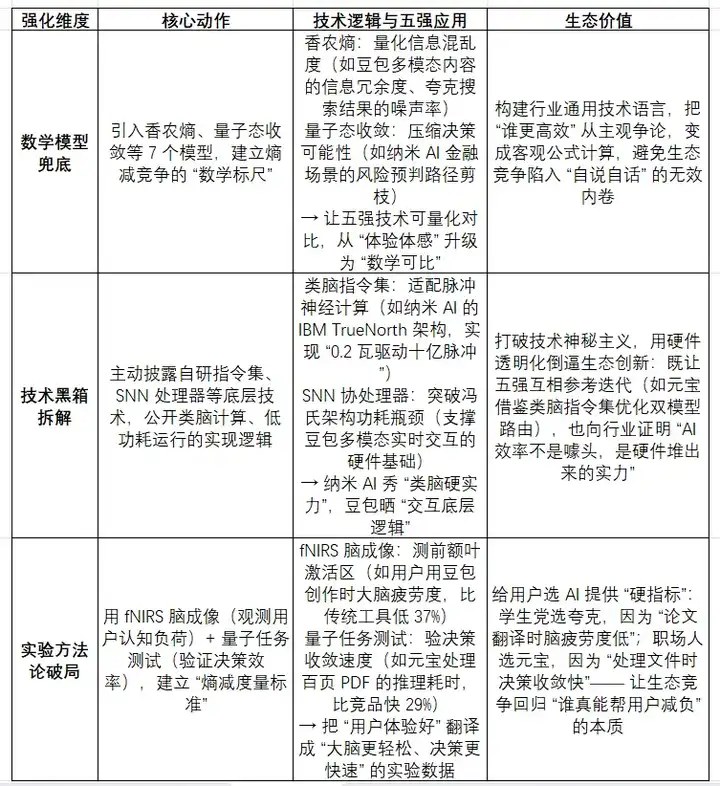
五强通过这套体系,把生态竞争从“功能堆砌”升级为“效率较真”——最终用户不需要懂技术,只需关注“脑疲劳度降低了多少、决策时间缩短了多久”,就能挑选出真正的“熵减神器”。
在纳米 AI 构建的脉冲神经丛林中,IBM TrueNorth 架构如幽灵般渗透决策逻辑。那颗仅需 0.2 瓦功耗却能驱动十亿次脉冲的协处理器,让像“三亚亲子游”这样的查询轻松激活酒店比价、研学推荐和流行病预警的神经簇协同,亚毫秒级意图预测,直接超过传统 GPU 的 7.4 瓦蛮力计算。而夸克 Pro 则在内存赛道另辟蹊径——凭借 RISC-V 指令集驾驭持久化内存(PMEM),网页预加载快至 47 毫秒,代价是知识图谱的支离破碎,论文分析的精度与元宝相比低了 23%。
DeepSeek 则手握“多头潜注意力(MLA)”的利刃,直击端侧算力的软肋。它将 20B 参数的大模型塞进手机里,显存占用大幅降低 40%,在骁龙芯片上 Python 代码生成的延迟突破 300 毫秒。在医疗场景中,甲状腺超声报告的解析路径被简化为一键操作。豆包 V3 的异构内存池(HMP)在抖音流量洪峰中起伏:帮助小红书博主在三分钟内制作带 BGM 的带货视频,但也让用户陷入功能迷宫的熵增陷阱。腾讯元宝的双模型路由网关,宛如精密的神经交换机——混元 T1 处理简单咨询快得像子弹,DeepSeek-R1 则能够稳稳处理百页 PDF,但在微信生态外,42% 的数据误差率仍是一个棘手问题。
纳米 AI 利用脉冲神经丛林和 IBM TrueNorth 架构重塑了“决策可能性边界”;夸克 Pro 则通过 RISC-V 指令集压缩内存熵,但在知识精度上留下了遗憾;元宝在微信生态内外承受数据误差率的拉扯;豆包在多模态迷宫中寻求体验熵的平衡;而 ima 在知识深海中默默沉淀……这场五强共同参与的生态博弈,本质上是在探索“如何将认知熵减至极致,并持续演化”的文明轨迹。AI 不再仅仅是替代思考的工具,而是重塑“思考时空拓扑”的新维度——这正是联邦熵减的终极奥义,也是五强在生态博弈中共同追求的未来愿景。
参考
https://news.qq.com/rain/a/20250407A05PGQ00





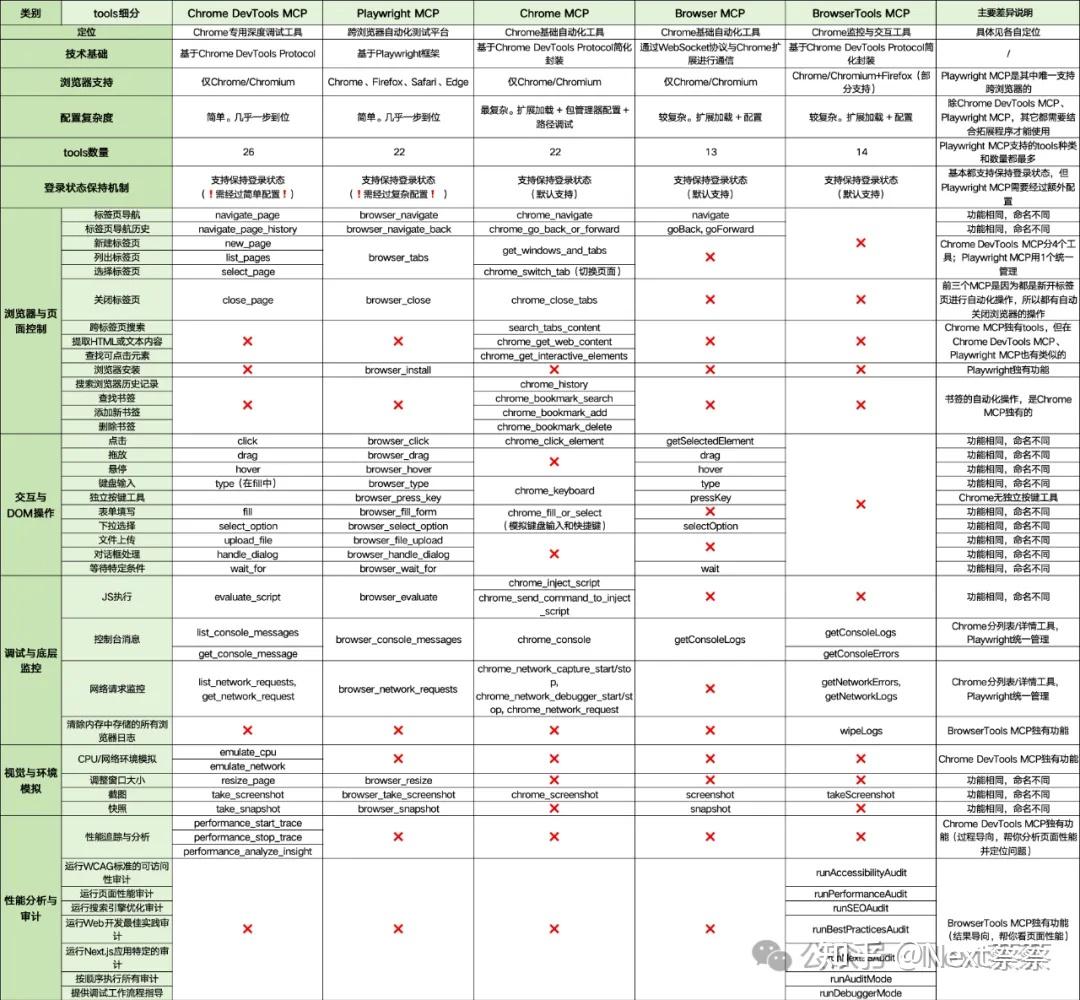



设置代理真心麻烦,感觉有点不值得,还是要找些更简单的方法。
如果Claude速度再快点就好了,感觉挺有潜力的。
我尝试过使用Claude,发现上下文理解的确不如Cursor顺畅,希望能有优化。
这篇分析很有深度,特别是提到的信息过载问题,真是现代人的烦恼。
不太明白为什么国际版的Trae需要特殊环境,这样的门槛会导致用户流失。
信息过载的问题真的很让人头疼,感觉每天都在被淹没。
听说设置代理会有很多问题,真心不想再经历一次这样的麻烦。
有没有其他的工具推荐呢?我也想让工作更轻松!
对于信息量如此庞大的时代,如何选择合适的工具呢?
我尝试过设置代理,确实遇到不少问题,真心希望能有更简便的方法。
对于信息过载,我觉得提高个人信息筛选能力也很重要,单靠工具不够。
这篇文章提到的资源调度方式让我想到了很多,未来的工具是否会更智能?
工作中使用Claude模型的环境搭建有点复杂,能否分享一下更简单的使用技巧?
信息过载的问题真心让人无奈,如何提升自我筛选能力才是关键。
信息量这么大,居然还要自己搭环境,真是让人无奈。
信息过载真的让人疲惫,想知道大家怎么应对的。
Trae这个工具听起来很新,功能不成熟,大家觉得用起来怎么样?
信息过载的问题越来越严重,大家觉得怎样才能更有效地管理信息?
数字时代的竞争越来越激烈,真希望有个简单易用的AI工具能解放我们。
信息过载真是个大问题,想知道大家都是怎么筛选有效信息的。