这个话题可真是老生常谈了!你可能会发现,试过三个不同的AI后,反而对每个都爱得不行。
昨天我被公司的CTO问了个很有意思的问题:“我们到底应该选哪个AI呢?Claude太贵了,ChatGPT总是出错,Gemini…感觉存在感不强?”
经过一番思考,我意识到,很多人选择AI就像在抽盲盒,完全靠运气。
作为一个在AI界摸爬滚打了几年的工作者,我想说:别再纠结哪个是最好的了,2025年已经是多模型合作的时代了。
上周我们团队做了个实验,针对同一个Python重构任务,Claude用了8分钟给出企业级方案,ChatGPT只花了5分钟,但有3个bug,至于Gemini…嗯,2分钟出结果,能跑就行。
我眼里的三大巨头:各有特点
先说个有趣的事,Stack Overflow最近的调查显示,84%的开发者在使用AI,但只有3%的人表示“非常信任”。
这数据一看就觉得有点意思,想想我每天调试AI生成的代码调到崩溃,确实是这样。
Claude:像“处女座”的代码大师
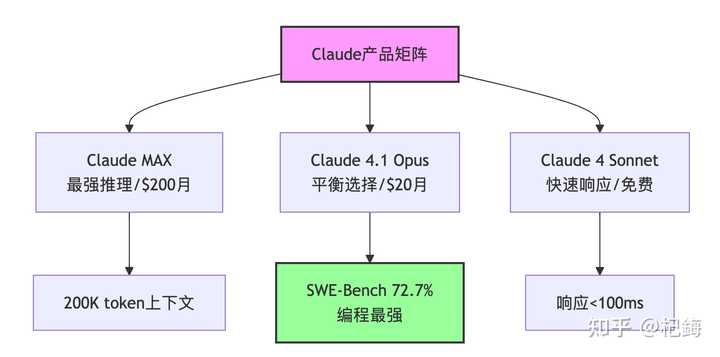
提到Claude,我的第一反应是“贵”,第二个就是“真不错”。
Anthropic这家公司蛮有意思的,创始人都是从OpenAI出来的,听说是理念不合——他们想要打造更“安全”的AI。
搞技术的都知道,Constitutional AI可不是噱头,背后确实有实打实的东西。
简单来说,它的训练过程可以用一个公式表达:
其中 是监督学习的损失,
是基于“宪法约束”的强化学习损失。简单点说,它不仅学会怎么回答问题,还学会了哪些问题不该回答。这个$lambda$的权重系数听说调了好几个月才找到最佳值(大概在0.3-0.5之间)。
我觉得Claude最厉害的就是它的Constitutional AI,换句话说,它会进行“自我审查”。
上个月我让它帮我写个爬虫,它居然提醒我注意robots.txt和法律风险——虽然有时候有点烦,但至少不会像某些AI那样啥都敢写。
- 处理18K行的遗留代码时,Claude能理解整体架构(而其他两个直接傻眼)
- 月费更贵的Claude Code,一周帮我省了近27小时
- 不过!响应速度确实慢,大概78 tokens/秒,泡杯咖啡回来才算完成
顺便提一下,Reddit上的Python社区都炸了,大家都在说“Claude写Python完胜GPT”。
根据我自己的测试,确实在Django和FastAPI框架上,Claude的代码质量高得惊人。
这其实和位置编码有关。Claude使用的是旋转位置编码(RoPE):
这种编码在处理长代码文件时特别有优势,能更好地保留相对位置信息。而GPT系列还在用传统的正弦位置编码:
当代码超过8K tokens时,性能差异就显现出来了。我处理一个15K行的项目时,Claude能够准确找到函数调用关系,而GPT-4经常搞混。
ChatGPT:全能选手
OpenAI这边就热闹得多了。
从GPT-3.5到现在的GPT-5(今天大家都在讨论,降智与否,还不如OSS),更新速度快得让人心痛。
你知道GPT系列的核心是什么吗?其实就是自回归语言建模,数学原理挺简单的:
OpenAI的多头注意力机制才是真正的黑科技:
这个 的缩放因子特别关键,要是没有它,梯度可能会爆炸。有次我自己实现Transformer,忘了加这个,loss直接飞到nan,调了一下午才发现问题。
最新数据显示,ChatGPT的周活跃用户超过7亿,市场份额达到60.5%,妥妥的老大哥。但你知道吗?开发者社区已经开始“叛变”了,Cursor IDE(不让大陆用户使用Claude)和Aider等主流工具都把默认模型换成了Claude。
真实案例:需求一样,风格却大不同
# ChatGPT的代码(简洁却有隐患)
async def fetch_data(urls):
"""并发获取数据,简单明了"""
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
return await asyncio.gather(*tasks) # 错误处理给忘了...
# Claude的代码(虽然冗长但稳妥)
async def fetch_data(urls: List[str]) -> List[Dict[str, Any]]:
"""
并发获取数据,包含全面的错误处理
Args:
urls: 要获取的URL列表
Returns:
包含响应数据的字典列表
Raises:
FetchError: 当获取失败时
"""
results = []
async with aiohttp.ClientSession() as session:
for url in urls:
try:
async with session.get(url, timeout=30) as response:
if response.status == 200:
results.append(await response.json())
else:
logger.warning(f"获取 {url} 失败: {response.status}")
results.append({"error": f"HTTP {response.status}"})
except asyncio.TimeoutError:
logger.error(f"获取 {url} 超时")
results.append({"error": "timeout"})
except Exception as e:
logger.exception(f"获取 {url} 时出现意外错误")
results.append({"error": str(e)})
return results说到ChatGPT,它的生态圈真的是厉害,GitHub Copilot的用户超过2000万,其中有130万是付费用户。
不过,老实说,GPT5的错误率还真不低,有人说它甚至不如那种20B的开源模型,还有人怀疑是不是降智版的,这就有点搞笑了。
Gemini:低调的赢家
说到Google的Gemini,它真的是相当低调,但价格实惠啊!
Gemini Flash每百万token只要$0.10,跟Claude比起来便宜了150倍!
从技术角度讲,Gemini最牛的地方在于MoE(Mixture of Experts)架构。每次推理时并不是所有参数都被激活,而是通过门控机制来选择专家:
这里的门控函数$G(x) = text{softmax}(W_{gate} cdot x + b)$决定了哪些专家会被激活。这就是为什么Gemini能做到又大又快——它的模型参数有1.8T,但每次只激活约200B。
不过,这里有个潜在问题,负载平衡非常重要。Google使用了一个辅助损失函数:
表示专家$i$的使用频率,
是它的容量。这个
系数如果设置得不好,某些专家可能会超载,性能就会下降。我在自己的项目中尝试过类似的架构,这个参数调了整整两周…
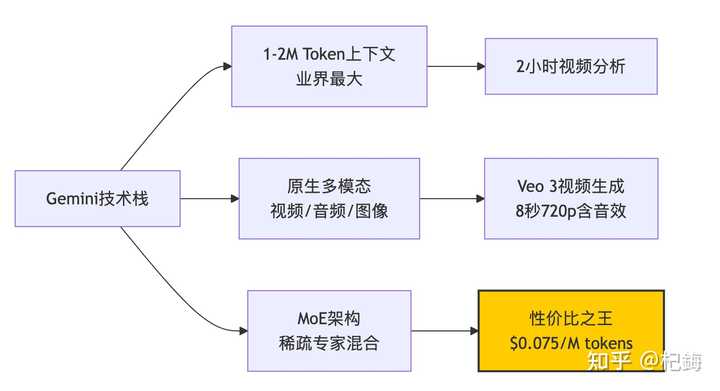
说真的,上周我用Gemini分析了一个两个小时的技术讲座视频,它居然能很准确地定位到某个概念在第几分钟出现。这种能力,其他两个可真比不了。
当然,Gemini也有一些不足之处:
- 在国内访问相对容易,但速度有时候不太稳定
- 编程能力确实不及前两者,SWE-Bench的得分只有63.8%
- 与Google生态绑定得太紧,如果不使用GCP,优势就会打折扣
编程能力对比:我的实验数据
作为程序员,最关心的当然是写代码的能力。我搞了个“创建俄罗斯方块游戏”的测试,结果还挺有趣的。
不过在看结果之前,得先理解这些模型是如何“理解”代码的。其实,它们本质上是把代码进行token化,然后计算上下文的相关性:
这个前馈网络(FFN)的隐藏维度通常是模型维度的四倍。Claude的维度是8192,所以FFN的维度是32768——这也就是它能够很好理解复杂代码结构的原因。
基准测试成绩单(2025年1月数据)
| 测试项目 | Claude 4 | ChatGPT | Gemini 2.5 | 备注 |
|---|---|---|---|---|
| HumanEval | 92% | 88% | 85% | 基础算法 |
| SWE-Bench | 72.7% | 54.6% | 63.2% | 真实工程任务 |
| LiveCodeBench | 75.8% | 68.2% | 65.1% | 竞赛算法 |
| 俄罗斯方块测试 | 完美运行 | 有小bug | 能跑就行 | 我的测试 |
Claude生成的代码包含了完整的错误处理、单元测试,甚至还有性能优化的建议。
ChatGPT的代码更简洁易懂,特别适合用作教学。
至于Gemini…嗯,它生成速度最快,2分钟解决问题,虽然效果有点简陋。
不同语言的表现差异
Python生态:Claude > ChatGPT > Gemini
- Claude:在Django/FastAPI方面达到了专家级水平
- ChatGPT:在数据科学库(如pandas、numpy)方面表现更强
- Gemini:适合写一些简单的脚本
JavaScript/TypeScript:ChatGPT ≈ Claude > Gemini
这个有点意外,可能是因为GitHub上JS项目最多,ChatGPT的训练数据更丰富。上次我写React组件时,ChatGPT给的hooks用法确实更地道。
系统编程(C++/Rust/Go):Claude >> ChatGPT > Gemini 在内存管理上,Claude简直是降维打击。有次我调试一个use-after-free的bug,只有Claude准确指出了问题。
多媒体能力:各有千秋
这一块Gemini突然就强势崛起了。
图像生成对比
- ChatGPT + DALL-E 3:艺术感最强,非常适合创意设计
- Gemini + Imagen 3:生成的图像更真实,并且有SynthID水印技术
Claude的图像处理能力真是让人惊叹
Claude虽然不生成图片,但它的图像理解能力可是杠杠的,OCR的准确率高达95%。上个月我做PPT时,发现用ChatGPT生成的图片更有那种“感觉”,不过Gemini生成的图像在正式场合使用更合适。
视频处理:Gemini的强项
说到视频处理,Gemini的Veo 3真的是牛,能在2分钟内生成8秒的720p视频,还带音效,已经和YouTube Shorts整合了,简直是内容创作者的福音。虽然OpenAI的Sora质量更高,但那个等待的时间,真的是够我简单搞定一个版本了。
成本分析:钱包在哭泣
来算算这笔账,如果一个10人的团队每月处理10M tokens,成本可不低。
先来普及一下token的计算方式,一般说来: 。
中文的复杂性更高,一个汉字大概要1.5到2个tokens。所以在写中文文档时,真的是费钱,我一般先用英文的提示,再翻译回来。
为了控制成本,有个经典公式: 。
这里的重试率很重要,如果模型经常输出无用的信息需要重试,成本就会翻倍。
我统计过,Gemini的重试率大约是15%,而Claude的只有5%。从长远来看,Claude反而更省钱。
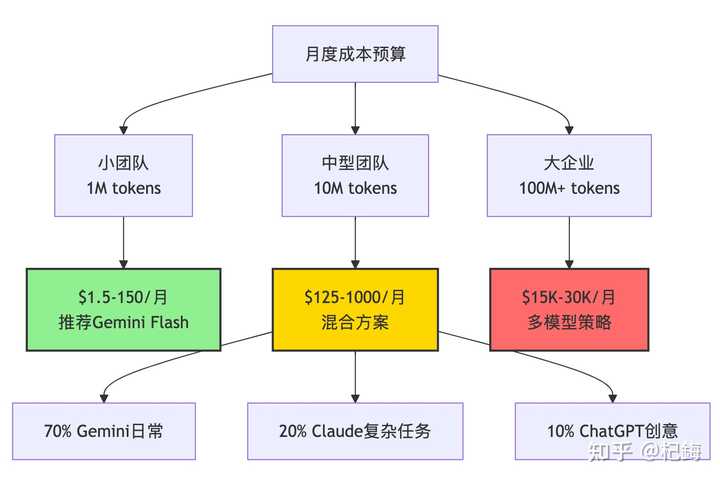
个人开发者的选择:
- 预算宽裕的:Claude Pro($20/月)+ 偶尔用ChatGPT。
- 预算有限的:Gemini的免费版(每月180,000次补全!)。
- 折中的:ChatGPT Plus($20/月),通用性最佳。
企业用户的选择: 有个数据显示,43%的企业员工使用两个以上的AI工具。我们团队的策略是:
- 核心代码:Claude(虽然贵,但很值得)。
- 日常查询:Gemini(便宜且数量大)。
- 创意文案:ChatGPT(无可替代)。
安全性问题:被忽略的重点
自从o3模型的幻觉率达到48%的消息曝光后,大家都开始重视这个问题了(GPT5还没正式发布,具体情况不清楚)。
根据Vectara的测试结果:
- Gemini 2.0 Flash:幻觉率仅为0.7%(最低)。
- Claude 4系列:大约2-3%(得益于Constitutional AI的支持)。
- ChatGPT GPT-4.1:5-8%(还算可以接受)。
- OpenAI o3/o4:33-48%(翻车现场)。
幻觉率是怎么计算的呢?其实就是看模型输出的条件概率分布和真实分布之间的差异:
。
Claude之所以幻觉率低,秘密在于它的RLHF优化目标与众不同:
。
这个Constitutional Score就是关键,它会对不安全或不准确的输出进行惩罚。
我测试过同样的医疗问题,Claude会说“我不是医生,建议咨询专业人士”,而某些模型则会胡编乱造治疗方案。
在医疗、法律等领域,还是老老实实用Claude吧,真的很神奇,为什么呢?
因为Claude使用的是实实在在的数据,而GPT大多数情况下是闭门造车。
我见过用ChatGPT写合同条款,结果被法务骂得很惨的案例。
Gemini的利用网络数据的能力也是非常强大。
2025年的最新动态与趋势
技术更新的节奏(持续关注中)
- 2025年8月:Claude 4.1 Opus发布,混合推理模式。
- 2025年3月:Gemini 2.5 Pro增加“思考”功能。
- 2025年8月:OpenAI发布GPT5推理模型(使用需谨慎)。
说到响应速度,这里面的学问可不少。推理速度主要受这个公式影响:
。
Gemini Flash能达到每秒200+ tokens,秘诀在于它的稀疏激活——实际FLOPS需求只有密集模型的1/8。而Claude的深度思考模式会增加额外的“思考token”:
。
这个Thinking部分可能是Output的3到5倍,所以看起来速度慢,但准确性明显提高。
我测试过一个算法题,加上思考模式后,错误率从12%降到2%。
开发者生态的变化
有个很有趣的趋势是:主流开发工具都在“去OpenAI化”。Cursor默认使用Claude,Continue支持多模型,甚至连微软的VS Code也开始支持Gemini了。
从信息论的角度来看,多模型策略实际上是在优化信息熵:
。
单一模型的输出熵是固定的,但组合多个模型可以降低整体的不确定性。
这就是为何43%的企业在使用多模型策略——这可不是跟风,是真的有效。
我觉得这反映出一个事实:没有万能的AI,只有适合特定场景的AI。
我的使用策略(不断优化中)
经过无数次的踩坑,我现在的工作流程是这样的:
开发阶段的分工
我的AI工具配置文件 (.ai-config.yaml)
development:
requirement_analysis: "chatgpt" # 理解需求最准
architecture_design: "claude" # 设计最严谨
implementation: "claude" # 代码质量最高
quick_prototype: "gemini" # 最快出活
testing: "claude" # 调试能力最强
documentation: "chatgpt" # 文档最易读
daily_tasks:
code_review: "claude"
refactoring: "claude"
bug_fixing: "claude"
learning_new_tech: "chatgpt"
data_analysis: "gemini"具体场景选择
紧急修复bug:先用Gemini快速处理,再让Claude验证一下。重构老代码:Claude在这方面可是个专家,尤其对老代码特别有一套。
写技术方案:可以用ChatGPT起个草稿,接着让Claude来把关。处理大文件:Gemini的上下文能力很强,能应对2M token的文件。面试算法题:Claude思路清晰,特别适合这个。
一些不成熟的建议
折腾了这么久,我有几点体会:
- 别迷信benchmark:虽然SWE-Bench给了72.7%的成绩,听起来很厉害,但实际使用时可能会遇到问题。
- 成本要算总账:Claude虽然贵,但如果能省下调试的时间,其实是划算的。
- 保持skeptical:AI生成的代码一定要仔细审核,尤其是在处理并发和内存管理时。
- 多模型是趋势:到了2025年,还在纠结用哪个AI,不如学会灵活组合使用。
最后,讲个段子:上周组里的新人(也是个动漫迷)问我“哪个AI最好”,我打趣地说:“佐为就在你的棋盘里。”
意思就是,你最好的AI,实际上就在你的代码里~
参考资源与工具推荐
官方文档
- Claude官方文档
- OpenAI API文档
- Google AI Studio(注意,这里不是专门地区,无法享用免费额度)
基准测试平台
- Chatbot Arena排行榜
- SWE-Bench官网
- Vectara幻觉率测试
社区讨论
- r/LocalLLaMA – 模型对比讨论
- Twitter #AIEngineering – 实时更新