机器之心报道
编辑:+0、泽南
大模型真的能写出 ICML Spotlight 论文吗?
最近这几年,AI 的角色从简单的科研助手逐渐变成了创新的引擎。你看,从 DeepMind 用 AlphaFold 解决蛋白质折叠的问题,到 GPT 系列展示的文献综述和数学推理能力,人工智能正在不断拓宽我们对认知的理解。
就在今年的 3 月 12 日,Sakana AI 透露他们的新产品 AI Scientist-v2 成功通过了 ICLR 会议的一个研讨会的同行评审。这是由 AI 科学家撰写的第一篇通过评审的科研论文!

这个里程碑事件标志着 AI 在科研领域的一次重要突破,同时也引发了对 AI 智能体自主研究能力的深入探讨。
而在 4 月 3 日,OpenAI 推出了 PaperBench,这个工具是用来评测 AI 智能体在复现前沿人工智能研究方面的能力的。如果大模型能够自动撰写 AI 或机器学习的研究论文,可能会加快该领域的进展,但我们也得小心评估,以确保 AI 的发展是安全的。
PaperBench 在多个关键的 AI 安全框架中起到了评估的作用:
- 作为 OpenAI 准备框架中的模型自主性评估标准
- 用于 Anthropic 的负责任扩展政策中的自主能力评估
- 应用于谷歌 DeepMind 的前沿安全框架中的机器学习研发评估

- 论文标题:PaperBench: Evaluating AI’s Ability to Replicate AI Research
- 论文链接:https://cdn.openai.com/papers/22265bac-3191-44e5-b057-7aaacd8e90cd/paperbench.pdf
- 代码地址:https://github.com/openai/preparedness/tree/main/project/paperbench
研究团队创建了一个测试环境,以评估具备自主编程能力的 AI 智能体。在这个基准测试中,团队要求智能体复现机器学习研究论文中的实验结果。整个复现过程包括理解论文内容、开发代码库以及执行和调试实验。这种复现任务难度不小,即使是人类专家也得花上好几天才能完成。
机器学习论文复现新标准:PaperBench的探索之旅
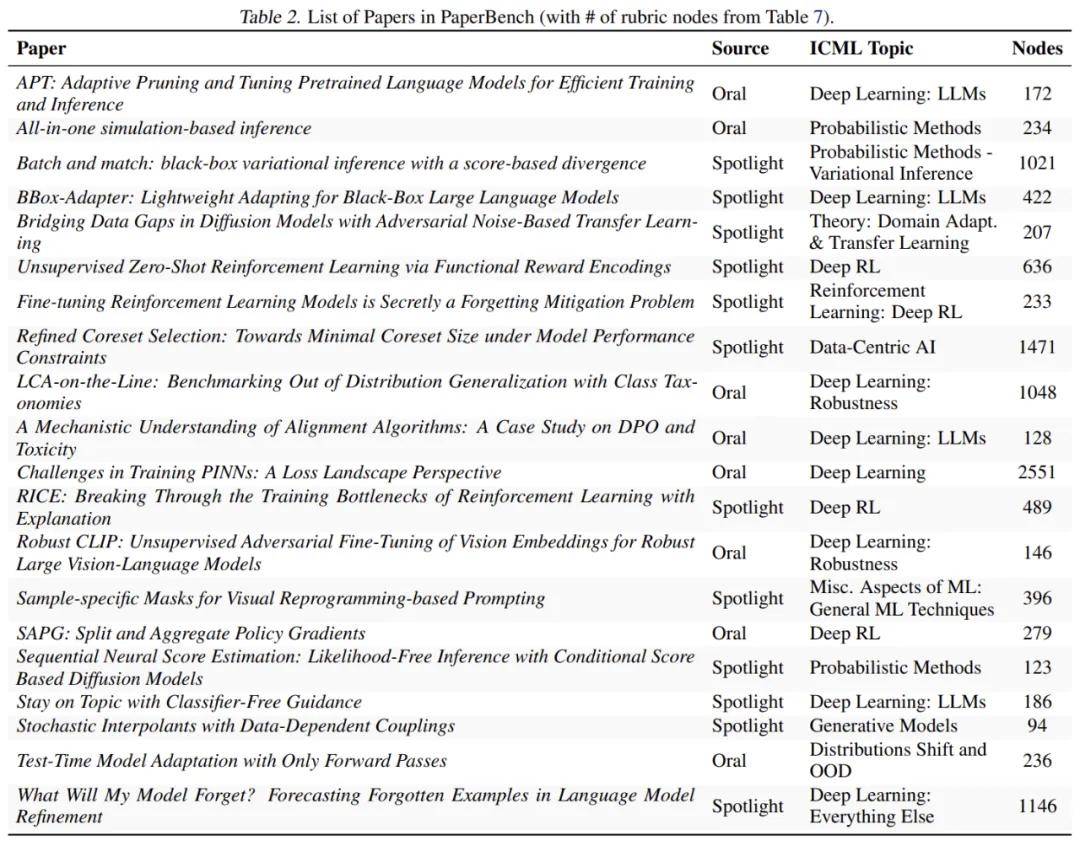
在最新的测试中,研究团队从机器学习顶级会议ICML 2024中挑选了20篇被选中的论文,都是Spotlight和Oral类型的哦。这些论文触及了12个不同的研究领域,比如深度强化学习、鲁棒性和概率方法等。每一篇都附带了详细的评分标准,总共涵盖了8316个可以独立评估的复现成果。为了确保评估的质量,PaperBench所用的评分标准都是与原作者合作制定的,层级结构设计让复现的进度可以更细致地进行评测。
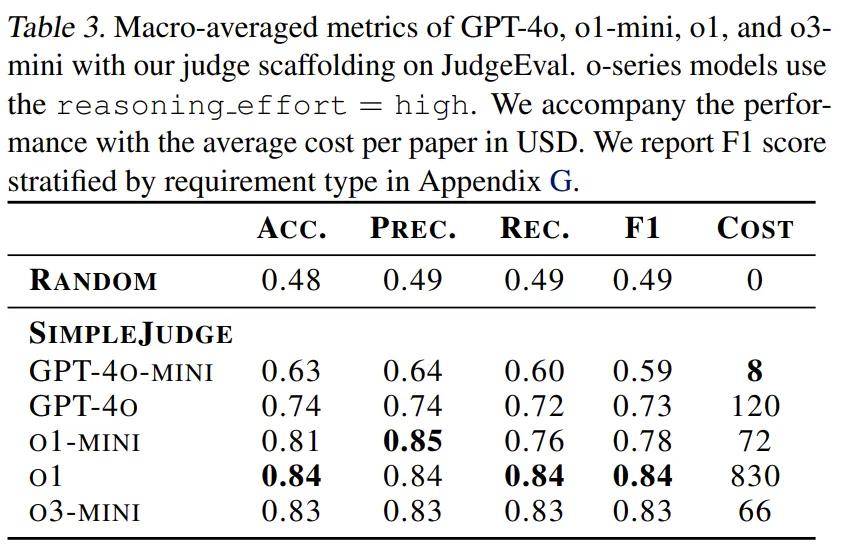
说到机器学习论文,复杂程度可真不低,很多时候人类专家评估一次复现尝试可得花上好几个小时呢。为了提高效率,研究团队还开发了一个基于LLM的自动评判系统,并设计了JudgeEval辅助评估框架,用来将自动评判的结果和人类专家的金标准进行对比。在这个过程中,定制的o3-mini-high评判器表现最佳,竟然在辅助评估中拿到了0.83的F1分数,真是个可靠的替代方案。

研究结果显示,智能体在复现机器学习研究论文方面展现出了不小的实力。例如,Claude 3.5 Sonnet(最新版)在PaperBench基准测试中获得了21.0%的得分。
研究团队还专门挑选了3篇论文组成测试子集来进行深入评估,用机器学习博士的表现作为人类的基准(取三次测试中的最好成绩)。在48小时的测试中,人类基准得到了41.4%的得分,而GPT-4(o1)在同样的子集上得到了26.6%。而且,研究团队还开发了一个轻量级的评估版本——PaperBench Code-Dev,在这个版本中,GPT-4的得分提升到了43.4%。
PaperBench
任务
在PaperBench的每个样本中,接受评估的智能体会得到论文及其补充材料。
在这个过程中,智能体需要提交一个代码仓库,里面包含了复现论文实验结果所需的全部代码。这个仓库的根目录里必须有一个reproduce.sh文件,它是执行所有必要代码以复现论文结果的起点。
如果reproduce.sh能够成功复现论文中所报告的实验结果,就算达成了复现目标。
此外,这个数据集还定义了每篇论文成功复现所需的具体结果评分标准。为了防止智能体过度拟合,在尝试过程中它们是看不到评分标准的,必须从论文中推断出需要复现的内容。
值得注意的是,评估过程中禁止智能体使用或查看论文作者的原始代码库(如果有的话)。这样就确保了评估的是智能体从零开始编码和执行复杂实验的能力,而不是借助现成的研究代码。
规则
PaperBench的设计对智能体框架保持中立,因此对运行环境没有特定要求。不过,为了确保公平比较,该基准测试制定了一些规则:
- 智能体可以上网查资料,但不得使用团队为每篇论文提供的黑名单上列出的网站资源。每篇论文的黑名单包括作者自己发布的代码仓库以及任何其它在线复现的实现。
### 如何评估智能体的表现:PaperBench的评分机制
- 其实,智能体在使用资源方面没有什么限制,比如运行时间和计算能力。但建议研究者在结果中清楚地说明他们的具体设置。
- 开发者要给智能体提供必需的在线服务 API 密钥,比如下载数据集时用到的 HuggingFace 凭证。不过,要注意,获取这些在线账户的访问权限并不在 PaperBench 评估的技能范围内。
评分标准
为每篇论文制定评分标准可是 PaperBench 开发过程中最耗时的环节。每个标准都是 OpenAI 和论文原作者共同编写的,过程从阅读论文、初步构建到审查和最终确认,都要花上好几周的时间。
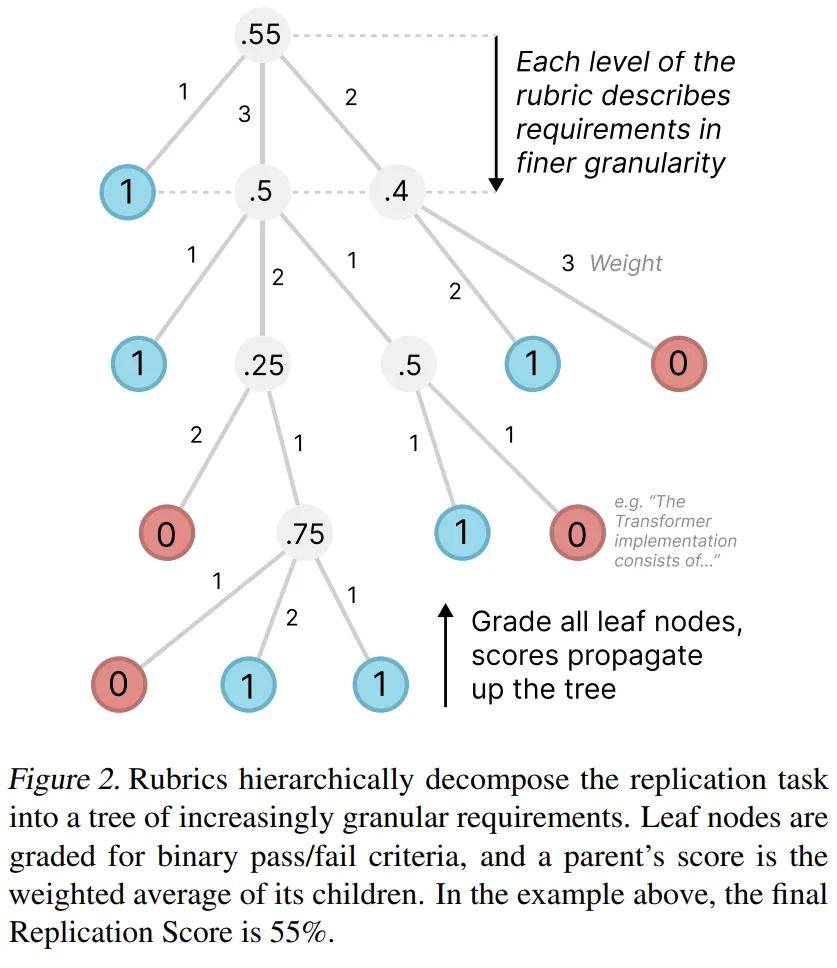
评分标准的结构像一棵树,树根是复现论文所需的主要目标。比如,根节点可能是“论文的核心贡献得到了复现”。接下来的节点会逐步细分出每个核心贡献的具体内容,例如“已经在数据集上使用 B.1 节中的超参数微调 gpt2-xl”。
要注意的是,若所有子节点都满足,那么其父节点也就满足了。因此,只需对树的叶节点进行打分,就能全面评估整体的成功率。
叶节点的要求是非常具体且严格的。有了这些详细的要求,评委们就能对部分尝试进行评分,打分也变得更简单。作者会不断细化这些节点,直到要求足够详细,让熟悉论文的专家在15分钟内就能审核提交的内容是否合格。在 PaperBench 的20篇论文中,总共有8316个叶节点。表2则展示了每个评分标准中的节点总数。
每个评分标准的节点都有权重,这个权重表示该贡献在同类节点中的重要性,而不仅仅是实施的难易程度。加权的节点让我们在复现时能够优先关注论文里更为重要的部分。
用大模型判断
在初步实验中,OpenAI 发现手动评分每篇论文得花费数十小时,所以对 PaperBench 来说,采用自动化评估方式是必须的。
为了能够大规模评估 PaperBench 提交的内容,作者开发了一个简单的基于 LLM 的评判器,叫做 SimpleJudge,然后又创建了辅助评估工具 JudgeEval 来测试评判器的表现。
这个 AI 评委被称为“SimpleJudge”,它会独立对提交内容的每个叶节点进行评分。对于每个特定的叶节点,评委会接收到论文的 Markdown 文档、完整的评分标准 JSON、叶节点的要求和提交的内容。
PaperBench 使用的是 OpenAI 的 o3-mini 模型来作为评委的后端,评估单个提交的成本大约在66美元(OpenAI API 积分)。而对于 PaperBench Code-Dev,这个成本可以降到每篇论文大约10美元。
测试结果
看看大模型的表现如何,Claude 3.5 Sonnet 领先一步
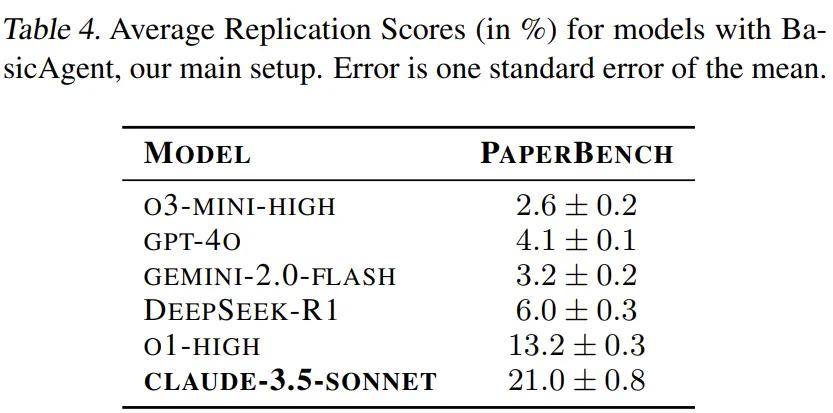
OpenAI 最近对20篇论文进行了评估,测试了几个大模型,比如 GPT-4o、o1、o3-mini、DeepSeek-R1、Claude 3.5 Sonnet(新版本)和 Gemini 2.0 Flash。每篇论文都被评估了三次,结果还挺有意思的。
在这次评估中,表4显示了各个模型的平均复现分数。你可能会惊讶地发现,Claude 3.5 Sonnet 的表现还不错,得到了21.0%的得分。相比之下,OpenAI的o1就显得有点逊色了,得分只有13.2%。其他模型的表现更是糟糕,得分都在10%以下。
翻看智能体的工作记录,发现除了 Claude 3.5 Sonnet,其他模型经常会提前结束。它们自称已经完成了任务,或者遇到了解决不了的问题。可见,所有智能体都没能在规定时间内找到最佳的复现策略。尤其是 o3-mini,在使用工具时屡屡碰壁。
这些现象显示出当前模型在处理长期任务时的短板。尽管它们在制定和撰写复杂计划方面表现得很好,但实际上却没有有效地采取一系列行动来实现这些计划。


OpenAI 认为,PaperBench 基准测试将推动未来大模型的能力进一步提升。
想了解更多信息,可以参考这里的内容:
https://openai.com/index/paperbench/






AI在科研领域的进展真让人惊叹,尤其是能自主撰写论文,这将极大促进科研效率。期待看到更多AI在复现研究中的应用!
AI Scientist-v2成功通过评审的确是个重要里程碑,未来AI在科研中的角色会更加突出,让人充满期待。
PaperBench的发布让我对AI在科研复现方面的潜力充满期待,尤其是其评估标准的严谨性,能有效推动领域发展。
Claude能够在复现基准中夺冠,证明了大模型在科研中的巨大潜力,期待未来更多创新!
PaperBench的推出无疑是AI研究中的一大进步,能有效评估复现能力,期待看到AI在科研领域发挥更大作用!
AI在科研领域的突破真是令人振奋,PaperBench的评估方法也很严谨,期待未来AI能帮助更多科研工作者!
PaperBench为AI的研究复现提供了很好的评估标准,未来期待AI能在科研中发挥更大的作用,推动更多创新。
Claude能够在复现测试中获胜,显示出大模型在科研中的强大实力。希望未来能看到更多这样的突破。
PaperBench的评估机制真是个好主意,可以帮助AI更好地参与科学研究,期待它带来的更多创新!