GPT‑5.2的推出意味着人工智能在专业交付能力上迈出了重要一步。这一次,它通过GDPval、SWE‑Bench等关键指标,重新设定了评估专业工作的标准——关注的是交付的成果,而不是知识的多少。LinkedIn正在推动的“全栈构建者”模式与GPT‑5.2的进步不谋而合,正在改变产品经理的工作方式以及团队结构。接下来,我们将深入探讨这一“从构思到上市”的变革。

发布的GPT‑5.2不是简单的“跑分秀”,而是一次对专业知识运用的重大转变。它通过GDPval、SWE‑Bench等硬指标再次强调,评估AI的标准应从“知道什么”转向“能交付什么”。LinkedIn的首席产品官Tomer Cohen在Lenny的播客中提到,打破传统的PM→设计→工程的链条,是与GPT‑5.2能力升级相呼应的。这一切的关键在于,你是否能利用AI把创意转化为实际可交付的成果。
一、发布背景:从“红色警报”到职业工具
在与Gemini 3的竞争中,OpenAI拉响了“红色警报”,将资源重新聚焦于ChatGPT,并推出了三款GPT‑5.2版本:Instant(用于日常高效)、Thinking(处理复杂任务)、Pro(应对高难度问题)。官方的定位很明确——“当前最强大的专业知识模型系列”。这次升级围绕“职场可交付”的主题展开,包括制作表格、撰写PPT、编写代码、分析图像、阅读长文献、调用工具,以及完成复杂项目的全过程。
二、能力与数据:用“经济价值”来量尺
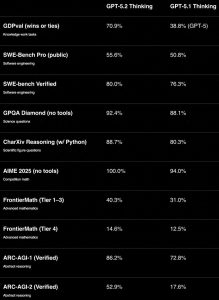
- GDPval:在对美国GDP前9个行业、44个职业和1320个真实任务的盲评中,GPT‑5.2 Thinking在70.9%的项目中表现优于或持平于行业专家;而Pro的胜率更高,达到了74.1%。评审只需回答“哪一份更愿意交给客户”,这直接反映了“结果”的质量。
- SWE‑Bench:在更加严格的跨语言Pro基准测试中,GPT‑5.2 Thinking得分为55.6%;在SWE‑bench Verified中则达到了80%。这表明它在生产环境下调试代码、实现功能和进行重构时的稳定性更强。
- 长上下文与多模态:在MRCR的4-needle变体(最高可达256k token)测试中,GPT‑5.2 Thinking的准确率接近100%;在Tau2-bench Telecom测试中获得98.7%的成绩,展现了在长时间、多轮任务中稳定的工具调用和执行能力。
- 推理与科研:在GPQA Diamond(研究生级别)的测试中,Pro的得分为93.2%,Thinking则为92.4%;在验证版ARC‑AGI‑1中,Pro首次突破90%;而在更具挑战的ARC‑AGI‑2中,Thinking得分为52.9%,Pro为54.2%,显示了在抽象和流动性推理上的进步。
- 可靠性与速度:与GPT‑5.1相比,Thinking的幻觉现象减少了约30%;不过,在复杂任务中深度推理的速度相对较慢,这是一种“质量与延迟”的权衡。
当“能交付”这一标准通过上述指标被量化后,如果组织架构还是围绕“沟通与协调”而非“构建与决策”,那么能力红利就会被流程中的混乱所吞噬。接下来,我们不再讨论模型本身,而是要回答一个更重要的问题:为了实现这份能力,组织和角色应该如何变化。
三、组织范式:从能力到结构的必然迁移(LinkedIn “Full Stack Builder”)
如前所述,能力的提升如果不落实到流程和职责上,最终只会停留在工具层面,难以实现“从构思到上市”的完整交付。LinkedIn的做法提供了一个经过实践验证的模板:以AI为核心,将整个流程交给同一个人,减少中间环节导致的混乱。
LinkedIn的首席产品官Tomer Cohen在Lenny的播客中直言,传统的“PM→设计→工程”流程如今已经不再适用。随着组织规模的扩大,职能孤岛和碎片化的协作让创新变得非常缓慢。LinkedIn的解决方案是取消助理产品经理(APM)项目,改为“Associate Full Stack Builder”,通过AI实现同一人将“构思到上市”的全程推进;用户研究员(UXR)借助AI转型为增长型产品经理;设计师不再仅仅是画图,而是直接在代码库中构建结果。随着代码生成和原型搭建门槛的降低,任何不直接产生成果(如代码或产品)的流程都只是增加了不必要的混乱。
四、产品经理的工作流升级:PRD → Live Prototype
沟通语言的变化:过去我们通过文档来沟通需求;而现在,我们用代码和实时原型来进行交流。对齐需求的最快方式,就是能运行、可展示并可调整的“活体原型”,而不是一份“完美的PRD”。
能力矩阵的调整:
- Context Engineering:将业务上下文精准注入到模型和工具链中,构建可复用的“上下文工程”资产(数据字典、场景指令、校验清单、审计留痕)。
- Vibe Coding:将交互氛围、视觉语言与工程约束整合在代码层面表达,而不仅仅停留在绘图和评审。
- Builder 路径:以“能从需求到交付”的个人为单位设计流程与责任,产品经理需要掌握能够直接产生结果的最小技术栈。
版本选型的经验法则:
- 需求澄清、资料汇总、轻量写作:用Instant来加速。
- 长文档分析、数据管道、复杂原型:用Thinking来保持质量。
- 高风险决策、科研级推理:用Pro来增强可靠性,允许更长的延迟。
五、三个典型场景:把“结果”变成默认
- 销售/运营方案到交付级PPT:使用Thinking在44类职业任务的框架下,从简报出发,自动生成结构、图表和讲故事的逻辑,然后通过人机协作进行校准;盲评的标准是“你更愿意交给客户哪一份”,与GDPval的评审口径一致。
- 电子表格与分析模型:在内部基准测试中,GPT‑5.2 Thinking的单任务平均得分较5.1提升了9.3%(从59.1%升至68.4%),在复杂度和规范性上表现更佳;产品经理可以将数据清洗和建模从“被动协调”转变为“主动构建+可审计”。
- 前端与交互原型:早期测试表明,5.2在复杂或非标准界面、包含3D元素的场景中稳定性更高;从文本需求到可操作的单页应用,参数可调、动画流畅、UI风格一致。这使得“评审”可以直接在可运行的界面中进行,从而缩短了多轮沟通的成本。
六、成本与部署:把“可控”纳入设计
- 定价与折扣:API端的定价为每百万输入token $1.75,每百万输出token $14,缓存输入内容可享受90%的折扣。结合上下文缓存和模板化的上下文工程,能够显著降低长期成本。
- 生命周期与推送:对于付费用户来说,ChatGPT 5.2 会优先推送,而5.1版则会继续保留三个月。企业在升级过程中,最好是双轨并行:旧流程继续可用,同时要把新流程的成果纳入审核。
- 速度权衡:在处理复杂任务时,Thinking和Pro的延迟会更高。为了避免等待影响协作,建议使用“异步任务池+交付节点承诺”的方式。
- 幻觉与核查:虽然错误率降低了30%左右,但对于关键事务,还是得坚持“双人(AI+人类)复核+可追溯的产物”,确保数据来源、推理过程和版本记录都能追溯。
- 合规与隐私:在处理包含个人信息、客户机密和受监管领域的内容时,需要在上下文工程中加入权限管理、数据脱敏和审计等系统化的控制。
- 组织承诺:Builder模式并不是“一个人做十个人的工作”,而是“一个人负责整个过程的权责与交付范围”。如果没有组织的明确承诺,个人再怎么高效也只能沦为无边界的忙碌。
生命周期与推送:既要新鲜又要稳妥
七、风险与边界:用“可验证性”来保障质量
八、结语:从“需不需要 PM”到“PM 是否能交付”
现在行内最懂行的人已经不再争论“需不需要 PM”这个问题,而是在Cursor里和AI一起重新定义交付流程。GPT-5.2通过GDPval等硬指标,把“专业工作可交付”这一点变得更有量化依据;LinkedIn的全栈构建者变革则让组织与角色齐心协力,共同朝着目标前进。对于产品经理来说,竞争力不再只是写出完美的PRD,而在于能否在Instant、Thinking和Pro的协作中,亲自将从构思到上市的每一步都变成可验证的成果。
本文由 @徐浩楠 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议







GPT-5.2的进步真是颠覆了传统的工作模式,特别是在产品经理的角色重构上,交付成果的重视让人耳目一新。
GPT-5.2的升级真是让人期待,特别是它在提高交付质量上的表现,能否真正改变产品经理的工作方式,值得观察。
GPT-5.2的推出确实让产品经理的工作更加聚焦于实际成果,而不是单纯的知识积累,这种转变很有意义。期待看到它在实际项目中的应用效果。
GPT-5.2的评测标准变化真是值得关注,它强调了交付成果的重要性,可能会引领更多产品经理重视实际效果而非单纯的理论知识。