四款主流 Agent 工具的深度比较:你选对了吗?
(
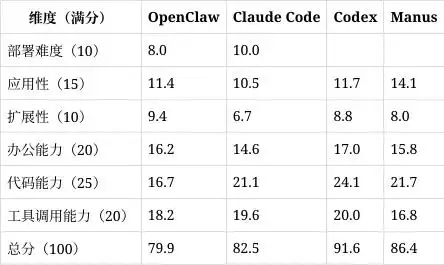
这篇文章是基于至顶AI实验室的真实工作流程进行的测试,专门对 Codex、Manus、Claude Code 和 OpenClaw(大家常叫它“龙虾”)这四款热门 Agent 工具进行了全面的对比。我们从部署难度、应用性、扩展性、办公能力、代码能力和工具调用能力六个方面来看它们的表现。

总的来说,Codex 以91.6分荣登榜首,接下来的顺序是 Manus(86.4分)、Claude Code(82.5分)和 OpenClaw(79.9分)。我们的测试内容涵盖了PPT生成、前后端代码开发和论文解读等三个真实的长流程任务。这些信息特别适合个人开发者、企业的IT决策人士以及普通办公用户在选择 Agent 工具时参考哦。
测试
Agent 工具:Codex、Claude Code、OpenClaw、Manus
评测方法:六个维度与真实工作流程任务的结合
在这次评测中,我们没有只做单一的能力测试,比如“写一个函数”或“画一张图”,而是设计了多步骤、真实场景的工作任务。评测体系由六个维度构成,总分为100分:部署难度占10分,应用性15分,扩展性10分,办公能力20分,代码能力25分,工具调用能力20分。前三个是基础体验,后面三个则是核心能力。
为了确保测试的公平性,Claude Code、OpenClaw 和 Manus 三款产品都连接了 Claude 4.6 模型,只有 Codex 因为不支持第三方模型,所以使用了自家的 GPT-5.5。由于 OpenClaw 和 Claude Code 都是基于 Claude 4.6 的,因此核心能力的差异主要体现在产品的工程层面,比如提示词设计、工具链管理等,而不是底层模型本身的差异。这一点对于后续的代码能力和工具调用能力的比较很重要。不过,关于办公能力的比较,Codex(GPT-5.5)和其他三款(Claude 4.6)之间的差异则混合了模型和工程的因素,得特别注意哦。
部署难度:图形化客户端满分10分,CLI部署的OpenClaw得8分
在部署难度这一项(占总分的10%)上,Claude Code、Codex 和 Manus 都获得了满分,三者的安装流程几乎完全一致:从官网下载安装客户端,安装并登录后就可以直接使用,整个过程和安装普通的软件没有太大差别。反观 OpenClaw,最后得分只有8分,主要是因为它需要预先配置 Node.JS、NPM 等环境,虽然官方提供了一键安装的脚本,但还是得通过命令行来执行。安装结束后,还要进行模型接入、工具配置等一系列命令行交互。
这个结论主要是针对普通用户的开箱体验来说的。但要提一下,OpenClaw 的命令行部署在私有化和企业内网场景中其实更有优势,因为它支持自定义模型接入和本地化配置,这也是它在扩展性方面表现突出的原因。简单来说,部署难度低并不意味着应用性差,这个结论的适用范围需要注意。
应用性与扩展性:Manus易用性胜出,开源OpenClaw扩展性强劲
在应用性(15分)和扩展性(10分)这两个维度上,涉及的主观判断较多。为了避免评分上的分歧,我们采用了豆包2专家模式进行联网检索独立打分。应用性考量了安装的便捷性、前置依赖数量、交互方式的丰富程度和中文支持等四项指标,最终得分为:Manus 14.1分,Codex 11.7分,OpenClaw 11.4分,Claude Code 10.5分。Manus 的得分比排名最低的 Claude Code 高出了约34%,这和它的纯SaaS形态有直接关系——免安装、免配置,注册后就能用的产品形态在易用性上自然占优势。
而在扩展性方面,OpenClaw 以9.4分遥遥领先,Codex 8.8分,Manus 8分,Claude Code 6.7分排在最后。OpenClaw 的扩展性得分比 Claude Code 高出约40%,主要因为它开源的特性,带来了更多模型接入和多样化的部署方式。这一结论适合关注生态扩展能力的开发者和企业用户,但对于只追求“打开就能用”的普通办公用户来说,扩展性的重要性就相对较低了。
办公能力实测:Codex 3分钟完成PPT夺得17分,Claude Code因文字重叠得分偏低
办公能力的测试(满分20分)选用了一个真实的七步骤营销场景任务:要求 Agent 检索并补全客户产品信息、提炼核心卖点、结合企业历史营销案例与内部资源,最终生成一份可直接使用的市场推广PPT,并进行自我验收。这个任务主要考察联网检索、文件处理、代码执行、信息整合推理和格式遵循能力。
四款应用都完成了任务,但在效率和质量上差异明显。用时上,Codex 仅用3分钟,Claude Code 6分钟,OpenClaw 8分钟,Manus 用时最长,共12分钟。成本方面,Codex 花费0.22元,Claude Code 0.4元,OpenClaw 6.4元,Manus 的花费更是高达27.3元,是 Codex 的124倍。从质量来看,Manus 的排版最好、资料最丰富且逻辑清晰;OpenClaw 也表现得不错;Codex 轻微出现排版问题;而 Claude Code 则有些页面出现了严重的文字重叠。综合时间、成本和质量,最终得分为:Codex 17分排名第一,OpenClaw 16.2分,Manus 15.8分,Claude Code 14.6分垫底。
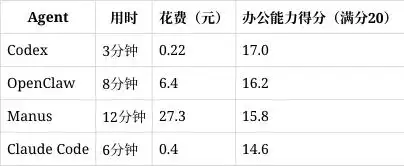
这个结论主要适用于以PPT生成和营销文案为主的小型办公场景。值得注意的是,Claude Code 得分低主要是因为这次PPT渲染中的排版问题,而不是它的信息整合或检索能力不足,这也是我们结论的一个局限。
代码能力实测:Codex两轮任务合计24.1分高居榜首,OpenClaw后端接口注册失败影响成绩
代码能力(满分25分)的测试分为前端制作和后端开发两个任务。前端任务要求基于一段产品文字内容,经过四个阶段(需求理解、框架规划、主题页面设计和最终制作)构建一个完整的网站,并模拟真实的交付节奏,用户可以随时修改需求,主要考核指令遵循度、技术判断力和设计的差异化能力。四款应用都交付了可使用的网站,用时和花费分别为:Codex 9分钟/0.49元,Manus 12分钟/15.2元,OpenClaw 14分钟/8.9元,Claude Code 15分钟/0.8元。前端单项得分为Codex 11.8分、Manus 10.3分、OpenClaw 10.1分、Claude Code 9.2分。
后端任务要求从零构建一个具备用户认证和文章管理功能的RESTful API服务,这属于中等难度的工程任务,主要考核工程完整性、代码生成精度、版本兼容意识和执行细节的把控。我们通过curl实际验证了各个应用生成的API端口,结果显示 OpenClaw 出现了注册接口失败的情况,其他三款均通过验证。用时和花费方面:Claude Code 2分钟/0.18元,Codex 和 OpenClaw 均为3分钟,Manus 用时最长为10分钟/13.8元。
谁才是AI助手中的佼佼者?
经过两轮任务的比拼,这四款代码助手的最终表现如下:Codex得到了24.1分,紧随其后的是Manus,得分21.7分,Claude Code稍逊一筹,得21.1分,而OpenClaw则以16.7分垫底。Codex的得分比最后的OpenClaw高出大约44%,而这一差距很大程度上是由于OpenClaw在后端的接口出现了问题。这个结果能帮助我们评估这些工具在标准化工作中的可靠性,不过要注意的是,OpenClaw和Claude Code其实都基于Claude 4.6模型,因此它们之间的分数差异更反映了产品设计上的不同,比如自我检查和纠错机制,而不完全是代码生成能力的差异,这一点在解读结果时需要留意。
工具使用能力测试:Codex在论文解读任务中拿到满分20分,Manus的用时是Codex的2.7倍
我们在工具使用能力的测试中,满分为20分,主要是进行一个分两阶段的人机交互论文解读任务:Agent首先在Hugging Face上找到当天热度最高的三篇论文,并提供推荐理由,然后用户选择其中一篇,再深入抓取完整论文进行解析。最后,通过特定的提示词生成适合公众号的深度解读文章,并输出为Word文档,同时还要自动从论文的PDF中截取插图插入文档。这项任务流程较长,涉及到网络抓取、PDF处理、内容生成和文档排版等多种工具调用,算是一场综合能力的压力测试。
四款应用在完成任务时都表现得不错,尤其是在图片截取和插入的准确度上都挺高。从效率和成本来看,Codex用时7分钟,花费0.4元;Claude Code用时9分钟,花费0.4元;OpenClaw则用了8分钟,费用为15.4元;而Manus则是耗时最长,达到19分钟,花费31.3元,时间是Codex的2.7倍,费用是Codex的约78倍。最终得分方面,Codex以20分(满分)拔得头筹,Claude Code得了19.6分,OpenClaw则是18.2分,Manus以16.8分排在最后。这轮测试中,Claude Code和Codex的表现明显优于Manus和OpenClaw。
这个结果适合于那些涉及到网络抓取、文档生成等综合工具链调用的研究工作。不过需要说明的是,Manus这次的低分主要是由于用时和成本的问题,而不是任务完成质量的明显不足。因此,如果仅仅以“完成质量”作为评判标准,那么这种排序的参考价值会降低。
综合得分与成本效益对比:Codex以91.6分高居榜首,四款产品的总花费差距超过70倍
将六个维度的得分汇总后,我们得到了四款Agent工具的总分排名:Codex 91.6分,Manus 86.4分,Claude Code 82.5分,OpenClaw 79.9分。Codex的总分比最后的OpenClaw高出大约15%。
如果把四个任务(PPT、前端、后端、论文解读)的用时和花费加在一起,就能更清晰地看到成本方面的差异:Codex总用时22分钟,总花费约1.24元;Claude Code总用时32分钟,花费约1.78元;OpenClaw总用时33分钟,费用为34.8元;而Manus则是总用时53分钟,花费高达87.6元。换句话说,Manus完成这四项任务的总费用是Codex的70倍,总用时是Codex的2.4倍。这种成本差异主要源于Manus采用的是SaaS按需计费的模式,而其他三款则是基于月度订阅套餐的计费方式,虽然二者不完全可比,但对重度用户来说,这仍然是评估长期成本的一个参考。
需要注意的是,至顶AI实验室强调,分数的排名只是一种观察视角,每款Agent都有其最适合的应用场景,这一点将在后面的选型建议中详细说明。
至顶AI实验室的见解
落地阶段的判断与选型建议:开发者选择Codex或Claude Code,办公用户选择Manus,企业用户选择OpenClaw
从落地的成熟度来看,这四款产品都具备完整的真实工作流交付能力,但它们适合的用户群体和前提条件却有明显的差异。对于个人开发者,Codex和Claude Code是最优选择:两者在代码能力(Codex 24.1分、Claude Code 21.1分)和工具调用能力(Codex 20分、Claude Code 19.6分)上均表现突出,原生模型能力足够强,且单次任务的平均成本不到1元,非常适合日常高频使用的工程场景。
而对于那些不想费心配置环境,只想打开即用的普通办公用户,像Manus这样的SaaS化工具体验会更好,它的应用性得分14.1分位列第一,几乎没有前置依赖,但代价是单任务成本相对较高(四项任务合计约87.6元),适合任务频率较低且对成本不太敏感的轻量办公场景,不太适合需要高频调用且严格控制成本的团队。
对于有数据合规要求、需要私有化部署或者需要同时管理多个Agent实例的企业用户,OpenClaw这种开源且可自部署的方案会更具优势:它的扩展性得分为9.4分,明显领先,支持灵活的模型接入与部署方式。不过,由于其CLI部署的门槛(难度评分8分)和本次测试中暴露的后端接口稳定性问题(代码能力得分16.7分垫底),因此需要有一定技术背景的团队来实施,前置条件相对较高。
常见问题(FAQ)
Q:Codex、Manus、Claude Code和OpenClaw这四款工具中,哪个综合能力最强?
A:根据至顶AI实验室的六个维度实测,Codex以91.6分排名第一,接下来是Manus(86.4分)、Claude Code(82.5分)和OpenClaw(79.9分),Codex在代码能力和工具调用能力两个关键维度都拿下了单项第一。
Q:Manus和Claude Code哪个更适合个人开发者?
A:个人开发者更推荐选择Claude Code或Codex。这两者的代码能力得分(21.1分和24.1分)都高于Manus(21.7分,且成本较高),而且单任务的平均花费不到1元,远低于Manus四项任务合计约87.6元的费用。
Q:企业用户该如何选择Agent工具进行私有化部署?
A:对于有数据合规或私有化部署需求的企业用户,更适合选择OpenClaw,它的扩展性得分为9.4分,明显领先,支持开源、自部署和灵活的模型接入方式,但需要配备具备一定技术背景的团队来应对CLI部署过程中的复杂性和稳定性问题。



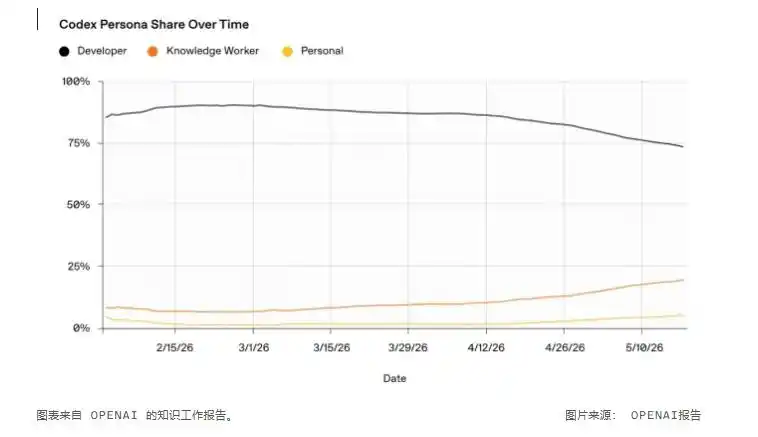



OpenClaw的部署确实有点麻烦,普通用户可能会被吓退。
测试内容设计得很合理,能真实反映工具的实际应用场景。
建议对比时可以增加用户反馈部分,这样能更直观了解工具的长期使用效果。
这四款工具的对比真是太详细了,特别有参考价值!
看到OpenClaw的部署评分不高,想起我当初用它的时候,调试环境确实耗费了不少时间。
OpenClaw的命令行部署听起来复杂,普通用户真的能上手吗?有没有一些简化的建议?
评测方法真不错,能反映工具在实际工作中的表现,不是那种纸上谈兵。
Codex的表现真让人惊喜,能做到这么高的分数,感觉值得一试。
这篇评测让我对四款工具有了清晰的认识,真的很实用。
我觉得Manus的评分也挺不错的,适合一些小团队使用,性价比高。
评测方法设计得很合理,真实工作流程的模拟让我感觉更可信。