昨晚,GLM-4.6 低调上线,我们立刻拿起 Claude 4.5 进行了一次为期 48 小时的盲测。结果真是意外:中文指令的遵循率上,GLM 超出 9.4%,而代码的首次运行成功率更是领先了 7%,在 2024 年的高考数学卷中获得了 142 分,比 Claude 高出 18 分;不过在复杂的逻辑推理和长文本记忆方面,Claude 依旧保持着“人性化”的优势。那么,究竟谁更懂中国开发者,谁又更适合投入生产?今天我们将分享 6 组实测截图和提示,帮助你一眼看出应该把算力投向谁。

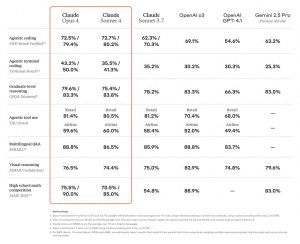
核心资讯:GLM-4.6 正式发布,排名提升,价格不变,实际效果与 Claude 4 对齐,并超越其他国产模型。GLM 的开发者包月套餐升级,价格为 1/7,效果达到 Claude 4 的 9/10,绝对值得尝试。
这个国庆节,AI 界似乎没有人能休假。
在 Deepseek-V3.2 开源之后,Claude Sonnet 4.5 也突然发力,顶尖的 AI 企业都在节前这几天拼命展示实力。
智谱也在这场竞争中发布了新型号 GLM-4.6,这也是迄今为止智谱最强大的编程模型。

两个月前,我在深入评测智谱的 GLM-4.5 时,曾强烈推荐过它。
从综合质量、成本和速度来看,当时 GLM 显然是最值得选择的国产编程模型。智谱因此在 Openrouter 上的模型调用收入,迅速超过了其他国产模型的总和。
而这次的 GLM-4.6 则带来了更多的改进:
下面这篇文章将从模型信息、实际测试效果(与 Claude 4.5、Deepseek V3.2 直接对比)、定价、以及综合结论等方面,提供一些有价值的实测参考信息。
GLM 模型:特性速览
这次智谱只发布了一款模型:
GLM-4.6,超大版本,355B-A32B。
在编程表现、上下文长度、token 效率、推理能力和 Agent 任务等多个方面都有了全面提升。
这是我总结的官方介绍图,可以帮助你快速了解新特性:

总结一下这次升级的要点:编程能力提升:在 Claude Code 的真实环境中,GLM-4.6 的实际表现超越了以往,达到与 Claude Sonnet 4 相当;上下文长度增加:从 128K 提升至 200K,支持一次性分析更复杂的项目代码(而新发布的 DeepSeek V3.2 仍保持在 128K);Tokens 消耗减少:与前一代相比,同样的任务能节省超过 30% 的 token 消耗,让工作速度更快,成本更低。
所以,真正的问题来了:
作为上个季度最强的国产编程模型,GLM-4.6 在面对 Claude Sonnet 4.5 和 DeepSeek V3.2 的密集发布时,
究竟是停滞不前,还是再次超出预期?
GLM-4.6:在真实编程场景中的横向对比
每次发布新模型,用户真正关心的其实是相对结论:1. 新模型在特定任务中,全球/国内模型排名如何?2. 和当前正在使用的模型相比,是否值得切换?
接下来是 GLM-4.6 与最新的 Claude Sonnet 4.5、GPT-5 Codex、DeepSeek V3.2,
还有上代但依然表现出色的 Gemini 2.5 Pro、Claude Sonnet 4 等的真实对比和结论。
我也选择了一些在测试中具有代表性、便于观察对比差异的案例,跟大家分享:1)经典素养测试:超长论文生成一图流
熟悉我的读者应该知道我经典的基准测试:
让模型阅读长文后,自行提炼关键内容,并生成一图流网页。
这是个经典的任务设计,考验模型的长文本处理能力、推理能力,以及前端编程的质量和设计美感。
模型进步迅速,这次我还增加了任务难度,让 AI 直接挑战论文的提炼,生成总结一图流 html。
我测试用的是 OpenAI 最近发布的论文:《人们是如何使用 ChatGPT 的》。
# AI的长文本处理能力大比拼,你更喜欢哪个?
这次的PDF文件有64页,大小是9.3 MB,内容量可真不少呢!为了测试这些模型的能力,我用的是OpenAI最近发布的论文《人们是如何使用 ChatGPT 的》,其他模型则都是通过Cherry Studio调用API来进行的。
这次的测试结果有两组对比,分别是新模型跟老模型的比拼:
1)GLM-4.6和新模型的比对:DeepSeek V3.2、Claude Sonnet 4.5、GPT-5 Codex。
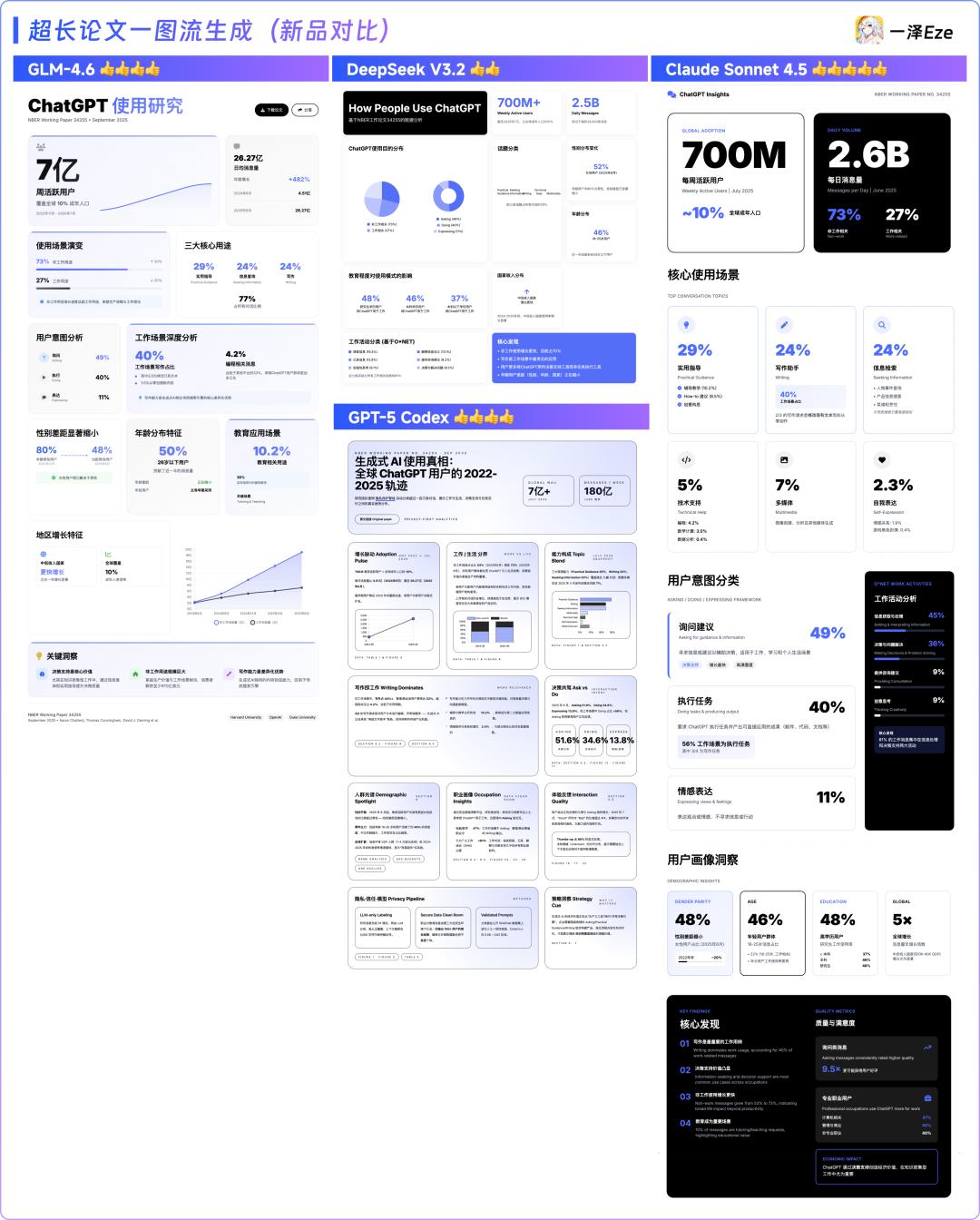
关于GLM-4.6,它的长图排版还不错,内容也挺丰富的。而DeepSeek V3.2在推理方面就有点问题,排版设计显得单一,重点不够突出。至于GPT-5 Codex,它在文字表达上比其他模型更为深入,像一份完整的报告,但排版上有些小瑕疵。而Claude Sonnet 4.5在布局和设计感上最有优势,内容详略得当,虽然有一处数据错误,但还算可以接受。综合来看,本轮排名是:Claude Sonnet 4.5 > GPT-5 Codex ≈ GLM-4.6 > DeepSeek V3.2。
2)GLM-4.6与前代的对比:GLM-4.5、Claude Sonnet 4、Gemini 2.5 Pro、Qwen3-Max。
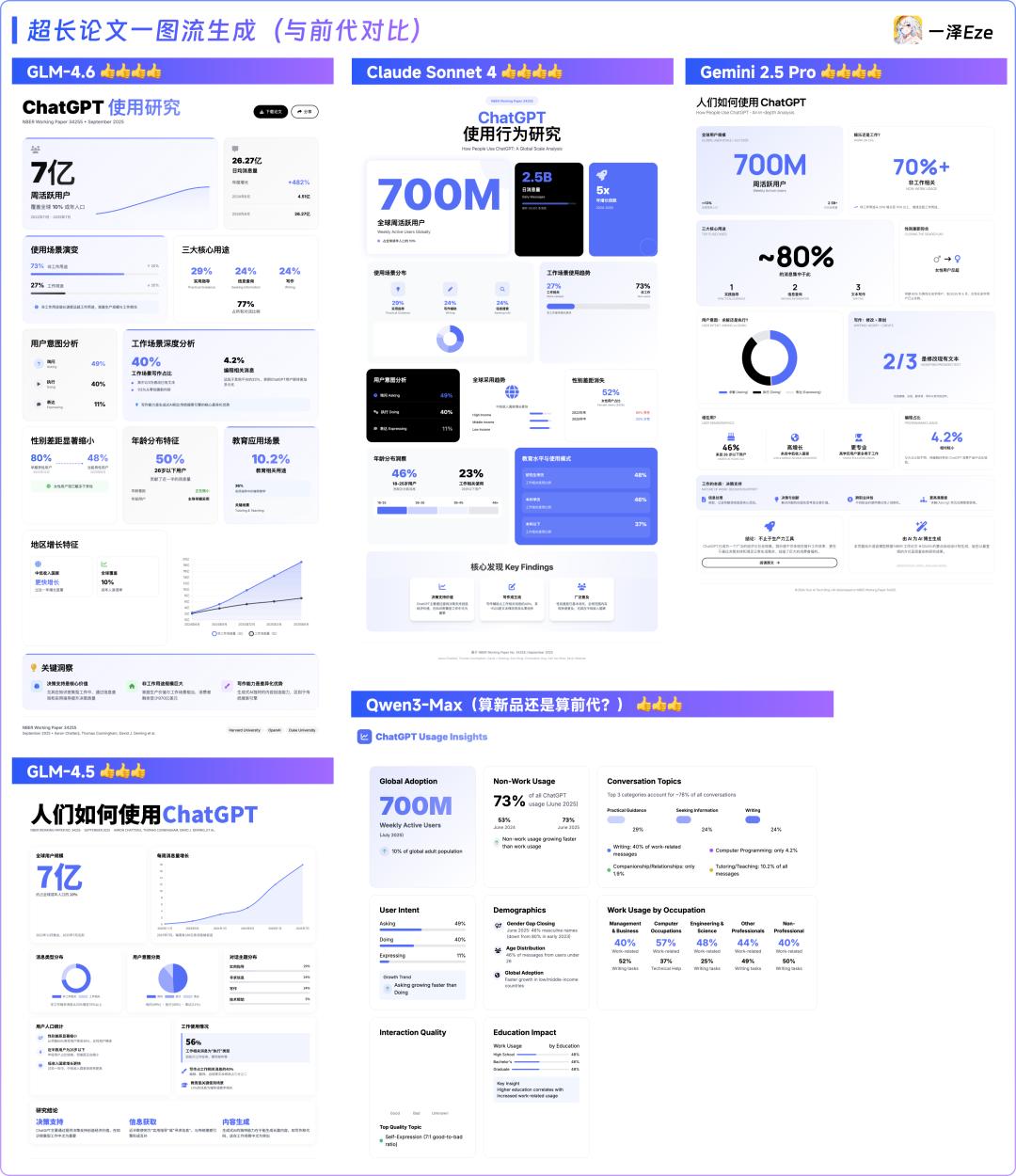
和前一代GLM-4.5相比,GLM-4.6在布局设计和推理上的理解有明显进步,几乎可以和Claude Sonnet 4平起平坐。个人感觉GLM-4.6似乎更胜一筹。Gemini 2.5 Pro则因其独特的结构化思维链,在内容提炼上有独到之处,读起来更加容易理解。不过,它在前端设计上稍显逊色。最近更新的Qwen3 Max版本内容丰富,但在语言一致性上仍有待改进,尤其是在中文提示下偏好使用英文。总的来说,与前代的对比结果为:GLM-4.6 > Gemini 2.5 Pro ≈ Claude Sonnet 4 > GLM-4.5 ≈ Qwen3-Max。
从整体来看,我们可以发现一个趋势:
在这波9月底的Coding模型中,无论是在推理能力、上下文的关注度、编程的稳定性,还是前端设计的美感,都有了显著的提升。
总结一下这次的测试:GLM-4.6虽然没能完全做到完美,但表现依然非常出色。相较于全球最新的Claude 4.5模型,GLM-4.6在设计和长文本理解上确实还有些差距。不过,它仍然巩固了国产Coding模型的顶尖水准,与之前的国产模型相比有了明显进步,甚至在某些方面与GPT-5 Codex也互有优劣。
考虑到它的性价比,在第一轮测试中,GLM-4.6在自己的价格区间内继续保持了优秀的表现。
接下来,我又提升了Coding任务的难度:
我让AI深入研究了24年的国庆节全国旅游数据,并将结果报告给了AI,要求它根据数据详情自行设计一个静态数据大屏。
任务提示如下:## 任务请为旅游行业的决策者,设计并开发一个“2024年国庆黄金周旅游数据智慧大屏”。最终成品需要在一个单页的HTML文件中包含所有代码,确保能直接在浏览器中打开运行。决策者需要通过这一块屏幕,快速、直观地了解2024年国庆假期的旅游市场全貌,把握核心亮点、发现潜在趋势。# 要求视觉: 非常专业、极度美观、一屏统览。信息: 高信息密度,关键指标一目了然,配合丰富的可视化图表。动态与交互: 数据加载时有动态效果,配合动效能够响应用户的操作。其他:不要引用外部组件,防止无法加载、显示的情况## 核心数据(以文本格式贴入 Prompt)[2024年国庆黄金周深度洞察报告], [表1:2024年国庆假期全国总体旅游数据], [表2:2024年国庆假期交通方式数据], [表3:2024年国庆假期部分省份旅游数据], [表4:2024年国庆假期文旅消费与活动数据], [表5:2024年国庆假期出入境旅游数据], [表6:2024年国庆假期游客画像数据]
这次测试的对比对象包括Claude Sonnet 4.5、GLM-4.5、Claude Sonnet 4、DeepSeek V3.2和Gemini 2.5 Pro,以及GLM-4.6。
在没有任何设计风格提示的情况下,各个模型经过一轮任务和一轮优化后,生成的前端效果如下:
### 令人惊讶的测试结果,GLM-4.6表现抢眼!
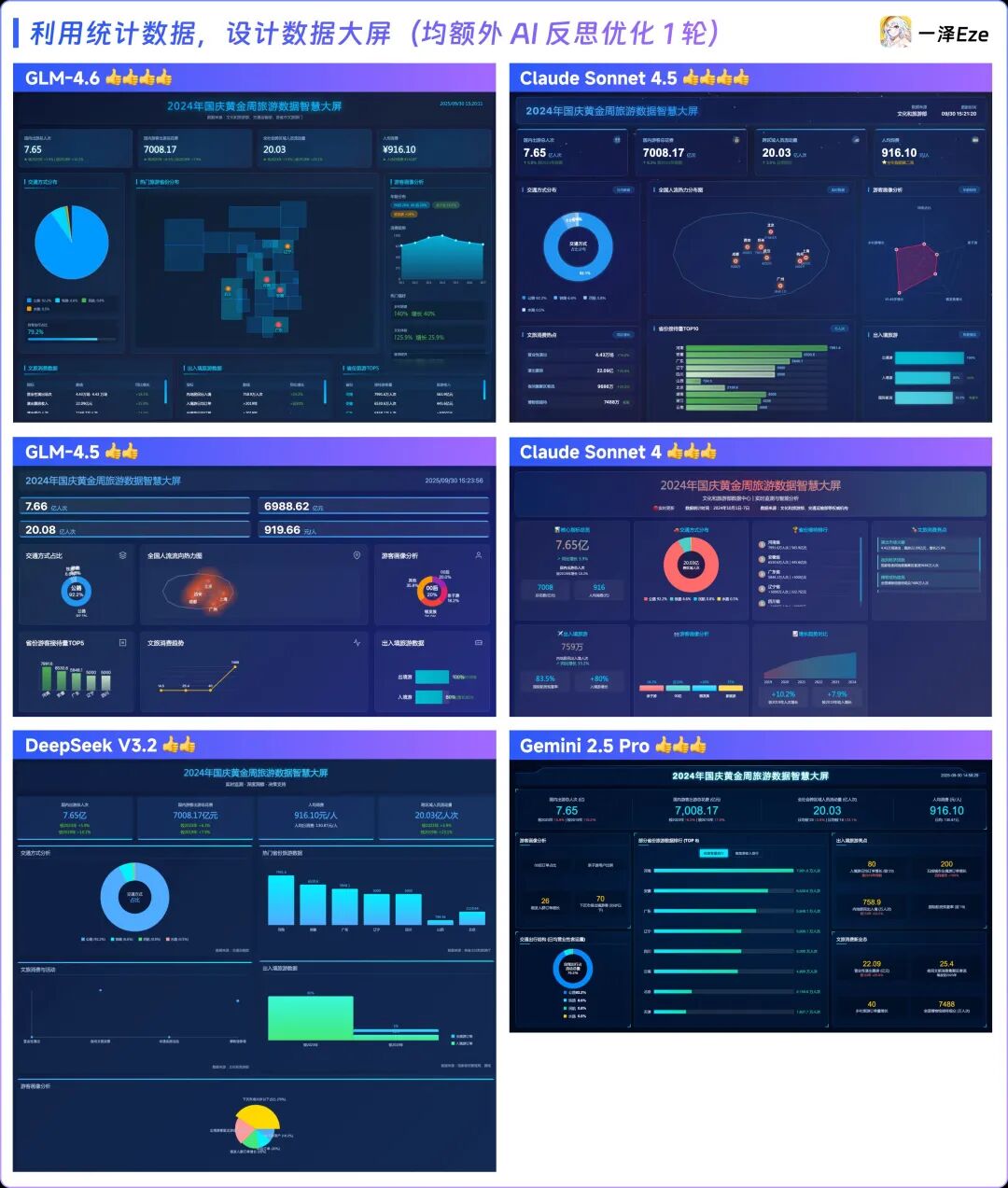
结果真是出乎意料!根据这次测试的排名,第一梯队是GLM-4.6和Claude Sonnet 4.5并列,接下来是Claude Sonnet 4和Gemini 2.5 Pro,最后是GLM-4.5和DeepSeek V3.2。
老实说,这个结果让我大吃一惊。我本以为Claude 4.5会占据优势,但GLM-4.6带来了意想不到的惊喜:在没有额外提示的情况下,它的表现完全不逊于Claude的新模型Sonnet 4.5。而且,GLM-4.6在各个方面都比DeepSeek V3.2以及Claude 4有了显著的进步。特别是数据大屏在To B软件中扮演着至关重要的角色,GLM-4.6的表现无疑为国内的To B软件行业带来了巨大的效率提升。
难怪我的朋友#赛博禅心 @大聪明最近推出的公众号排版Agent,自动排版的底模也选择了GLM-4.6呢。

一次的胜出或许是偶然,那如果是两次或三次呢?
不得不说,在结合编程与审美的Coding Agent任务中,GLM-4.6似乎找到了它的优势。
说到价格,接下来我们来聊聊更实际的内容。
Claude一向表现出色,但由于其高昂的计费(每输入token $3),还有动辄上百的套餐费用,很多开发者可能会犹豫不决,尤其是国内对Claude Code套餐的封号问题让人心有余悸。
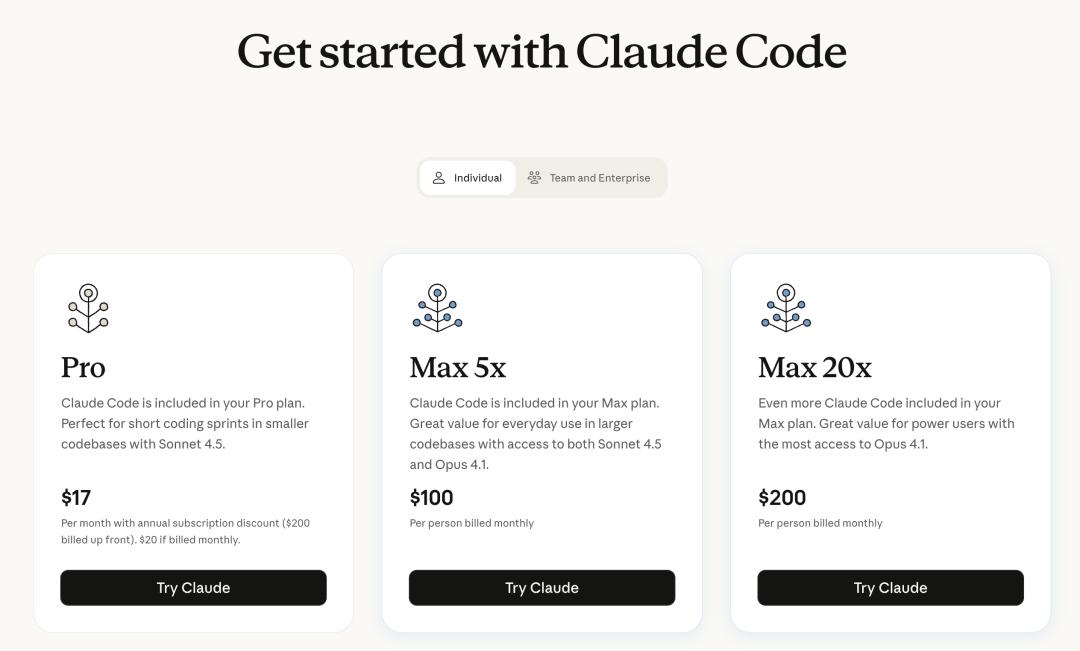
不过,GLM-4.6发布后,不仅有常规的按量付费,定价也做了更新:
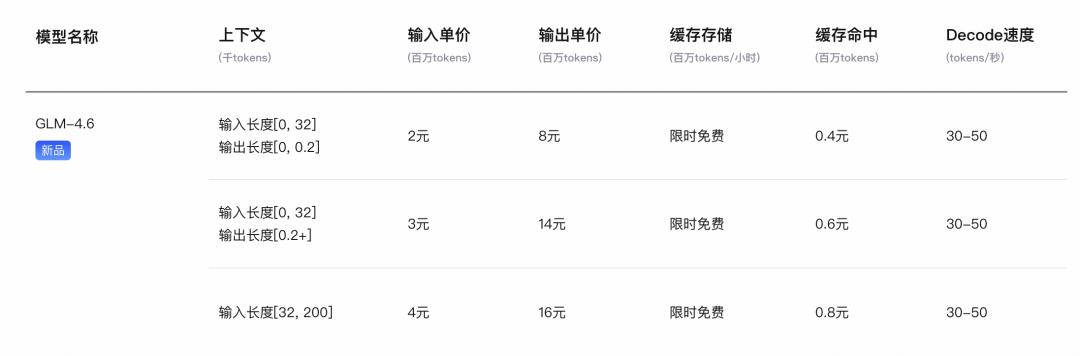
智谱也对之前推出的GLM Coding Plan套餐进行了全面升级:
大家好,今天来聊聊最近发布的GLM-4.6模型。其实呢,之前的用户自动升级到这个新版本,它的功能可真是扩展了不少哦!现在不仅增加了图像识别和搜索功能,最吸引人的是价格——每月低至20元!Lite、Pro和Max三个计划分别提供每5小时120、600和2400次的提示额度,按月合计可以使用几十亿到几百亿个tokens,算下来大概是等量API价格的十分之一,性价比真是超高。
而且,这个模型还兼容了Claude Code、Roo Code、Kilo Code、Cline等十多种编程工具,真是方便开发者们的工作。
结合之前的测试结果,大家可以把GLM-4.6当作是……只需Claude 1/7的价格,就能在真实的开发场景中,超越刚发布的DeepSeek-V3.2,甚至在某些情况下能与Claude Sonnet 4平起平坐,体验毫不逊色于Claude 4.5!哇,真是让人惊喜。
说到数据,自从GLM-4.5推出Coding Plan以来,智谱MaaS平台的API商业化增长了十倍以上,开发者们用真金白银表达了他们的选择。
那么,想试试GLM-4.6的朋友们,可以通过bigmodel.cn进行体验,海外的用户则可以通过z.ai来下载。GLM-4.6也将在Hugging Face和ModelScope上发布,购买GLM Coding Plan的话,可以直接去bigmodel.cn,个人和企业版套餐都有哦。
最后,关于GLM-4.6,我的测试到此为止。说实话,没想到在国庆节前的最后两天,居然会有这么多模型发布。(我原本是打算去放松一下的……)
一方面,DeepSeek V3.2的调用成本降低了50%,另一方面,Anthropic推出的Claude Sonnet 4.5又一次提升了AI编程的能力。
在这波9月底模型密集发布的竞争中,再看看GLM-4.6:在经典长文一图流测试中,它的整体表现稳压DeepSeek V3.2和国内其它模型,甚至与Claude 4相媲美,也在商业开发场景的数据大屏测试中,与Claude 4.5相比毫不逊色,显著优于之前的版本。
这些实测数据让结论不言而喻:结合性能和越来越实惠的GLM Coding Plan,GLM-4.6确实称得上是“国产最好用的编程模型”。
虽然GLM-4.6可能还不能在每个维度上都赶超Claude 4.5这样的“顶尖”存在,但它以极具诚意的价格,为你提供了一个在大多数场景下都“足够好用”的选择,甚至常常带来惊喜。
所以,如果你有编程和代理任务的需求,并且希望“用得爽”“用得起”,GLM-4.6绝对值得你花时间亲自试试看。我也期待听到你的使用反馈哦!
本文由人人都是产品经理的作者【一泽Eze】原创/授权发布,转载请联系作者获得许可。
题图来源于Unsplash,基于CC0协议。