【新智元导读】OpenClaw迅速崛起,标志着AI正式进入了Agent时代。一个低调的中国团队借助超快的推理能力和完美适配128G内存的196B模型,精准抓住市场痛点,成功登顶海外热榜。
2026年才刚刚开始,AI领域的风向就已经悄然变化。
火爆的OpenClaw一跃而起,将大模型从之前枯燥的「对话框」时代,带入了「自动执行中枢」的新阶段。

OpenClaw GitHub星标狂飙200k
放眼全球,OpenClaw的开源生态如火如荼,核心的Skill注册平台ClawHub已经成为开发者们的“采购天堂”。
这里汇聚了超过5000个社区贡献的丰富Agent Skills
就在最近,国内有个类似的平台「水产市场」也迅速火了起来。
上线没几天,下载量就达到了3.3k,开发者们也纷纷一键接入他们的龙虾。
这个平台的核心思路是把各种分散的GitHub工具集中展示,方便Agent随时调用。
传送门:https://openclawmp.cc/
当AI的能力越来越强,开发者的选择也变得更加简单明了:
在复杂的长程任务中,谁能速度最快、逻辑最强、和各类工具配合得最顺畅,谁就能赢得胜利。
在这个强调「实战为王」的时刻,一个低调的中国大模型团队——
阶跃星辰(StepFun),凭借新推出的Step 3.5 Flash,成功抓住了这波火热的流量红利。

全球「逮虾户」
争用中国黑马模型
由于OpenClaw需要频繁调用大模型API,OpenRouter作为全球最大的模型聚合平台,自然成为了最直接的竞争场。
在GPT等强大对手的包围中,Step 3.5 Flash异军突起,不仅顺利进入Fastest榜的第一梯队,还一度登顶Trending榜。
一个代表速度,一个代表趋势,精准对接了Agent时代开发者最看重的两个维度:快,以及越来越多的人在使用。
根据过去30天的调用量数据,Step 3.5 Flash目前稳居全球第四;自2月26日以来,单日调用量直接冲到了第三的位置。
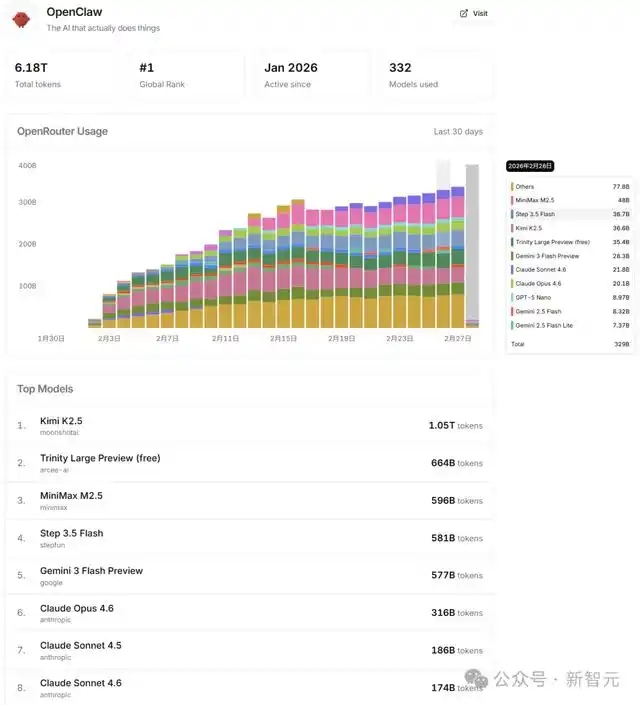
不过,更引人关注的是,这样的成绩是如何取得的。
阶跃的CTO朱亦博随后在Reddit上分享了:
Step 3.5 Flash并不在OpenClaw的首页推荐列表中,也没有与OpenClaw进行过任何官方推广合作。
换句话说,这完全是开发者自发选择的结果——用脚投票,每个token都是一票。
潜入Reddit
海外开发者「真香」现场
随着调用量的猛增,阶跃的核心团队也受邀加入了全球最严苛、最挑剔的本地大模型开源社区Reddit的 r/LocalLLaMA 板块,进行了一场长达数小时的AMA(问我任何事)。
开发者的真实声音:Step 3.5 Flash的突破与挑战

要说起r/LocalLLaMA这个社区,大家一定知道这里的用户可是全球最牛的独立开发者。
他们不在乎那些PPT和市场宣传,只看模型能否在自己电脑上流畅运行。
面对这些超级挑剔的极客,StepFun可是派出了包括CEO、CTO和首席科学家在内的明星团队,整整十一个人一起在线解答问题。
对海外极客尖锐的技术提问,甚至是对Bug的准确反馈,阶跃团队交出了一份真诚又扎实的答卷。
把这场跨洋对话和最近的榜单逆袭结合起来看,我们不仅能理解Step 3.5 Flash在海外为何突然走红的深层原因,还能看到:
在算力和生态的重重限制下,一家中国创业公司是如何开辟出一条突破之路的。
先聊聊速度。
在Chatbot时代,大模型只需要20到30 tokens/s的输出速度就行,因为用户的眼睛会盯着屏幕,根本来不及消化更快的速度。
但在Agent时代,游戏规则完全改变了。
用户使用OpenClaw这类工具进行长时间任务时,谁还会去关注模型每一个字的输出呢?大家更关心的是「你什么时候能完成任务并交付给我」。速度,从一个附加值变成了生死攸关的关键。
海外用户的反馈也证实了这一点。
在AMA中,有网友直言:「用OpenClaw真的特别好,速度快得惊人,是我见过的所有模型中最满意的一个。」

再来聊聊尺寸。
如果说速度是引燃这场AMA的火花,那么引爆高潮的则是一个看似普通的参数:约196B的MoE架构。
对于开发者来说,这个尺寸简直是「天上掉下来的馅饼」。
知名评论员ilintar兴奋地留言称:「我觉得196B MoE的参数规模简直完美——它不仅支持高质量的4-bit量化,合理的上下文长度也刚好能放进128 GB内存里。」

这个「卡点」并不是偶然的。朱亦博在AMA中坦言:
我们的目标就是让它能够在128 GB内存的系统上运行。为了测试模型,我自己花钱买了一台128GB内存的Macbook Pro,首席科学家也入手了一台128GB内存的AMD机器。
作为一名资深的本地模型玩家,我深知其中的痛点。
许多230B级别的模型在进行4-bit量化后,恰好超过了128GB内存的极限,迫使开发者不得不牺牲性能,使用3-bit甚至更低的量化,或忍受超慢的硬盘卸载。
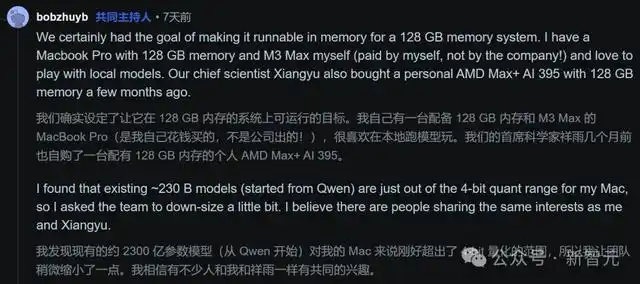
为了让开发者能够使用4-bit顺畅运行256K上下文,阶跃团队将尺寸「压制」在比235B稍小的范围内。
这不仅是技术上的精打细算,更是对开源社区真实需求的深刻理解。
难怪有用户感慨:「你们考虑到128GB的范围真是太棒了!」
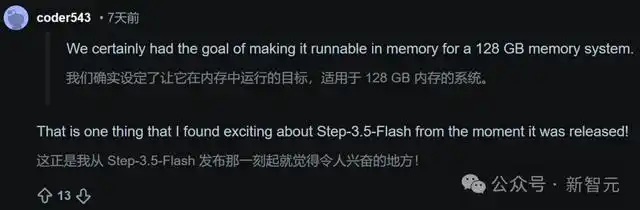
当然,反馈并不是全是好话。
有开发者直言,Step 3.5 Flash在首日发布时,工具调用在vLLM、llama.cpp等主流推理框架上完全无法使用,甚至有人直接放弃测试,转而使用竞争对手的模型。
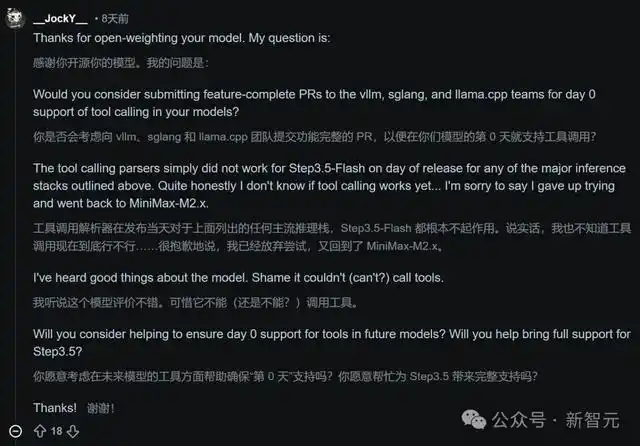
面对这种直接的批评,CTO朱亦博也亲自出来道歉:
这确实暴露了我们在发布支持工具调用的模型方面的经验不足……我们只确保了数学和编码的基准测试结果,但测试用例并没有覆盖到工具调用的实际实现。

标题:打破常规,开源社区的新思路与大模型的未来
关于用户反映的模型“无限推理循环”问题,团队并没有选择回避,而是积极面对。
他们详细说明了这个问题的根源在于缺乏多样化的推理强度训练数据,并且透露了将通过强化学习来控制推理长度的解决方案。
甚至在提到“世界知识遗忘”这样复杂的技术难题时,团队也毫不吝啬地分享了他们面临的挑战和思考:
对于规模达到200B的推理模型来说,在从预训练到推理阶段的对齐过程中,模型很容易进入一个“知识匮乏的封闭子空间”,这就导致了过高的“对齐成本”,从而影响了对世界知识的掌握。
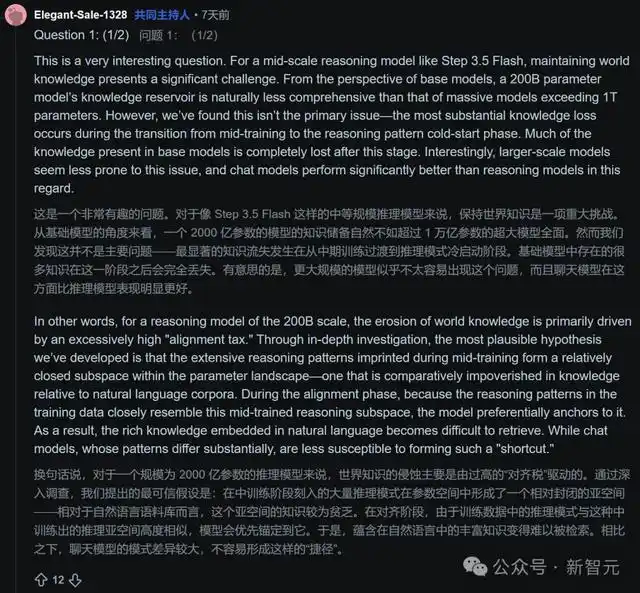
这种不仅不遮掩缺陷,反而将经历的挑战详细分享给社区的态度,赢得了极客们的极大敬意。
在开源社区,大家只在乎一件事:你是否真心在解决问题,以及你是否与开发者们并肩作战。
有用户甚至主动表示:“如果我能在下个版本之前搞定自动解析器,那你们就不用担心llama.cpp的工具调用支持了。”
这,就是开源所带来的力量。
196B参数背后的设计理念
从CTO朱亦博最近发表的一篇长文中,我们可以窥见阶跃在大模型发展方向上的战略思考。
第一个思考:大模型时代正在转变轨道。
目前,大模型的发展可以分为三个阶段:L1 对话机器人→ L2 推理器→ L3 智能体。
每个阶段所需的“基础架构”也各有不同。
换句话说,强行用上一代的架构去做下一代的事情,虽然可以,但效率会很低。
对于没有像海外巨头那样强大算力的中国公司来说,低效是致命的。
第二个思考:在Agent时代,速度比参数更为关键。
与其一味追求参数的数量,不如拥有一个效率极高的模型更为重要。
这意味着,模型的推理速度现在不仅是“体验优化”的一部分,更是“核心竞争力”。
因此,Step 3.5 Flash的设计目标明确为三个关键词:强逻辑、长上下文、快。
在架构上,它采用高效的稀疏MoE,并选择了最适合投机采样的SWA结构;在端侧部署中,团队坚持使用8个Group,以适应8卡并行推理的硬件。
这种从一开始就将“智能密度”和“推理速度”作为双重核心指标的策略,让Step 3.5 Flash在没有盲目堆砌参数的情况下,成为了完美契合Agent工作流的“性能小钢炮”。
第三个思考:拒绝孤注一掷,持续发展才是正道。
这场AMA及其背后的开发故事中,最引人深思的是阶跃星辰对“大参数模型”的重新思考。
在他们看来,训练超大规模模型很容易陷入死胡同:
训练周期极长,等到模型终于成熟,上一个智能时代已经结束,新的范式(比如长链推理)又开始盛行,结果不得不推倒重来。
这需要像巨头那样庞大的算力储备,而对于初创公司来说,这就像是一场要么成功要么破产的豪赌。
更深层的技术洞见在于:当模型尺寸达到一定程度后,逻辑能力与模型大小的关联性就不大了,逻辑能力主要依赖于后期的训练技术。
在巨头之间
开辟一条“实战派”的道路
放眼整个2026年初的大模型竞争格局,市场正在经历剧烈的重构。
前两年的竞争逻辑是,谁能取得更高的分数,谁就更接近所谓的SOTA。
未来AI竞争的新方向:从理论到实战的转变
如今,行业的重心正在发生变化:谁能够在算力有限的情况下产生实际的收益?又有谁能在模型的能力和推理的成本之间找到最佳的平衡点呢?
最近出现的Step 3.5 Flash,以及它在Reddit上引起的热议和在OpenClaw榜单上的逆袭,为我们提供了一个非常有启示性的答案。
- 如果算力上没有优势,那就把系统和算法的联合设计做到极致;
- 不必追求全能的巨型模型,而是集中解决Agent时代的关键问题,比如提升长上下文的处理效率、加快推理速度和强化逻辑训练;
- 在商业化方面,通过提供适合硬件部署的高效工具,自然而然吸引了OpenClaw带来的开发者流量。
正如团队在AMA中提到的:“训练基础模型既是科学也是工程,最核心的是每位团队成员都要理解设计目标。一旦目标明确,算法选择、数据处理和基础设施的决策都会自然而然地协调一致。”
这大概就是2026年AI竞争的真实写照——不是实验室里的分数游戏,而是真实工作流程中的生死时速。
当你的模型每天被全球的开发者调用数百亿个tokens时,任何华丽的PPT都不如一句“它就是能用”来得更有说服力。
至少在现在,阶跃星辰的Step 3.5 Flash已经以一种最简单的方式证明了自己的价值:
在一个外国用户用英语提问、中国工程师用英语回答的深夜Reddit帖子里,和一个个被全球开发者输入到配置文件中的模型名称里。
不需要翻译,代码就是最直接的语言。












建议关注OpenClaw的后续发展,尤其是技术迭代方面。
很喜欢OpenClaw的自动执行中枢理念,这样能大幅提升工作效率,真是个好主意!
Step 3.5 Flash的表现也太优秀了,难道真的是因为开发者的选择影响了排名吗?
OpenClaw和Step 3.5 Flash的竞争会不会促使整个行业的发展?
建议多关注社区的反馈,了解开发者对这两个平台的真实看法。
OpenClaw的崛起真是让人惊喜,没想到中国团队能做到这么好!
OpenClaw崛起的背后,真的值得我们思考国内团队的潜力,未来可期!
这么强的技术,为什么没有更多的宣传呢?开发者真的这么自发选择吗?
对于普通开发者来说,如何选择合适的工具来提升效率呢?
OpenClaw和Step 3.5 Flash的崛起,能否让更多开发者参与到AI应用中来?
建议开发者多参与社区交流,分享使用经验,这样能更快上手。
在这个快速发展的AI时代,OpenClaw的成功让我想到了早期的TensorFlow,是否会有更多类似平台涌现?
在AI逐渐普及的今天,如何才能更好地平衡技术与市场需求?