本月更新汇总
- Gemini:新推出了生图模型Gemini 2.5 Flash Image;
- 通义千问:新增了代码平台Qoder和生图模型Qwen-Image。
- 字节Seed:发布了开源推理模型Seed-OSS;
- DeepSeek:更新了混合推理模型DeepSeek-V3.1;
- 智谱AI:推出了多模态混合推理模型GLM-4.5V;
- OpenAI:发布了更新版混合推理模型GPT-5和开源推理模型gpt-oss;
- Anthropic:更新了混合推理模型Opus 4.1;
OpenAI
- GPT-5
2025年8月7日,OpenAI正式推出了新一代旗舰模型GPT-5。这个模型可不是单纯的“智力”飞跃,而是经过深度工程优化,专注于“现实世界”的应用,反映了OpenAI从追求AGI的艺术性转向打造高效的企业级工具的战略变化。GPT-5通过统一架构,把之前的GPT数字系列(像GPT-4o)和OpenAI o系列推理模型(如o3)整合在一起,实现了文本、图像、音频和视频的全方位多模态输入输出能力。
它推出了两个主要版本:gpt-5-main作为通用主模型,gpt-5-thinking则专注于增强推理能力。根据官方的数据,gpt-5-main的事实错误率比前代GPT-4o减少了44%,而gpt-5-thinking在与o3的比较中,事实错误率竟然下降了78%。在效率方面,OpenAI报告称,GPT-5在视觉推理、代理编码和研究生级别的科学问题解决等功能上输出token数量比OpenAI o3减少了50%至80%,并且还进行了降价,性价比显著提升。
不过,这样的性能提升并不是没有代价的。很多长期用户和评测机构发现,GPT-5在文学表现和创造力上有所下降。诗歌变得无聊,哲学对话缺乏深度,长篇叙事也显得机械化。这意味着OpenAI为了更高的事实准确性和推理能力,牺牲了模型的艺术性和探索性。这种取舍正好反映了行业的“实用主义”趋势。
总的来说,尽管GPT-5上线后在LMSYS竞技场的排名一直保持在前三,但相比于给行业带来震撼的GPT-3和GPT-4,GPT-5似乎没有带来太多惊喜。在顶尖人才不断流失的情况下,OpenAI这位曾经的王者能否找到出路呢?

- gpt-oss
在发布旗舰模型的同一天,OpenAI也做出了一个重大的决定:8月5日,发布了其在GPT-2之后的第一个开源模型系列gpt-oss,包括20B和120B两个版本,并采用了宽松的Apache 2.0许可证。
从技术上看,gpt-oss是一个纯文本推理模型,其MoE架构和4-bit MXFP4量化技术使其能够在单张80GB或16GB GPU上高效运行。模型内置了CoT能力,开发者可以通过系统消息调节推理强度(低、中、高),在延迟和性能之间找到合适的平衡。在通用基准测试(像MMLU)中,gpt-oss-120b在性能上接近OpenAI自家的o4-mini模型,并在竞赛数学等特定领域表现优异。
这一战略举措表明OpenAI意识到,单靠闭源API可能会面临开发者流失和生态萎缩的风险。在开源模型日益增多的背景下,OpenAI需要在技术标准、开发者社区和企业级市场中,建立新的话语权和生态壁垒。通过提供一个性能优秀且可控的开源“替代方案”,OpenAI希望将自己的影响力扩展到企业私有部署和Agent应用开发等更广泛的领域。

Anthropic
- Claude Opus 4.1
8月5日,Anthropic发布了其旗舰模型Claude Opus 4的升级版Opus 4.1。此次更新主要集中在Agent任务、实际编码和推理能力的增强。
在技术和性能上,Opus 4.1在SWE-bench Verified编码基准测试中的得分提升至74.5%,在多文件代码重构和准确错误修复方面取得了显著进步。该模型也是“混合推理”模型,开发者可以通过API调节“思考预算”(thinking budgets),以在性能和成本之间找到平衡。
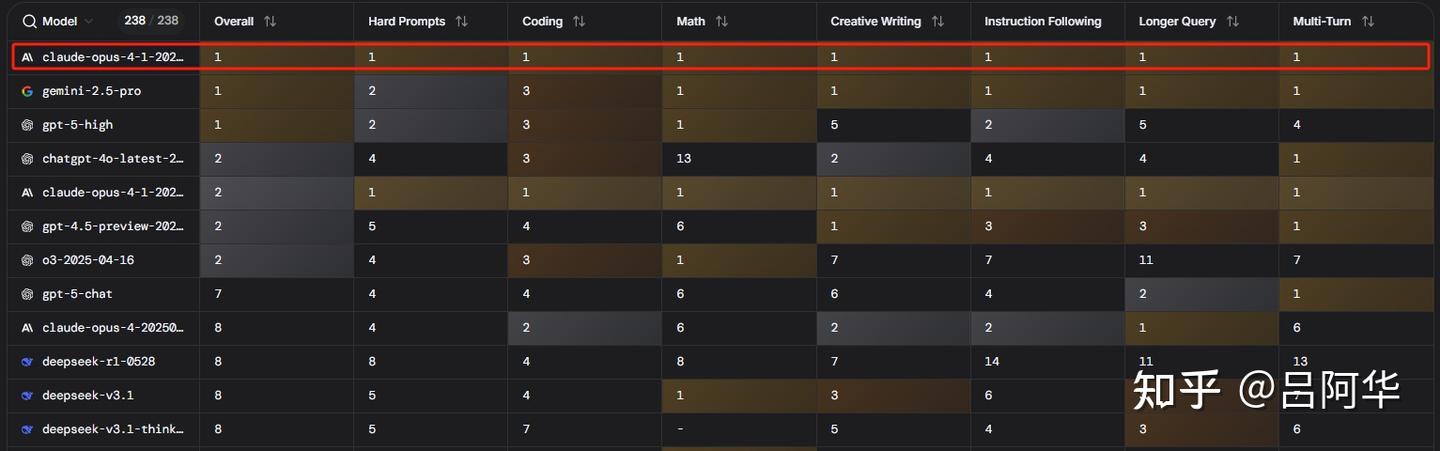
上线仅半个月,Opus 4.1便稳居LMSYS竞技场总榜首位。Anthropic的实力依然不可小觑。
智谱AI
- GLM-4.5V
8月11日,智谱AI正式发布了其开源视觉推理模型GLM-4.5V。这个模型是基于其旗舰文本基座GLM-4.5-Air构建的,采用了视觉编码器、MLP适配器和语言解码器的三部分架构,总参数量达106B,激活参数量为12B。
GLM-4.5V的技术亮点在于引入了三维旋转位置编码(3D-RoPE),显著提升了模型对空间关系的感知能力。在多模态基准测试中,该模型在41个公开榜单上刷新了同级别开源模型的记录,并在精准视觉定位、复杂文档解析、前端复刻和GUI智能体交互等任务中表现突出。
不过,GLM-4.5V在与某些工具(如aider)合作时表现不佳,这暴露了模型在通用Agent任务中的“数据覆盖范围”挑战。尽管它在多模态能力上有了突破,但面临的挑战也反映了AI从模型能力到实际Agent应用过渡阶段的共性问题。

DeepSeek
- DeepSeek-V3.1
8月21日,DeepSeek发布了V3.1版本,主要亮点是混合推理架构和更强的Agent能力。
DeepSeek-V3.1的混合推理架构允许用户通过API或网页按钮自由切换“思考模式”和“非思考模式”。这种设计使得模型在需要快速反应时可以迅速给出答案,而在需要深度推理时又能进行复杂的思维链生成,从而在响应时间和性能之间实现动态平衡。经过思维链压缩训练,V3.1-Think在输出token数量减少20%-50%的情况下,仍能保持与旧模型相当的性能,直接为开发者提供了成本优化的空间。
在Agent能力方面,新模型通过后期训练优化,在编程智能体(SWE)和搜索智能体(browsecomp, HLE)等任务中表现显著提升,部分指标大幅领先于前代模型。
DeepSeek年初时的形象是行业的先锋,如今却有些追随友商以迎合市场。
我个人觉得,DeepSeek毕竟不是Deepmind(谷歌),以它的行业积累和人才储备,最多只能当一段时间的黑马,等被全行业关注和模仿之后,能否继续保持领先地位是个大问题。
如果你关注国产大模型的发展,肯定也注意到像Kimi K2和GLM-4.5这样的最新国产旗舰模型,在技术报告中提到它们是基于DeepSeek-V3的改进而来的。另外,今年转为开源的国产旗舰模型也大多是因为在竞争中落后而加入了DeepSeek带头的开源阵营。
所以大家可以适度降低对DeepSeek这样的明星企业的期待,让它在更宽松的环境中自由发展。这样的企业也许不一定能保持行业领头羊的地位,但它对行业的贡献是其他友商无法替代的。

字节Seed
- Seed-OSS
8月21日,字节跳动的AI研究团队Seed正式开源了Seed-OSS系列模型,其最大的亮点是实现了业界领先的512K超长上下文窗口。这一突破性技术重新定义了LLM处理长文档和复杂代码库的极限,极大地拓展了AI在知识密集型和代码库级任务中的应用边界。
Seed团队的创新之路
说到Seed团队,最近他们在数据处理上搞了个大新闻,推出了一种叫“模型中心”的新方式。这个方法特别厉害,利用一个专门训练的评分模型,能自动筛选出高质量的代码数据。这个评分模型基于DeepSeek-V2-Chat,能从可读性、模块性、清晰度和可重用性四个维度来评估代码的好坏,结果是原始数据量竟然减少了约98%!而他们的指令微调模型Seed-OSS-36B-Instruct在各种基准测试中表现出色,甚至超越了不少知名模型,比如Qwen3-32B、Gemma3-27B和gpt-oss-20B。
展望2025年,字节Seed的模型能力和应用生态发展,跟OpenAI相比不遑多让。就在OpenAI开源gpt-oss模型仅过了一周半,字节Seed的Seed-OSS也顺势发布并开源了。我个人觉得,字节Seed无论在综合实力上还是在国内市场上,都是数一数二的。而且,字节还有自己的云服务火山引擎,这让他们走开源路线的理由比OpenAI更充足哦。

阿里巴巴的Qoder平台
- Qoder平台
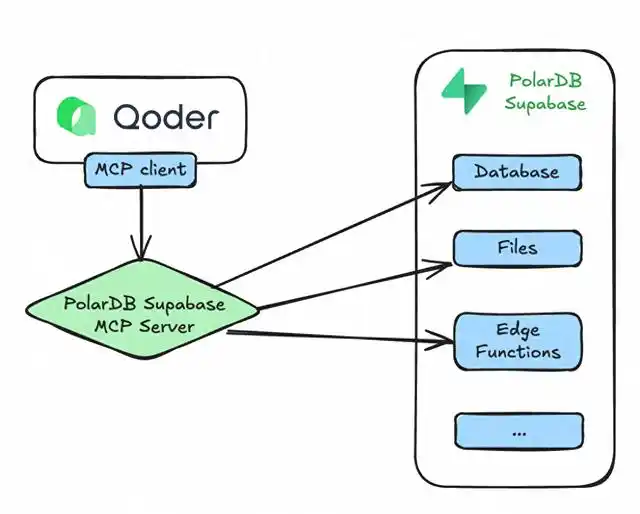
在8月22日,阿里巴巴向全球发布了新一代AI编程平台Qoder。这个平台结合了最先进的编程模型(Qwen3-Coder)和强大的上下文工程能力,核心理念是“以AI为中心的集成开发环境”。
Qoder的一个亮点是它的“Quest模式”。在这个模式下,开发者只需简单描述需求,AI Agent就能自动拆解任务,编写代码并进行测试,开发者最后只需验收或做些调整。Qoder通过“上下文工程”等技术,解决了传统编程助手记忆力差和多文件协同难的问题。

到了8月底,阿里集团发布了本财年第一季的财报,云业务增长了26%,是近三年来的最高水平;而AI产品的营收也实现了三位数的持续增长,占到了云业务的20%以上,通义大模型的全球下载量已经超过了3亿次。此外,阿里还透露未来三年将投入3800亿元用于建设AI基础设施,这个规模超过了过去十年的总和;在应用生态上,他们计划推动“全栈AI能力”,涵盖基础设施、模型、开源生态到应用(比如高德的AI化、钉钉的升级)。
总的来说,阿里的AI生态战略发展得很顺利,前景也很广阔,相信在行业中会受到长期的关注。
谷歌Deepmind的新突破
- Gemini 2.5 Flash Image
在8月26日,谷歌推出了最新的原生图像生成模型Gemini 2.5 Flash Image Preview(nano-banana),这个模型因其优秀的性价比以及在LMArena基准测试中位列AI图像编辑模型的榜首而备受瞩目。
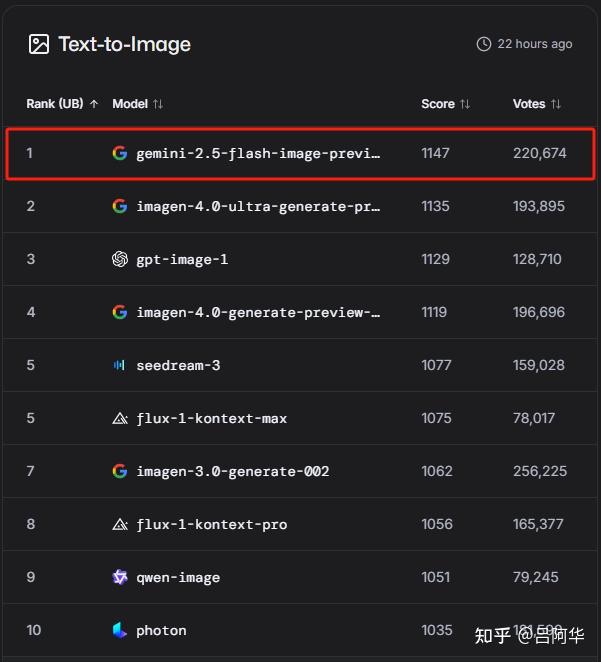
Gemini在图像生成质量上不输强大的专业生图模型Imagen,同时还吸取了不少对话模型的优点,使得图像在多轮对话中保持更好的一致性,让图像的生成与修改都更可控。

小结一下
在这个八月,伴随着GPT-5这个曾经的王者新版本发布,模型市场的热度也随之升高,但市场并没有对这个大家期待已久的更新给予太多认可。
这个月值得一提的关键词是:混合推理模型。自从Claude 3.7 Sonnet推出了Extending Thinking模式后,越来越多的手动模型开始转向手自一体,而像GPT-5这样的先锋已经尝试了纯自动化的模型。
我相信,无论发动机技术如何演变,总会有人因省油或操控自由的原因选择手动车,但自动挡的普及是大势所趋,毕竟大多数人开车只是为了更方便地到达目的地,而不是享受驾驶的乐趣。
附汇总贴传送门:





听说GPT-5在文学表现上变差,有点担心它的长远发展。能否再提升?
DeepSeek的更新也值得关注,混合推理模型的应用场景想看看。
开源模型的推出是个好消息,希望能吸引更多开发者参与,促进模型的进一步优化。
对于GPT-5的表现,是否有具体的使用反馈?用户们对于它在实际应用中的表现怎么看?
对于GPT-5的表现,感觉它更像是工具,而不是艺术家,这种转变有点让人感慨。
DeepSeek的更新值得期待,混合推理模型会不会有新的应用方向?希望能看到更多案例分享。
听说GPT-5的推理能力提升了,具体在什么领域表现得更好呢?