
快速了解(TL;DR)
- Qoder是什么:它被定义为“真实软件的代理编码平台”,不只是写几行简单代码,而是针对长期发展的工程项目。
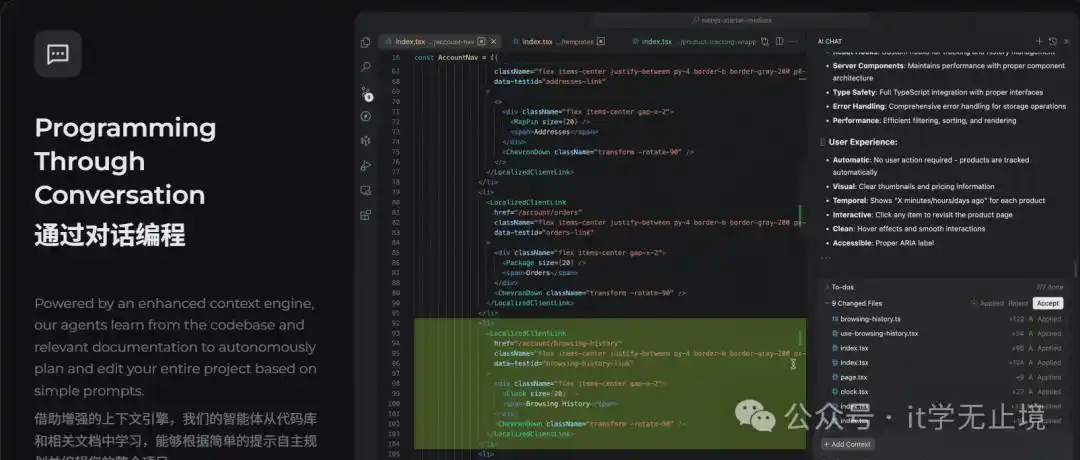
- 两种协作模式:
- 聊天模式:在对话中边聊边修改,我全程跟进;
- 任务模式:先写好Spec(规范),然后一键托管,AI自我推进,遇到问题再询问。
- 方法论关键词:知识可见性、执行透明、增强上下文工程(记忆 + 图谱 + 索引)、自动模型路由。
- 适用场景:新项目启动、老项目添加功能、日常多文件联动修改、复杂仓库“找上下文”、应急排障。
- 当前状态:官网显示“公开预览,免费使用”。(具体情况以官方页面为准)
Qoder到底是什么?(用我自己的话说)
Qoder把AI视为一个可以信任的“助手”,它的主要目标是在真实的代码库中,持续、可追踪地完成工程任务,而不是仅仅在编辑器里写几段代码。
原话:Qoder,专为真实软件开发打造的Agentic编程平台!
你可能感兴趣:Qoder,带你从“执行者”华丽转身为“架构师”!
下载页面大概是这个样子的:
现在标注的状态是免费公开预览:
小贴士:预览期的功能和条款可能会调整,请以官网为准。
背景:AI编程趋势到底在变什么?
随着大模型的进化,AI编程经历了三个阶段:
- 辅助写代码:自动补全、代码片段生成;
- 对话式改造:通过聊天驱动重构和修补;
- 半/全托管开发:明确给AI设定目标与边界,让它自己执行流程。
AI的角色从“工具”逐渐转变为“同事”,开始承担多步、长期的工程任务。
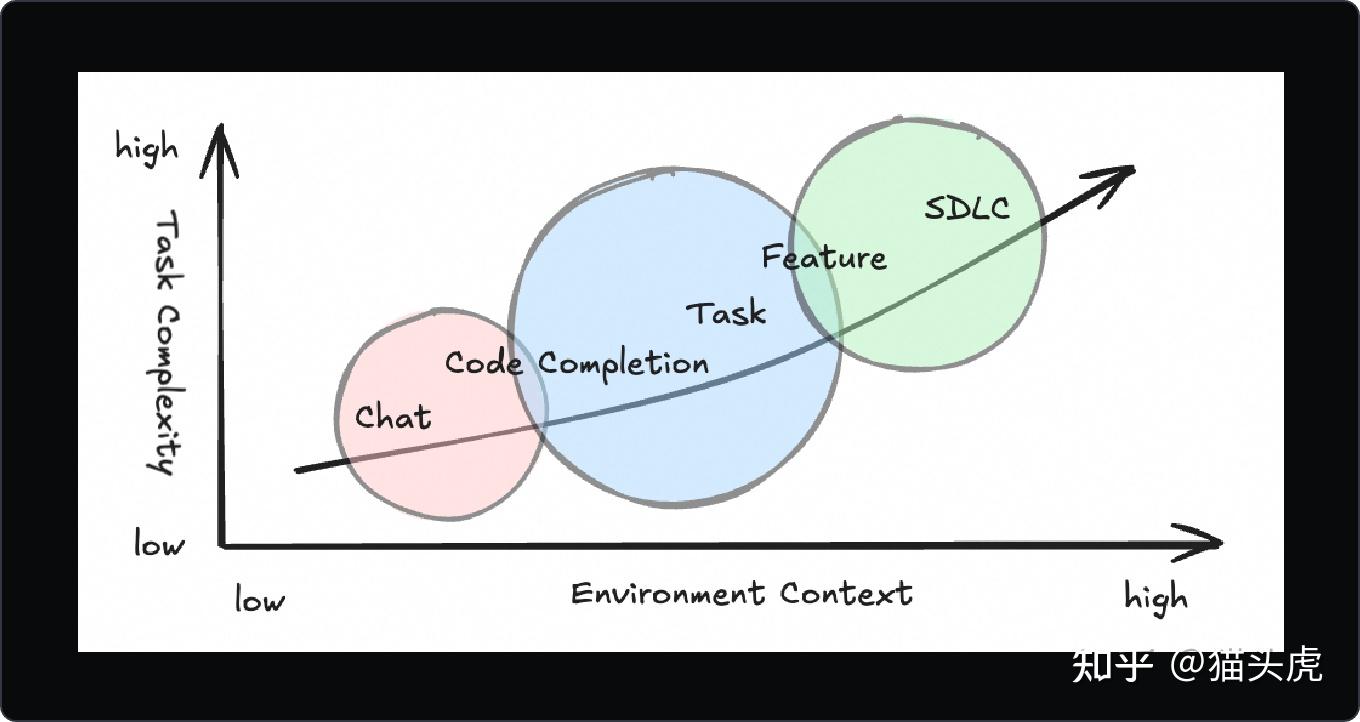
工程现实中的难题
Brooks在《人月神话》中总结了软件开发的四个主要难点:复杂性 / 一致性 / 可变性 / 隐形。在AI时代,这些问题并没有自动消失,反而可能变得更加明显:
- 知识太抽象 → 新人很难接手,技术债务容易累积;
- 过于依赖“自动生成代码” → 设计和需求澄清被忽视,后期维护更加麻烦;
- 强同步沟通 → 人机之间频繁确认,AI难以“长时间独立工作”。
Qoder的解决方案(我理解的四个关键词)
① 提高透明度:知识与执行的可见性
- 知识可见性:不仅仅是写代码,还要帮助人们了解项目的全貌——架构、设计、技术债务和决策过程。
- 执行透明:
- 待办清单:任务分解、优先级、预估路径;
- 行动流程:过程跟踪与关键决策记录。
目的很简单:让开发者始终“心中有数”,而不是在黑箱中托管。
② 增强上下文工程
口号是:上下文越丰富,建议越准确。
- 深度理解代码库:理解结构、依赖关系、设计意图,而不仅仅是看文本相似;
- 持久记忆:能够记住项目历史、用户操作和对话上下文。
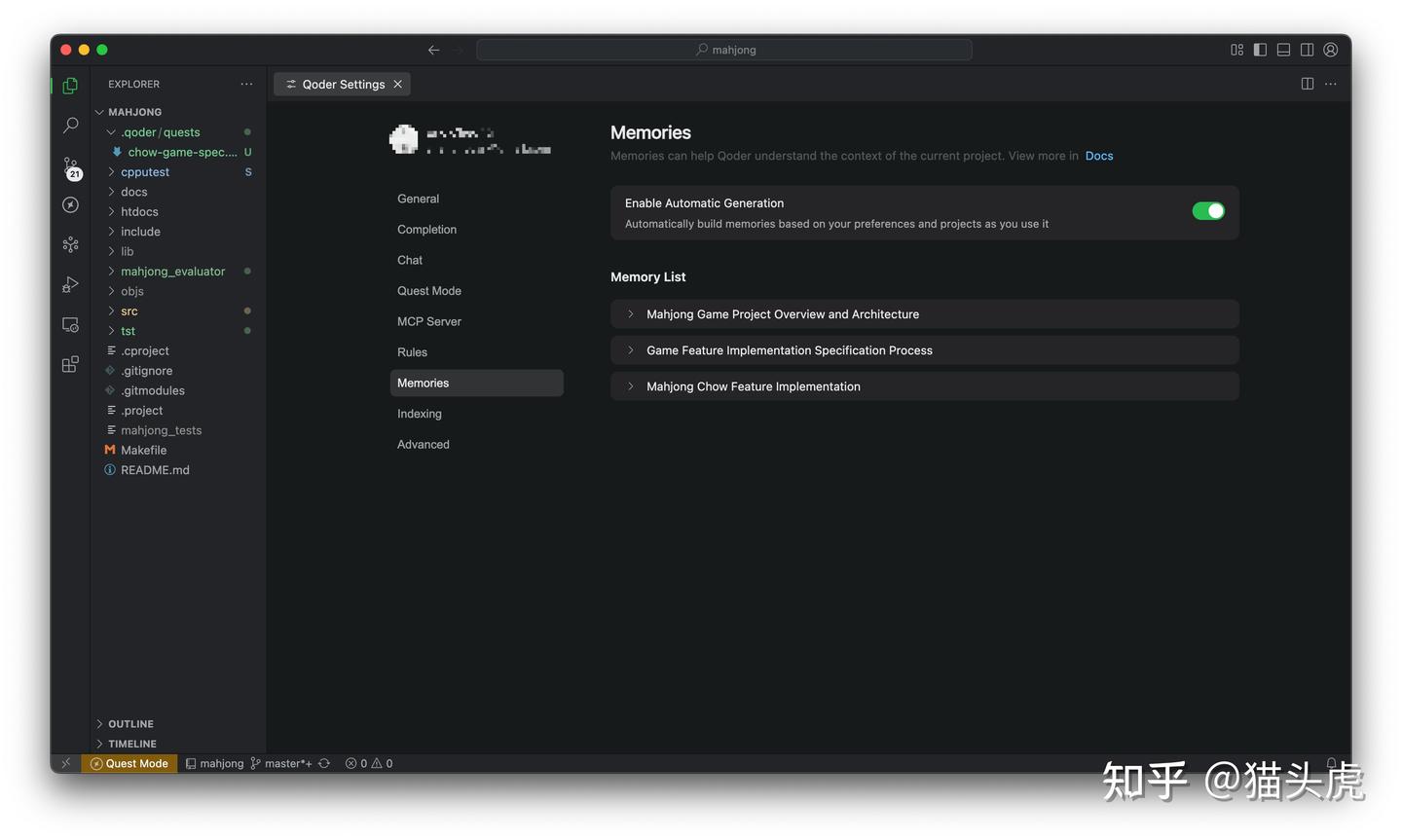
③ 规范驱动 + 任务委托:把意图说清楚
有两种协作方式:
- 聊天模式:通过对话驱动修改,随时审查,适合短期任务;
- 任务模式:我写好Spec(尽量把目标、边界和验收标准详细说明),然后托管给AI,适合长期任务。
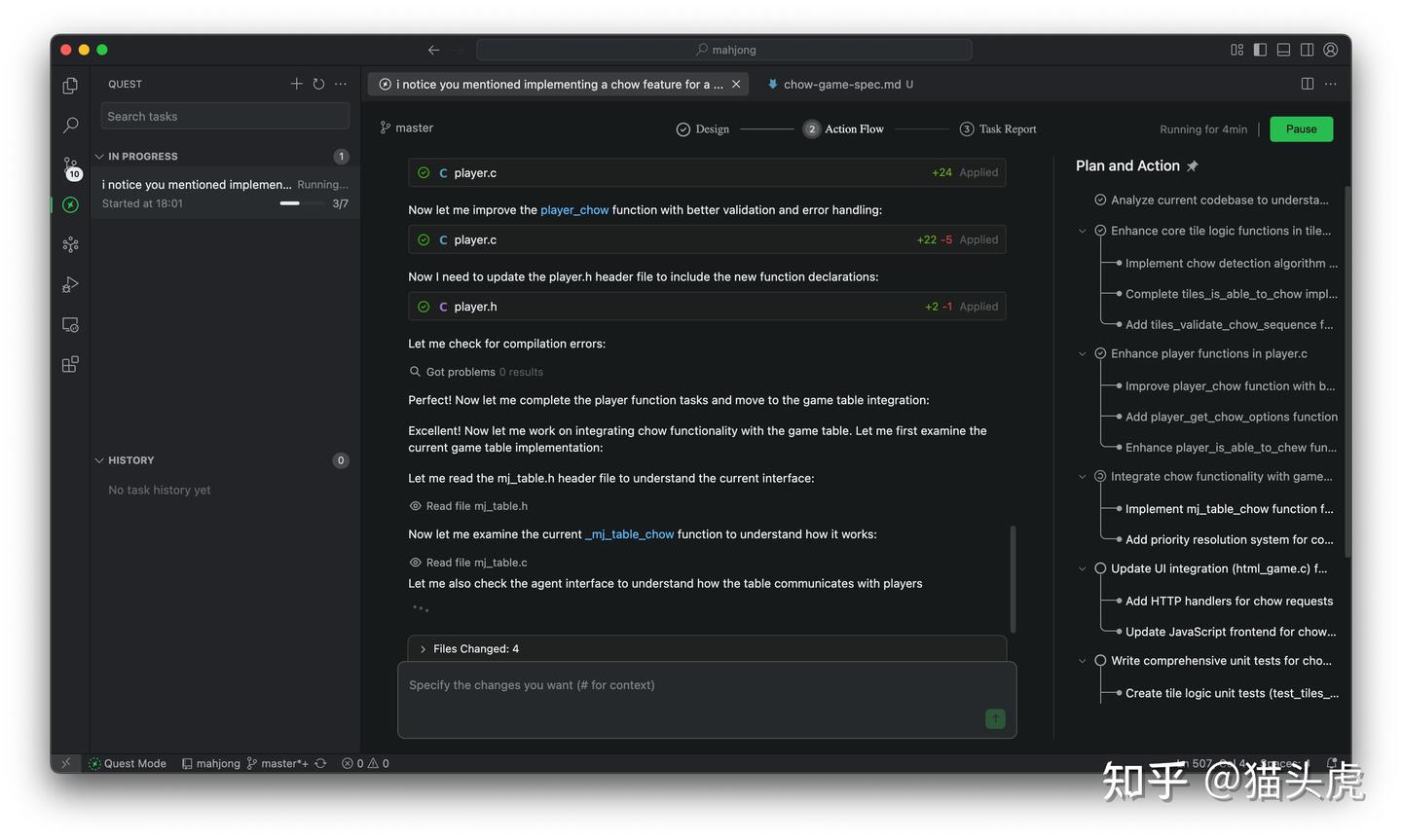
对比表(简版):
| 聊天代理模式 | 任务模式 |
|---|---|
| 聊天迭代 | 规格优先 |
| 通过对话进行编码 | 将任务委托给AI代理 |
| 短期任务 | 长期任务 |
| 你盯流程 | 你定目标 |
我理想中的工作日:上午对齐需求 → 下午和AI一起打磨Spec → 下班前托管 → 第二天早上验收和重构。
④ 模型“自动路由”:别再让我去比对参数
在模型层面,Qoder更像是**“根据任务自动选择最佳方案”**。你只需告诉它目标,如何达成交给系统处理,兼顾质量和成本。
上手建议(给想尝试的朋友)
新项目从0到1
一句话描述你的目标就行,比如:
“用Spring Boot做一个图片上传/预览/下载的简单应用。”
Qoder会帮你生成框架和核心逻辑;或者先开启探索模式,写一份可运行的Spec(技术栈、架构、MVP功能)。
老项目中增加功能
老项目的一个痛点是不清晰的上下文。Qoder的Repo Wiki会预索引并注入信息,启动任务时自动带入上下文,不再需要手动挑选文件。
日常编辑体验
- 代码补全
- NES(下一步编辑建议):提供“下一步修改”建议,可以跨多行;
- 内联编辑:可以在聊天中直接修改补丁。核心诉求:增强,不打断。
一些使用建议(主观分享)
- 适合对象:经常在中大型项目中进行多点联动修改、需要频繁追踪上下文的同学;或者是小团队想把“工程推进”交给AI来加速。
- 尽量写清楚Spec:别把“需求澄清”这个工作偷懒给AI——写得越详细,委托就越稳妥。
- 关注隐私与合规性:企业或高校的代码要清楚数据流向和权限设置。
- 免费不等于永久:预览期的策略可能会变,注意官方的更新信息。
愿景
- 把隐形知识显性化,减少沟通的摩擦;
- 把重复的工作交给AI,让人们专注于设计与验证;
- 加厚上下文,让AI真正“理解项目”,而不仅仅是“看似懂”。
目前官网上写着“公开预览,免费使用”。如果你感兴趣,可以在真实项目中试试,反馈给社区也欢迎分享给我(猫头虎)。
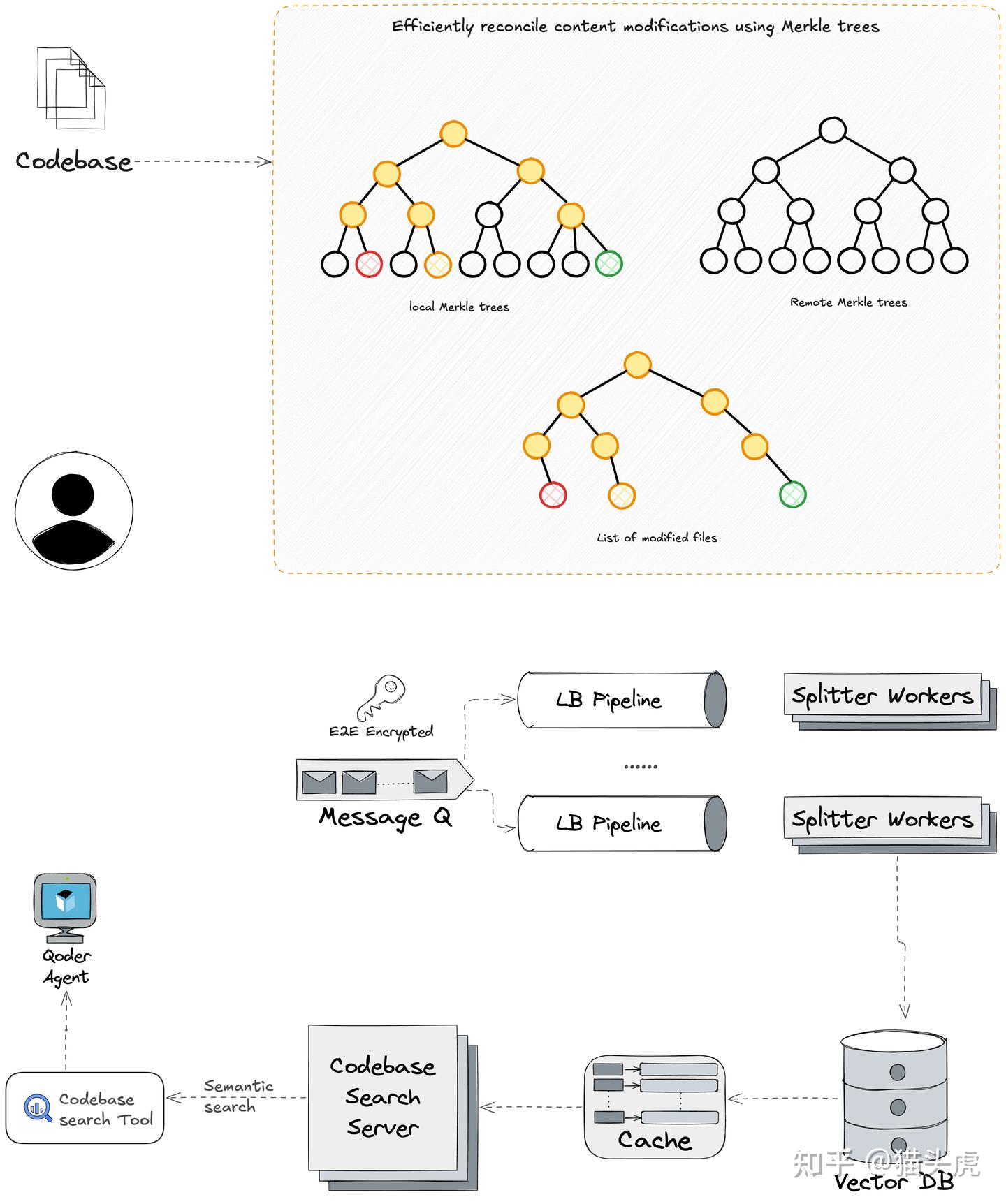
加餐:代码库感知的“混合检索”到底怎么实现?
从“通用嵌入”到“实时 + 图谱 + 预索引”的多重组合策略
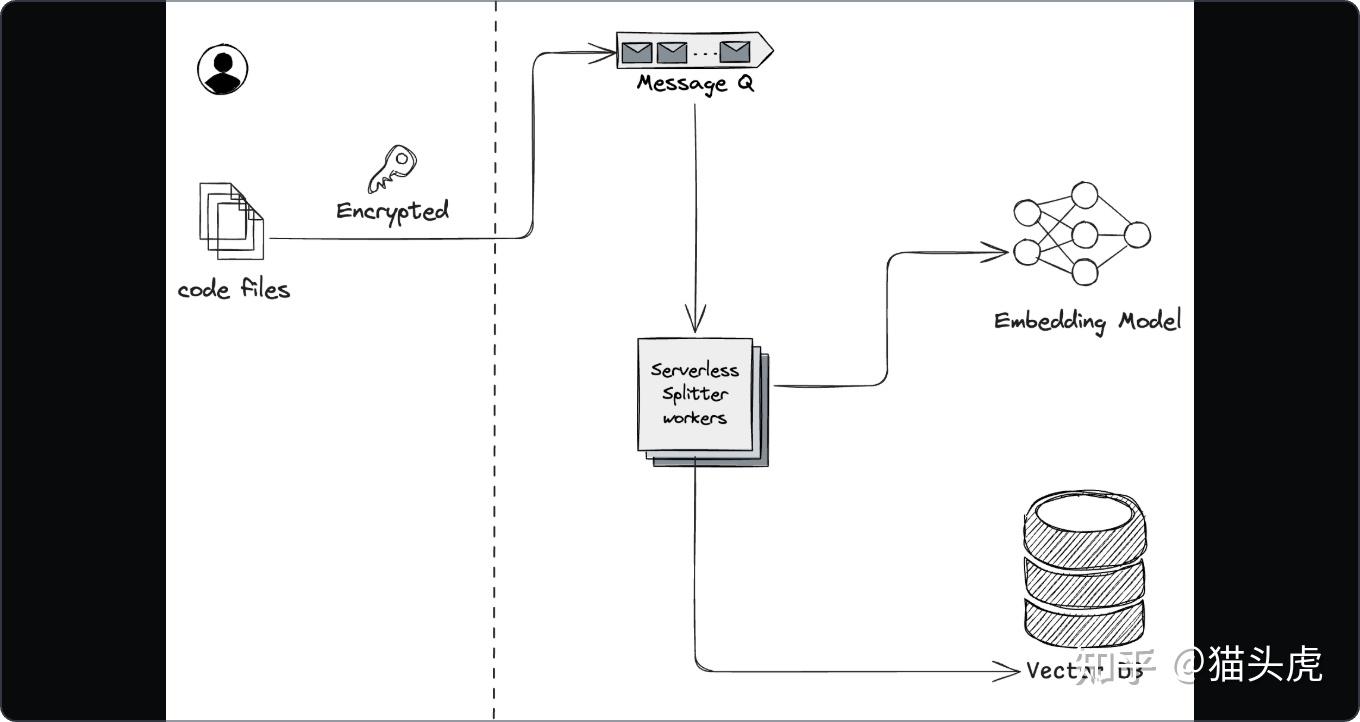
市面上有不少工具自称“懂你代码”,但大多数其实是依赖于通用嵌入和远程向量库。虽然它们能计算相似度,但结构关系(比如调用、被调用、不同语言之间的交互、文档概念与实现的映射)却容易丢失。而且,索引的刷新速度通常是几分钟,这根本跟不上你本地的分支切换或重命名。再加上把私有代码交给第三方服务,隐私问题让人心里不安。
那么,有没有更靠谱的解决办法呢?其实可以把三件事情结合起来:
1)服务器端向量搜索:更了解“代码语义”
首先,在后端放一个高效的向量库,专门存储代码片段、文档和工件的嵌入;而且这个嵌入模型是针对代码和领域语义优化过的。这样一来,索引就能持续增量更新,几乎可以在秒级内反映新的改动。
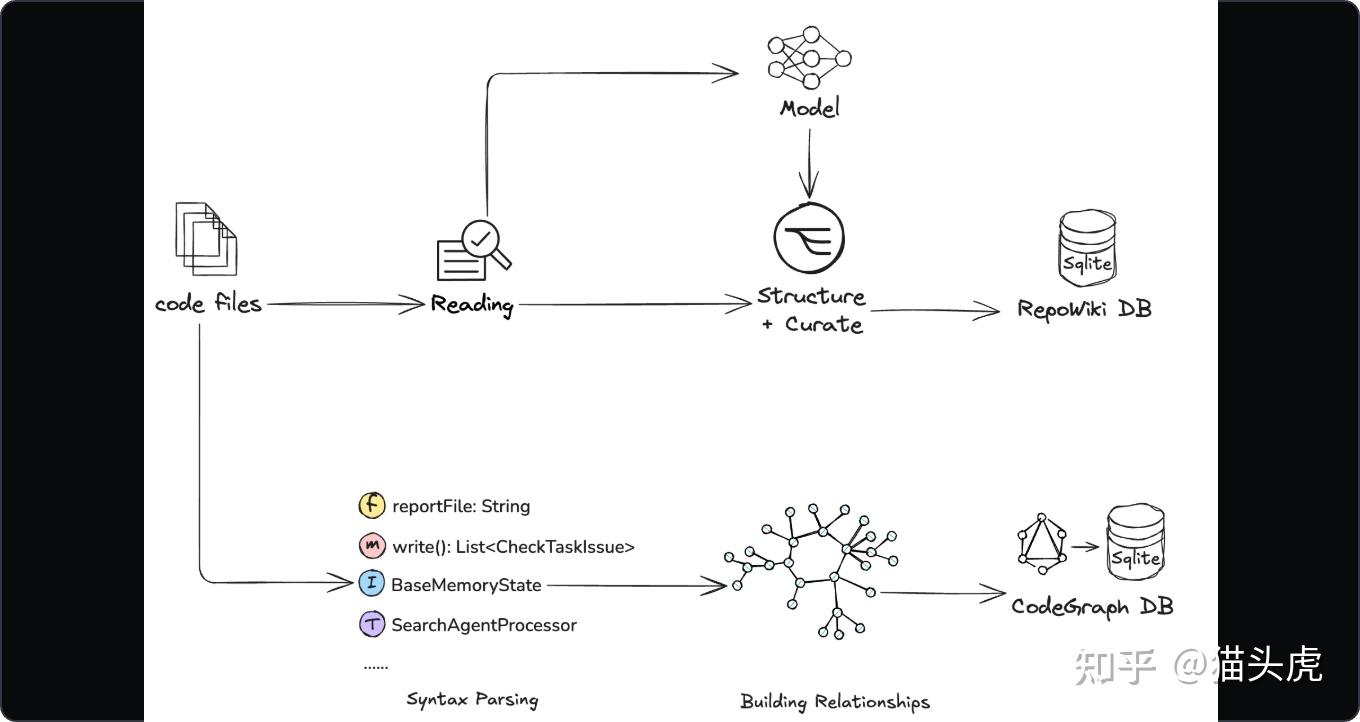
图像.png 2)代码图谱和预索引知识:更懂“结构关系”
客户端则维护一个代码图,包括函数、类、模块,还有它们之间的调用、继承关系以及跨语言的映射。同时,把设计文档、架构图和内部wiki等进行预索引处理,这样在查找的时候就能实现超低延迟的图遍历和概念查询。
图像.png 3)融合检索:向量与图谱,双信号重排
查询的过程可以这样进行:
- 先计算查询嵌入;
- 接着进行向量检索,找出前N个结果;
- 然后利用图谱进行扩展或收敛(把被调用者、调用点、相关配置和参考文档一起找出来);
- 最后利用相似度和结构相关性进行融合重排。
这样做的好处是,能够同时找到语义上相近和结构上高度相关但文本不相似的内容,比如“调用点”和“实现”之间的关系。
4)实时与个性化:跟随你的分支变动
每个开发者都有自己的个人索引:当你切换分支、批量替换或保存文件时,客户端会在秒级内将这些变动同步到服务器,向量和图谱都会随之更新。
图像.png 5)安全与隐私
- 不把原始代码传输给第三方,所有的嵌入计算和搜索都在自家的基础设施中进行;
- 通过加密哈希来证明内容的真实性;
- 嵌入的传输和存储全部加密。
典型应用场景
- 逛大仓库:不仅能匹配“名字相似”的定义,还能根据调用链、配置和设计文档提供完整的上下文信息。
- 应急排障:能够快速覆盖相关的代码路径、测试和Runbook,比起单纯的全文检索能更快缩小问题范围。
尾声
以上是我(猫头虎)根据公开资料整理出的一个非官方视角:Qoder在“AI写代码”这一领域又向工程化和可托管的方向迈进了一步。如果你对性能、插件生态、团队落地,或者与现有IDE的协同等方面有任何疑问,欢迎留言讨论。同时也期待你分享使用体验,后续我会继续关注这些反馈并更新使用体验。







这款Qoder看起来真的很不错,特别是它的协作模式,感觉会提高开发效率!
Qoder的功能听起来很强大,特别是知识可见性这一点,能帮助新手更快上手。
Qoder的聊天模式让我想起了小时候玩游戏的感觉,能否把编程变得更有趣?
真希望Qoder能解决开发中的沟通问题,毕竟大多数时间都在开会,写代码的时间真心不多。
如果Qoder能减少技术债务,那开发者们是不是能轻松点?
能否在预览阶段就提供更多的用户反馈渠道?这样更能完善产品。
如果Qoder能提供更好的代码库理解功能,那将大大减少后期维护的麻烦。
希望Qoder能尽快推出稳定版本,毕竟预览期可能会遇到不少问题。
Qoder的可视化设计能否帮助新人快速理解项目架构?这对学习很重要。
愿Qoder能在处理复杂项目时表现出色,别让开发者陷入更多的技术债务。
希望Qoder在后期能保持良好的用户体验,不要让我们等太久,毕竟预览期总是充满未知。