作者 林易
编辑 重点君
2025年已接近尾声,全球科技的潮流又一次发生了变化。
年初的时候,大家都在翘首以待OpenAI的GPT-5问世,认为它会和之前的版本一样令人惊艳。然而,到了年末,这种期待似乎并没有实现。
在12月29日,美国著名科技媒体《连线》发布了一篇颇具象征意义的年终文章——《再见,GPT-5。你好,千问》。
虽然文章并没有否认GPT的地位,但却敏锐地察觉到了市场的变化:GPT-5未能如预期那样引发热潮,而来自中国的开源模型阿里千问(Qwen)表现出色,适合灵活应用,2026年将会是千问的时代。
《连线》杂志的观察指出,尽管OpenAI的GPT-5、谷歌的Gemini 3和Anthropic的Claude通常得分较高,但千问、DeepSeek等中国模型的表现也不逊色,并且越来越受欢迎,这主要是因为它们的性能优异,开发者能够轻松地进行调整和使用。
在文章中,《连线》的资深编辑Will Knight提出了一个新的评估标准:“衡量任何AI模型价值的关键不应仅仅是它的智能程度,更要看它能在多大范围内被用来构建其他应用。”
如果按照这个标准来衡量,过去的一年绝对是全球大模型格局重塑的一年。全球AI的格局正在从以美国为主导的单极世界,逐渐发展成中美双核的多极世界。中国的大模型正从追随者转变为并肩作战者。
开源:权力的交接
让我们把时间回到两年前,那时Meta的Llama系列是全球开源模型中的绝对霸主。在那个时期,中国的AI行业普遍关注“如何做出中国版Llama”,有很多创业公司甚至以Llama模型的外壳来进行融资。
然而到了2025年,Meta的基础模型性能明显落后,Llama 4未能在LM Arena基准测试中进入第一梯队,创始人扎克伯克开始从OpenAI等竞争对手那里高价挖人,频频登上头条;与此同时,OpenAI的gpt-oss等开源模型表现不佳,没能吸引到太多开发者。
进入2025年下半年,开源的领导权发生了转变。根据全球最大的AI开源社区HuggingFace的数据,2025年7月成为一个标志性时刻:中国开源模型的下载量首次超过了美国,其中千问名列前茅。
截止到2025年10月,千问的全球下载量已经突破了7亿次,超越Llama,成为全球最大的开源模型。更值得一提的是,在OpenRouter这个能更好反映开发者偏好的第三方API聚合平台上,千问的调用量曾一度排名全球第四,仅次于几个顶尖的闭源巨头,而且在编程等细分领域常常名列前茅。
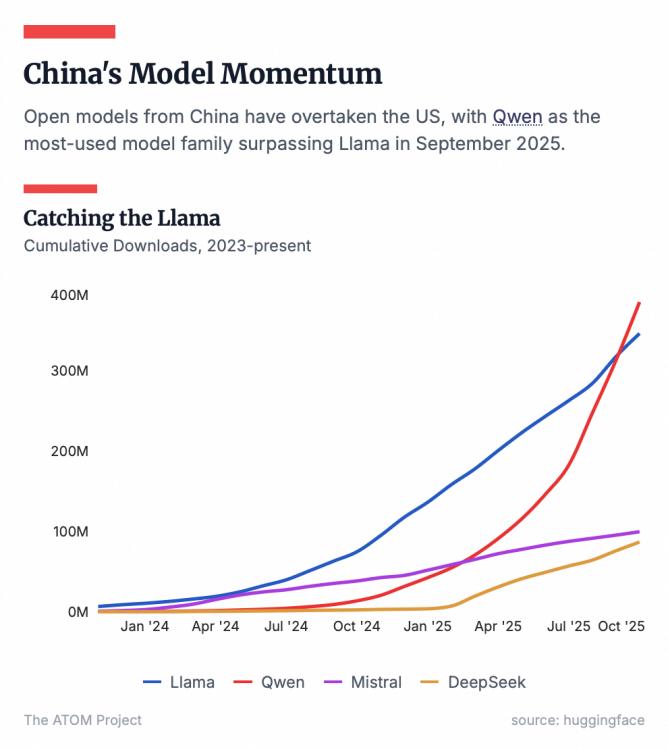
《连线》在调查中发现,连曾经的开源先锋Meta也在内部使用千问来帮助开发其下一代模型,这在两年前简直难以想象。
而在美国,推动开源模型发展的非营利组织Laude Institute的联合创始人Andy Konwinski也直言:“很多研究人员都在使用Qwen,因为它是目前最优秀的开源大模型。”
这背后的原因,是阿里选择了一条比Meta等公司更为彻底的开源之路。
一方面,与几乎不开放源代码的OpenAI相比,阿里在模型的构建和持续更新上投入了更多精力,千问的技术细节也更加公开透明,阿里定期发表论文,详细介绍新的工程和训练技巧,这与美国大型科技公司的封闭态度形成了鲜明的对比。
另一方面,不同于一些公司采取“开源小模型、闭源大模型”的谨慎策略,阿里的做法更像安卓系统:一次性开源了近400款模型,涵盖从0.5B到110B的全参数规模,涉及文本、图片、语音、视觉等多种模态,还支持119种语言。
生态护城河:千问的策略
这种策略就像是在建立一道保护墙。当开发者想要造一款智能硬件时,就得用一个小型模型;如果是要处理复杂的推理,那就得用大型模型。以前,开发者可能得四处找不同厂商的模型拼凑,如今,千问直接提供了一整套标准化的解决方案,真是方便极了。
根据HuggingFace在2025年9月底发布的开源模型排行榜,前十名中竟有七款是通义的。斯坦福HAI研究所的报告也指出,2024年重要的大模型里,阿里有六个入围,AI贡献度位居全球第三,真是厉害了。
显而易见,中国的科技公司已经不仅仅是全球AI的使用者,它们开始掌握模型层的技术标准和话语权,真是大步向前。
模型应用:隐形的战场
只有把模型应用到各行各业的实际场景中,才能真正发挥它的价值。
相比于开源社区那些可见的下载量,AI落地的产业往往是默默无闻的。对大多数企业来说,模型只是个技术底座,他们不需要宣传自己用的是什么模型,只要产品好用就行。
在《连线》的一篇文章中提到,杭州的智能眼镜初创公司Rokid,记者和工程师正在用智能眼镜实时翻译对话,文字就在眼前显示。这一切的背后,是千问的开源模型在支撑。
这不过是个开始。
基于千问,AI社区已经形成了庞大的生态系统。千问模型发布后,主流的AI框架如vLLM、SGLang、苹果MLX等都迅速支持;硬件厂商如英伟达、联发科等也第一时间适配;开发者们使用的应用、工具和平台,如Ollama、Kaggle等,都会同步上线新的开源模型。
这意味着,任何企业想用千问,工具链的完善让他们的边际成本降到最低,真是加速了AI的落地和创新。
从北京到硅谷,再到华强北和义乌小商品市场,千问已经覆盖大公司、中小企业和创业公司,成为实际应用最多的大模型。
在美国,像Airbnb、Perplexity和英伟达这样的硅谷明星公司都已把千问纳入了技术栈;而在中国,比亚迪等新能源车企将千问整合进了新款车载助手中;OPPO、vivo等手机厂商则在端侧大量部署千问的小参数模型。
国际权威调研机构沙利文的报告显示,到2025年上半年,中国企业使用大模型的市场中,千问的占比排名第一,服务客户超过100万。
这种广泛应用正是《连线》提到的新标准:一个模型能构建出成千上万种不同的应用时,它的生命力就远超单纯的榜单排名。
正如Laude Institute的创始人Andy Konwinski对《连线》所说,“狭窄的基准测试往往只衡量数学或编程技能,却牺牲了确保模型产生重大影响的机会。当基准测试无法代表真实世界的使用场景时,最终就会走上错误的方向。”
编程:被低估的赛道
值得注意的是,在所有的产业落地场景中,AI编程正在成为最赚钱的AI领域。
以Anthropic为例,2025年,它凭借Claude模型在编程领域的出色表现,营收实现了爆发式增长。预计到年底,其年化营收将接近70亿到90亿美元,短短一年就翻了近7到9倍。在完成F轮融资后,估值迅速飙升至1830亿美元,甚至二级市场给出了2200亿美元的隐含估值。
Anthropic的成功在于,它的API收入中很大一部分来自Cursor和GitHub Copilot等编程工具的使用,单这一块就为它带来了数十亿的收入。
毫无疑问,AI编程正在彻底改变程序员和企业的工作流程。程序员不再只是埋头苦干,而是专注于更高层次的架构和创新,通过大模型快速生成代码,然后进行修改和迭代,这种新方式极大提升了验证想法的速度。
OpenAI的联合创始人Andrej Karpathy,甚至感叹:“作为一名程序员,我从未感到如此落后……”
在中国,阿里在AI编程模型和平台方面的布局最为全面,并且正在迅速赢得市场。
在模型层,阿里在7月23日开源了千问AI编程大模型Qwen3-Coder。这款模型以480B参数激活35B参数的MoE架构,原生支持256K上下文,编程能力在全球开源阵营中名列前茅,不仅超越了GPT-4.1,更比肩全球最强的编程模型Claude 4。OpenRouter数据显示,Qwen3-Coder上线后,调用量一周内猛增1474%,成为编程领域全球第二。
在应用层面,通义灵码已经成为国内使用最广泛的辅助编程工具。
例如,在金融行业,中国建设银行、工商银行、平安集团等巨头已经全面推广;平安集团超过1.5万名研发工程师使用AI编程,部分新项目中AI生成的代码占比超过70%;在汽车行业,吉利、蔚来和小鹏汽车的研发团队中,AI生成代码的比例普遍超过30%;在SaaS领域,用友网络的研发人员中,有超过50%使用通义灵码,AI代码生成占比达到37%。
截至2025年9月,通义灵码为开发者生成了超过60亿行代码,帮助300万开发者减少重复编码、测试和修复工作,专注于架构设计和技术创新。
为了进一步抢占市场,阿里还推出了Agentic编程平台Qoder,它能够集成全球顶尖模型,一次检索10万个代码文件,将数天的网页开发工作缩短至十分钟。
通过深度集成全球顶尖编码模型的Qoder和Owen-coder系列模型的通义灵码,阿里云已经形成“全球创新→本土深耕→生态落地”的全面布局,而这一部分的价值,目前市场还没有完全认可。
对于企业来说,AI编程能力是通向通用人工智能的必经之路。阿里巴巴集团董事兼首席执行官、阿里云董事长兼首席执行官吴泳铭曾在云栖大会上系统阐述了通往超级人工智能的三个阶段,其中第二阶段“自主行动”的核心就是大模型具备编程能力。因为只有掌握了代码,AI才能像工程师一样拆解任务、操作工具,最终发展成为能够自我迭代的Agent。
全栈:AI巨头的入场券
当模型能力越来越相似,竞争的焦点开始转向更全面的全栈能力。
回顾过去三年,全球科技圈的主流叙事中,只有两个角色:英伟达负责提供GPU硬件,OpenAI则专注于挖掘前沿模型的潜力。
未来的AI市场:谁将主导?
到了2025年,谷歌的强势回归可谓是一次游戏规则的重新定义。过去一年里,谷歌借助Gemini 2.5和3.0系列模型,以及TPU v6和v7芯片的强大算力,不仅缩小了与OpenAI之间的差距,还通过“芯片+云+模型”的全栈技术构建了一个完整的闭环,大幅降低了推理成本。有分析师甚至指出,谷歌提供同样推理服务时的底层成本,可能仅需对手的20%不到。
随着AI应用的爆炸式增长,推理算力的需求也在迅速提升。对于企业而言,控制成本简直就是生死攸关的事情。
因此,谷歌云财报的亮眼表现就不难理解了:在2025年第三季度,新增客户数量同比增长接近34%,而且超过70%的客户已经开始使用它的AI产品;前三个季度的总营收达到了410亿美元,同比增长31.2%,这在与亚马逊AWS和微软Azure的比较中,显示出其在北美三大云服务商中增长最快的势头。这种增长主要得益于其全栈AI能力的释放。
说到全球科技巨头,阿里与谷歌的路径最为相似。从模型到B端市场再到C端应用,“西谷东阿”逐渐成为硅谷和华尔街的共识。在过去一年里,这两家科技巨头的股价都飙升了超过60%。
和谷歌一样,阿里通过阿里云也建立了全球性的AI基础设施,涵盖了底层芯片、超节点服务器、高性能网络、分布式存储,以及人工智能平台、模型训练和推理服务,形成了完整的全栈AI云技术能力。

全栈布局带来的好处显而易见。未来,企业所需的不再只是一个简单的API接口,而是一整套结合了私有数据、算力调度与安全合规的解决方案。有些企业可能只需要API调用,有的则希望自己训练模型,还有的可能需要RAG(检索增强生成)。这些复杂的需求,只有那些覆盖IaaS、PaaS、MaaS的全栈服务商才能完美满足。
这种“云+模型”的一体化策略,正是阿里在B端市场的杀手锏。
作为全栈AI服务提供者,阿里正在推进一项为期三年的3800亿人民币的AI基础设施建设计划,并持续增加投入。阿里云也在为全球用户提供智能算力网络。
总结
《连线》杂志的标题——“再见,GPT-5。你好,千问”,并不意味着行业的终点。OpenAI和谷歌依旧掌握着顶尖的模型,而英伟达的算力霸权在短期内也难以被打破。不过到2025年,AI的格局将不再是单一的世界。
当全球开发者逐渐习惯于使用千问的开源模型,当硅谷的创业公司开始将业务建立在来自杭州的模型上时,中国的AI将在全球科技版图上获得不可替代的地位。
到2026年,或许正如《连线》所预测的那样,将是“千问之年”。不过,这不仅仅属于千问和阿里,更是属于所有拥抱开放、支持开源的人们。