开启你的智能代理之旅,轻松接入强化学习!
机器之心编辑部
2026年开年的这两个月里,智能代理(Agent)依旧是全球范围内备受关注的人工智能领域之一。OpenClaw(之前叫Clawbot)引发的那股代理热潮如今仍在持续,甚至让“一人公司”这个概念开始有了实际的落地可能。
最近,OpenClaw在GitHub上的关注度超越了React和Linux,成为了非资源类和教程类开源项目中星标数量最多的项目。
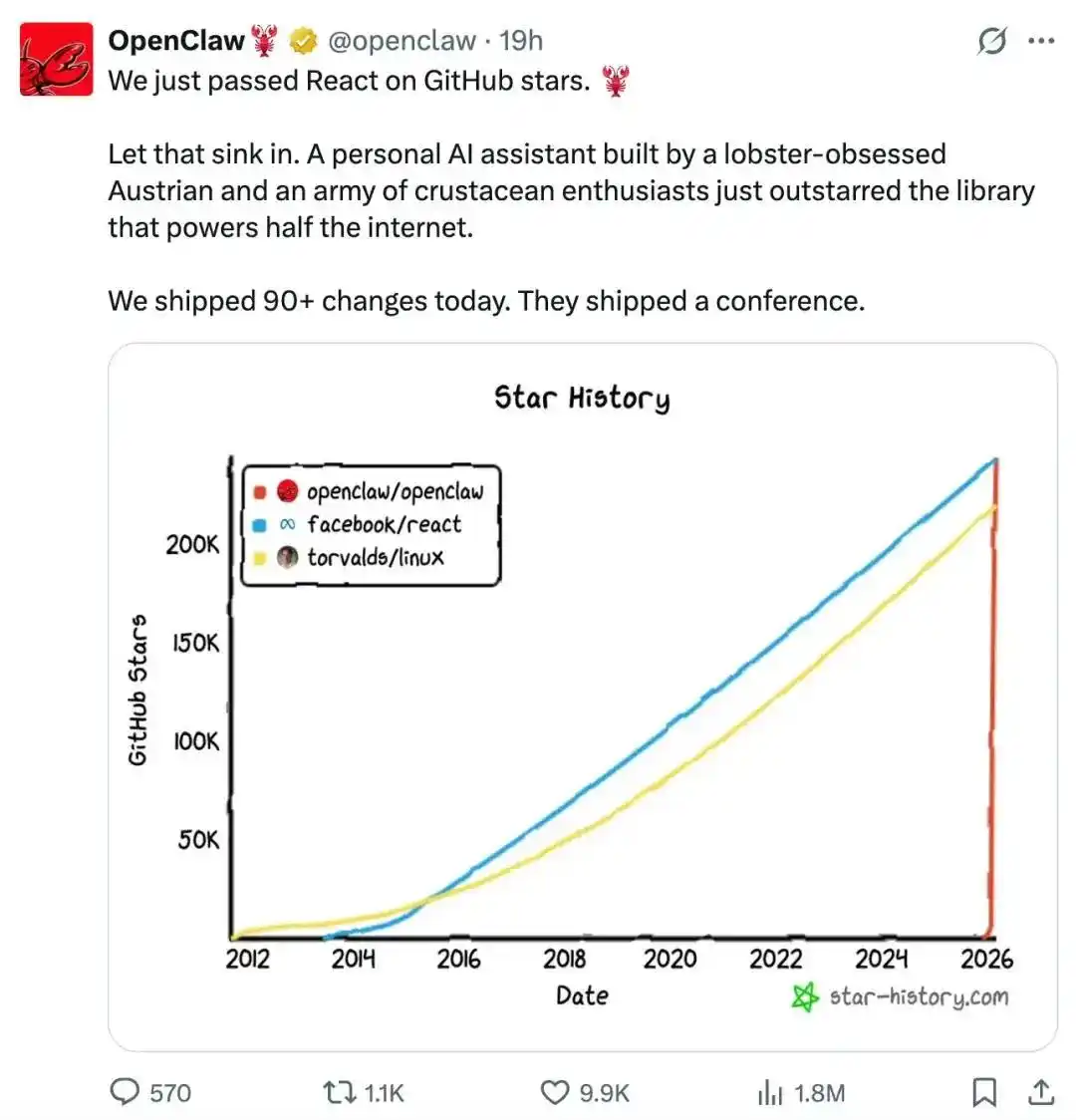
从浏览器代理到编码代理,再到个人和企业级的工作流代理,大家可能会发现:代理的能力在不断增强,能做的事情越来越多。
与此同时,像LangChain、Claude Code和OpenClaw等一系列运行时框架也在不断扩展智能代理的能力,让它们能够处理更复杂的任务。虽然这些框架为代理提供了更广泛的应用前景,但要想让它们在真实环境下持续进步并具备自我进化的能力,仍然缺乏成熟的支撑体系。
尤其是被寄予厚望的强化学习(RL)训练,承载着让代理在复杂、多轮、长程任务中不断进化的重任,但在实际应用中却面临许多挑战,这限制了当前代理的能力提升。
不过,AReaL v1.0的发布给行业带来了好消息:一个即插即用的代理强化学习训练基础设施已经初步成型。
这个由蚂蚁和清华大学联合开发的开源强化学习框架AReaL,经过近一年的不断改进,终于发布了一个稳定的里程碑版本。作为一套专为代理设计的全异步强化学习训练框架,这次最令人瞩目的进展是实现了“代理一键接入RL训练”的目标,重新定义了智能体强化学习的方式。
📦 GitHub 仓库:https://github.com/inclusionAI/AReaL
📄 论文:https://arxiv.org/abs/2505.24298
借助Agentic RL算法系统的协同创新,AReaL v1.0能够兼容任何代理框架,只需修改一个接口地址,就能无缝接入RL训练,包括最近非常火的OpenClaw,这极大地降低了强化学习的入门门槛。此外,AReaL v1.0还引入了系统化的AI辅助开发体系,并通过深度定制的PyTorch原生训练引擎Archon,实现了千亿MoE模型的端到端训练,引领了下一代AI基础设施的变革。
零代码接入OpenClaw训练
以往,进行Agent的强化学习训练,往往需要开发者深入理解底层框架,还得修改代理的运行时代码,甚至重构整个数据处理流程。而AReaL v1.0彻底打破了这种壁垒——你的代理框架完全不需要改动任何代码。
让我们用一个实际的例子来看看这有多简单。
完整案例:https://github.com/inclusionAI/AReaL/tree/main/examples/openclaw
第一步:启动RL训练服务
uv run python3 examples/openclaw/train.py –config examples/openclaw/config.yaml
启动后,你会看到类似这样的输出:
(AReaL) Proxy gateway available at http://x.x.x.x:xx
记得记下这个网关地址,它可是连接你的代理和RL训练的桥梁哦。
第二步:配置你的代理
我们以ZeroClaw为例,这是OpenClaw的一个变种。只需要修改一个配置文件,把API地址指向AReaL网关:
# ~/.zeroclaw/config.tomldefault_provider = “localhost”api_key = “sk-sess-xxxxxxxxxxxx” # 从AReaL获取
[model_providers.localhost]base_url = “http://” # AReaL代理网关地址
就这样,配置完成。你的ZeroClaw代理现在每次LLM调用都会被自动记录,用于强化学习训练。
第三步:正常使用你的代理
让你的智能体在日常使用中不断进化
启动智能体,准备好和它进行互动吧:
使用命令:zeroclaw channel start # 这一操作可以让你在Discord、Slack或CLI等平台上与智能体交流。
你可以让这个智能体来写代码、查找信息、完成各种任务——一切都和往常一样。而在这些互动的背后,AReaL正默默地记录着每一次对话,为强化学习提供数据支持。
第四步:给出反馈,助力智能体进化
完成任务后,给你的智能体一个评分吧:
运行命令:python set_reward.py http:// –api-key sk-sess-xxx –reward 1.0
就这么简单。AReaL会将这次互动的记录和你的评分打包,送往训练系统进行处理。
当收集到足够的互动记录后(根据设置的batch_size来决定),系统会自动进行一次训练迭代,更新模型的权重。而且更新后的权重会直接应用到后续的推理请求中,毫不费力。
你的智能体在训练过程中依然可以正常工作,不需要重启,也不必重新加载模型——它会在不知不觉中变得更加聪明。
用「异步训练」和「代理网关」打破智能体的进化瓶颈
AReaL是如何让OpenClaw实现自我进化的呢?这里面有两个关键的架构设计:「全异步训练」和「代理网关」。
AReaL的一个重要创新在于将强化学习中的训练和推理完全分开。推理引擎流式生成数据,训练引擎则持续处理样本,这两者在不同的GPU上同时运行。
通过精心设计的PPO算法和陈旧度控制机制,AReaL在确保训练稳定的同时,实现了2倍以上的吞吐提升。
这种设计在智能体训练中更是大显身手——训练引擎异步更新参数,不会影响智能体的推理过程,让你的OpenClaw可以一边学习,一边全力以赴工作。
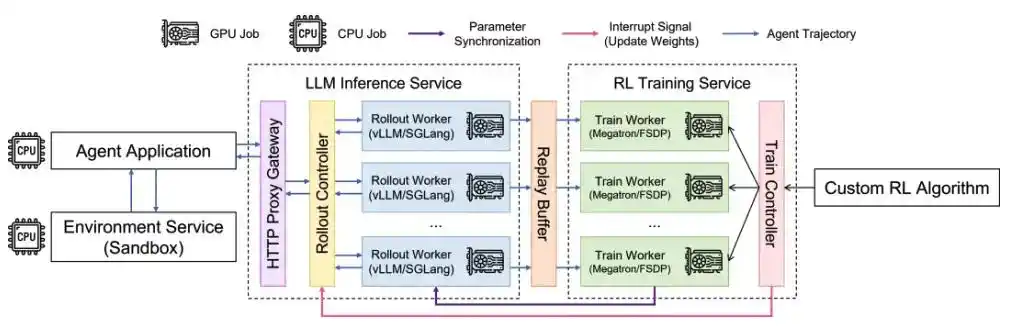
AReaL的代理网关与全异步强化学习架构
为了适应各种智能体框架,AReaL选择了「协议」作为统一标准,设计了一个代理网关(Proxy Gateway)。这个网关提供OpenAI/Anthropic API协议的推理服务,并会将所有输入请求转发到本地的推理引擎(比如SGLang、vLLM)进行计算,使用起来就像普通的推理服务一样。
不过,这个代理网关可不仅仅是路由功能——它在推理的同时,捕捉每一次LLM互动中的Token级信息。当一轮互动结束后,AReaL会将后续的奖励值反向传播,为每一轮的输入输出分配奖励,最终生成独立的训练样本。这样,即使是早期的决策也能获得合理的奖励分配,让模型学会「为长远目标做出正确的早期选择」。
传统方法中,推理时的文本必须在训练时重新进行tokenize,可能会因为tokenizer的配置不同导致token序列不一致。而AReaL的独立导出方案从根本上解决了这个问题:推理时产生的token IDs会被缓存,训练时照样使用。所以发送给训练引擎计算的tokens就是推理引擎生成的tokens,完全一致。
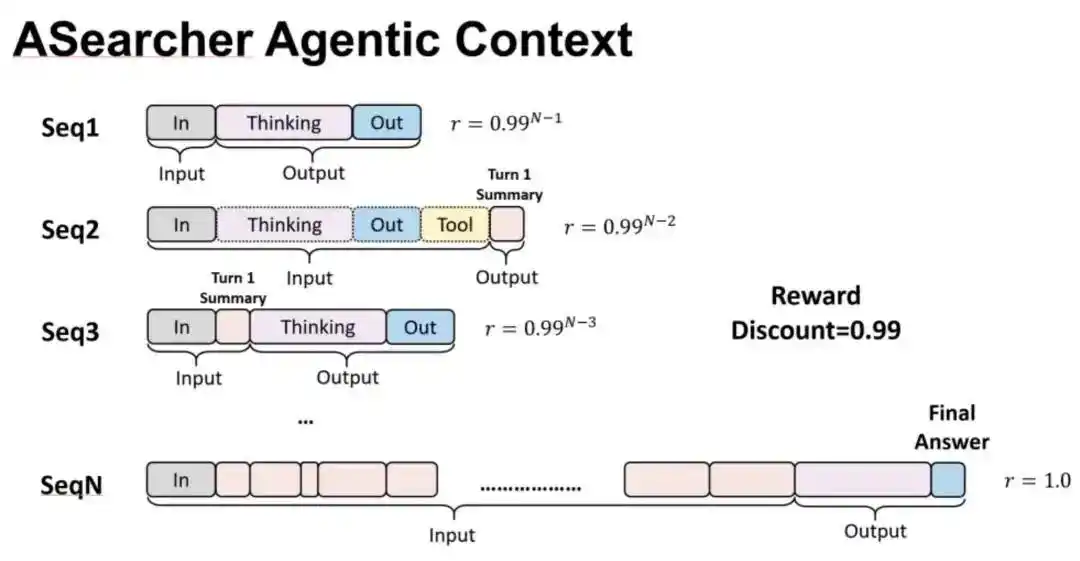
AReaL中的多轮互动应用案例
基于以上架构设计,AReaL支持任何Agent框架的训练——无论是OpenClaw还是你自己搭建的Agent,只需将API地址指向AReaL的代理网关,就可以自动接入强化学习训练。
开发者无需改动现有Agent的代码或业务逻辑,就能启动RL训练流程。这意味着,原本分散的Agent接口被整合成了一层标准化的协议级RL入口,让「任何Agent都能训练」首次在工程上真正可行。
然而,同一个prompt可能会生成多条不同的轨迹(比如多次采样),而且每条轨迹也会被AReaL拆分成多条独立的输入输出。一个批次的数据之间往往会有大量共享前缀。传统的训练方式对每条轨迹独立计算,导致了大量冗余的计算。
为了解决这个问题,AReaL引入了基于Trie(前缀树)的序列打包方案:
构建Trie结构:将共享前缀的序列压缩到同一个树结构中。
树状注意力计算:AReaL-DTA方法实现了完整的树状注意力前向和反向计算方案,让共享前缀只需计算一次。
AReaL的树状注意力带来了显著的性能提升:单Worker训练的吞吐量最高提升8.31倍,集群整体吞吐量最高提升6.20倍,相较于基线方案减少了超过50%的GPU显存占用。
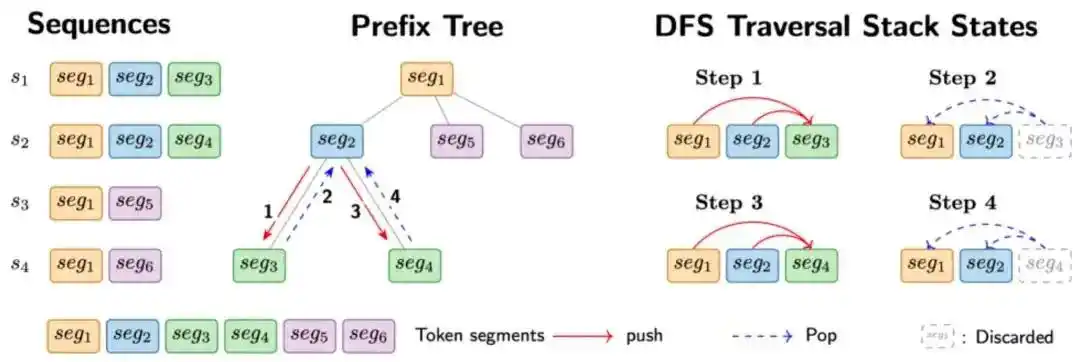
这是关于Agentic RL训练中树状注意力的实现图,详细信息可以查看这篇论文:https://arxiv.org/pdf/2602.00482
用 AI 重新构建引擎:AI Infra 的工程模式革新
除了降低Agent RL训练的难度,AReaL v1.0的推出还带来了训练引擎的重大更新。
在大规模的RL训练领域,Megatron-LM可谓是业界的标杆。不过,它的安装依赖于Docker环境,还有复杂的C++编译,代码结构层层嵌套,让人难以调试和扩展。团队一直在思考:是否可以用PyTorch原生API实现同样功能的分布式训练引擎?
答案就是,AReaL团队基于torchtitan深度定制的训练引擎Archon——一个支持完整5D并行(DP、TP、PP、CP、EP)的PyTorch原生训练引擎:
数据并行 (DP):基于FSDP2 fully_shard,进一步细分了模型参数,相较于Megatron默认的数据并行。
流水线并行 (PP):利用torch.distributed.pipelining,支持ZeroBublePipeline、1F1B、Interleaved1F1B等调度方式。
张量并行 (TP):基于DTensor,采用ColwiseParallel / RowwiseParallel来切分权重。
上下文并行 (CP):依靠Ulysses Sequence Parallelism,使用all-to-all来分布处理长序列。
专家并行 (EP):基于all-to-all + grouped_mm,支持EP + ETP的2D分片。
令人瞩目的是,这个复杂的分布式系统,从零开始到验证正确性,仅花费了1人・月的时间——在32天内,通过修改72万行代码,成功实现了Archon引擎,并验证其能够训练千亿参数的MoE模型。
这一效率奇迹的背后,是AReaL集成的一整套AI辅助开发系统,大幅提升了复杂工程开发的自动化程度。
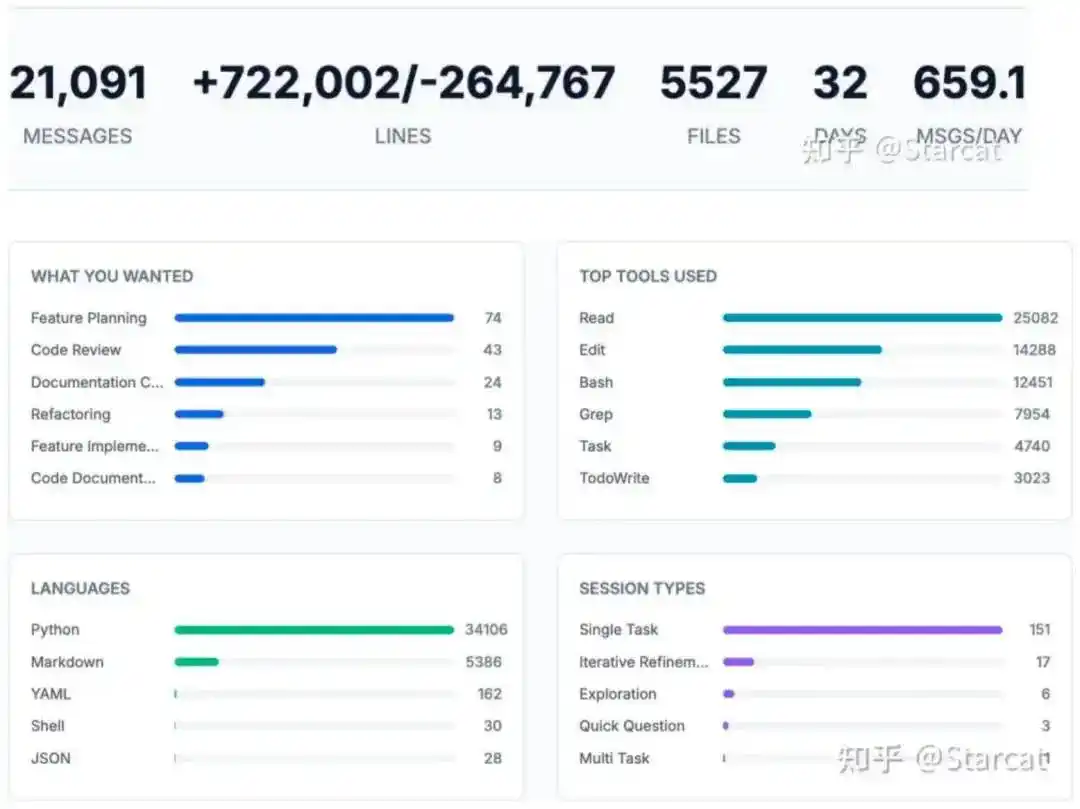
基于AI编程的Archon引擎代码修改统计,
这些掌握AI编程的「秘籍」全部开源,任何开发者都能借助「专业团队」,在AReaL中加速自己的Agent RL应用开发:
首先,为AReaL的每个核心模块配备领域专家Agents,使它们具备模块级架构的理解,同时在代码修改时提供相关的精准指导。
其次,采用命令驱动的引导式工作流程,通过简单的一句话指令,将常见的开发任务流程化和标准化,让开发模式从「手动实现」转变为「声明需求」,让AI自动完成软件工程中那些繁琐且耗时的运维工作。
最后,在真实的开发场景中,AReaL提供的特定Agent可以全程自动化完成任务规划、代码生成、自动校验到PR创建的工作。
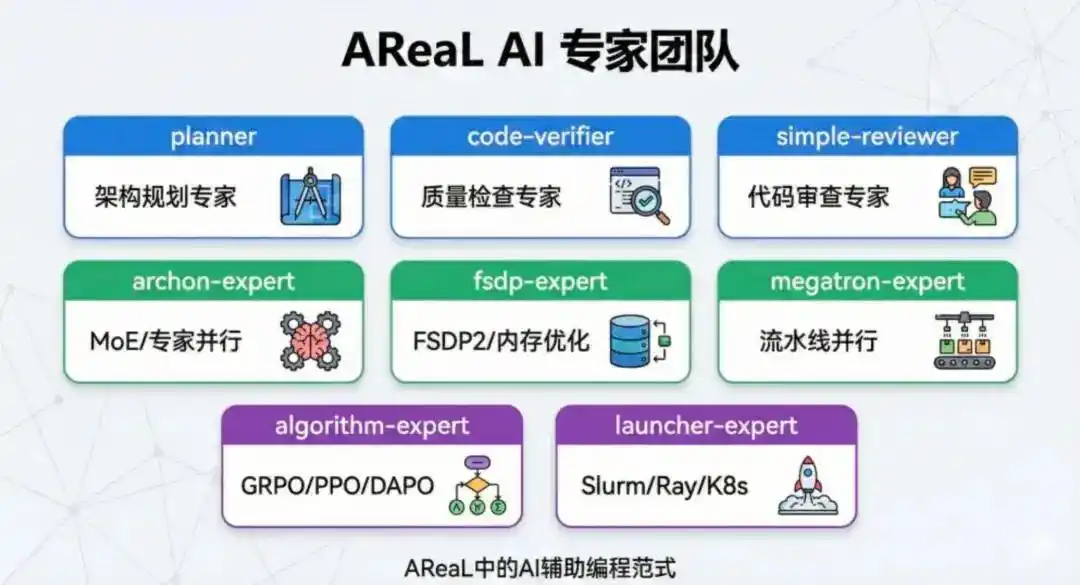
AReaL AI Coding Sub-Agents(图片由AI辅助生成)
这套AI辅助开发体系不仅加速了Archon引擎的落地,还传达了一个明确的信号:AI辅助编程不仅仅是效率工具,它具备真正参与复杂系统开发的能力。这一「用AI造AI工具」的工程实践,重新定义了效率的边界。
相应的,软件工程中的角色分工也在深刻变化,开发者无需再把大量时间花费在具体实现和重复性细节上,而是可以更多地专注于「明确需求、设计系统」等决策性工作。AI则可以处理那些流程固定、规则明确的工程落实任务。
在这种模式变革下,以往重视工程和经验的Agentic RL有望随着开发门槛的降低,吸引更多的开发者参与。
总结
如果说在过去一两年,行业的重点在于教Agent「如何执行任务」,通过更好的工具调用、复杂的工作流编排和精细的prompt工程,让Agent一步步完成任务。那么在接下来的阶段,「如何让Agent自我进化」将成为重中之重。
正因如此,以RL为代表的系统化训练,从过去的加分项逐渐演变为决定Agent能力上限的关键因素。
在这样的转折点上,AReaL v1.0为行业提供了一个兼具易用性、可靠性和强扩展性的开源Agentic RL模板:应用层保持开放和兼容,轻松接入不同的Agent框架;引擎层经过深度优化,极大提高了训练效率和资源利用率。
未来,AReaL团队将继续在系统组件的可用性、Archon引擎的生产效率、AI辅助开发能力以及VLM/Omni模型Agent训练等四个方向上发力,最终目标是打造Agentic AI时代的高性能RL运行时基础。
让AI变得更亲民,开发变得更简单
想象一下,如果训练框架足够简单,Agent的接入方式也变得统一,再加上AI能够深入帮助底层系统的开发,那么Agentic RL就不再是少数顶尖团队的专属,而是能被更多开发者广泛使用的利器。这其实就是“技术民主化”的真谛。
随着这些高效基础设施的不断成熟,Agent很可能会迅速突破初步Demo阶段,真正迎来一个持续、自主和规模化演进的新纪元。










建议在使用时关注训练参数的调整,不同的任务可能需要不同的配置才能达到最佳效果。
之前用过类似的框架,调试过程挺麻烦的,希望AReaL能更简化开发流程。
这次的进展让我想起以前学习强化学习的艰辛,希望AReaL能让更多人受益。
强化学习的挑战真不少,AReaL这么一来,期待能有更好的突破!
有点好奇,AReaL和其他框架相比,有什么独特之处吗?
在这么多代理中,AReaL会不会在使用上有额外的隐患呢?
看到AReaL的进展让我想到了开发的乐趣,希望更多人能参与进来,分享自己的经验!
AReaL v1.0的零代码接入真的很赞,省去了不少麻烦!
AReaL的进步让我想起了以前学习强化学习的艰辛,是否有更简单的学习资源推荐?
刚接触这些代理技术,AReaL的零代码接入让我有种豁然开朗的感觉,期待接下来能有更多实践经验分享。
一键接入的想法很不错,能帮助更多人入门!
AReaL的设计理念很有前瞻性,是否会考虑增加更多的学习资源和文档呢?
看到AReaL的介绍,感觉这个框架真是为开发者减轻了负担,未来的应用会不会更多?
AReaL的进步让人振奋,是否会有更多的开源项目跟上这个趋势呢?
AReaL的零代码接入真是个好消息,方便了不少新手,值得一试!
零代码接入的确是一个大进步,是否会有更多开发者因此加入到代理领域中?
AReaL v1.0的发布真是太赞了,特别是零代码接入的设计,简直是开发者的福音!
看到AReaL的发布,让我想起了以前做项目时遇到的种种麻烦,真希望早些有这样的工具!
在使用AReaL时,是否需要特别注意系统兼容性?
AReaL的设计理念好先进,真的能让代理领域迎来一波创新吗?
AReaL v1.0的零代码接入确实让人眼前一亮,想知道这个功能是否真的适合所有代理框架?
这个框架的发布让我想起了以前的复杂流程,有没有人愿意分享一下使用经验?