
简单来说,核心思路就是给 AI 提供必要的上下文信息,省去那些多余的内容和细节,这样能更有效地使用 Token。
## 一、核心原则:提供「最小必要」的上下文
AI 的 Token 消耗主要是由输入的上下文 Token 和输出的响应 Token 组成,优化的关键就在于只提供 AI 真正需要的信息。
### 1. 精准选择代码,避免全盘提交
– ❌ 错误做法:直接让 AI 「看这个文件」或「优化我的项目」,然后贴上几百行无关的代码,像注释和测试用例等。
– ✅ 正确做法:
– 仅选中「有问题或需要修改的代码块」,比如出错的函数或待优化的逻辑,而不是整个文件。
– 如果需要依赖其他代码,尽量只贴出「最小依赖片段」,如只给函数签名,而不是完整实现。
– 举个例子:假设你要修复登录接口的参数校验逻辑,只需选中与校验相关的10行代码,而不是整个登录控制器文件。
### 2. 主动去掉冗余信息
– 删除注释:AI 很懂代码逻辑,去掉那些多余的中文注释和调试注释(比如 `// 这里是循环` `// TODO 后续优化`)。
– 清理空行和格式化:简化代码格式,去掉多余的空行和不必要的缩进(Cursor 自带格式化功能,可以先整理再提交)。
– 删掉无关代码:包括注释掉的废弃代码、临时调试代码(比如批量删除 `console.log`)、未用到的变量或函数。
### 3. 合并重复提问,避免碎片化
– ❌ 错误做法:分三次提问「优化函数?」「加异常处理?」「简化参数?」—— 这样反复消耗上下文 Token。
– ✅ 正确做法:一次性提问涵盖所有需求,比如:「优化下面的用户查询函数:1. 减少数据库查询次数;2. 增加参数合法性校验;3. 捕获查询异常并返回统一错误格式」。
## 二、提问技巧:明确需求,减少 AI 的「猜测」
提问不清晰会导致 AI 输出冗长的回应,浪费 Token,清楚的需求能让 AI 更快进入正题。
### 1. 结构化提问:指令+范围+约束
– 指令:明确你想要的动作,比如修复、优化、解释或生成。
– 范围:限制作用域,比如「只优化循环逻辑」或「针对手机号校验」。
– 约束:规定输出格式、长度和技术栈限制(例如「输出精简代码,不写注释」「用 ES6 语法,不引入第三方库」)。
– ❌ 模糊提问:「这个代码有问题吗?」
– ✅ 精确提问:「检查下面的手机号正则校验逻辑,修复匹配 177 号段失败的问题,只输出修改后的代码片段,不额外解释」。
### 2. 直接说明背景,减少 AI 的分析成本
– 不要让 AI 自己去分析代码「是什么意思」,直接说明核心背景(场景+问题),例如:「下面是 Vue 3 组件的表单提交函数,点击提交后未触发接口请求(控制台无报错),请排查并修复,只输出修改后的函数」。
### 3. 限定输出格式,避免冗余回应
– 清楚要求「只输出代码」「只给关键步骤」「不写解释」,避免 AI 输出长篇文字说明,例如:「用 Python 实现列表去重函数:1. 保留原顺序;2. 时间复杂度 O(n),只输出函数代码,无注释无解释」。
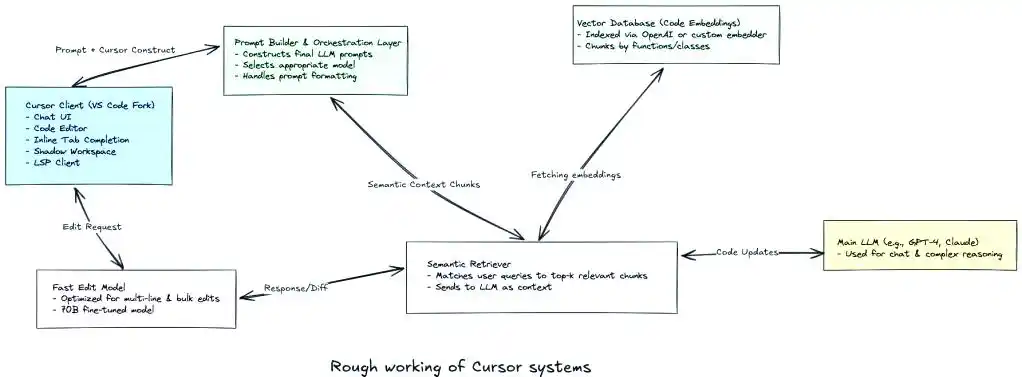
## 三、工具特性:充分利用 Cursor 的内置功能省 Token
Cursor 自带「精简上下文」的功能,无需手动修改,能高效节省 Token。
### 1. 使用「Code Lenses」精准定位
– 当鼠标悬停在函数或类上时,会出现「Explain」「Refactor」「Debug」等按钮,点击后自动聚焦该代码块,避免手动选择时误选多余代码。
### 2. 开启「上下文压缩」(Cursor 特有)
– 路径:Settings → Cursor AI → 开启「Context Compression」(上下文压缩)。
– 功能:自动去掉注释、空行和未使用的代码,只保留核心逻辑传给 AI,从而减少 Token 消耗(不会影响本地代码)。
### 3. 用「Inline Chat」进行小范围交互
– 选中少量代码(1-3行),右键选择「Cursor: Inline Chat」,可以在代码旁直接提问。
– 适用场景:语法纠错、简单优化等小修改,这样上下文范围最小,Token 消耗最低。
### 4. 关闭「自动加载依赖」(按需)
– 如果 AI 自动加载了太多无关的依赖(比如未使用的库、其他文件的代码),可以在聊天框输入「只使用当前选中的代码,不加载其他依赖」,手动限制上下文的范围。
## 四、进阶技巧:培养省 Token 的长期习惯
### 1. 分阶段处理大需求
– 在重构大模块(几百行代码)时,避免一次性提交:
– 阶段 1:先贴上「核心问题代码」(20行以内),让 AI 给出精简优化建议。
– 阶段 2:按照思路分模块(先优化查询逻辑,再优化缓存逻辑)逐一提交,避免上下文负担过重。
### 2. 复用上下文,避免重复粘贴代码
– 在同一轮对话中,可以基于之前的代码继续修改,无需重新粘贴代码,只需说「继续优化刚才的函数,增加缓存逻辑」即可(AI 会保留历史上下文)。
– 如果对话过长(历史上下文 Token 累积过多),可以新建对话,只粘贴「必要的历史代码片段」(比如之前修改后的核心函数),而不是全部历史记录。
### 3. 使用「占位符」替代冗余细节
– 当代码中有大量静态数据(配置项、测试数据)时,可以用占位符替代:
– ❌ 贴完整配置:`const config = { appId: ‘123456’, secret: ‘abcdefg’, … }`(几十行)
– ✅ 用占位符:`const config = { /* 应用配置,包含 appId 和 secret */ }`(AI 不需要知道具体值)。
## 五、避坑指南:这些行为最浪费 Token
1. 把「整个项目/文件夹」贴给 AI 让其「全局分析」—— 90% 代码是无关的,Token 消耗直接飙升。
2. 提问时带上大段「需求背景故事」(例如「我昨天在做功能时遇到问题,查了很多资料…」)—— 只需保留「需求+问题+代码」,删去多余内容。
3. 要求 AI 输出「详细文档+完整注释+多种方案」—— 非必要时,直接要求「只给最优方案+精简代码」。
4. 重复提交相同的代码(比如忘记选中,多次粘贴同一文件)—— 提交前预览聊天框「输入上下文」,确保没有冗余再提交。
## 总结
节省 Token 的关键在于「做减法」:**减少输入上下文的冗余,明确输出需求的边界**。建议优先使用「精确选择代码+结构化提问+Cursor 的内置压缩功能」,并养成长期习惯,以提升 Token 的使用效率超过 50%,避免频繁充值。
在特定场景下(如重构、调试、生成代码)可进一步细分:生成代码时用「模板+约束」,调试时仅贴「报错信息+相关代码」,按需优化会更高效。






学习了如何优化 Token 使用,特别是精简代码与提问技巧的部分,确实能提高效率,期待实践中能有效减少冗余信息。
掌握省 Token 的技巧确实很实用,特别是通过提供最小必要的上下文来提升 AI 的响应效率,这样能节省不少时间。
提供最小必要的上下文真的很重要,这样不仅能节省 Token,还能让 AI 更快理解问题,期待以后能更高效地使用这些技巧。
学习了省 Token 的技巧,特别是如何选择必要的代码和提问方式,确实能帮助我更高效地使用 AI,期待今后能灵活运用这些方法。
文章中的提问技巧十分实用,尤其是结构化提问能大幅提升 AI 的响应效率,明白了如何清晰地表达需求,省去了很多不必要的 Token 消耗。
很赞同文章中提到的主动去掉冗余信息,清理注释和无关代码确实能让 AI 更快理解需求,省去不必要的 Token 消耗。