Cursor的实现原理初探
概述
Cursor可是AI代码编辑器中的佼佼者哦!最近在http://newsletter.pragmaticengineer.com上,有篇文章专门采访了Cursor的开发者,聊了聊他们的实现原理。接下来,我给大家总结一下这篇文章的精华内容。
Cursor的设计理念
我们觉得一定要有自己的编辑器,而不是简单地当个扩展工具,因为我们想要改变大家的编程习惯。换句话说,我们要么从头开始打造一个全新的IDE,要么就直接对一个现有的编辑器进行改造。
我们的目标不是要做一个特别稳定的编辑器,而是希望逐步改变开发者的工作方式。
Cursor使用的技术栈
后端技术
- TypeScript:大部分的业务逻辑都是用这个写的。
- Rust:所有对性能要求高的组件都使用这门语言,比如接下来会提到的Orchestrator。
- Node API与Rust的结合:大部分的逻辑用TypeScript,而性能密集的部分用Rust,通过Node.js实现两者之间的调用。比如索引逻辑就是一个使用Rust的例子。
- 单体架构:后端服务主要是一个大型的单体架构,整体部署。这让我们意识到,单体架构在初创公司中非常有效,能帮助团队快速壮大。
数据库
- Turbopuffer:一个多租户数据库,用于存储加密文件和工作区的Merkle树,后面会详细讲解。这个数据库受欢迎的原因在于它的可扩展性,不用再像以前那样处理数据库分片的复杂问题。相关挑战将在接下来的“工程挑战”部分中讨论。
- Pinecone:用于存储文档嵌入内容的向量数据库。
流数据处理
- Warpstream:与Apache Kafka相兼容的数据流服务。
工具使用
- Datadog:用于日志记录和监控。Sualeh提到,他们是Datadog的重度用户,觉得它的开发者体验优于其他同类产品。
- PagerDuty:用于值班管理,并且与Slack集成。
- Slack:内部的通讯和聊天工具。
- Sentry:用于监控错误。
- Amplitude:用于数据分析。
- Stripe:用于Cursor的计费和付款。
- WorkOS:用于Cursor的身份验证,比如用GitHub或Google Workspace登录。
- Vercel:http://Cusor.com的网站托管平台。
- Linear:用于工作管理。
大部分的CPU基础设施都运行在AWS上,还有数万块NVIDIA H100 GPU,其中很大一部分是在Azure上使用的。
推理是Cursor最大的一块GPU应用,主要用于生成下一个token,无论是自动补全还是完整的代码块。实际上,Azure的GPU仅用于推理,不涉及LLM的微调和模型训练。
Cursor使用Terraform来管理像GPU和虚拟机(例如EC2实例)这样的基础设施。
Cursor自动补全的工作机制
想了解构建Cursor过程中遇到的技术挑战,我们先来看看启动编辑器时发生了什么。
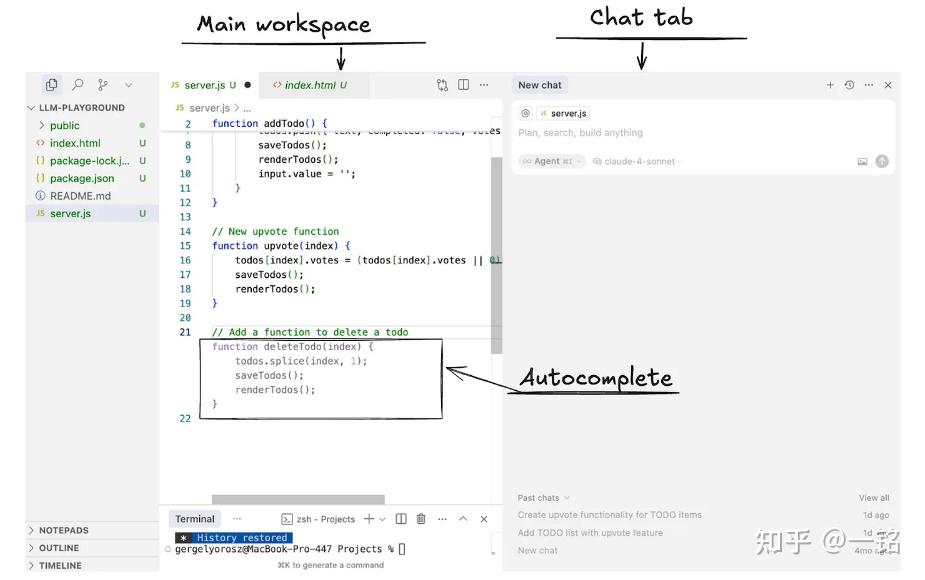
低延迟同步引擎:自动补全建议
当你打开项目或文件夹的时候,往往会直接开始编辑文件。这就意味着Cursor需要提供自动补全建议,团队称之为“tab建议”。这个过程是由低延迟同步引擎驱动的“tab模型”来实现的。它会生成一些灰色的建议,你只需点击“Tab”键就可以接受。这些建议的生成速度要快,理想情况下不超过一秒。下面是它的工作原理:
自动补全的步骤如下:
- 客户端本地收集当前上下文窗口(代码)的一小部分。
- 这些代码会被加密。
- 加密后的代码和上下文会发送到后端。
- 后端对代码和上下文进行解密。
- 使用Cursor内部的LLM模型生成建议。
- 补全建议返回给客户端。
- IDE显示建议,点击“Tab”键接受。
- …这个过程会不断重复,以生成下一个建议。
这个“tab模型”需要尽可能快,同时还要控制数据传输量。发送的上下文信息量和建议的质量之间总是有个平衡:发送的相关上下文越多,建议就越精准,但如果发送太多信息,建议的显示速度就会降低。因此,如何在这两者之间找到最佳的处理方式,确实是Cursor工程师面临的一个挑战。
Cursor的聊天功能如何在不存储代码的情况下运作
Cursor还有聊天模式,可以用来查询代码库、与代码库“对话”,或者让Cursor执行一些操作,比如启动代理进行重构或添加功能等。后端并不保存任何源代码,所有的LLM操作都是在这里完成的,依靠代码库索引来管理这些操作。具体工作流程如下:
在聊天模式下提问:假设我们要问代码库中在server.js定义的createTodo()方法。为了让问题更复杂一些,我还在index.html中定义了一个类似的方法,叫addTodo()。接下来看看Cursor是怎么处理的!
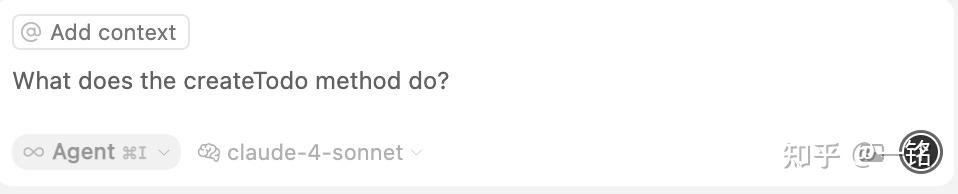
这个提示词会被发送到Cursor的服务器,系统会对其进行分析,然后决定需要在代码库中进行搜索:

搜索过程开始:

代码库索引的搜索过程。这里的“代码库索引”其实就是之前做好的嵌入(embedding)。它会通过向量搜索来找到最符合上下文的嵌入。在这个实例中,向量搜索给出了两个非常相似的结果,分别来自 server.js 和 index.html。
客户端如何请求代码:服务器上并不保存源代码,但它会从 server.js 和 index.html 中请求源代码,接着分析这两者,找出最相关的一个:

最终,经过向量搜索和对相关源代码的请求后,服务器得到了回答问题所需的上下文信息:

Cursor 在后台做了不少工作,确保这些搜索能够顺利进行。
用代码块进行语义索引(Semantic indexing with code chunks)
为了像上面那样利用嵌入进行向量搜索,Cursor 首先要把代码分成更小的块,生成嵌入,并把这些嵌入存储在服务器上。具体步骤如下:
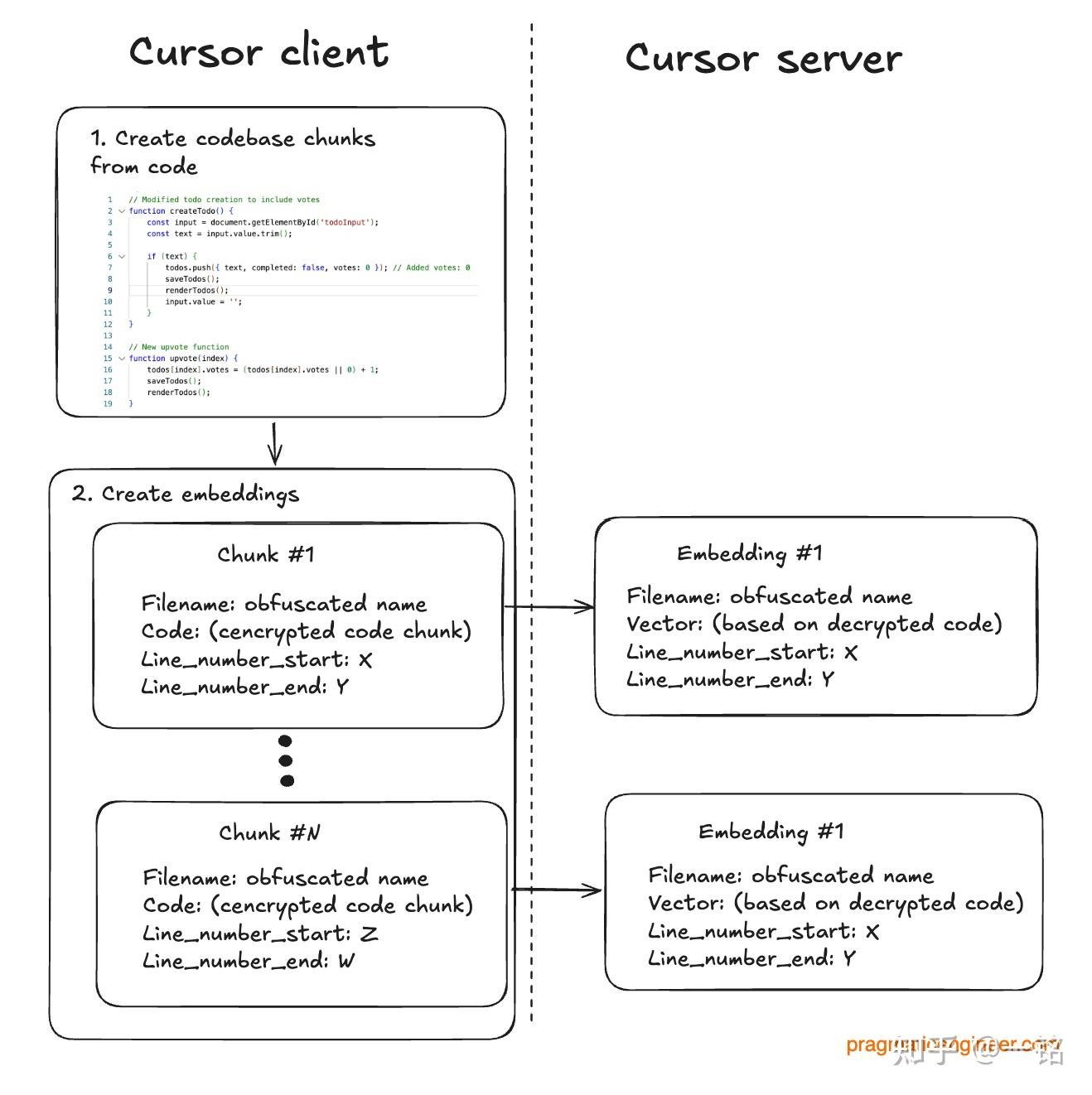
- 生成代码块。Cursor 会把文件内容切分成更小的部分,每一部分都会被创建成一个嵌入。
- 生成嵌入时不存储文件名或代码。Cursor 甚至不想把文件名放在服务器上,因为这可能被认为是敏感信息。相反,它会将混淆后的文件名和加密的代码块发送到服务器。接着,服务器会解密这些代码,利用 OpenAI 的嵌入模型(或它们自己的模型)来生成嵌入,并将其存放在向量数据库 Turbopuffer 中。
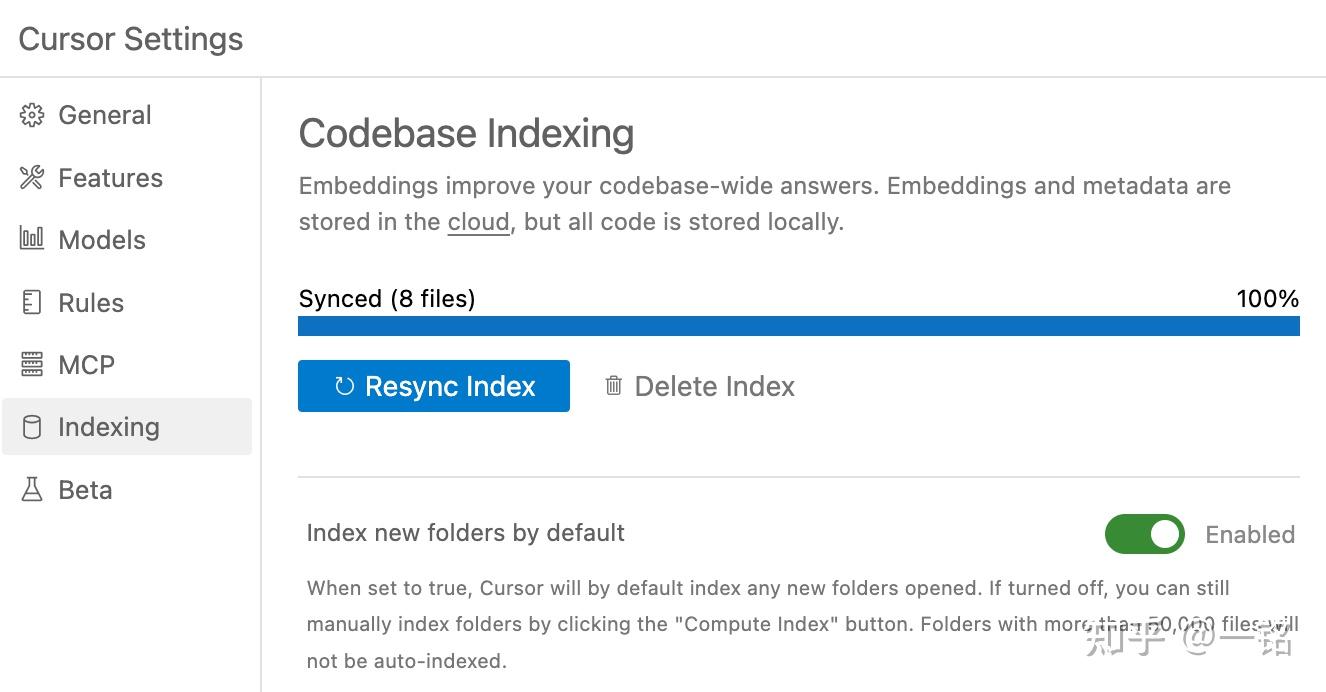
生成嵌入的计算成本是很高的,这也是 Cursor 后端为何使用云端 GPU 的原因之一。对于中型代码库,索引一般不超过一分钟;但如果是大型代码库,可能会需要几分钟甚至更久。你可以在 Cursor 的“Cursor 设置”→“索引”中查看索引的状态:
利用 Merkle 树保持索引最新(Keeping the index up-to-date using Merkle trees)
当你使用 Cursor 或其他 IDE 编辑代码库时,Cursor 服务器的索引可能会过期。一个简单的解决办法是每隔几分钟就重新索引一次。不过,由于重新索引的计算成本很高,而且会占用带宽,所以这种方法并不太理想。Cursor 聪明地利用了 Merkle 树和高延迟同步引擎(每 3 分钟运行一次)来确保服务器索引保持更新。Merkle 树 是一种树结构,其中每个叶子节点都对应底层文件的加密哈希值(比如 main.js 文件的哈希值),而每个节点则是其子节点哈希值的组合。这里有一个包含四个文件的简单项目的 Merkle 树示意:
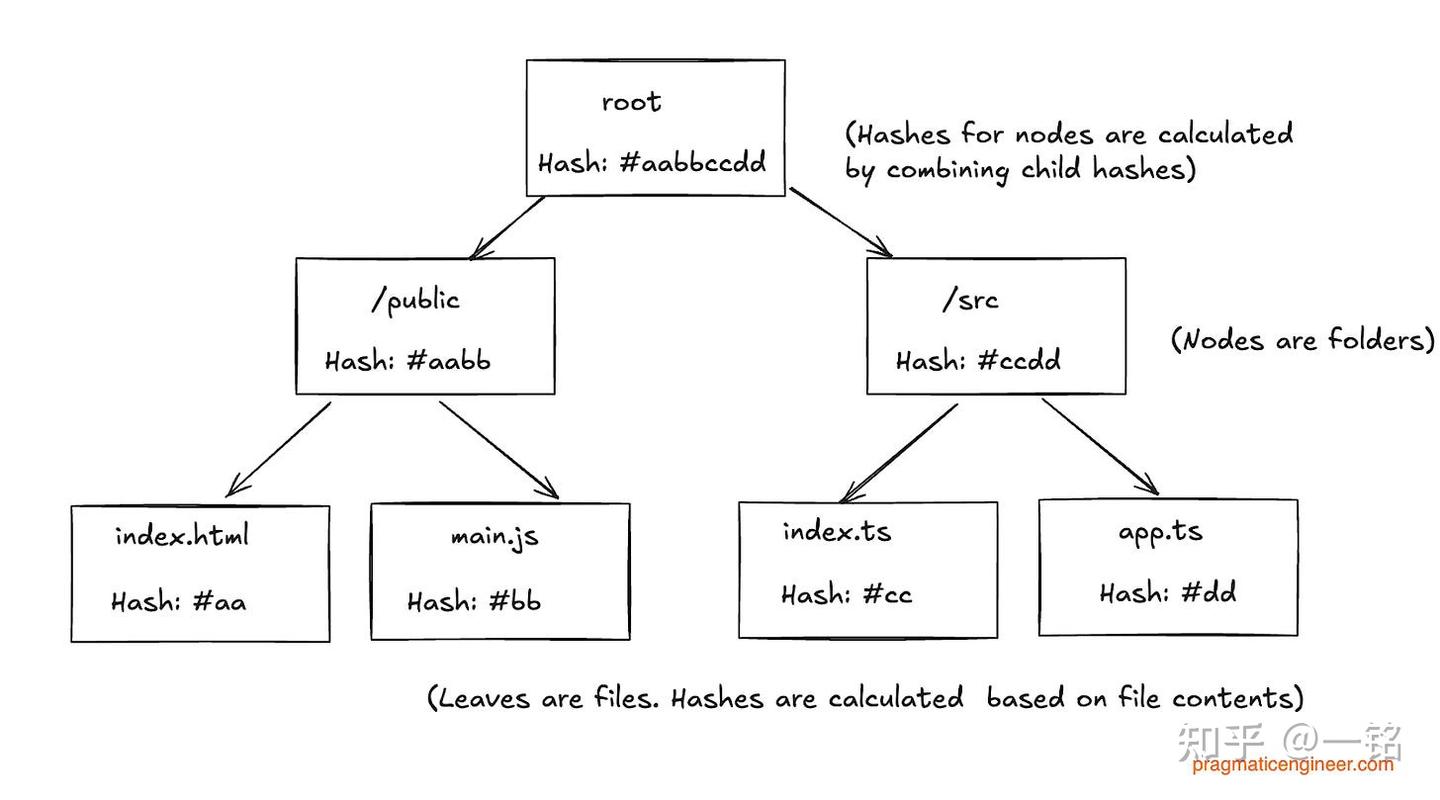
这是基于代码库中代码构建的 Merkle 树
Merkle 树的工作原理是:
- 每个文件会生成一个根据内容得出的哈希值,树的叶子节点就是这些文件。
- 每个文件夹会根据其子文件或文件夹的哈希值生成一个哈希值。
Cursor 使用的 Merkle 树大致相似,只不过它用的是混淆的文件名。Cursor 客户端会根据本地文件生成 Merkle 树,服务器也会根据已完成索引的文件生成 Merkle 树。这意味着客户端和服务器各自都会保存自己的 Merkle 树。
Cursor 每 3 分钟进行一次索引同步。为了确定哪些文件需要重新索引,它会比较两棵 Merkle 树:一棵在客户端,作为真实数据的来源;另一棵在服务器,作为索引的状态。以客户端“index.html”的修改为例:
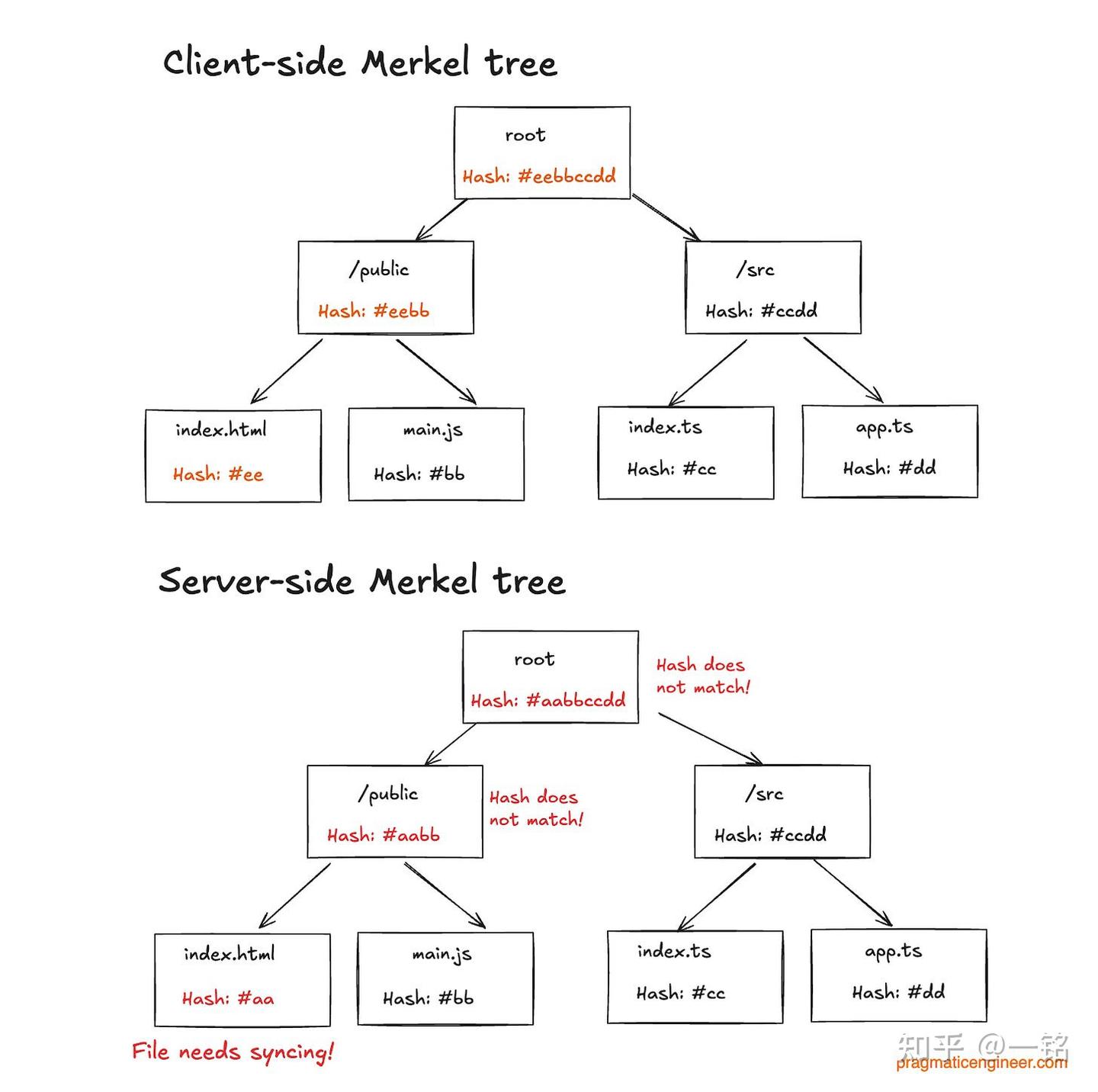
客户端和服务器的 Merkle 树不同步。Cursor 使用混淆的文件名,以上的实际文件名仅为简化示例
树形遍历帮助找出需要重新索引的地方。我们开发者通常不太会实现树形遍历,但在这种情况下,Cursor 的工程师不得不这么做。Merkle 树使得树形遍历变得更加高效,因为从根节点开始,可以轻松判断哈希值是否相匹配。如果有差异,能够迅速定位需要同步的文件。而且,Merkle 树还优化了同步操作,只同步那些变化过的文件。
这种 Merkle 树结构非常适合 Cursor 的实际运用场景。比如,常见的情况是一天工作结束后关机,第二天再从 git 仓库获取更新,早晨再开启新的一天。在团队中,许多文件在第二天早上都会被修改。依靠这棵 Merkle 树,Cursor 能尽可能减少重新索引的次数,从而节省客户端的时间,同时也高效利用服务器的计算资源。
安全索引(Secure indexing)
虽然 Cursor 不会把代码存储在服务器上,但代码库中仍然可能包含一些敏感数据,即使加密后也不应该被发送。敏感数据包括机密信息、API 密钥和密码。
使用 .gitignore 和 .cursorignore 是确保索引安全的最佳方法。机密信息、API 密钥、密码等敏感内容不应该上传到源代码管理,通常会以本地变量形式或添加到 .gitignore 中的本地环境文件(.env 文件)进行存储。Cursor 会尊重 .gitignore 文件,不会索引其中列出的文件,也不会将这些文件的内容发送到服务器。此外,它还提供了一个 .cursorignore 文件,用于添加需要被 Cursor 忽略的文件。
在上传块进行索引之前,Cursor 会扫描代码块,查找可能的秘密或敏感数据,并确保不发送这些信息。
索引非常大的代码库(Indexing very large codebases)
对于那些庞大的代码库(通常是数千万行代码的单一仓库),索引整个代码库是非常耗时的,并且会消耗大量的计算资源,这通常是没有必要的。在这种情况下,使用 .cursorignore 文件是个明智的选择。
参考资料:
https://docs.cursor.com/context/codebase-indexing#working-with-large-monorepos
- https://en.wikipedia.org/wiki/Merkle_tree
- https://developer.hashicorp.com/terraform
- https://www.warpstream.com/
- https://pinecone.io/
- https://turbopuffer.com/
- 点击这里,了解实用工程师的最新资讯
标题:探索实用工程师的最新动态





我觉得Cursor在推理方面的应用非常酷,特别是用GPU生成下一个token的功能,期待看到更多!
对于需要频繁切换工具的开发者来说,Cursor的集成方案是个福音,能否分享一下实际使用中的具体体验?
Cursor的设计理念很有趣,想要改变开发者的工作方式,确实需要勇气和创新。
看到Cursor使用Rust处理性能密集的部分,真心觉得有点高大上,开发者真是用心良苦。
对于初次接触Cursor的开发者,是否有学习资源推荐?这样能帮助更快上手。
使用Terraform管理基础设施的想法很不错,能否分享一下使用体验?
Cursor的设计理念让我联想到以前的编辑器,想要改变习惯确实不容易。开发者加油!
低延迟同步引擎的设计想法挺新颖的,不知道在实际使用中能达到什么效果呢?
Rust作为性能密集部分的选择真心赞同,开发者在后端技术选型上下了很多功夫。
文章中提到的单体架构在初创公司中的有效性让我深有感触,团队快速壮大确实需要这种灵活性。
建议开发者在使用Cursor时,关注其与其他工具的集成,可能会提升工作效率。
用Rust处理高性能部分的做法真的很聪明,想知道在开发中遇到过哪些具体问题?
使用Terraform管理基础设施,感觉挺前卫的,是否真的能提高开发效率呢?
听说Cursor的自动补全能力超强,实际使用中怎么表现呢?
Cursor的自动补全功能是什么样的体验,难道真的能提高工作效率吗?
对Cursor的自动补全功能很期待,希望能在实际项目中验证其效率提升。
建议开发者在使用Cursor时,提前了解其与现有工具的兼容性,避免不必要的麻烦。
在实际使用Cursor时,遇到的性能瓶颈和解决方案也许值得一提,以便其他开发者参考。