执墨,一名在编程界摸爬滚打了四年的开发者,对AI有些了解,热衷于探索有趣的技术和项目,目前还在琢磨怎么培养出一个AI开发的好伙伴。
大家在用AI生成代码时,可能会遇到些让人感到无奈的情况,要么代码位置不对,要么不符合项目要求,最后不得不返工,真是觉得不如自己来。但是别担心,毕竟你已经学习了三四年代码,AI写代码也是需要时间去磨合的。从Zulu公测开始,我就一直在用文心快码,算是积累了些经验。结合我在IntelliJ IDEA中的使用体验,我总结了一些Zulu和Chat的实用小技巧,希望能对大家有所帮助。
一 Zulu 调教指南:生成代码更可用
1 用 # 提供上下文
语言模型的工作原理其实就是根据前面内容来猜测接下来最可能出现的词或代码片段。没有上下文的话,模型就很难准确预测接下来的内容,因此,理解和使用上下文是生成高质量代码的关键。在开发中,上下文不仅仅是当前的文件或代码,还包括项目的结构、依赖关系、函数和变量的作用域等。掌握这些上下文,AI才能更有效地补全代码或生成符合项目风格的内容。
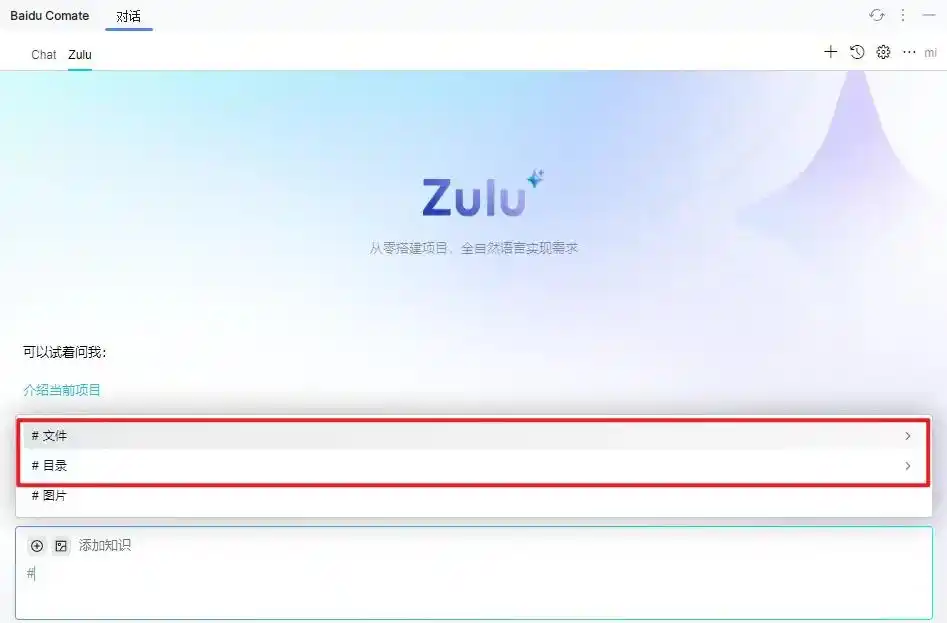
在文心快码中为Zulu添加上下文:Zulu支持文件、文件夹和项目级别的上下文。开发者可以使用 # 操作符唤起当前索引的所有文件,并将其添加到当前会话的上下文中。
-
# 操作符唤起上下文菜单进行编辑
-
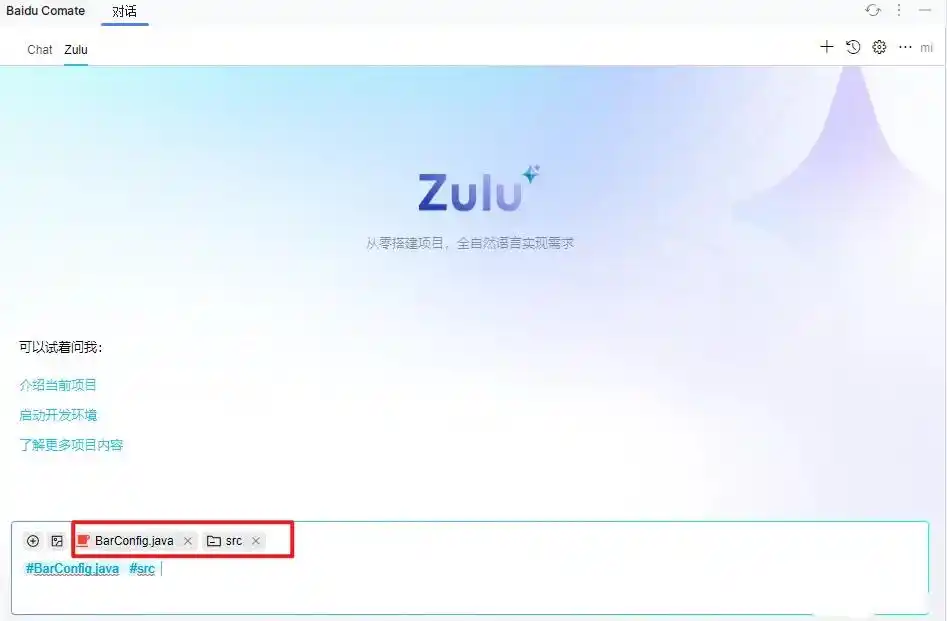
选择相应的文件或目录,可以添加多个,如果没有选择上下文,系统会默认当前项目作为上下文环境。
-
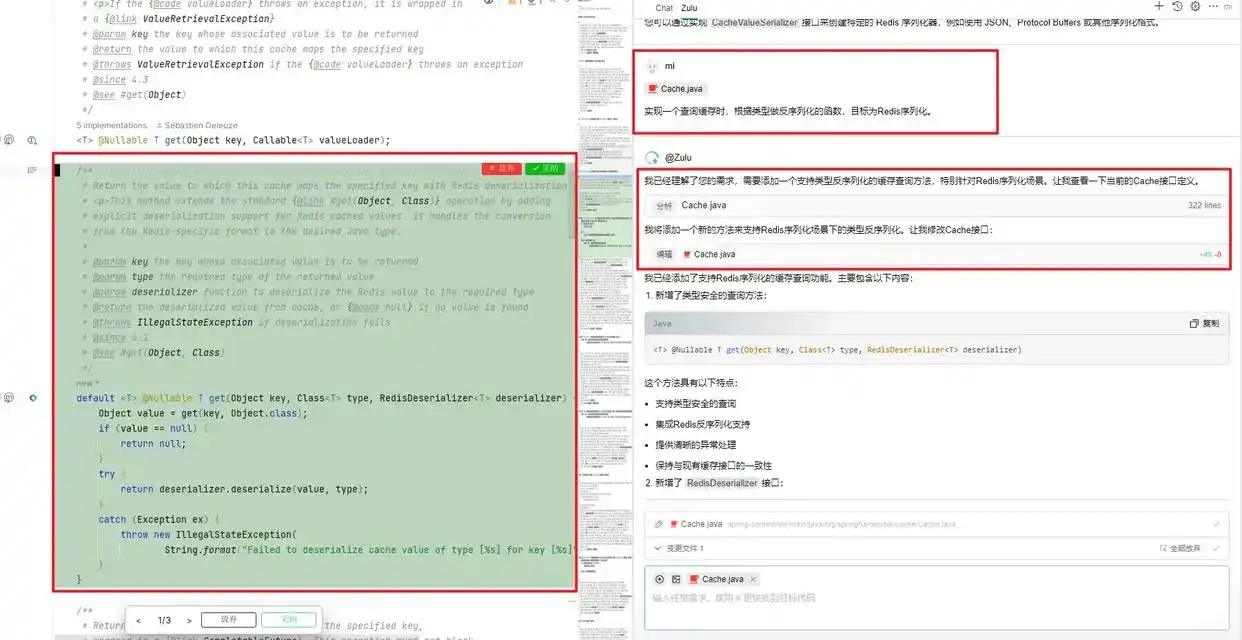
配置好上下文后,可以用自然语言描述你想让AI做的事。例如,我选择了Cache.java这个文件,然后请Zulu“实现一个查询缓存时,根据类型进行反序列化的函数,目标是Redis序列化”。这时,Zulu就开始读取上下文,立刻明白了我的需求,在Cache接口中进行修改,添加了我想要的功能。
2 善用命令自动执行
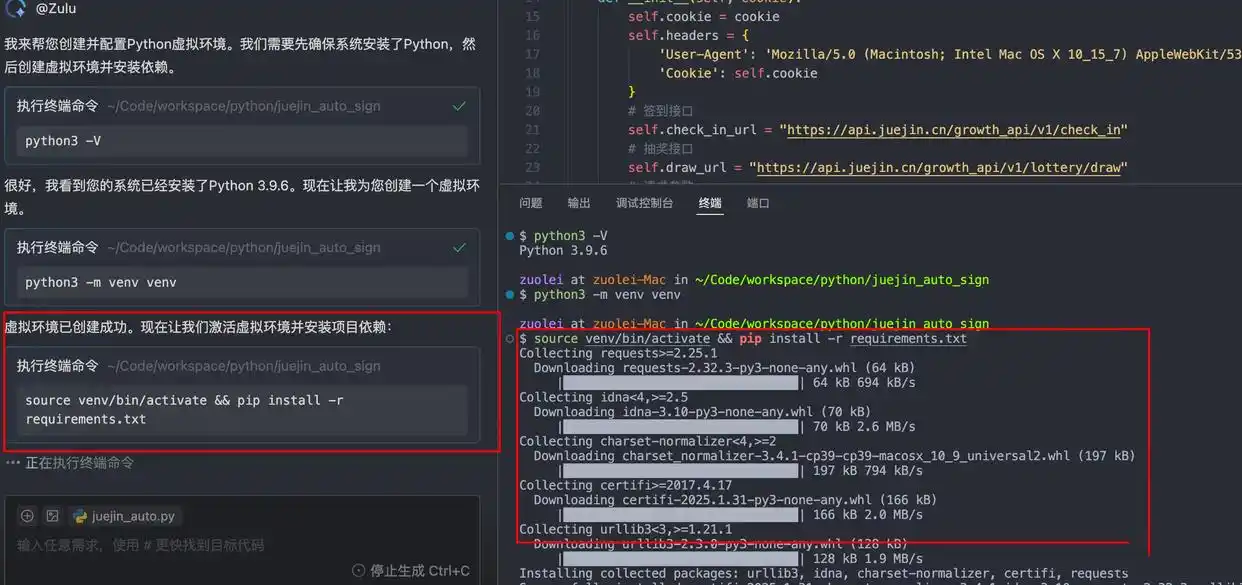
Zulu能自动感知当前项目的框架、技术栈、文件结构和运行环境,按照需求自动生成终端命令,然后把这些命令发送到开发环境中的终端执行。这种能力在脚本语言的开发过程中,尤其是Python、JS等语言中,非常有用。你根本不用操心框架要怎么用,AI会自己处理,开发者可以更专注于业务逻辑的实现。
比如在创建和配置Python虚拟环境时,Zulu首先执行了终端命令python3 -V,查看当前环境中的Python版本,然后生成命令python3 -m venv venv创建虚拟环境,最后通过source venv/bin/activate && pip install -r requirements.txt激活虚拟环境并安装项目依赖。整个过程都在IDE内部完成,保持了开发流程的连贯性。
3 规则约束
如果没有提供规则文件来约束Zulu的生成行为,在新项目开发时很容易生成一些意料之外的代码,甚至会出现魔改代码的情况。了解到文心快码支持自定义规则,我为Zulu编写了执行的上下文约束,以控制其代码生成。接下来我将详细讲述我的规则编写思路。
3.1 编码环境
介绍当前的编码环境,说明项目所用的技术栈。这一步非常重要,简直就是给Zulu描绘了一幅项目的蓝图,让它明白自己所在的“战场”环境。例如在一个基于Java的Spring Boot项目中,我明确告诉Zulu项目使用的语言是Java,以及涉及的Spring、Spring Boot、Spring Security等相关技术框架。这样,Zulu在生成代码时,就能遵循这些技术栈的规范,生成合适的代码。
## 编码环境用户询问以下编程语言相关的问题:- Java- Spring&SpringBoot&SpringSecurity- MyBatis&MybatisPlus- RocketMq- Nacos- Maven- SpringSecurity
3.2 代码实现指南
这个部分包括当前项目具体的代码实现,比如数据库表创建规范、用户上下文获取方式、项目结构的含义等。这就像是给Zulu制定了一套详细的工作流程,让它生成的代码符合项目的特定要求。在采用DDD(领域驱动设计)方式实现代码的项目中,我为Zulu提供了这样的工作流程。
1. 项目使用 DDD 的方式来实现代码,你需要注意如下几点: 1. 领域层和仓库层的入参都要使用 DO、仓库层的实体对象需要添加 PO 的后缀 2. Application或者Service层的输出必须的 DTO,接口层的返回可以是 DTO 也可以自己定义 VO 3. 每一层对应的对象都需要添加对应的后缀,并且后缀要全大写。如仓库层的实体 UserPO,领域层领域 UserDO,应用层的DTO UserDTO 4. 项目的类之间的转换需要使用 MapStruct 来完成2. 在使用三方依赖的时候,需要将对应的依赖内容先添加到 Maven 依赖中3. 所有的接口都按照 RestFul 的风格定义,并且你需要区分接口的使用场景,如:前端使用、OpenApi、小程序端使用。 1. 如果你无法通过用户的上下文知道需要你生成的接口的使用场景,你可以再次询问用户 2. 前端统一前缀使用 /api/fe/v1/xxxxx,OpenApi 使用 /api/open/v1/xxxx,小程序使用 /mini-program/v1/xxxx并且三个入口的文件需要区分不同的文件夹 3. 对于批量查询接口,你需要涉及分页的能力,不能使用内存分页,只能在 DB 层面做分页,并且要考虑深分页的问题 4. 所有的接口返回需要返回 BaseResp 对象,BaseResp 的定义如下: @Data public class BaseResp { private String code; private String message; private T data; } 4. 对于应用层,需要注意如下几点: 1. 函数的输入和输出都是 DTO
3.3 总结历史记录
每次用Zulu生成代码之后,可以让它帮我们将每次查询的结果总结并记录到文件中,这对项目的跟踪和回溯非常有帮助。提示词如下:
## 历史记录1. 针对你回答用户问题的答案,你需要将本次回答的内容记录到项目的根路径下的 .cursor-history 文件里,格式如下:2025-11-11 10:10:10变更内容如下:1. 增加用户模块2. 修改用户管理内容3. 增加用户内容涉及文件为:xxxx.javaxxxx.java2. 你需要按照倒序的方式记录这个历史纪录
这种详细记录的格式,能清晰地显示每次代码生成的时间、变更内容以及相关文件,方便开发者随时查看和追溯项目开发的记录。而且,倒序记录能让最新的变更出现在前面,开发者快速掌握最新动态,提高信息查找的效率。
二 Chat 隐藏技巧:编码交互更灵活
在研究Zulu的同时,我也发现了Chat功能很实用,下面想分享一些让编码过程更加方便的技巧。
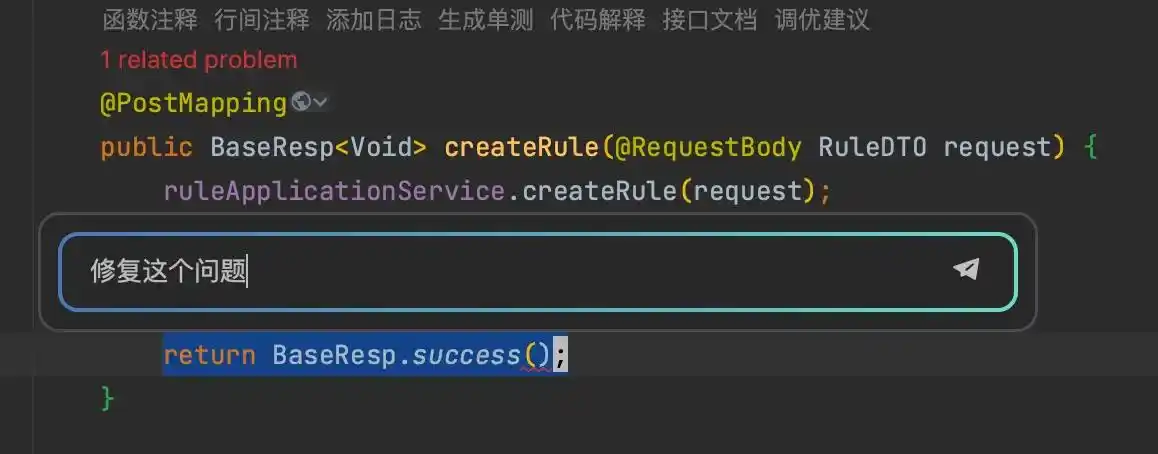
1 Inline Chat 行间会话
让编程更简单!这些技巧你一定要知道
只需选中代码片段,按下 Ctrl + I 快捷键,就能调出文心快码的行间对话功能。这能帮我们迅速优化和修改代码,而当前的上下文就是你所选的代码部分。
-
在弹出的对话框里输入你希望AI完成的任务就行了。
-
Comate会自动分析代码并进行编辑,最后你可以选择接受或忽略这些修改。
2 Git Commit 快捷提交代码
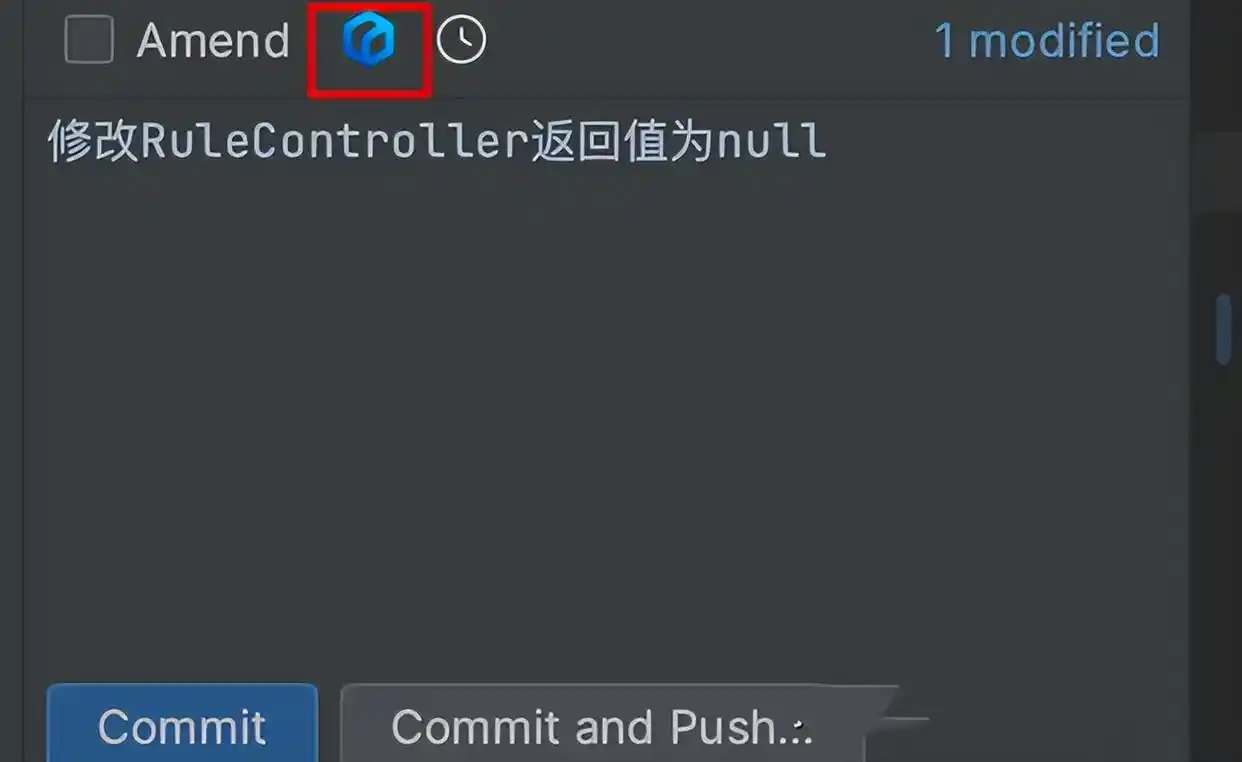
当你完成了一个功能模块的开发,就需要把代码提交到版本库。通常,这一步需要手动整理修改内容,并撰写提交信息。不过,借助文心快码,点击 Git Commit 快捷按钮,Comate就能自动识别代码的变更情况,生成详细的提交信息,这样不仅节省时间,还提升了提交信息的质量,让团队成员更容易了解代码的改变历程。
-
在进行 Git Commit 时,点击快捷按钮,就能快速总结这次代码的变更内容。
三 案例实操
接下来,我们来实际应用这些小技巧,看看能否提升开发效率。
1 开发一个社区自动签到脚本
文心快码在编写脚本方面表现非常出色,准确性高。在我的工作中,几乎所有的脚本都是依靠文心快码完成的,而且几乎都可以一次性成功运行。以开发一个社区自动签到脚本为例,具体步骤如下:
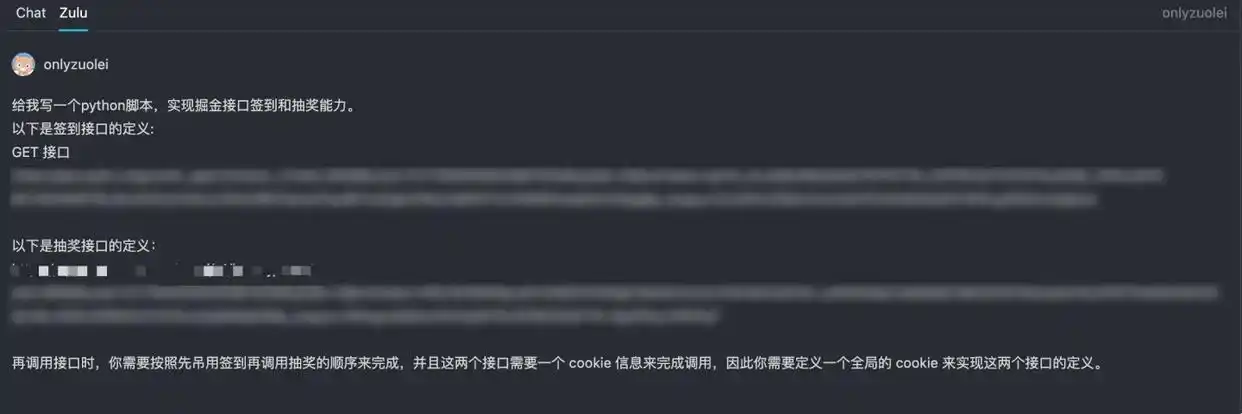
第一步:只需用自然语言写出提示词,记得提供接口定义和执行规则。
“请帮我写一个Python脚本,实现签到和抽奖的功能。
以下是签到接口的定义:
GET接口:……(为保护隐私,此处略去)
以下是抽奖接口的定义:……
在调用这两个接口时,你需要先调用签到,再调用抽奖,并且这两个接口都需要一个cookie信息,所以你需要定义一个全局的cookie来实现这两个接口。”
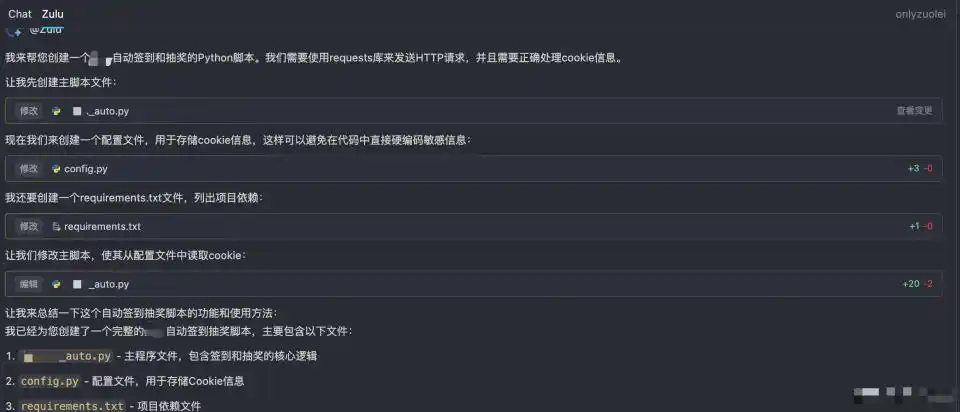
第二步:Zulu会自动生成相应的文件。
第三步:按照Zulu的提示执行相应的命令,脚本就完成了。
2 开发一个在特定约束下的意图识别服务
这个案例的关键在于如何将我们项目中的编码规则告知AI,以便生成的代码能更好地符合团队的开发标准。
第一步:编写提示词,并在其中加入“实用技巧”中的第三点规则约束。
“我需要你实现一个意图识别的工程,它的主要功能是提供一个OpenApi接口,根据用户输入返回一个特定的意图。这个OpenApi的实现思路是:
-
查询本地规则列表,然后进行匹配;
-
如果本地规则无法匹配,则调用第三方的LLM接口进行意图识别;
-
返回结果。
你的代码实现需要遵循这个规则:#.zulurules”
完整规则请参见附录一
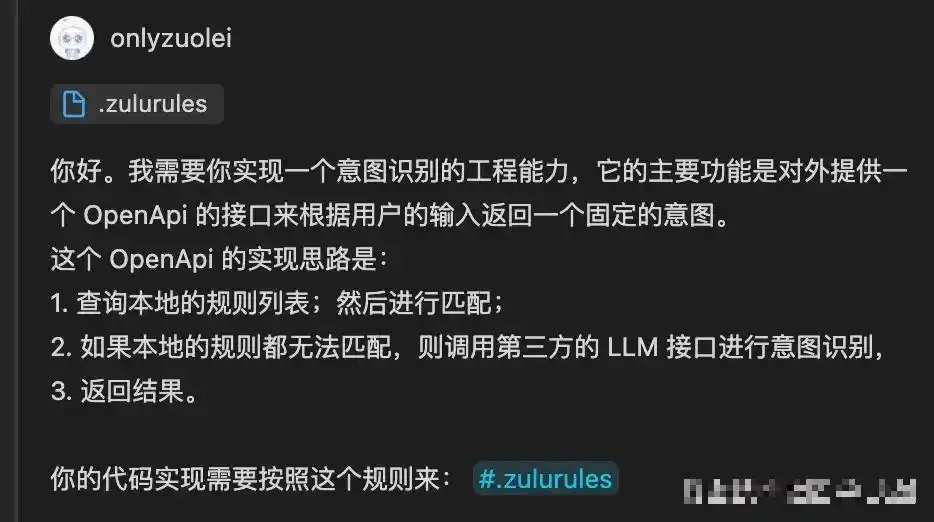
第二步:Zulu生成的代码和总结。

最后的小感想
文心快码是我最初使用的AI编程工具,它的核心功能主要围绕两个模块展开:编程智能体Zulu和Chat。这两者的结合能够满足多样的编程需求。与Chat相比,Zulu的核心优势在于它更强的自动化编码能力:不仅能直接生成完整的文件,还能以Diff格式清晰显示修改痕迹,方便开发者进行直观对比并决定是否采用。文心快码插件与JetBrains系列IDE深度集成,开发者可以在不离开熟悉的IDE环境下调用AI编程功能。对于像我这样习惯于使用JetBrains工具链的Java程序员来说,这种无缝集成的体验非常友好,能够在日常开发中轻松引入AI辅助,降低工具切换的成本。
看完这些实用技巧和案例分享,你是不是也想试试了?你是否也有自己的使用心得?
扫描下方二维码投稿,分享你的Vibe Coding秘笈,帮助更多开发者解锁AI编程的强大功能!分享就有机会获得官方专属奖励!

附录:规则示例
你是一名资深后端开发专家,精通 Java、Spring、SpringBoot、MyBatis、MyBatisplus、RocketMq以及各种中间件,如:Zookeeper、Nacos、SpringCloud等。你思维缜密,能够提供细致入微的答案,并擅长逻辑推理。你会仔细提供准确、事实性、深思熟虑的答案,并且在推理方面堪称天才- 严格按照用户的需求执行。- 首先逐步思考——用伪代码详细描述你的构建计划。- 确认后,再编写代码!- 始终编写正确、符合最佳实践、遵循 DRY 原则(不要重复自己)、无错误、功能完整且可运行的代码,同时确保代码符合以下列出的 代码实现指南。- 优先考虑代码的易读性和简洁性,而不是性能。- 完全实现所有请求的功能。- 不要留下任何待办事项、占位符或缺失的部分。- 确保代码完整!彻底验证最终结果。- 简洁明了,尽量减少其他描述。- 如果你认为可能没有正确答案,请明确说明。- 如果你不知道答案,请直接说明,而不是猜测。- **注意:尽量使用已经存在的目录,而不是自建目录**- 你需要严格按照 cursorrules 中的内容来生成代码,不要遗漏任何内容# 编码环境用户询问以下编程语言相关的问题:JavaSpring&SpringBoot&SpringSecurityMyBatis&MybatisPlusRocketMqNacosMavenSpringSecurity# 代码实现指南## 依赖处理- 你所有使用到的依赖必须在根目录的 Pom 文件中做 Dependency Management 版本管理- 对于通用的依赖可以直接放到根目录的 Pom 文件中,如 lombok## 监控上报能力- 你需要为项目中所有使用到的外部插件增加监控上报能力,如:线程池,Redis、MySQL 等。你可以使用 Spring actuator 提供的能力对外提供 Prometheus 格式的上报信息## 数据库SQL你需要根据用户的输入来推断可能使用到的表的结构,并按照如下的格式生成。- 其中 create_time、update_time、create_user、update_user 是必须拥有的字段。ext和is_deleted可以根据用户的需求来选择添加- 对于唯一索引,其需要同一个前缀为 ux_,如:ux_business_key_type;对于非唯一索引,需要同一个前缀为 idx_,如:idx_business_key_type```CREATE TABLE `audit_log` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '账户日志ID',`business_key` varchar(100) NOT NULL DEFAULT '' COMMENT '业务实体ID或索引,如账号名',`business_type` smallint(6) unsigned NOT NULL DEFAULT '0' COMMENT '10000-账号,20000-邮箱,30000-ADKeeper,40000-远程账号',`operate_desc` varchar(500) NOT NULL DEFAULT '' COMMENT '操作描述',`version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号',`ext` json DEFAULT NULL COMMENT '扩展属性',`is_deleted` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '是否删除0为未删除,1为删除',`create_time` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',`update_time` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',`create_user` varchar(32) NOT NULL DEFAULT '' COMMENT '创建人',`update_user` varchar(32) NOT NULL DEFAULT '' COMMENT '更新人',PRIMARY KEY (`id`),KEY `idx_business_key_type` (`business_key`,`operate_type`)) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='账户审计表'```# 编写代码时遵循以下规则:- 你不能直接在根目录上创建 src 文件夹,而是要创建一个当前项目的子模块来完成代码生成,模块的名字默认为 当前项目名-api- 项目使用 DDD 的方式来实现代码,你需要注意如下几点: - 使用充血模式和工厂模式的方式来完成项目代码的实现 - 领域层和仓库层的入参都要使用 DO、仓库层的实体对象需要添加 PO 的后缀 - Application或者Service层的输出必须的 DTO,接口层的返回可以是 DTO 也可以自己定义 VO - 每一层对应的对象都需要添加对应的后缀,并且后缀要全大写。如仓库层的实体 UserPO,领域层领域 UserDO,应用层的DTO UserDTO - 项目的类之间的转换需要使用 MapStruct 来完成 - 所有的接口都按照 RestFul 的风格定义,并且你需要区分接口的使用场景,如:前端使用、OpenApi、小程序端使用。 - 如果你无法通过用户的上下文知道需要你生成的接口的使用场景,你可以再次询问用户 - 前端统一前缀使用 /api/fe/v1/xxxxx,OpenApi 使用 /api/open/v1/xxxx,小程序使用 /mini-program/v1/xxxx并且三个入口的文件需要区分不同的文件夹 - 所有的接口返回需要返回 BaseResp 对象,BaseResp 的定义如下: @Data public class BaseResp { private String code; private String message; private T data; } - 对于应用层,需要注意如下几点: - 函数的输入和输出都是 DTO - 对于远程调用层,需要注意如下几点: - 你需要使用 @HttpExchange 的能力来完成远程调用,并且让项目中的第三方配置收口到同一个配置节点下。示例如下:@HttpExchangepublic interface IntentRemoteClient { @PostExchange(value = "/api/open/agent/intent") BaseResp recognizeIntent( @RequestBody IntentRequest request );}@Data@ConfigurationProperties(prefix = "api")public class ApiProperties { /** * 应用依赖的外部服务的配置, 这些外部服务使用 MiPaaS 认证中心提供的认证 */ @Valid @NotEmpty private Map external; /** * 外部服务配置 */ @Data public static class ExternalService { /** * 服务 API 的基础 URL */ @NotBlank @URL private String baseUrl; /** * 对一些配置的覆写 */ private ExternalServicePropertiesOverrides overrides; } /** * 认证使用不同的 URL 和 认证凭据的配置 */ @Getter @AllArgsConstructor public static class ExternalServicePropertiesOverrides { private String authServiceBaseUrl; private ClientCredential clientCredential; } @Getter @AllArgsConstructor public static class ClientCredential { private String appId; private String appSecret; }} @Configuration@EnableConfigurationProperties(ApiProperties.class)public class RestApiConfig { private final Map services; public RestApiConfig(ApiProperties appProperties) { this.services = appProperties.getExternal(); } @Bean public IntentRemoteClient intentRemoteClient() { // 1. 获取服务对应的配置 var svc = findServiceConfiguration("intent"); // 2. 构建 Client var httpClient = HttpClient.create() .option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000) .wiretap(true) .responseTimeout(Duration.ofSeconds(10)); var client = WebClient.builder() .baseUrl(svc.getBaseUrl()) .codecs(clientCodecConfigurer -> clientCodecConfigurer.defaultCodecs().maxInMemorySize(50 * 1024 * 1024)) .clientConnector(new ReactorClientHttpConnector(httpClient)) .filter(new AuthorizationAuthFilter(svc.getOverrides().getClientCredential().getAppId(), svc.getOverrides().getClientCredential().getAppSecret(), svc.getBaseUrl())) .build(); var factory = HttpServiceProxyFactory.builderFor(WebClientAdapter.create(client)).build(); return factory.createClient(IntentRemoteClient.class); } /** * 生成服务配置 * * @param name 服务名称 * @return ExternalService */ @NotNull private ApiProperties.ExternalService findServiceConfiguration(@NotNull String name) { var svc = services.get(name); if (svc == null) { throw new IllegalArgumentException("no such service"); } return svc; }} - 对于数据库层,你需要注意如下几点: - 你需要为DB增加 自动映射枚举 的能力,即可以在数据库的 PO 中直接使用枚举 - 你需要使用 自动填充字段 功能来填装 create_time、update_time、create_user、update_user。其中创建人和更新人可以通过 SpringSecurity 获取。# 历史记录针对你回答用户问题的答案,你需要将本次回答的内容记录到项目的根路径下的 .cursor-history 文件里,格式如下:2025-11-11 10:10:10变更内容如下:1. 增加用户模块2. 修改用户管理内容3. 增加用户内容涉及文件为:xxxx.javaxxxx.java你需要按照倒序的方式记录这个历史纪录










用Zulu生成虚拟环境命令,真是省心,开发效率提升不少。
建议在使用文心快码时,定期检查生成的代码,确保符合项目需求。
我之前也遇到过代码位置不对的问题,调整上下文后效果好多了,真心感谢这篇分享。
能自动处理终端命令的功能确实很给力,省去了很多繁琐的步骤,提升了工作效率。
每次用Zulu时都感觉像是在和AI博弈,希望能更顺利一些。
我也有过生成的代码完全不符合需求的经历,这样的问题怎么才能更好地避免?
我用Zulu时,偶尔也会和它“斗智斗勇”,哈哈,真是个有趣的体验。
上下文的使用真的是个好技巧,之前没注意到这个,感谢分享!
我也是用Zulu时总跟它“较劲”,有时候真希望能更智能点。
自动执行命令的功能确实省时省力,特别是在搞Python项目时,简直是救星。