一不小心,可能就把除了C、C++和汇编这些语言都给淘汰了……
不过好在,Vibe coding的威力没那么恐怖,这个问题的深层意思在于,如果Vibe Coding成功了,那就是先把C系语言和汇编以外的所有语言都给踢出局。
其实现在的LLM根本不需要那些“人类友好的语法糖”,高级语言那些为了让人好理解而设计的东西,难道不是多余的吗?
可惜的是,结论就是别用C来搞Vibe coding,真的是个大坑!
并不是C语言太难,而是你得选择一种能够给LLM提供”纠错反馈循环”的语言。
Rust的编译器会一直“教育”你,直到你把错误改过来,而Python出错了至少不会让你的内存炸掉——可是C呢?
它默默地埋下了雷,等你上线后再给你一个大惊喜。
那到底有没有人真的成功搞Vibe coding呢?
当然有,而且有些案例确实让人惊讶。
我知道有位大佬用Claude Code结合Opus 4.5,做了个叫bipscan的工具——可以扫描公开文本寻找隐藏的比特币种子短语。
他用的是Ruby+C+Shell……
我看到他的性能数据都惊呆了:
• 4分钟就扫描完12G的pg19文本库
• 生成了6400多万个候选种子短语
• 并行检查器的速度每秒可以处理460个派生地址
还有一个用Rust和Python做的图标转图像工具,核心逻辑用Rust编写,接口绑定用Python,依然是opus4.5。
其实即使是一些老旧的技术栈,Vibe coding依然可以奏效。
但!失败的案例同样数不胜数!
我团队里有个小伙伴,就用LLM尝试完成一个简单的任务:用GTK4设置全局快捷键。
结果怎么样呢?
无论他怎么调整prompt,怎么指定版本,LLM就是在那里认真地编造一些根本不存在的函数。
他还尝试了Alembic库查询、GitHub GraphQL API调用,结果全都是幻觉。
后来他发现这个功能在GTK4里根本是“effectively undocumented”!
训练数据里根本没有足够的示例,LLM只好胡编乱造。
总之,LLM并不是不会欺骗你,而是它在欺骗你的时候特别自信。
最让人头疼的是,这样的过程非常浪费时间,全部时间都花在排查问题上!
Vibe coding最开始看似不错,试试看吧,但很快就会让你陷入困境……
因为你会发现大量时间都花在和AI“澄清”问题上,等代理跑完后再写新的修正,这种start-stop的节奏就像刷短视频一样,让人根本无法深入思考。
不如还是回归手动编程,把那些无聊的小任务交给ChatGPT或者Claude code。
不仅在开发中如此,学术上也是一样。
这篇arxiv论文2507.09089的核心结论是开发者对AI辅助编程效果的主观感受与客观测量之间存在巨大差距。
换句话说,当你觉得“我用AI提高了3倍的效率”时,可能只是你“觉得”而已。
这个研究让我有点小震惊,因为我自己也时常觉得AI帮了大忙,但实际产出到底提高了多少……我真不敢细想。
其实自从我开始搞Vibe coding,只要不把那些小问题、bug处理以及写给自己看的注释全交给LLM,其实还是可以用的。
Vibe coding可以做一些事情,但并不能全包。
你会发现自己陷入一个既想前进又得回头的两难境地。
在这种情况下,你需要找到一个平衡点,而这个平衡点就是Vibe coding能做的事情用十根手指都能数完。
所以说,很多语言或者项目根本无法胜任,也就意味着它不可能做出多少成果。
到2025年12月,Vibe coding无法有效应对简单语言的项目。
更别提C或者汇编了。
C能写吗?
简单的可以,但最好还是别碰……
因为C语言是Vibe coding的高风险选项,训练数据里全是问题……
作为53岁的C语言,现在的LLM根本不知道它埋下了多少陷阱。
看看Chromium项目的统计数据,那可是Google的顶级C++工程师,依然在代码里埋下了内存炸弹。
LLM是在海量代码上训练的,而这些海量C代码中充满了内存管理的错误,因此LLM学会了这些错误模式,生成的代码大概率也会有类似的问题。
这并不是LLM“愚蠢”,而是统计学习的必然结果。
Pegasus恶意软件、Zerodium、Windows零日、Chrome零日……这些都是专家写的C/C++代码中的“祖传屎山”代码。
也就是说,顶尖专家在C语言中也会犯错,你凭什么相信LLM能比他们更强?
不过Vibe coding确实可以写C和WebAssembly。
我知道有位大佬simonw就用GPT写过SQL的扩展……

simonw认为实验可以,但上线得谨慎。
还有另一位大佬成功用Vibe coding做了一个Windows托盘小工具,体验“刺激”。
但他也提醒大家,如果不懂代码就别轻易尝试。
言外之意就是Vibe coding写的东西,千万不要外包给它。
用Vibe coding最舒爽的就是Rust,因为Rust的编译器反馈循环很强,Rust编译器会告诉LLM哪里错了、怎么错了,LLM才能改正,直到编译通过为止。
Rust的错误信息是“为人类设计的”,详细到LLM都能理解并据此修正。
而对于动态语言来说?
出问题只能靠反复测试慢慢试错。
在Android中用Rust的案例中,Rust帮我们节省了处理内存bug的时间,这些时间可以用来修复逻辑错误。
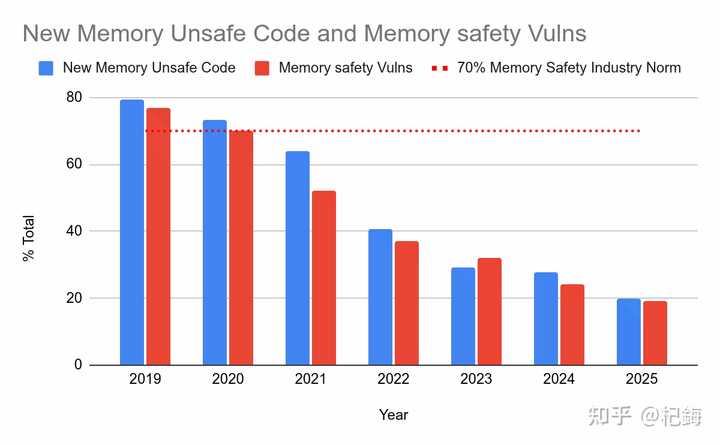
我觉得这个企业级案例确实说服力很强。
而最佳组合是:Rust负责核心逻辑,Python负责接口绑定。
原因如下:
• Rust的强制正确性能够防止大量bug
• Python的REPL便于快速验证
• 每个PR都要附带demo notebook确认功能
从我看来,LLM理解复杂系统没问题,但前提是你得给它足够的上下文。
想了解Claude Code的上下文管理教程可以查看这里:由2条Prompt到2条命令,让你的Claude Code拥有无限上下文,不会乱Grep浪费Tokens(帮你省Tokens),按你所想埋头苦编,绝不越界
想了解更多Vibe coding和Claude Code的使用技巧,可以关注我的专栏:coder≥Vibe coder码到成功
参考
研究论文
• METR研究(主观感知vs客观测量):https://arxiv.org/pdf/2507.09089
• 代码质量研究:https://arxiv.org/abs/2501.16857
• LLM-Modulo框架:https://arxiv.org/pdf/2402.01817
技术资源
• Google Android Rust安全博客:https://security.googleblog.com/2025/11/rust-in-android
• simonw SQLite C扩展:https://simonwillison.net/2024/Mar/23/building-c-extensions-for-sqlite-with-chatgpt-code-interpreter/
代码仓库
推荐几个有趣的项目
• bipscan项目:你可以在这里找到它的代码:https://github.com/akaalias/bipscan
• icon-to-image:这个项目也很不错,详细信息在这里:https://github.com/minimaxir/icon-to-image









Vibe coding听起来很吸引人,但实际操作中却充满了挑战,尤其是对LLM的信任度。感觉还是有很多不确定性。
虽然有些成功案例让人惊叹,但我觉得在具体任务中,AI的表现常常让人失望,特别是在处理复杂功能时。
Vibe coding 的确有吸引力,但实践中遇到的困难不容小觑。尤其是依赖 LLM 进行编程时,常常会被其不可靠的输出所困扰。手动编程还是更稳妥。
Vibe coding确实是个新兴概念,但在真实项目中,LLM的表现令人堪忧,尤其是面对复杂任务时,错误频出让我感到无奈。
虽然Vibe coding听上去很酷,但我在实际应用中发现,LLM的输出经常不靠谱,反而浪费了大量时间。
实践中发现,Vibe coding的挑战远超过想象,尤其是AI在提供代码时的准确性和可靠性令人担忧。
这篇文章让我意识到,尽管Vibe coding有其潜力,但现实中AI的错误输出常常让我头疼,还是手动编程更靠谱。
Vibe coding的想法很新颖,但我在实践中发现LLM的输出经常不符合预期,反而增加了工作量。
虽然有些成功的案例,但我认为使用LLM编程时,面对复杂逻辑时总是会遇到许多意想不到的问题。
文章提到的时间浪费问题完全能够理解,Vibe coding的过程确实让人感到挫败,尤其是在调试时。
对Vibe coding的热情是可以理解的,但在实际操作中,AI的错误让我感到不安,还是手动编程更稳妥。