今天凌晨,OpenAI发布了他们全新升级的编程模型GPT-5.2-Codex。这款模型是基于GPT-5.2进行深度优化的,主要在长程任务执行、大规模代码修改、兼容Windows环境以及网络安全防护方面都有所提升。OpenAI在他们的博客中表示,这可能是他们目前为止最强大的编程模型。
根据OpenAI的官方博客,GPT‑5.2-Codex不仅继承了GPT‑5.2的优势,还吸收了GPT‑5.1-Codex-Max的尖端智能体编程和终端操作能力,特别为复杂的软件工程和网络安全领域量身定制。
OpenAI已经在Codex CLI、IDE扩展、云端及代码审核等多个领域推出了GPT‑5.2-Codex,从今天起,所有付费的ChatGPT用户都能使用这项新功能,API接口也很快会开放。
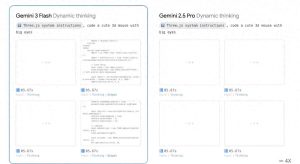
有趣的是,就在GPT‑5.2-Codex发布前,谷歌刚推出了Gemini 3 Flash模型。有网友尝试让这两者一起处理任务,结果发现GPT‑5.2-Codex落败!在对50个文件进行漏洞检查时,Gemini 3 Flash只用了1分2秒,发现了5个问题,而GPT-5.2-Codex却花了4分48秒,仅找出2个Gemini 3 Flash已经识别的问题。

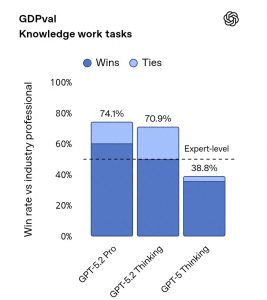
不过,GPT‑5.2-Codex的表现似乎并未达到预期。一些网友反馈称,GPT‑5.2-Codex在SWE-Bench Pro上的性能提升不足1%,而且尚未发布SWE-Bench Verified的结果,这让人不禁怀疑GPT‑5.2-Codex是否真的达到了当前的最佳水平,甚至在某些系统基准测试中显示出性能下降。

根据OpenAI的官方说法,从功能上看,GPT‑5.2-Codex加入了原生上下文压缩技术,在长上下文理解、工具调用和事实准确性等方面都有显著提升。而且,它在推理时的Token使用效率也提高了,能够更精准地理解编码过程中共享的截图、技术图表和数据图表。在原生Windows环境中,GPT‑5.2-Codex相较于GPT‑5.1-Codex-Max的能力提升更加明显,智能体编程变得更高效可靠。
在实际的软件工程任务中,GPT‑5.2-Codex的表现也有所提升,涵盖了代码库导航、重构以及Pull Request的创建和审核等方面。
从基准测试的结果来看,GPT‑5.2-Codex在真实世界代码问题的SWE-Bench Pro基准测试中得分为56.4%,不仅超越了GPT-5.2的55.6%得分,还比GPT-5.1的50.8%高出不少;在处理编译和服务器配置等任务的Terminal-Bench 2.0基准测试中,GPT‑5.2-Codex得分达到了64.0%,显著领先前代的GPT‑5.1-Codex-Max的58.1%,展示了模型在使用命令行和终端处理任务方面的进步。
AI编程工具的竞争正在升温
根据OpenAI的官方博客,最近在网络安全的夺旗挑战(CTF)中,GPT‑5.2-Codex表现出色,成为所有模型中的佼佼者。从趋势图来看,我们可以看到OpenAI在网络安全评估方面的能力正在不断提升。博客中提到,他们正在全面升级网络安全防护,并引入了可信访问机制,以增强防御效果。
OpenAI的首席执行官萨姆·阿尔特曼(Sam Altman)表示,上周有一位安全研究员利用GPT‑5.1-Codex-Max发现并报告了React框架中的一个漏洞,可能会导致源代码泄露。这一事件显示了模型在网络安全领域应用的实际价值。阿尔特曼还提到,这些模型仍在持续改进之中,未来将为网络安全带来更多好处。
在结尾要说的是,GPT-5.2-Codex是OpenAI在编程模型上的又一次重大进步,它在处理复杂任务、大规模代码变更和特定环境下的表现上都有显著提升,成为开发和安全研究中的强大助手,可能会成为发现和修复漏洞的重要工具。
而在OpenAI发布更新的同一天,谷歌也推出了经济实惠的Gemini 3 Flash模型,AI编程领域的竞争愈发激烈。目前来看,虽然号称最强的GPT-5.2-Codex,但在实际应用效果和与竞争对手的对比中,可能并没有达到预期。这也让人对它在未来的表现充满期待,究竟它的实际应用效果怎么样,大家都在关注。
本文内容来自微信公众号“智东西”(ID:zhidxcom),作者:王欣逸,编辑:程茜,36氪经授权发布。