整理|华卫
嘿,大家好,刚刚听说GPT-5.2发布了!
这次一共推出了三个版本:
-
首先是GPT-5.2 Instant,它是一款特别实用的日常工具,能在信息检索、操作指南、技术文档撰写和翻译等方面大幅提升效率,而且延续了GPT-5.1 Instant那种亲和的对话风格。
-
接下来是GPT-5.2 Thinking,这个版本是专门为需要深入思考的工作场景设计的,特别适合那些复杂任务,比如编程、长文档总结、文件问答、数学逻辑推导,以及生成条理清晰、信息详尽的规划和决策支持。
-
最后是GPT-5.2 Pro,这是OpenAI为解决高难度问题推出的超级智能选项,虽然获取答案的时间可能会变长,但质量绝对值得期待。
OpenAI表示,这是他们迄今为止功能最强大的专业知识工作模型系列,涵盖了44种职业,特别是在明确任务的知识型工作中,它的表现超越了许多行业专家。
总体来看,GPT-5.2在通用智能、长上下文理解、智能工具调用和视觉能力上都有了显著提升。相较于之前的任何版本,它在执行复杂现实任务时表现得更加出色,比如制作表格、搭建演示、编写代码、图像识别、理解长文本、调用工具和处理多步骤项目等方面的能力都有了飞跃。
OpenAI的CEO Sam Altman在社交媒体上兴奋地说:“这是一个非常智能的模型,自GPT-5.1以来,我们取得了巨大的进步。”而微软的CEO Satya Nadella也亲自送上了祝贺,表示“GPT-5.2已经在Copilot上线”,还引入到了Microsoft Foundry和Copilot Studio。
从今天开始,GPT-5.2的即时版、思考版和专业版将在ChatGPT平台推送,优先面向付费用户。而在编程接口方面,所有开发者目前都可以使用这些版本。GPT-5.1将作为旧版继续服务于付费用户三个月,之后就会正式下线。
1个GPT-5.2的能力相当于11个专业人士,经济性真是爆表!
OpenAI强调,开发GPT-5.2的目标就是为了让人们释放更多的经济价值。GPT-5.2 Thinking是迄今为止最适合实际应用的模型,它的性能已经达到了甚至超越人类专家的水平。
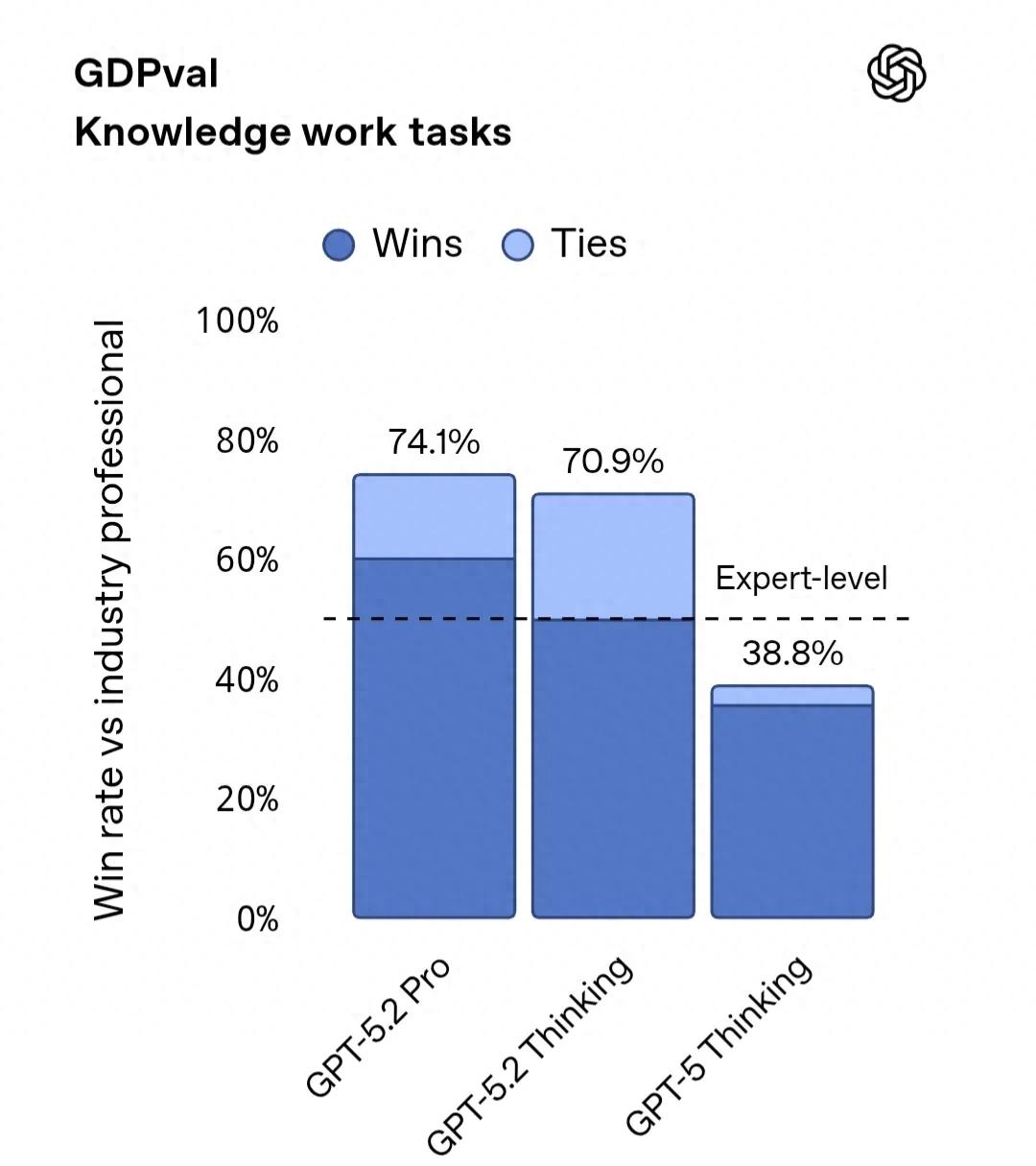
在针对44个职业的特定知识工作任务的GDPval评测中,GPT-5.2 Thinking创下了新的高分。在评比中,GPT-5.2 Thinking在70.9%的项目上表现超过或与顶尖行业专家相当。这些任务包括制作演示、表格和其他工作成果。
在完成GDPval相关任务时,GPT-5.2 Thinking的输出速度是专业人士的11倍,成本却不到他们的1%。这意味着在人工监督下,GPT-5.2能够为专业工作提供强大支持。
有一位GDPval评测员对此表示:“质量的提升真是惊人,效果看起来就像是专业团队制作的,交付的成果无论是排版还是建议都非常出色,不过其中一份还有一些小错误需要修正。”
此外,在OpenAI针对初级投行分析师的电子表格建模任务的内部测试中,GPT-5.2 Thinking的单项平均得分提高了9.3%,从59.1%增至68.4%。对比结果显示,GPT-5.2 Thinking生成的电子表格和幻灯片在复杂性和格式规范性上都有了明显的进步。
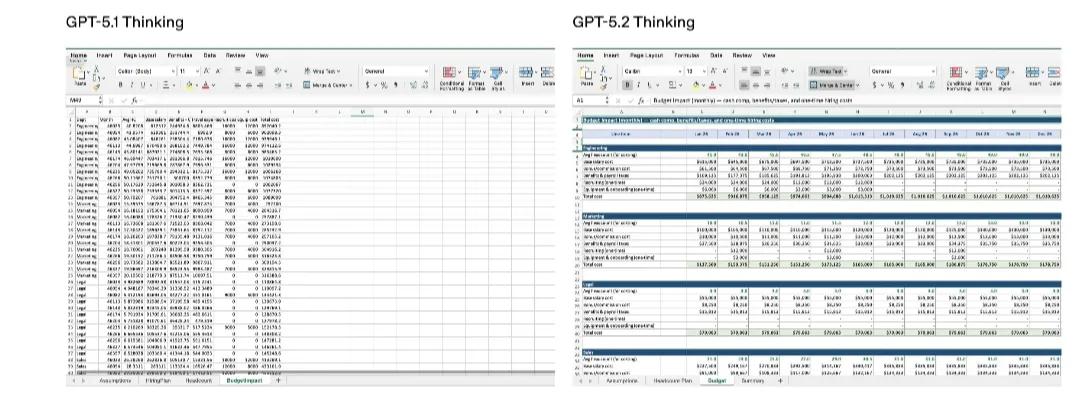
不过需要注意的是,生成复杂内容时,GPT-5.2 Thinking可能会花费几分钟的时间。而且,要在ChatGPT中使用最新的电子表格和演示文稿生成功能,得订阅Plus、Pro、商业版或企业版套餐,并选择GPT-5.2 Thinking或Pro版。
值得一提的是,GPT-5.2 Thinking是OpenAI目前所见的首个在4-needle MRCR变体测试中取得接近100%准确率的模型。尤其在深度文档分析等需要处理数十万词元关联信息的任务中,GPT-5.2 Thinking的准确率远远超越了GPT-5.1 Thinking。
GPT-5.2:让复杂任务变简单的超级助手
从实际应用的角度来看,GPT-5.2真的是个好帮手。它能帮助专业人士高效地处理各种文档,比如报告、合同、研究论文、会议记录,甚至是多文件的项目。即使在信息量庞大的情况下,它也能保持逻辑的连贯性和结果的准确性。因此,GPT-5.2特别适合做深度分析、信息整合等复杂的工作流程。
在Tau2-bench Telecom的基准测试中,GPT-5.2 Thinking获得了98.7%的高分,展现了它在处理冗长多轮任务时的出色能力。而在对延迟敏感的场景中,它在零推理消耗模式下的表现同样提升明显,性能明显优于之前的版本GPT-5.1和GPT-4.1。
对于专业人士来说,使用这个模型可以显著提升工作流程的效率和稳定性。比如在处理客户支持工单时,它能够从多个系统中调取数据,进行分析并生成最终成果。整个过程中的中断率也明显降低。打个比方,当用户遇到需要多步骤解决的复杂客服问题时,GPT-5.2能更有效地协调多个智能助手完成工作。
谈到编程能力,GPT-5.2也有了很大的进步。不过,产出的速度还是有点慢。在SWE-Bench Pro基准测试中,它的成绩达到了55.6%。这个测试对软件工程能力的评估非常严格,不同于只测试Python的SWE-Bench Verified,SWE-Bench Pro涵盖了四种编程语言,挑战性和实际应用性都有提升。
在SWE-bench Verified测试中,GPT-5.2 Thinking的表现也很不错,达到了80%的新高分。这意味着它在调试生产环境代码、实现功能需求、重构大型代码库等方面变得更加稳定,基本上不需要太多人为的干预就能完成漏洞修复和上线。
至于前端开发,GPT-5.2 Thinking的表现比5.1更好。早期测试者发现,它在复杂或非标准界面的开发中表现得尤其出色,特别是在涉及3D元素的开发场景,这让它成为全栈工程师的日常协作工具。以下是GPT-5.2 Thinking通过一条指令生成的一些成果示例:
Windsurf公司的首席执行官Jeff Wang表示,“GPT-5.2是自GPT-5以来在智能编码方面最大的飞跃,是同价位产品中最先进的编码模型。版本号的提升远不足以体现其智能水平的飞跃。”据说,GPT-5.2 Thinking已成为Windsurf和多个Devin核心工作负载的默认版本。
此外,Cognition、Warp、Charlie Labs、JetBrains和Augment Code等公司也认为,GPT-5.2在交互式编程、代码审查和漏洞排查等领域都有了显著的提升。
目前,早期测试者们也分享了他们对GPT-5.2编码能力的反馈。HyperWriteAI的CEO Matt Shumer从11月25日开始使用GPT-5.2,经过两周在编程、研究、创意写作和日常任务等方面的全面测试,他对GPT-5.2给出了以下评价:
-
GPT-5.2 Thinking在指令遵循能力和解决问题的意愿上实现了实质性的进步。
-
它的代码生成能力相比GPT-5.1有了显著提升,功能更强,自主性更高,逻辑也更加严谨,甚至能编写更复杂的代码。
-
在图像元素位置识别和处理大型代码库方面,视觉和长上下文处理能力得到了显著优化。
-
不过,速度问题依然是它的短板,面对大部分问题时,思考模式的反应速度还是比较慢的。
GPT-5.2的强劲表现和潜在问题
说到GPT-5.2 Pro,它在深度推理方面真的让人眼前一亮,但速度上却有点拖后腿,有时候还会卡住,搞得结果迟迟出不来。
在Codex的命令行界面里,GPT-5.2的编程能力几乎可以和专业版媲美,不过如果你想用超高推理模式来发挥它的威力,那就得耐心等上一阵子,时间可不短。
自评为“最佳科研模型”的GPT-5.2 Pro和GPT-5.2 Thinking,OpenAI称它们是目前全球顶尖的科研助手。
在谷歌的研究生级别验证问答测试GPQA Diamond中,GPT-5.2 Pro拿下了93.2%的高分,而紧随其后的GPT-5.2 Thinking也达到了92.4%。在专家级的数学评测基准FrontierMath(1-3级)中,GPT-5.2 Thinking成功解答了40.3%的题目。
最近的一项研究中,科研人员利用GPT-5.2 Pro探讨了统计学习理论中的一个开放性问题。在特定的场景下,这个模型提出了证明的步骤,经过研究作者和外部专家的认可,结果被证实是有效的。
在通用推理能力的测试中,GPT-5.2 Pro成为了第一个得分超过90%的模型,比去年的o3-preview版87%有了显著提升,且其性能的成本降低了约390倍。
在更具挑战性的ARC-AGI-2(验证版)中,GPT-5.2 Thinking以52.9%的分数表现不俗,而GPT-5.2 Pro则更为优秀,达到了54.2%,进一步展示了它在新的抽象问题上的推理能力。
Triple Whale的首席执行官AJ Orbach对此表示,“GPT-5.2的架构彻底变革了整个系统,简化了原本复杂的多智能体系统,变成了一个拥有20多个工具的超级智能体。这个超级智能体不仅速度快、智能高,而且维护也轻松了100倍。延迟大幅降低,工具调用的能力更强,而且不需要冗长的系统提示,只需一行简单的指令就能完成任务,真是太厉害了!”
不过值得注意的是,GPT-5.2 Thinking的幻觉现象较GPT-5.1 Thinking有所减少。在一组来自ChatGPT的匿名查询中,错误回复的比例降低了30%。对于专业人士来说,这意味着在使用这个模型进行研究、写作、分析和决策时,出错的机会更小,工作时也会更加可靠。
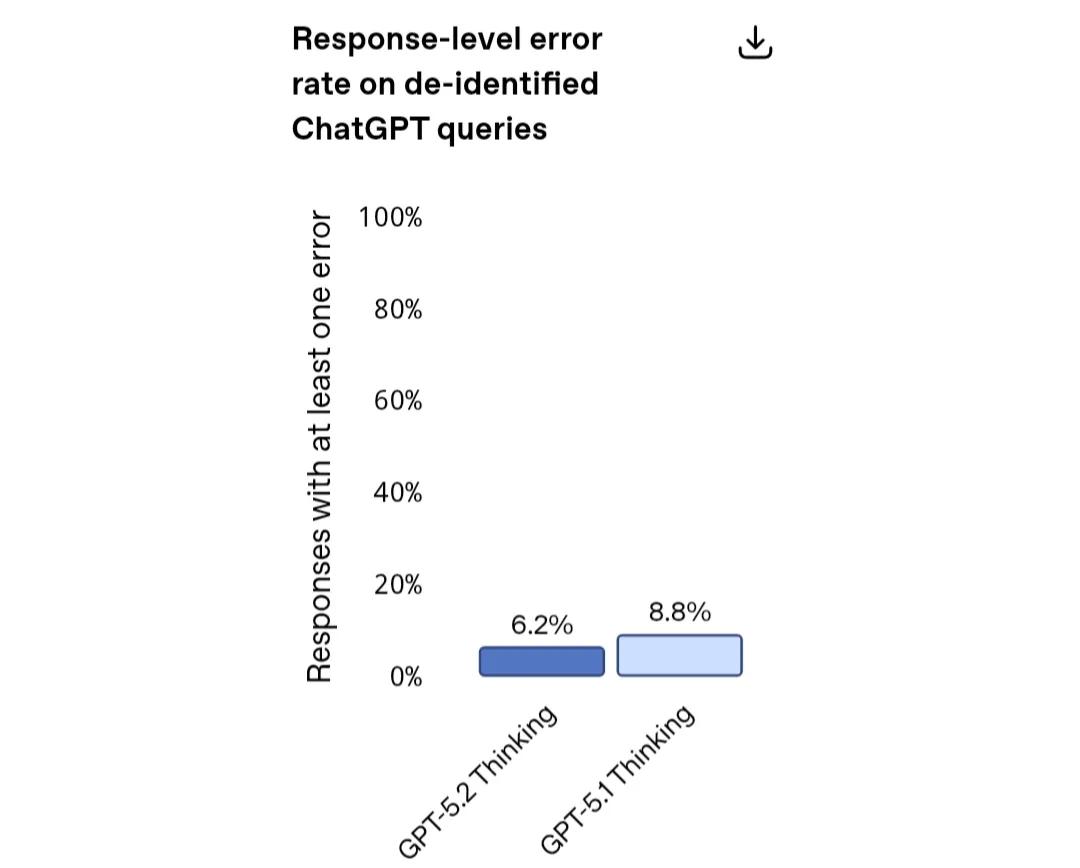
尽管如此,OpenAI依然提醒大家,“就像所有模型一样,GPT-5.2 Thinking也不是十全十美的。在处理任何重要事务时,务必要核实它给出的答案。”
在定价方面,接入GPT-5.2后,ChatGPT的订阅费用没有变动,但在API端,由于GPT-5.2的强大性能,单词元的定价高于GPT-5.1。具体来说,GPT-5.2的定价为:每百万输入词元1.75美元,每百万输出词元14美元,而缓存输入内容则享有90%的折扣。

接下来几周,OpenAI预计会推出针对Codex进一步优化的GPT-5.2版本,而目前GPT-5.2也已经可以在Codex平台上直接使用了。
参考链接:
https://openai.com/index/introducing-gpt-5-2/
声明:本文为AI前线整理,不代表平台观点,未经许可禁止转载。
今日好文推荐
InfoQ 老友!请留步!极客邦 1号客服上线工作啦!










