从Word2Vec到DeepSeek V3,再到自注意力机制和混合专家模型,本文将带你深入探讨现代AI的基础架构
引子:为什么掌握Transformer对你很重要?
最近我在一家电商公司讨论AI客服系统的选择时,发现了个有趣的现象:技术团队对GPT-4、Claude、DeepSeek这类大模型如数家珍,但一问起“为什么这个模型适合你的业务”时,大家却都哑口无言。
理解Transformer,不是要你成为算法工程师,而是让你具备一定的判断力——明确哪个预训练模型最符合你的业务需求,知道在什么情况下应该选择微调而不是RAG,避免技术选型上的误区。
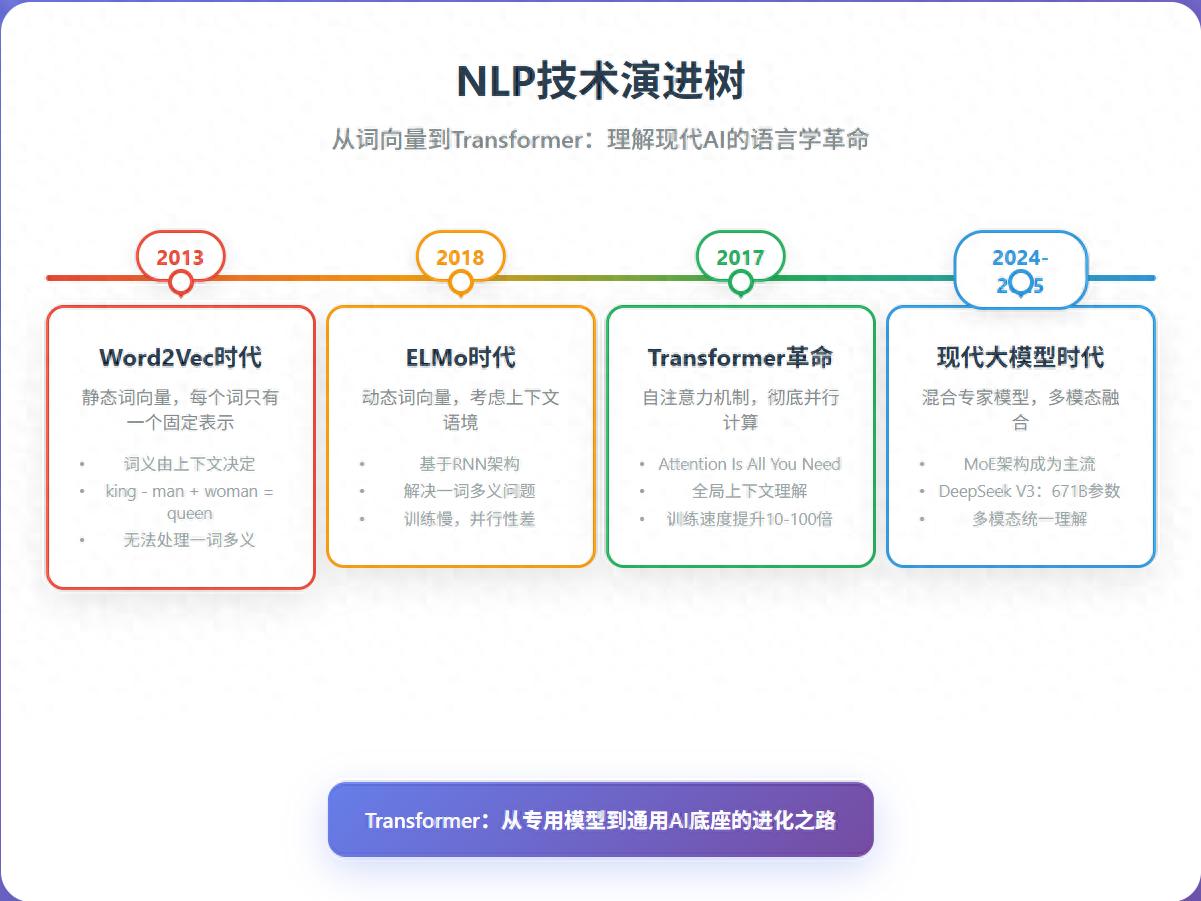
一、从Word2Vec到Transformer:NLP的三次变革1.1 第一次变革:Word2Vec(2013)
你还记得2013年Word2Vec发布时的震撼吗?它向我们揭示了一个重要观点:“词的含义是由其上下文决定的”。
# 经典的Word2Vec示例
king - man + woman = queen
这个简单的向量计算,实际上标志着NLP领域从“规则匹配”向“语义理解”的转变。不过,Word2Vec也有个明显的短板:每个词只有一个固定的向量表示,无法处理多义词的问题。
1.2 第二次变革:ELMo(2018)
ELMo恰好解决了Word2Vec的不足之处:同一个词在不同的语境中有不同的向量表达。
比如“苹果”这个词:
- “我吃了一个苹果” → 指水果
- “我买了一台苹果电脑” → 指品牌
不过ELMo是基于RNN架构的,训练速度慢、难以并行处理,且对长文本的理解能力有限。
1.3 第三次变革:Transformer(2017)
2017年,Google发表的《Attention Is All You Need》这篇论文彻底改变了游戏规则。Transformer摒弃了RNN的序列依赖,采用了自注意力机制,实现了真正的并行计算。
二、深入理解自注意力:就像词语的社交网络2.1 自注意力是什么?
试想一下你在聚会上,每个人都在关注着其他人:
- Query(你想找谁聊天):你希望找到技术专家聊聊AI
- Key(别人擅长的领域):张三在AI方面很有一套,李四则精通前端
- Value(别人能带来的价值):张三可以分享AI的经验,李四能提供前端技巧
自注意力机制就像为每个词建立了一个“社交网络”,帮助它们决定应该关注哪些“朋友”。
2.2 自注意力的数学原理
自注意力的核心公式其实非常简单:
Attention(Q, K, V) = softmax(QK^T / √d_k) V
- Q(Query):当前词想要了解什么
- K(Key):其他词可以提供的相关信息
- V(Value):其他词的实际内容
- √d_k:缩放因子,防止softmax的梯度消失
2.3 多头注意力:从多个角度观察
就好比一个人用多个感官来观察世界,多头注意力使得模型可以从不同的视角理解同一个词:
- 头1:关注语法上的关系
- 头2:关注语义的关联
- 头3:关注情感的倾向
- 头4:关注上下文的依赖
深入了解Transformer架构:从编码器到解码器
1. 编码器:理解输入数据
编码器其实由N个相同的层组成,每一层包含以下几个部分:
- 多头自注意力层:这部分的任务是建立词与词之间的关系。
- 前馈神经网络层:这是进行非线性变换的地方,目的是增强模型的表达能力。
- 残差连接:用来避免梯度消失的问题。
- 层归一化:确保训练过程的稳定性。
2. 解码器:生成输出结果
解码器在编码器的基础上又增加了:
- 掩码多头注意力:这样做是为了防止模型在生成时提前看到未来的信息。
- 编码器-解码器注意力:用来连接输入和输出。
3. 位置编码:给每个词加上“座位号”
由于Transformer缺乏RNN那种顺序信息,所以我们需要用位置编码来告诉模型词的顺序:
# 正弦位置编码
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
最新动态:Transformer的演变(2024-2025)
1. 混合专家模型(MoE):专注于专业领域
到了2024年,MoE架构逐渐成为主流。以DeepSeek V3为例:
- 6710亿参数,但是每次推理时只激活370亿参数。
- 多个专家网络,每个专家在不同领域表现突出。
- 门控网络:可以动态选择最适合的专家来处理问题。
可以把它想象成一个大型公司,里面有不同领域的专家团队,而每个项目只会调用最相关的团队。
2. 多头潜在注意力(MLA):更高效的注意力机制
DeepSeek V3采用了MLA机制,包括:
- 将KV缓存压缩到低维空间。
- 内存使用减少70%以上。
- 保持甚至提升建模性能。
3. 滑动窗口注意力:聚焦局部上下文
Gemma 3的滑动窗口注意力机制:
- 它只关注局部上下文(例如1024个词)。
- 大幅降低KV缓存的需求。
- 特别适合处理长文本。
Transformer为何成为现代AI的基础架构?
1. 架构的通用性
Transformer的“编码器-解码器”架构特别适合以下几个领域:
- 文本生成:比如GPT系列。
- 文本理解:例如BERT系列。
- 多模态应用:像GPT-4V和Gemini。
- 代码生成:比如Codex和Copilot。
- 图像处理:使用Vision Transformer。
2. 可扩展性
从1亿参数的BERT-base到1.8万亿参数的GPT-4,Transformer架构都能实现稳定的扩展。
5.3 并行计算的优点
与RNN需要按顺序处理不同,Transformer的并行计算方式让训练的速度提升了10到100倍,真的是效率飞起来了。
六、企业价值:只有理解这些,才能做出明智的选择6.1 模型选择指南
|
业务场景 |
推荐模型类型 |
理由 |
|
通用对话 |
GPT-4、Claude |
整体能力出色 |
|
中文场景 |
DeepSeek、通义千问 |
对中文的优化更贴心 |
|
代码生成 |
CodeLlama、DeepSeek-Coder |
专为这方面设计,效果佳 |
|
长文本处理 |
Claude、Gemini 1.5 |
能处理更大的上下文窗口 |
6.2 成本效益分析
- 全参数微调:效果绝佳,但费用不菲
- LoRA微调:效果接近,但能节省80%的成本
- Prompt工程:几乎零成本,但效果有限
- RAG:中等成本,效果较为稳定
6.3 技术债务预警
很多企业都会掉入这些技术陷阱:
- 过度依赖Prompt工程:业务复杂时,这种方式维护起来会很麻烦
- 盲目选择大模型:不考虑实际的业务需求和预算
- 忽视数据质量:垃圾数据进来,出来的也是垃圾
七、实战:用Python理解自注意力机制
现在让我们通过代码来直观地理解一下自注意力机制:
import torch
import torch.nn as nn
import math
class SimpleSelfAttention(nn.Module):
def __init__(self, d_model, d_k):
super().__init__()
self.d_k = d_k
self.W_q = nn.Linear(d_model, d_k)
self.W_k = nn.Linear(d_model, d_k)
self.W_v = nn.Linear(d_model, d_k)
def forward(self, x):
# x: [batch_size, seq_len, d_model]
Q = self.W_q(x) # [batch_size, seq_len, d_k]
K = self.W_k(x) # [batch_size, seq_len, d_k]
V = self.W_v(x) # [batch_size, seq_len, d_k]
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
attention_weights = torch.softmax(scores, dim=-1)
# 加权求和
output = torch.matmul(attention_weights, V)
return output, attention_weights
# 示例:理解句子"猫追老鼠,因为它饿了"
model = SimpleSelfAttention(d_model=512, d_k=64)
# 在这个例子中,"它"会更加关注"猫"而不是"老鼠"
八、总结与展望
Transformer不仅是一个简单的模型架构,它实际上代表了一种全新的计算方式:
- 从序列到并行:彻底改写了序列建模的规则
- 从局部到全局:每个词都能获取到完整的上下文信息
- 从专用到通用:统一的架构能够处理多种任务
理解Transformer,就是掌握现代AI的核心逻辑。在下一篇文章中,我们将深入聊聊如何通过Prompt工程与大型模型高效协作,教你用5%的投入获得80%的效果。
思考题:
- 在你的业务中,哪些任务最适合用Transformer架构处理?
- 如果让你设计一个电商客服系统,你会选择哪种Transformer变体?为什么呢?
- 如何在模型效果与推理成本之间找到平衡?
欢迎在评论区分享你的看法哦!