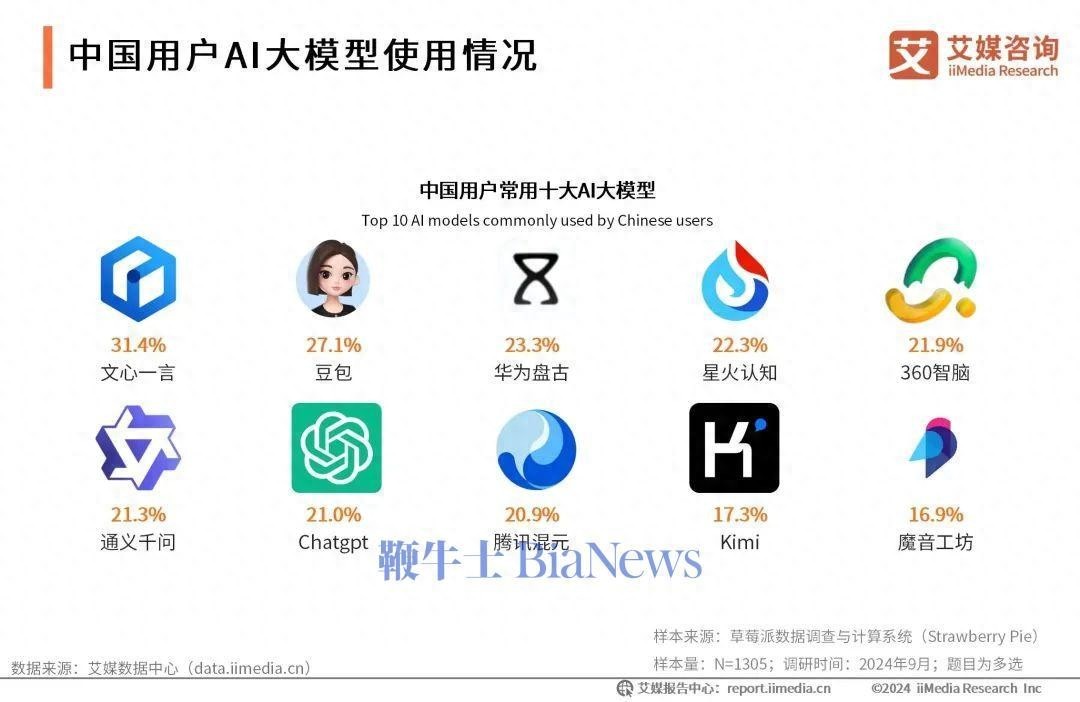
文|数据猿
DeepSeek的出现,让AI的舞台上多了一个耀眼的明星。它不仅在大语言模型(LLM)领域取得了不小的进展,更重要的是,给整个AI行业带来了新的希望,这可真是让人期待。
DeepSeek通过一系列创新的大模型,打破了传统的AI发展模式。以往大家都认为,提升AI性能就得投入更多的资金,使用昂贵的GPU,消耗大量电力和资源。可DeepSeek R1却走了一条不同的路,利用强化学习技术在微调阶段实现了性能的超越。未来的AI竞争,可能不再仅仅看谁花的钱多,而是看谁能更高效地利用资源,真正开启了AI发展的新方向。
DeepSeek的崛起告诉我们,模型的好坏不只是看规模,小而灵活的模型同样能展现出色的性能,给企业带来更优的选择。
而且,DeepSeek的成功也意味着,未来最优秀的模型会是开源的,这样对客户和AI开发者都有利,有助于实现AI的普及。现在,越来越多的国内外公司开始接入DeepSeek的大模型,纷纷希望用DeepSeek R1这样的开源模型来替代OpenAI等那些价格不菲的封闭模型。
就像特朗普说的,DeepSeek的出现并不是个威胁,而是一个“巨大”的机会,为用户、模型推理、训练、模型小型化及AI应用等带来了更多可能。未来的AI竞争,可能不再是“谁的钱多,谁的模型就强”,而是“谁能用更少的钱,达到相同甚至更好的效果”。
1. 星火燎原,更多企业与服务接入DeepSeek开源大模型
无数应用都在DeepSeek的基础上诞生,这将极大地重塑AI产业的格局。
开源意味着源代码可以在网上免费获取,用户可以自由修改和重新分发。与OpenAI等大模型不同,DeepSeek的模型是开源的,尤其是DeepSeek R1在MIT许可证下可供使用。
DeepSeek的开源特性和低计算要求大大降低了成本,加快了AI的普及步伐。用户可以在Web、iPhone/iPad、Android等平台上免费使用DeepSeek的应用,云服务商也可以轻松接入,甚至推出自家的AI大模型服务。
由于开源模型没有硬件和软件的壁垒,许多开发者热衷于用DeepSeek R1等开源模型替代OpenAI那些昂贵的封闭模型。
“DeepSeek强大的新人工智能模型不仅是中国的胜利,也是开源技术如Databricks、Mistral、Hugging Face的胜利。”开源人工智能不再只是一个非商业研究项目,而是成为了OpenAI GPT等封闭模型的可行替代方案。
DeepSeek迅速成为全球下载量最大的应用。Gartner预测,到2026年,超过80%的企业将使用生成式AI或部署相关应用。各个组织同时使用数百个模型,面临着为各种使用案例选择最佳模型的压力,正确选择AI模型并快速部署,对获得市场优势至关重要。
在不同的平台上,DeepSeek的下载量屡创新高,用户数量也在不断增加。在苹果的App Store上,DeepSeek一举超越了竞争对手OpenAI,成为下载量最大的免费应用。而在Google Play上,自1月28日以来,DeepSeek的下载量也居高不下,短短18天就达到了1600万次,几乎是OpenAI ChatGPT刚发布时的900万次下载量的两倍。
支持开源AI模型的用户对DeepSeek充满热情。基于DeepSeek-V3和R1的700多个模型现在已在AI社区平台HuggingFace上提供,下载量超过了500万次。
QuestMobile的数据表明,DeepSeek在2月1日突破了3000万的下载大关,成为历史上最快达到这一里程碑的应用。
在国外,包括英伟达、微软、亚马逊等多家美国公司也纷纷抢先采用DeepSeek-R1模型,为用户提供服务。
微软最早将DeepSeek-R1模型纳入其Azure AI Foundry和GitHub模型目录,开发者可以在Copilot + PC上本地运行DeepSeek-R1精简模型,或者在Windows的庞大GPU生态系统中运行。
亚马逊云科技AWS也宣布,用户可以在Amazon Bedrock和Amazon SageMaker这两大AI服务平台上部署“功能强大、性价比高”的DeepSeek-R1模型。
英伟达在1月30日宣布,DeepSeek-R1模型可以作为NVIDIA NIM微服务的预览版使用。NVIDIA NIM是NVIDIA AI Enterprise的一部分,旨在为跨云、数据中心和工作站提供自托管的GPU加速推理微服务,用于预训练和定制AI模型。
一些较小的美国科技公司也开始采用DeepSeek模型。美国AI初创公司Perplexity宣布接入DeepSeek模型,并与OpenAI的GPT-o1和Anthropic的Claude-3.5一同作为高性能选项。
New Relic公司通过DeepSeek集成扩展AI可观测性,帮助客户降低开发、部署和监控生成式AI应用的复杂性和成本。
自1月初推出以来,DeepSeek在印度的下载量惊人。印度的Yotta Data Services推出的“myShakti”基于DeepSeek开源AI模型构建,被誉为印度首个完全主权的B2C生成式AI聊天机器人。另一家印度公司Ola的AI平台Krutrim也将DeepSeek模型集成到其云基础设施中。
DeepSeek之所以在国外受到用户和服务商的青睐,主要因为模型开源、免费获取、低部署算力需求、API价格比GPT-4便宜10倍,甚至比Claude便宜15倍,同时速度极快,并且在某些基准测试中表现不俗,甚至超越了GPT-4。
中国的云服务商和软件企业也在接入DeepSeek,涵盖操作系统、网络安全、应用软件、云服务等多个领域,为软件和应用注入AI能力。
腾讯云、百度智能云、阿里云、京东云、青云等,以及三家基础电信企业相继接入DeepSeek大模型,麒麟软件、金蝶、用友、钉钉、南威软件、远光软件、万兴科技、超图软件等也宣布完成对DeepSeek的适配和接入。
例如,中国电子云CECSTACK智算云平台正式上线了基于MoE架构的671B全量DeepSeek-R1/V3模型,以及DeepSeek-R1的蒸馏系列Qwen/Llama模型,提供私有化部署方案,为关键行业用户提供安全可靠、智能集约的解决方案。
目前,中国电子云已在湖北机场集团进行了DeepSeek-R1的私有化部署,利用DeepSeek-R1大模型帮助湖北机场集团打造企业知识库等智能应用。
DeepSeek大模型已经与银河麒麟智算操作系统V10、银河麒麟高级服务器操作系统V10完成兼容适配,支持本地部署,并可通过Chatbox AI客户端使用DeepSeek,同时通过vscode集成DeepSeek以辅助编程。银河麒麟高级服务器操作系统V10作为云基础设施基础,已全面支持各大云厂商,实现DeepSeek的云端部署与使用。
天融信发布的DeepSeek安全智算一体机,以“算力硬件平台+智算平台”为基础,集成DeepSeek大模型,融入“计算、存储、网络、安全、智能”五大能力,旨在为客户提供高性能、安全可靠的一体化智算中心建设方案。
中国电动车巨头比亚迪即将为其汽车发布“DiPilot”辅助驾驶系统,正在将DeepSeek的人工智能集成到最先进的新驾驶员辅助系统中。
DeepSeek大模型的开源,为AI技术的普及和行业应用带来了新的机遇和动力。根据赛迪的预测,到2035年,我国人工智能核心产业的规模将达到1.73万亿元,全球占比将超过30%。
那么,企业和服务商为什么要接入DeepSeek呢?首先是工作效率提升。DeepSeek能够显著缩短推理时间,快速给出用户问题的答案。例如,在内容创作部门,输入关键信息和要求后,可以迅速生成初稿,加快市场响应速度。
其次是降低人力成本。DeepSeek能够自动完成数据标注任务,减少对基础性、重复性工作的依赖。同时,智能客服系统可以不间断地为客户解答常见问题,从而节省人力开支,提高服务的及时性和稳定性。
第三,DeepSeek还支持数据分析与决策。它能够快速分析海量市场数据和用户反馈数据,挖掘潜在规律和趋势,帮助企业制定科学合理的战略规划和市场营销策略。
最后,DeepSeek可以提供个性化服务。它能够根据用户的需求和偏好定制服务,例如在电商领域推动个性化推荐系统的普及,从而提升购物体验和满意度。
2. 推理模型兴起,芯片有望百花齐放
DeepSeek R1的迅速崛起,让一种新兴的AI模型——推理模型,成为了大家关注的焦点。随着生成式AI应用不断超越对话界面,推理模型的功能和使用范围也在不断扩大。
DeepSeek R1推理模型的与众不同之处在于能够将预训练模型转化为功能更强大的推理模型,并且成本更低、资源利用效率更高,它的运行成本仅为普通LLM的三十分之一。就像PC和互联网市场中,降价有助于推动应用一样,DeepSeek R1同样以更低的模型运行成本,推动了人工智能市场的长期增长,真是一个具有里程碑意义的时刻。
DeepSeek R1的成功证明,只要基础模型足够强大,强化学习就能在没有任何人工监督的情况下从语言模型中提取推理能力。接着,在通用大模型GPT-3、GPT-4(OpenAI)、BERT(Google)等之后,推出了OpenAI o1-mini、OpenAI o3-mini、Gemini 2.0 Flash Thinking等推理模型。
推理模型的发展,成为AI进步的重要机会。这类模型在传统的大语言模型基础上,强化了推理、逻辑分析和决策能力,通常具备强化学习、神经符号推理、元学习等技术,来增强其推理和问题解决能力。例如,DeepSeek-R1和GPT-o3在逻辑推理、数学推理和实时问题解决方面表现都相当出色。
其实呢,像OpenAI、Gemini和阿里巴巴的Qwen这些非推理大模型,适用于很多任务,比如语言生成、理解、文本分类和翻译等。它们通常是通过分析海量文本数据来进行训练,主要关注语言的生成和上下文理解,而不是那么强调深度推理的能力。
和那些能直接给出答案的通用语言模型不同,推理模型是经过专门训练的,它们在展示思考过程时会更有条理。一些模型在解决问题时不显示它们的推理过程,而有些则会明确展示出这个过程。推理的过程中,模型会把问题拆解成小问题(分解),尝试不同的解法(构思),挑选最佳方案(验证),排除不合适的方法(可能会回溯),最后找到最优解(执行/求解)。
推理模型与通用模型的对比
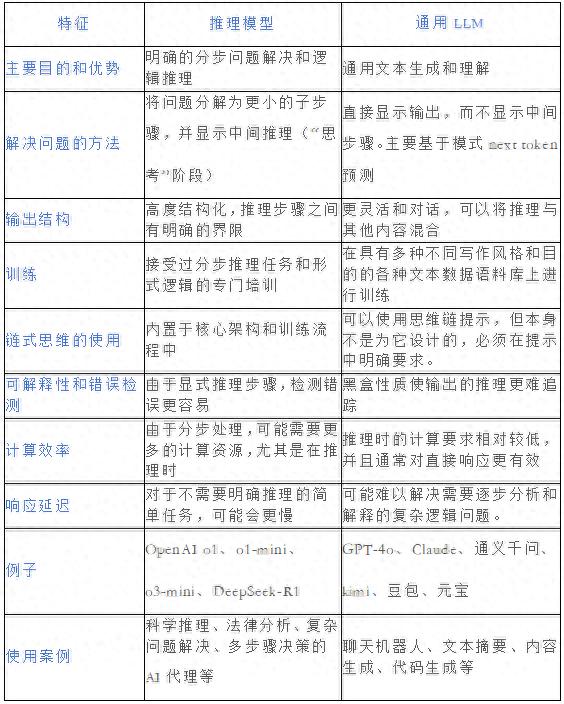
资料
随着核心技术的普及和成本降低,推理模型与普通的语言模型会越来越多样化,专注于更细分的任务。
现在,很多AI公司都在推出不同的技术来构建和优化推理模型,这也为其他企业提供了创新的机会。
提高语言模型推理能力的方法也在不断演变,比如推理时扩展(在推理阶段增加计算资源以提升输出质量)、纯强化学习(RL)、监督微调结合强化学习(SFT + RL)等。DeepSeek R1则采用了不同的技术,并推出了三种推理模型的变体:
DeepSeek-R1-Zero是基于2024年12月发布的671B预训练DeepSeek-V3模型,通过一种有两个奖励的强化学习方法进行训练,被称为“冷启动”训练。
DeepSeek-R1是DeepSeek的旗舰推理模型,建立在DeepSeek-R1-Zero之上,经过额外的监督微调阶段和进一步的强化学习训练,进一步提升了“冷启动”R1-Zero模型的性能。
而DeepSeek-R1-Distill则利用前面步骤生成的SFT数据,对开源的Qwen和Llama模型进行微调,以增强推理能力。虽然这个过程并不完全符合传统的蒸馏概念,但它是基于更大的DeepSeek-R1 671B模型的输出对较小模型(如Llama 8B和70B以及Qwen 1.5B-30B)进行训练。
DeepSeek的崛起也将影响到处理器的需求,推动推理芯片市场的增长。推理就是利用AI根据新信息进行预测或决策的过程,而不是构建或训练模型。简单来说,AI训练是工具或算法的构建,而推理则是将这些工具实际应用于现实场景。
AI训练通常需要大量的计算资源,而推理则可以使用功能较弱的芯片,经过优化后适合执行特定的任务。随着越来越多的客户使用和构建DeepSeek的开源模型,对推理芯片和计算能力的需求将会增加。
DeepSeek的测试显示,华为的HiSilicon Ascend 910C处理器的推理性能超出了预期。此外,通过对CUNN内核的手动优化,可以进一步提升性能。DeepSeek与Ascend处理器及其PyTorch库的原生支持,使得CUDA到CUNN的转换变得更加顺畅,便于将华为的硬件集成到AI工作流中。
新的Ascend 910C采用小芯片封装,主计算SoC拥有大约530亿个晶体管,采用中芯国际的第二代7nm工艺制造。
AWS推出的推理芯片主要是Inferentia系列,在提升推理效率和降低成本方面表现出色。目前AWS的Inferentia系列有两代产品。第一代Inferentia支持EC2 Inf1实例,吞吐量提升了2.3倍,推理成本降低了70%,配备多个NeuronCore,支持多种数据类型。
第二代Inferentia2在性能上有了飞跃,吞吐量提高了4倍,延迟降低,内存和带宽也大幅提升,支持更多的数据类型。配合AWS Neuron SDK,可以与热门框架集成,为AI应用提供支持。
寒武纪在推理芯片领域也取得了显著的成果,思元370芯片的表现非常亮眼。它基于7nm制程工艺,是首款采用chiplet技术的AI芯片,集成了390亿个晶体管,最大算力达到256tops(int8),相比思元270的算力翻倍,基于mluarch03架构,实际性能表现优秀。同时,它还是国内首款公开发布支持LPDDR5内存的云端AI芯片,内存带宽是上一代的三倍,访存能效极高。
思元370搭载mlu-link多芯互联技术,在分布式任务中为多芯片提供高效协作,每个芯片具备200GB/s的跨芯片通信能力。在软件平台方面,寒武纪的基础软件平台进行了升级,新增了推理加速引擎MagicMind,实现了训练与推理的一体化,提升了开发和部署的效率,降低了成本。MagicMind的设计与英伟达的TensorRT相对标,其架构和功能更为优越,性能极致、精度可靠,同时编程接口简洁,插件化设计也能满足客户的不同需求。
3.更小的成本也能训练大模型,AI训练芯片的多样化趋势
DeepSeek最显著的特点在于模型效率、训练精度和软件优先的创新,设计出更快、更精简、更智能的模型。DeepSeek的模型通过展现出与原始计算能力相当的效率,挑战了传统AI基础设施的依赖。
DeepSeek还拥有通用的大模型,如DeepSeek-V3与DeepSeek-R1,其中DeepSeek-V3包含670亿参数,在2万亿token的中英文数据集上进行训练,适用于语义分析、计算推理、问答对话等,在推理、编码、数学和中文理解等方面的表现超越了Llama2 70B base,展现出显著的泛化能力。DeepSeek V3的基准测试分数与OpenAI GPT-4o和Anthropic Claude 3.5 Sonnet相当,甚至超过了对手。
DeepSeek-R1的总参数为671亿,主要用于数学推理、代码生成和自然语言推理等需要深度逻辑分析的任务,在数学和编码等领域的表现与OpenAI o1相当,但API成本仅为后者的1/30。DeepSeek-R1的思维链推理与OpenAI o1类似,尽管它不是第一个开放推理模型,但其功能比早期的模型更为强大。
DeepSeek R1是一款开源语言模型,与OpenAI的顶尖产品相比,性能卓越且所需的计算和训练资源大幅减少,因此在科技领域引起了不小的波动。早前,微软表示将在2025年投入800亿美元用于AI基础设施,而Meta CEO扎克伯格则计划在同年投资600亿至650亿美元,用于其AI战略。
在DeepSeek的引领下,未来会有越来越多的语言模型实现商品化。随着大模型训练技术的不断进步,以及培训和运行这些模型的成本逐渐降低,预计不久的将来,LLM将会成为商品化的趋势。
DeepSeek R1模型的推出,被一些科技公司CEO视为LLM逐渐商品化的又一标志。
Hugging Face是开源AI项目的常用代码库,其联合创始人兼首席科学官Thomas Wolf表示,未来LLM将会更多地整合进与公司自身数据库相连接的智能系统中。人工智能的Airbnb和人工智能的Stripe将会出现,它们与模型本身无关,而是使模型在特定任务中变得更有用。
微软的CEO纳德拉认为,随着人工智能变得更加高效和可及,LLM的使用量会猛增,甚至可能成为一种我们无法完全满足需求的商品。
与此同时,美国软件公司Appian的CEO Matt Calkins表示,DeepSeek的成功表明AI模型将在未来更多地商品化。许多公司将能够实现具有竞争力的AI,而高成本必然会对大模型的销售产生影响。
显然,英伟达在大模型训练的AI芯片市场中占据主导地位,但竞争比以往任何时候都要激烈。瑞穗证券估计,英伟达在AI芯片市场的份额高达70%到95%,用于训练和部署语言模型的AI芯片。78%的毛利率显示了英伟达的定价能力,而竞争对手英特尔和AMD在最新季度的毛利率分别为41%和47%。
英伟达的旗舰AI GPU H100,加上该公司的CUDA软件,使其在竞争中占据了领先地位,转向其他解决方案几乎是不可想象的。
尽管英伟达的GPU市场从30亿美元增长到约900亿美元,但该公司承诺每年推出一种新的AI芯片架构,而不是像以前那样每隔一年发布一次,并推出更深入的AI软件集成。
从跨国公司到新兴初创企业,都在争夺AI芯片市场份额,预计在未来五年内市场规模将达到4000亿美元。
小模型的崛起:AI应用的新机遇
AMD最近在游戏GPU方面的表现不俗,同时也开始将这些技术应用到数据中心的人工智能上。它的明星产品Instinct MI300X,CEO苏姿丰博士特别强调了它在推理方面的优秀表现,而并不只是单纯和英伟达争夺训练市场。微软已经在使用AMD的Instinct GPU来支持其Copilot模型,预计今年AMD的AI芯片销量会突破40亿美元。
与此同时,英特尔也不甘示弱,刚刚发布了第三代AI加速器Gaudi 3。英特尔直接将其与竞争对手进行对比,宣称在推理方面更具成本效益,且在模型训练上比英伟达H100更快。尽管英特尔在AI芯片市场的份额还不到1%。
不过,软件的普及可能是一个主要障碍。AMD和英特尔正在参与一个叫做UXL基金会的行业联盟,致力于创建一个免费的替代方案来替代Nvidia的CUDA,以更好地控制AI应用的硬件。
未来,英伟达可能会与其最大的客户在芯片领域展开竞争。尽管云服务大客户如Google、Microsoft和亚马逊等的GPU采购占了英伟达收入的40%以上,它们也在努力构建自己的处理器。
AWS也首次推出了针对大模型训练的AI芯片Tranium,客户可以通过AWS租用该芯片,苹果公司是首个用户。
自2015年以来,Google一直在使用张量处理单元(TPU)来训练和部署其AI模型。现在已经有六个版本的Trillium芯片,支持包括Gemini和Imagen在内的多种模型。谷歌还在使用英伟达的芯片,并通过其云服务提供这些芯片。
微软也在研发自己的AI加速器和处理器,名为Maia和Cobalt。OpenAI正在与Broadcom合作,设计其定制芯片,这款芯片预计将在2026年由台积电开始量产。
摩根大通的分析师认为,为大型云服务商定制芯片的市场价值可能达到300亿美元,未来每年有可能增长20%。
越来越多的开发者开始把AI工作从服务器转移到个人的笔记本电脑、PC和手机上。比如,像OpenAI开发的大型模型需要大量强大的GPU集群进行推理,而像Apple和微软这样的公司则在开发“小模型”,它们消耗更少的电力和数据,能够在电池供电的设备上运行。Apple和Qualcomm也在更新芯片,以提升AI的运算效率,增加了专门用于AI的神经处理器部分。
4.小模型崭露头角,前景广阔
越来越多的公司开始推出SLM(小型模型),挑战“越大越好”的传统观点。DeepSeek R1推理模型首次亮相时,以低廉的训练成本展现了出色的性能。DeepSeek的成功证明,规模小且灵活的模型也能与大型AI模型一较高下,甚至有可能超越它们。
SLM以更低的成本和更高的效率,可能改变企业AI部署的方式,让预算有限的中小企业也能享受到高级AI模型的功能。
DeepSeek还推出了多款小模型,比如DeepSeek-Coder,这是一系列代码语言模型,从1B到33B不等,训练上使用了2万亿个token,数据集包括87%的代码和13%的中英文自然语言,主要用于代码编写等任务,在多种编程语言和基准测试中表现优异。
DeepSeek-VL则是一个开源的视觉-语言模型,采用混合视觉编码器,能够处理高分辨率图像,提供1.3B和7B两种模型,在视觉-语言基准测试中表现出色,适用于视觉问答等多种任务。
DeepSeek还推出了蒸馏的小模型系列,如Qwen系列和Llama系列等,像DeepSeek-R1-Distill-Qwen-7B在多个推理基准测试中超过了同规模模型,DeepSeek-R1-Distill-Llama-70B的推理速度也显著提升,接近顶级闭源模型。这些小模型的参数量在15B到70B之间,计算和内存消耗上都大幅降低,依然保持了大模型的核心推理能力,能够在教育和医疗等领域发挥作用。
DeepSeek的这些衍生和蒸馏的小模型在多个领域展现出广泛的应用潜力,具有很强的示范效果。未来,AI公司可以通过开发不同的小模型,进一步推动AI的应用。
蒸馏模型通过减少参数和计算复杂度,显著提高了推理速度。比如,DeepSeek-R1-Distill-Qwen-7B的推理速度比原始模型提升了约50倍,能够在资源有限的设备上高效运行。
小模型的部署成本大幅降低,适合在计算资源有限的场景中使用。DeepSeek的蒸馏模型在保持高性能的同时,显著降低了训练和推理的开销,助推了AI技术的普及。
蒸馏模型的多任务适应性使得其可以根据不同任务优化性能,适用于自然语言处理、代码生成、数学推理等多种场景。小模型的轻量化设计使得它们能够在智能手机、智能手表等边缘设备上运行,实现实时决策和低能耗操作,适合于自动驾驶、健康监测等快速响应的场合。
在教育领域,蒸馏模型能够提供个性化学习推荐和智能辅导,帮助学生制定学习路径,提高学习效率。而在医疗影像分析和疾病预测中,蒸馏模型也展现了优越性,能够实时提供医疗建议和辅助诊断,提高医疗服务质量。
目前,市场上涌现出不少创新技术,通过开源模型和新技术,大幅降低了模型的训练和小型化成本。
例如,斯坦福大学和华盛顿大学的团队训练了一个以数学和编程为重点的语言模型,其性能与OpenAI和DeepSeek R1推理模型相当,而构建成本仅需50美元的云计算积分。
该团队利用了一个现成的基础模型,并将Google的Gemini 2.0 Flash Thinking Experimental模型提炼到其中,提炼过程包括从大模型中提取相关信息,转移到小模型。
再比如,Hugging Face推出了名为Open Deep Research的工具,旨在与OpenAI Deep Research和Google Gemini Deep Research竞争,利用免费开源的LLM,训练只需约20美元的云计算积分,而且不到30分钟就能完成。
Hugging Face的模型在通用AI助手(GAIA)基准测试中取得了55%的准确率,而OpenAI Deep Research的准确率在67%到73%之间,具体取决于回应方式。
阿里巴巴的李飞飞团队基于阿里云的通义千问(Qwen)模型进行监督微调,成功开发了s1模型,训练成本不到50美元,使用16张英伟达H100 GPU,仅耗时26分钟。DeepSeek通过蒸馏技术将大模型的能力传递给小模型,而李飞飞团队则通过微调现有大模型,结合高质量数据和扩展技术,实现了低成本、高性能的模型训练。
以DeepSeek为代表的开源模型通过低廉的API服务费用,正在挑战传统的闭源大模型,未来有望重塑AI市场的格局。
低成本高效的大模型,为AI应用公司、云服务商和用户提供了新的机遇。AI应用公司可以基于新模型开发创新产品,提高投资回报;云服务商加速布局开源大模型生态,抢占市场;而用户则可以利用开源大模型,训练和部署属于自己的模型。