在使用像Cursor和Trae这样的AI编程工具时,确实能帮助我们更精准地获得建议,这主要得益于它们背后的索引代码库,比如Cursor的codebase。
不过,这里也有个隐忧:如果你的项目里有一些生产环境的敏感信息,比如数据库密码或API密钥,这些信息可能会被上传到云端,难免会有泄露的风险吧?
那在使用这些工具的时候,有没有办法避免这些潜在的风险呢?比如说,能不能像.gitignore文件那样,忽略某些不想上传的文件呢?
接下来,我们来聊聊MCP。这是一种既高效又通用的协议,能够让AI安全、快速地访问本地数据。举个例子,我们通过将Sentry接入MCP,成功实现了Sentry监控服务和Cursor助手的无缝集成,达成了对应用崩溃率的智能分析以及对崩溃问题的详细查询,这样大家就能更好地理解MCP的运作方式了。
1. MCP简介
MCP(模型上下文协议)是由Anthropic推出的开放标准,目的是统一大型语言模型(LLM)和外部数据源、工具之间的通信方式。
借助MCP,我们能够构建服务器,让LLM应用可以轻松获取数据和功能。具体来说,MCP服务器能做到以下几点:
- 通过资源(Resources)暴露数据,就像GET请求的接口,能把信息加载到LLM的上下文中;
- 通过工具(Tools)提供功能,类似于POST请求的接口,能执行代码或产生其他效果;
- 通过提示(Prompts)定义交互模式,像一个服务列表,方便查询服务器提供哪些服务以及需要什么参数。
MCP的主要目标就是解决当前AI模型因为数据孤岛而无法充分发挥其潜力的问题。借助MCP,AI应用能够安全地访问并操作本地和远程数据,为AI应用打开了通往万物的通道。
在如今的AI应用开发中,我们常常需要让AI模型和现有的业务系统互动,比如查询数据库、调用监控系统的API、分析日志等。MCP提供了一种标准化的方法,让AI模型能够“看到”外部世界的数据。
2. MCP的核心优势
- 能力扩展:使AI模型能够超越训练数据的限制,获取实时的外部信息;
- 标准化接口:提供统一的接口规范,简化服务集成的过程;
- 安全可控:通过明确的权限管理和访问控制,确保数据安全;
- 低代码集成:减少编写胶水代码的需求,从而降低开发成本;
- 实时数据访问:让AI能够基于最新数据做出决策和回应。
3. MCP可以实现的功能举例
以下是一些官方提供的或通过MCP协议实现的服务工具,都是用TypeScript或Python SDK做的,详细信息和更多例子可以查看官方文档:官方文档(https://github.com/modelcontextprotocol/servers)
- AWS知识库检索 – 使用Bedrock Agent Runtime从AWS知识库中提取信息;
- Brave搜索 – 利用Brave的搜索API进行网络和本地搜索;
- EverArt – 使用多种模型生成AI图像;
- Everything – 参考/测试服务器,包含提示、资源和工具;
- Fetch – 获取和转换网络内容,提高LLM的使用效率;
- 文件系统 – 提供可配置访问控制的安全文件操作;
- Git – 用于读取、搜索和操作Git仓库的工具;
- GitHub – 仓库管理、文件操作和GitHub API集成;
- GitLab – GitLab API,支持项目管理;
- Google Drive – 提供Google Drive文件访问和搜索功能;
- Google地图 – 提供位置服务、路线指引和地点详情;
- 记忆系统 – 基于知识图谱的持久化记忆系统;
- PostgreSQL – 只读数据库访问,具备架构检查功能;
- Puppeteer – 浏览器自动化和网页抓取;
- Redis – 与Redis键值存储交互;
- Sentry – 从 http://Sentry.io 检索和分析问题;
- Sequential Thinking – 通过思维序列进行动态和反思性问题解决;
- Slack – 频道管理和消息发送功能;
- SQLite – 数据库交互和商业智能功能。
4. 以Sentry服务为例的MCP实践
4.1 背景与实现的功能
在我们的项目中,我们选择Sentry作为bug上报的平台。通过接口获取的数据与MCP服务结合,让我们更方便地分析崩溃原因和查询崩溃率等信息。官方提供的示例程序,为我们进一步扩展Sentry功能提供了极好的参考。有了Sentry接入MCP协议,我们只需将bug ID或问题链接提交给Cursor,就能快速获取详细的bug信息及可能的解决方案,这大大提高了问题排查和解决的效率。
此外,我们还将Sentry的统计信息接入系统,赋予Cursor访问各版本崩溃率数据和全版本综合崩溃率数据的权限。AI根据这些数据能够生成直观的对比图表或数据。
为了进一步增强Sentry MCP工具的功能,我们将后端应用性能监控(APM)数据也整合进来了。这样,Cursor就能直接查询到更全面、更丰富的应用信息,全方位提升了数据的可获取性和利用价值。
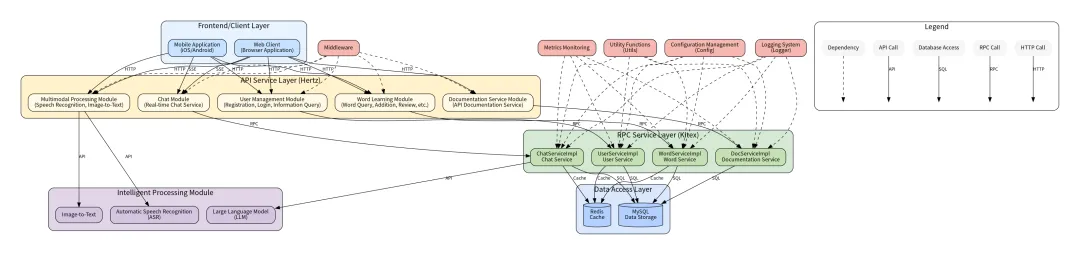
4.2 Sentry MCP服务组件功能结构
Sentry MCP服务组件的功能结构图如下:
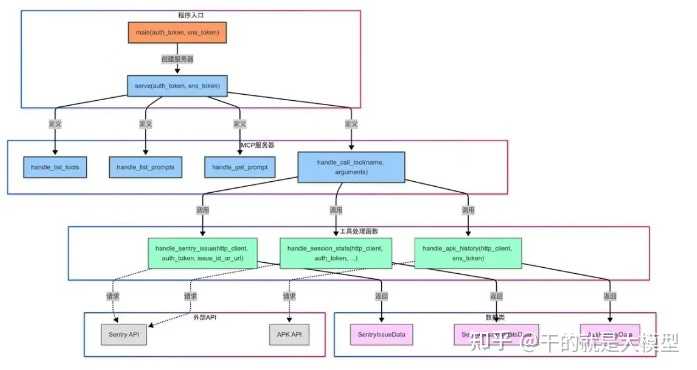
- 程序流程 – 程序入口:通过main函数启动程序,接收Sentry和SNS身份验证令牌;- 服务器创建:serve函数创建MCP服务器并注册各种处理程序;- 请求处理:当AI助手发起工具调用请求时,handle_call_tool函数根据工具名称进行请求的路由分发;- 数据获取:专门的处理函数通过外部API获取数据,并将其封装在相应的数据类中;- 响应生成:数据类提供方法将数据转换为所需的格式,返回给AI助手。
- 主要组件数据类:- SentryIssueData:存储Sentry错误和崩溃信息,包括标题、ID、状态和堆栈跟踪;- SentrySessionStatsData:存储Sentry会话统计数据,如崩溃率、用户数等;- ApkHistoryData:存储APK检测历史数据,包括版本、大小和各组件信息。处理函数:- handle_sentry_issue:获取特定Sentry问题详情;- handle_session_stats:获取会话统计数据,如崩溃率和稳定性指标;- handle_apk_history:获取APK历史数据,包括大小和组件分析。服务器配置:- serve:配置MCP服务器,注册工具、提示和处理程序;- handle_call_tool:分发工具调用请求到相应的处理函数。
4.3 功能实现
MCP协议提供Python、Java、Kotlin等语言的SDK,考虑到Python是最常用的,我们这里用Python SDK来实现。
4.3.1 安装MCP
pip install mcp
4.3.2 功能入口
创建server.py文件作为服务程序的代码文件,下面列出的代码都是在这个文件中。main函数是程序的入口函数:
#server.py
def main(auth_token: str, sns_token: str = None):
async def _run():
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
server = await serve(auth_token, sns_token)
await server.run(
read_stream,
write_stream,
InitializationOptions(
server_name="sentry",
server_versinotallow="0.4.1",
capabilities=server.get_capabilities(
notification_optinotallow=NotificationOptions(),
experimental_capabilities={},
),
),
)
asyncio.run(_run())
if __name__ == "__main__":
# 直接调用main函数
main()
main函数的功能包括:
- 创建基于标准输入输出的服务器通信通道;
- serve函数初始化MCP服务器实例;
- 配置服务器的初始化选项;
- 启动服务器的运行循环。
4.3.3 服务器实例创建
以下是简化版的serve函数:
#server.py
async def serve(auth_token: str, sns_token: str = None) -> Server:
server = Server("sentry")
http_client = httpx.AsyncClient(base_url=SENTRY_API_BASE)
apk_http_client = httpx.AsyncClient(base_url=APK_API_BASE)
@server.list_prompts()
async def handle_list_prompts() -> list[types.Prompt]:
prompts = [
types.Prompt(
name="sentry-issue",
descriptinotallow="通过ID或URL获取Sentry问题详情",
arguments=[
],
),
types.Prompt(
name="session-stats",
descriptinotallow="获取Sentry会话统计数据和崩溃率",
arguments=[
],
),
types.Prompt(
name="apk-history",
descriptinotallow="获取APK检测历史数据",
arguments=[]
)
]
return prompts
@server.get_prompt()
async def handle_get_prompt(
name: str, arguments: dict[str, str] | None
) -> types.GetPromptResult:
if name == "sentry-issue":
...
return issue_data.to_prompt_result()
elif name == "session-stats":
...
return stats_data.to_prompt_result()
elif name == "apk-history":
...
return history_data.to_prompt_result()
else:
raise ValueError(f"Unknown prompt: {name}")
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
tools = [
types.Tool(
name="get_sentry_issue",
),
types.Tool(
name="get_sentry_session_stats",
) ,
types.Tool(
name="get_apk_history",
)
]
return tools
@server.call_tool()
async def handle_call_tool(
name: str, arguments: dict | None
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name == "get_sentry_issue":
return issue_data.to_tool_result()
elif name == "get_sentry_session_stats":
return stats_data.to_tool_result()
elif name == "get_apk_history":
return history_data.to_tool_result()
else:
raise ValueError(f"Unknown tool: {name}")
return server
serve函数是MCP Sentry服务的核心,负责创建、配置并返回一个完整的MCP服务器实例。它通过四个主要组件构建了完整服务:
- 提示列表:定义可用的查询服务(问题详情、崩溃率统计、APK历史);
- 提示处理器:执行查询逻辑并返回结果;
- 工具列表:注册可调用的工具集合;
- 工具调用处理器:处理具体工具调用并获取数据,整体功能是将Sentry和APK监控系统的复杂API调用封装成结构化接口,便于AI助手获取崩溃报告、稳定性数据和APK分析信息。
4.4 三个查询功能的实现
4.4.1 Sentry问题详情获取功能实现
handle_sentry_issue函数是MCP Sentry服务的核心组件之一,通过问题ID或URL获取Sentry问题的详细信息,包括问题标题、状态、级别、首次和最后出现时间、事件数量,以及最关键的堆栈跟踪信息。下面是获取问题详情的主函数功能:
#server.py
asyncdef handle_sentry_issue(
http_client: httpx.AsyncClient, auth_token: str, issue_id_or_url: str
) -> SentryIssueData:
try:
# 提取问题ID
issue_id = extract_issue_id(issue_id_or_url)
# 获取问题详情
response = await http_client.get(
f"organizations/xxx/issues/{issue_id}/",
headers={"Authorization": f"Bearer {auth_token}"}
)
if response.status_code == 401:
raise McpError(
"Error: Unauthorized. Please check your MCP_SENTRY_AUTH_TOKEN token."
)
response.raise_for_status()
issue_data = response.json()
# 获取问题哈希值
hashes_response = await http_client.get(
f"organizations/xxx/issues/{issue_id}/hashes/",
headers={"Authorization": f"Bearer {auth_token}"},
)
hashes_response.raise_for_status()
hashes = hashes_response.json()
ifnot hashes:
raise McpError("No Sentry events found for this issue")
# 获取最新事件并生成堆栈跟踪
latest_event = hashes[0]["latestEvent"]
stacktrace = create_stacktrace(latest_event)
# 返回格式化的问题数据
return SentryIssueData(
title=issue_data["title"],
issue_id=issue_id,
status=issue_data["status"],
level=issue_data["level"],
first_seen=issue_data["firstSeen"],
last_seen=issue_data["lastSeen"],
count=issue_data["count"],
stacktrace=stacktrace
)
except SentryError as e:
raise McpError(str(e))
except httpx.HTTPStatusError as e:
raise McpError(f"Error fetching Sentry issue: {str(e)}")
except Exception as e:
raise McpError(f"An error occurred: {str(e)}")
为了简化使用并确保数据的一致性,我们在最新版本中对环境和项目做了固定配置:
轻松上手!Sentry与MCP集成的实用指南
- 环境(environment):设定为 [“flavorsOnline_arm64”]
- 项目 ID(project):设定为 [6]
这样一来,用户在查询的时候就不用每次都重新输入这些参数,省事多了。
4.4.2 获取Sentry会话统计数据的功能实现
handle_session_stats函数是Sentry MCP服务中的另一个重要部分,专门负责提取应用的会话统计数据,比如崩溃率、用户数量、会话时长等。这些指标对于我们监控应用的稳定性、分析版本质量和用户体验都是相当重要的。
#server.py
asyncdef handle_session_stats(
http_client: httpx.AsyncClient,
auth_token: str,
organization: str,
field: list[str],
start: str = None,
end: str = None,
environment: list[str] = None,
stats_period: str = None,
project: list[int] = None,
per_page: int = None,
interval: str = None,
group_by: list[str] = None,
order_by: str = None,
include_totals: int = 1,
include_series: int = 1,
query: str = None
) -> SentrySessionStatsData:
try:
# 构建查询参数
params = {"field": field}
if start:
params["start"] = start
if end:
params["end"] = end
if environment:
params["environment"] = environment
if stats_period:
params["statsPeriod"] = stats_period
if project:
params["project"] = project
if per_page:
params["per_page"] = per_page
if interval:
params["interval"] = interval
if group_by:
params["groupBy"] = group_by
if order_by:
params["orderBy"] = order_by
if include_totals isnotNone:
params["includeTotals"] = include_totals
if include_series isnotNone:
params["includeSeries"] = include_series
if query:
params["query"] = query
# 发送请求
response = await http_client.get(
f"organizations/{organization}/sessions/",
headers={"Authorization": f"Bearer {auth_token}"},
params=params
)
if response.status_code == 401:
raise McpError(
"Error: Unauthorized. Please check your MCP_SENTRY_AUTH_TOKEN token."
)
response.raise_for_status()
data = response.json()
stats_data = SentrySessionStatsData(
organizatinotallow=organization,
start_time=data.get("start", ""),
end_time=data.get("end", ""),
intervals=data.get("intervals", []),
groups=data.get("groups", []),
query=data.get("query", "")
)
report_file_path = generate_crash_rate_html_report(
data=stats_data,
params=params
)
stats_data.report_file_path = report_file_path
return stats_data
except httpx.HTTPStatusError as e:
raise McpError(f"Error fetching Sentry session statistics: {str(e)}")
except Exception as e:
raise McpError(f"An error occurred: {str(e)}")
- 功能亮点:
– 灵活的查询参数:可以使用多种筛选条件,比如时间范围、环境、项目ID、查询表达式等;
– 丰富的统计指标:提供多种与会话相关的指标,如会话总数(sum(session))、独立用户数(count_unique(user))、平均会话时长(avg(session.duration))、会话时长分位数(p50/p75/p90/p95/p99/max(session.duration))、用户崩溃率(crash_rate(user))、会话崩溃率(crash_rate(session))、用户崩溃免除率(crash_free_rate(user))、会话崩溃免除率(crash_free_rate(session));
– 数据系列和汇总:支持时间序列数据和汇总数据,并能生成html文件,方便进行趋势分析和总体评估;
– 分组与排序:可以对数据进行分组和排序,便于比较不同维度的数据。
通过这些功能,我们能利用cursor监控和分析应用的稳定性,及时发现潜在问题,提供数据支持来提升用户体验和应用质量。
4.4.3 APK检测历史数据获取功能实现
handle_apk_history函数在Sentry MCP服务中负责获取和分析APK的历史检测数据。它能追踪应用各个版本的体积变化、组件大小分布和版本更新情况。
#server.py
asyncdef handle_apk_history(
http_client: httpx.AsyncClient,
sns_token: str
) -> ApkHistoryData:
try:
response = await http_client.get(
"getHistory/0",
headers={"sns_token": sns_token}
)
if response.status_code == 401:
raise McpError(
"Error: Unauthorized. Please check your SNS token."
)
response.raise_for_status()
data = response.json()
# 从新的API响应结构中获取数据
apkData = ApkHistoryData(
apk_list=data.get("data", {}).get("apkList", []),
total_count=data.get("data", {}).get("totalCount", 0)
)
report_file_path = generate_apk_history_html_report(
data=apkData
)
apkData.report_file_path = report_file_path
return apkData
except httpx.HTTPStatusError as e:
raise McpError(f"Error fetching APK history data: {str(e)}")
except Exception as e:
raise McpError(f"An error occurred: {str(e)}")
这些信息来源于我们的应用性能监控(APM)接口,详细展示了APK的相关内容,包括:
- 基本信息:APK的版本、版本号和名称;
- 大小详情:APK的总大小与实际下载大小;
- 组件分析:对APK各个组件(如Assets、Dex、Lib及资源部分)的大小进行分析;
- 元数据:包括时间戳、文件路径、备注信息和特性描述等。此外,这些数据以结构化形式整合,输出到html文件中,方便后续深入分析和展示。
4.4.4 在cursor中集成
要在cursor的设置中添加MCP服务,选择Type为command,然后在Command中输入python执行程序,保存后就能在cursor对话框中使用。具体的界面如下图所示:
4.4.4 在cursor中集成
在cursor的设置中添加MCP服务,Type选择command,然后在Command中输入python执行程序,保存后,可以在cursor对话框中使用,添加的界面如图所示:
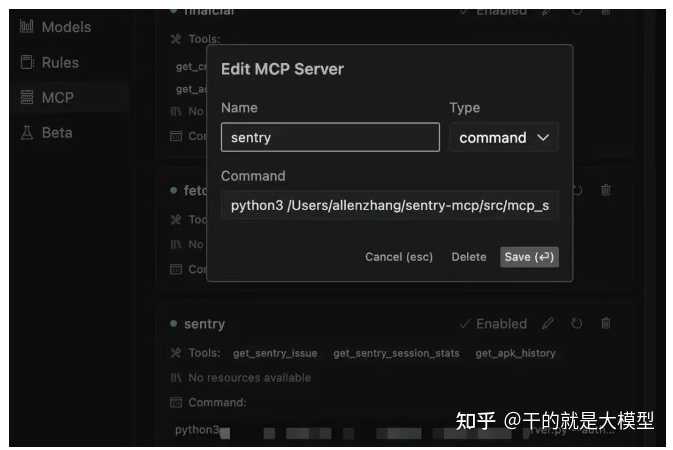
选择Type时,还有一种是sse(服务器发送事件,Server-Sent Events),这是一种允许服务器实时向客户端推送数据的Web API。它建立了单向的HTTP连接,服务器可以在有新数据时随时发送消息,而客户端只需监听。我们在Sentry MCP中主要使用主动获取数据的方式,所以选择了command命令行。完整的command命令如下:
python3 /Users/xxx/server.py --auth-token xxx sns-token xxx4.5 效果展示
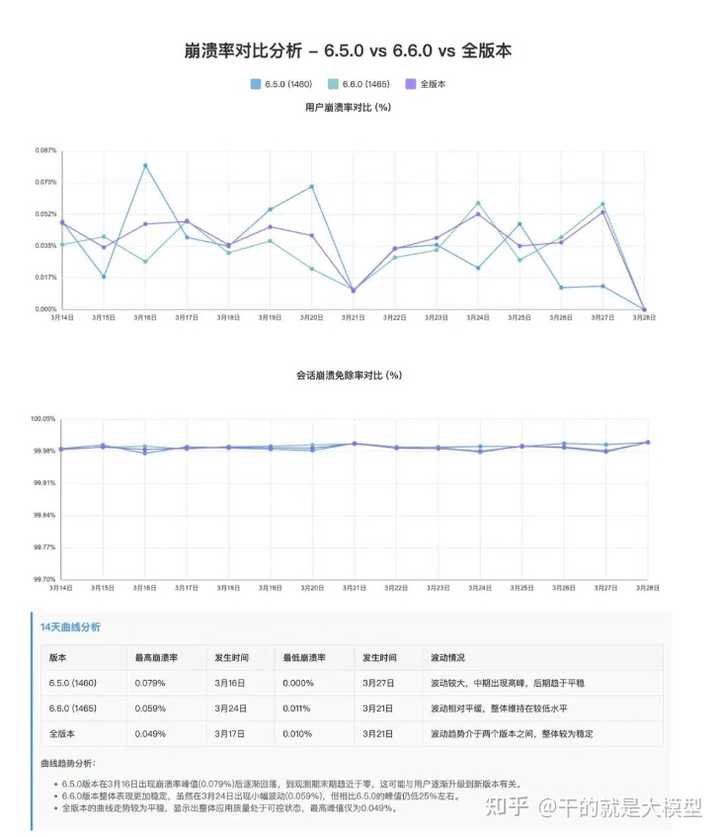
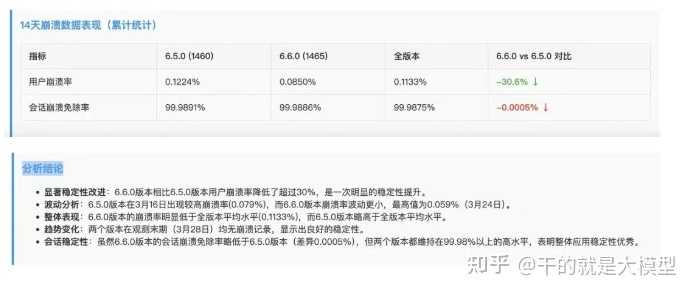
4.5.1 查询崩溃率数据
通过handle_session_stats函数,我们可以轻松获取应用的崩溃率数据。比如在cursor中输入:帮我查询6.6.0和6.5.0版本最近14天的崩溃率详情,生成的html结果如下:
4.5.2 查询bug详情
在cursor中输入:帮我查询这个bug的详细信息644,结果如下:
Sentry问题分析报告
我已经查询到关于您提供的Sentry问题的详细信息。这是一个发生在flavorsOnline_arm64环境中的项目6的错误:
错误概览
错误类型:RemoteServiceException$CannotDeliverBroadcastException
错误描述:can't deliver broadcast
问题ID:644
状态:未解决
严重级别:致命(fatal)
首次出现:2024-10-03 04:36:33
最近出现:2025-03-21 10:44:02
事件计数:18次
堆栈跟踪
错误发生在Android系统的广播传递机制中,堆栈跟踪显示:
ZygoteInit.java:954 in main
RuntimeInit.java:559 in run
Method.java:None in invoke
ActivityThread.java:8395 in main
Looper.java:300 in loop
Looper.java:211 in loopOnce
Handler.java:106 in dispatchMessage
ActivityThread.java:2349 in handleMessage
None:0 in -$$Nest$mthrowRemoteServiceException
ActivityThread.java:2087 in throwRemoteServiceException
崩溃率分析
根据过去7天的会话统计:
崩溃率:约0.0001 (0.01%)
无崩溃率:约0.9999 (99.99%)
总会话数:1,239,555
虽然崩溃率较低,但由于这是一个致命错误,且在近期(3月21日)仍有发生,应该引起关注。
问题分析
错误性质:这是一个与Android广播机制相关的RemoteServiceException,表明应用尝试发送一个广播,但系统无法传递。
可能原因:
广播接收器不存在或已被卸载
目标组件权限问题
系统资源限制导致广播传递失败
特定于arm64架构的问题
影响范围:
错误发生在flavorsOnline_arm64环境
相对较低的崩溃率(0.01%)表明这可能是特定设备或特定条件下才会触发的问题
建议解决方案
防御性编程:
在发送广播前检查接收器是否存在
使用try-catch块包装广播发送代码
错误位置定位:
检查ActivityThread.java:2087处的throwRemoteServiceException方法调用点
找出应用中哪些地方发送了可能触发此异常的广播
设备/版本针对性修复:
由于这个问题仅在arm64架构出现,可以考虑为该架构添加特定的兼容性代码
监控计划:
虽然崩溃率低,但应继续监控,特别是在新版本发布后
由于这个错误是与Android系统广播机制相关的,建议查看应用中所有发送广播的代码,尤其是在6.6.0版本中新增或修改的部分,确保它们都有适当的错误处理机制。
需要我进一步分析这个问题的特定方面吗?
4.5.3 查询应用性能监控(APM)数据
在cursor中输入:帮我查询6.6.0的性能数据,并与6.5.0版本对比。生成的html结果如下:
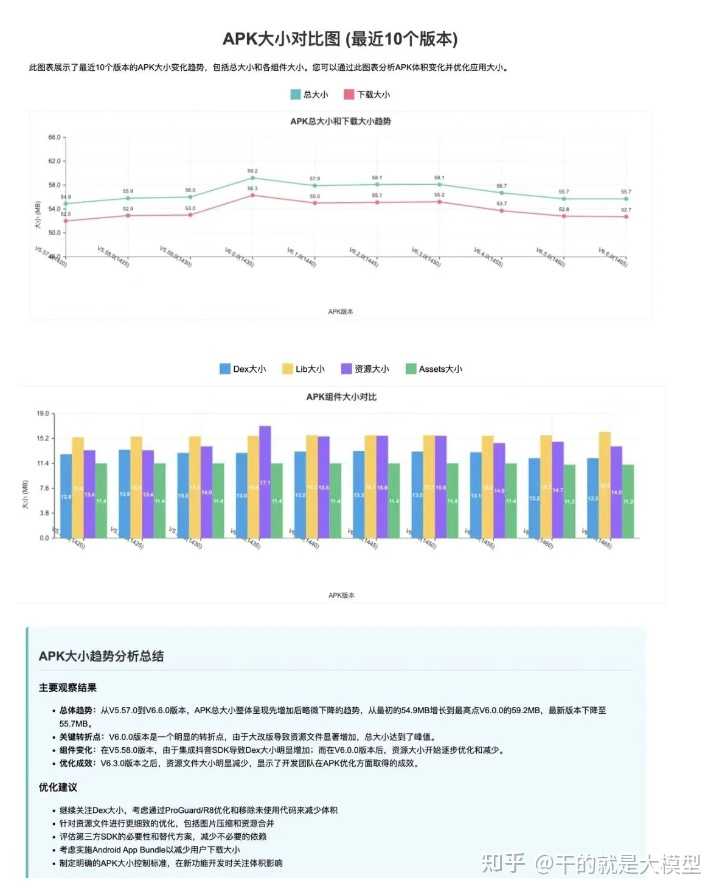
从结果中可以看出,通过MCP协议,本地数据得到了充分的利用,为AI访问本地数据提供了可能。这使得AI能够深入挖掘并高效利用这些数据。
5.总结
本文简要介绍了MCP协议。MCP是一种高效而通用的协议,可以让AI安全、快速地访问本地数据。通过Sentry接入MCP的实例,我们成功实现了Sentry监控服务与cursor助手的集成,达成了对应用崩溃率的智能分析以及崩溃问题的详细查询,帮助大家更好地理解MCP的工作原理。
希望本文能帮助读者更深入地了解MCP协议,并熟练掌握将本地数据接入AI的方法。期待这篇技术分享对您了解和运用MCP有所帮助。
零基础入门AI大模型
今天给大家准备了一系列AI大模型的资源,包括入门学习的思维导图、精选的学习书籍手册、视频教程和实战学习的录播视频,免费分享给大家。
1.学习路线图
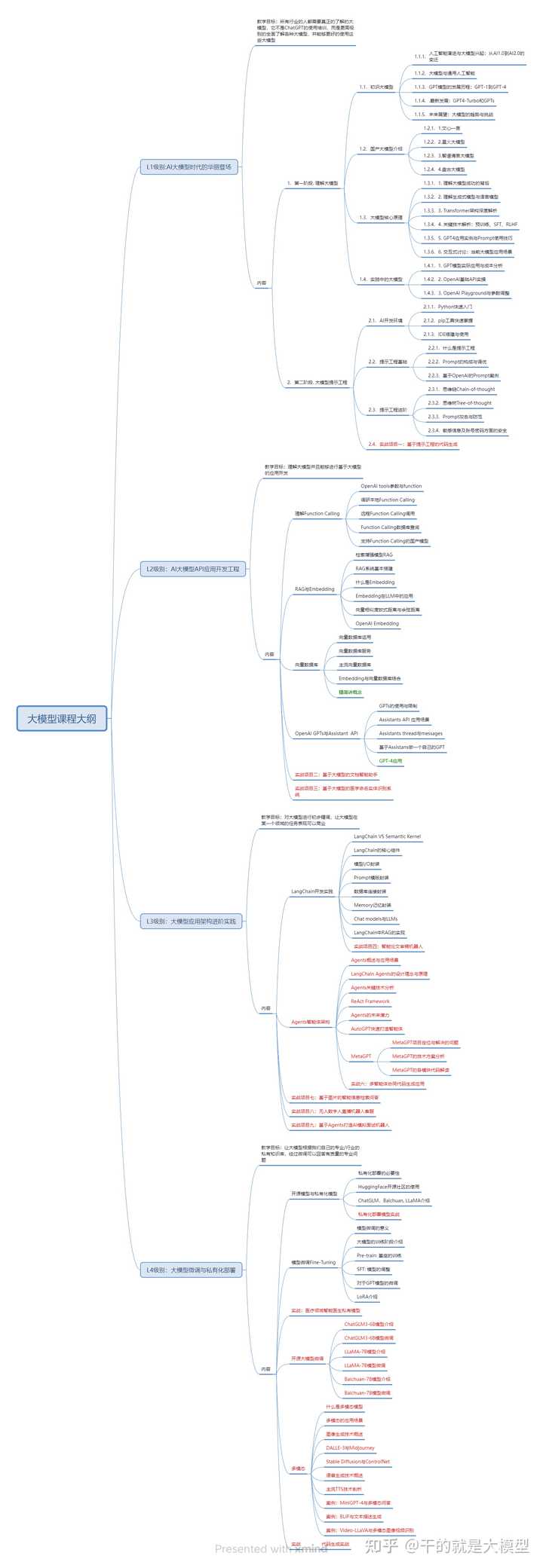
第一阶段:从大模型的系统设计入手,讲解主要方法;
第二阶段:通过大模型提示词工程,从Prompts角度更好地发挥模型的作用;
第三阶段:利用阿里云PAI平台进行电商领域虚拟试衣系统的开发;
第四阶段:以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段:在大健康、新零售和新媒体领域进行大模型微调开发;
第六阶段:以SD多模态大模型为主,搭建文生图的小程序案例;
第七阶段:通过星火大模型、文心大模型等成熟大模型构建行业应用。
2.视频教程
虽然网上有很多学习资源,但大多数都不完整。这是我整理的关于大模型的视频教程,涵盖了上面路线图中的每一个知识点,都有配套的视频讲解。
(视频已经打包在一起,总共300多集,不能一一展开。)
3.技术文档和电子书
这里整理了与大模型相关的PDF书籍、行业报告和文档,总共有几百本,都是行业内最新的资料。

4.LLM面试题和面经合集
这部分整理了最新的大模型面试题和大厂offer面经的合集。

学会后的收获:
• 可实现基于大模型的全栈工程(前端、后端、产品经理、设计、数据分析等),通过这门课程获得多方面的能力;
• 能够利用大模型解决实际项目需求:在大数据时代,企业需要处理大量数据,掌握大模型技术可以更好地分析数据,提高决策的准确性;
• 基于大模型和企业数据的AI应用开发,掌握GPU算力、硬件、LangChain开发框架和项目实战技能,学习Fine-tuning技术进行大模型的垂直训练;
• 提高程序员的编码能力:大模型应用开发需要掌握机器学习算法和深度学习框架,这对提高编码能力和分析能力大有裨益。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4. 超过200本大模型相关PDF书籍
5. LLM面试题汇总
6. AI产品经理资料大全
5. 免费领取方式(点击下方的小卡片就能拿到哦!)
AI大模型学习全套资料包:包含学习路线、面试真题以及PDF笔记等,助你从入门到精通,实战能力满分!