
如何实现高效的上下文管理?聊聊Cursor的背后技术
在实际开发中,像Cursor这种基于大模型(LLM)的智能IDE,想要高效管理上下文,可不是简单的事。它需要一整套工程系统来平衡相关性、性能、Token限制和开发体验。接下来,我们就来聊聊这些技术原理和工程手段,看看它们是如何贴近真实开发场景的。
对了,这个话题在前端面试中也可能会被提到哦。
1. 本地代码索引 + 向量嵌入(Vector Embedding)
Cursor在本地会为整个项目建立一个语义索引,具体是怎么做的呢?
- 它会用一种类似于
tree-sitter的解析器来构建抽象语法树(AST),从中提取出函数、类、变量等符号; - 然后,利用嵌入模型(如text-embedding-ada-002或开源的CodeBERT)把文件内容或代码片段转换成向量;
- 最后,这些向量会被存储到本地的向量数据库中,比如说SQLite配合FAISS、LanceDB或Chroma。
这样一来,当你在对话中提到“修改用户登录逻辑”时,Cursor就能自动调出 authService.ts、loginForm.jsx 等相关文件,即使你并没有打开它们。
2. 多级上下文选择策略(Context Selection Heuristics)
考虑到LLM的Token限制(比如说128K),Cursor不能把整个项目都放进去,所以它会动态地组合多种来源的信息:
- 显式上下文:就是你当前打开的编辑器Tab,优先级最高;
- 引用关系:通过静态分析找出import/require依赖链;
- 语义相似性:利用向量检索来找到与用户查询最相关的代码片段;
- 最近修改文件:可以通过Git历史或文件访问时间来加权。
这些策略通常会封装在一个 ContextProvider 模块里,结合prompt长度进行动态裁剪,以确保总Token数小于模型上限(例如留出4K给生成内容)。
3. 增量式上下文更新(Incremental Context Refresh)
为了避免每次对话都需要重新计算全部内容,Cursor会:
- 监听文件系统的变化(通过VS Code Extension API的
workspace.onDidChangeTextDocument); - 对变化的文件进行增量嵌入更新;
- 缓存已计算的上下文摘要,比如函数签名和注释的总结。
这样能够确保你在编辑过程中,AI始终根据最新的代码来做出回应。
4. 结构化上下文压缩(Context Compression)
当相关代码量太大时,直接拼接起来会超出Token限制。这时,Cursor会采取:
- 摘要压缩:利用LLM自动生成长文件的摘要(比如:“该文件定义了User类,包含id、name和login方法”);
- 符号提取:只保留函数名、类型定义和注释,去掉具体实现;
- 分块检索:将大文件按函数或类切分,召回最相关的部分。
5. 与编辑器深度集成(VS Code Extension架构)
其实,Cursor本质上是一个VS Code插件,它通过以下方式来获取上下文:
vscode.window.activeTextEditor用于获取当前文件和光标位置;vscode.workspace.getWorkspaceFolder用于获取项目根路径;- 借助Language Server Protocol (LSP)获取类型信息(如果项目配置了TypeScript LSP);
- 读取
.gitignore/.cursorignore来排除无关文件(比如node_modules)。
这种深度集成使得上下文自然具备“开发者视角”——AI能清楚地知道你在看哪段代码、光标停在哪、以及你最近修改了哪些文件。
海云前端丨前端开发丨简历面试辅导丨求职陪跑
来源:知乎
原文标题:你了解过类似 Cursor 这种 IDE 中的上下文管理,是通过什么工程手段或原理实现的吗?
声明:
文章来自网络收集后经过ai改写发布,如不小心侵犯了您的权益,请联系本站删除,给您带来困扰,深表歉意!




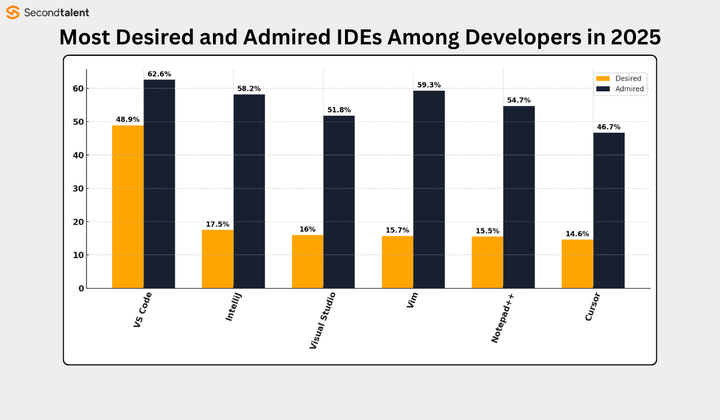
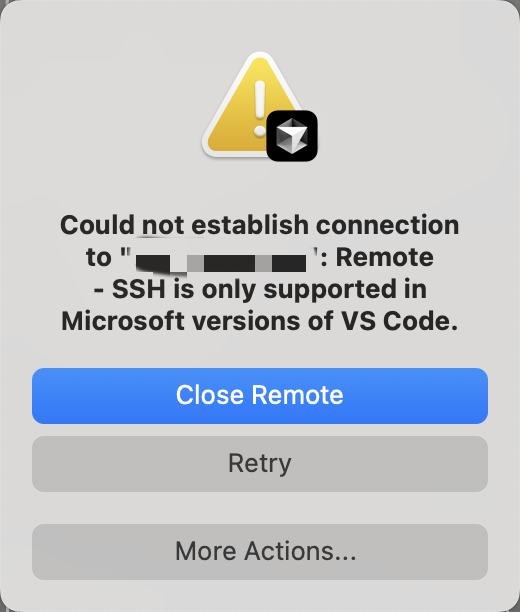

增量式上下文更新的设计思路不错,避免了重复计算,提升了效率,值得其他开发工具学习。
结构化上下文压缩的原理很有启发性,特别适合处理复杂代码。
对Cursor的上下文管理机制真的很感兴趣,感觉它理解代码的能力很强。
Cursor自动调出相关文件的功能,真是太方便了,提升了开发效率。
结构化上下文压缩的思路很新颖,能够有效管理Token限制,是否有可能被其他IDE借鉴呢?
Cursor的上下文管理机制让我想起了几年前的某些工具,期待它能带来更大的突破和创新。
建议在介绍Cursor上下文管理时,能多举一些实际应用场景,这样更容易理解。
在上下文管理方面,Cursor的技术细节值得研究,是否有可能在未来发布更多开发者文档?
增量式上下文更新的设计太聪明了,能及时跟进代码变化,不用每次都重算,真是个不错的功能。
看到多级上下文选择策略,真想知道在不同项目中效果如何,是否会有差异呢?
上下文管理的细节设计非常细致,这种小细节是否也会影响到团队的开发习惯?
能否分享一些在日常开发中使用Cursor的心得?不同团队的体验可能差异很大。
建议可以增加对用户自定义上下文的支持,可能会提升开发者的使用体验。
上下文管理的复杂性让我有点担心,团队如何快速上手这种新机制?
建议在使用Cursor时,定期检查上下文更新的频率,以保证信息的时效性和准确性。
多级上下文选择策略听起来很复杂,实际使用中会不会影响开发效率?
上下文压缩听起来很厉害,实际操作中会不会影响到代码的完整性呢?
Cursor的上下文管理听上去很高大上,实际使用中会不会觉得复杂?
如果Cursor能支持更多编程语言的特性,那在多语言项目中会不会更有效呢?
我觉得Cursor的语义索引很有意思,能快速找到相关代码。