前言
在这个AI辅助编程的时代,Cursor作为一款顶尖的代码编辑器,其Apply功能吸引了不少人的目光。你知道吗?Cursor的Apply功能可以以每秒1000 tokens的速度进行文件编辑,这可比起Cline、VS Code等工具快了不止一倍。那么,这么惊人的性能到底是怎么实现的呢?
编辑
什么是Apply功能?
Apply功能是Cursor编辑器的一个重要特性,它能根据用户的对话和指令,迅速对整个文件进行编辑和重写。和传统的逐行编辑方式相比,Apply功能可以一次性处理整个文件,实现大规模的代码改动。
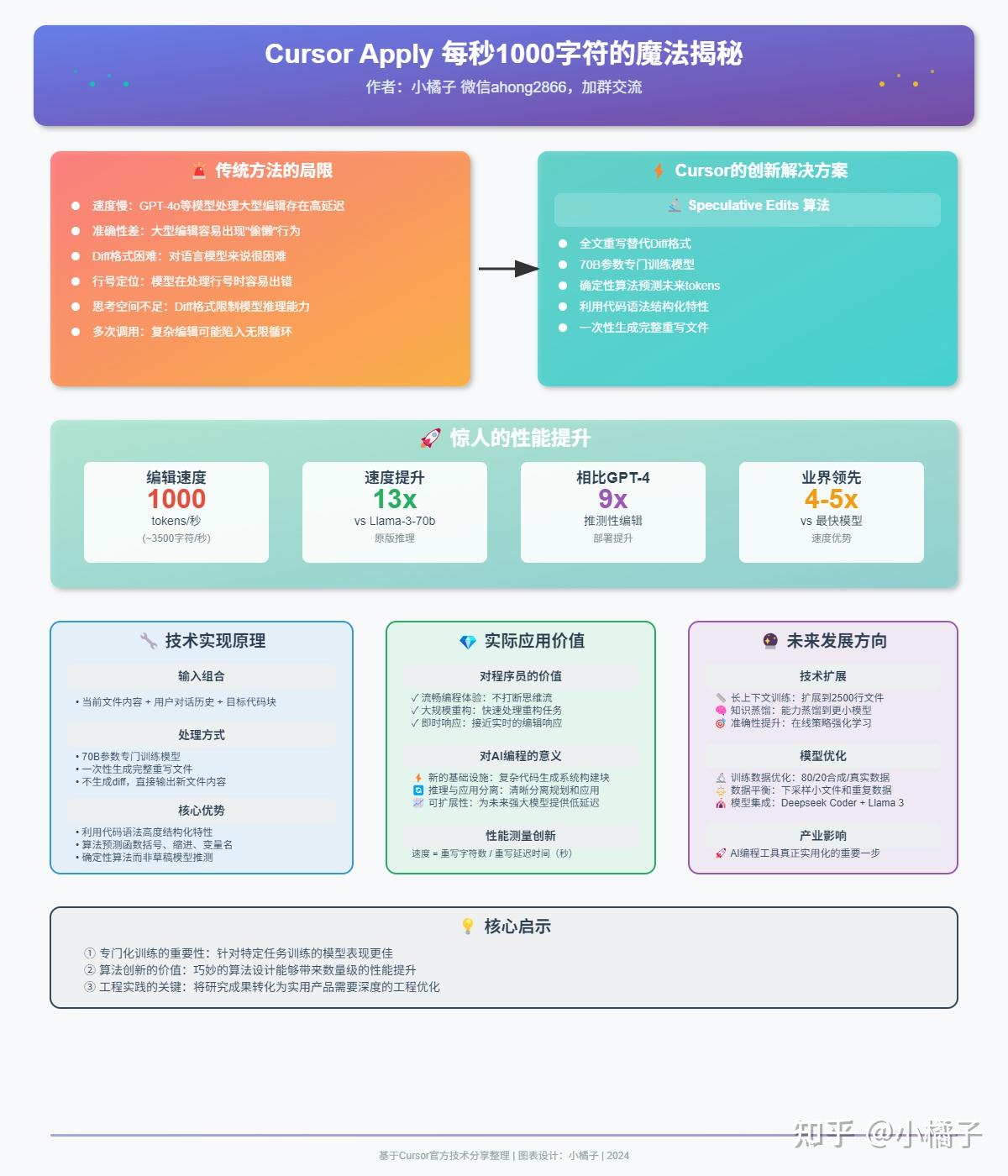
传统方法的局限性
在深入了解Cursor的创新之前,咱们先看看传统AI编辑面临的挑战:
1. 性能问题
- 速度慢:像GPT-4o这样的先进模型在进行大规模编辑时,延迟感很明显。
- 准确性差:在进行重大修改时,模型往往出现“偷懒”,导致结果不够准确。
- 多次调用:复杂的编辑任务可能需要多次调用模型,有时甚至可能陷入无限循环。
2. 编辑方式问题
- Diff格式困难:传统的差异化编辑方式对语言模型来说是个挑战。
- 行号定位:模型在处理行号时容易出错,尤其是在tokenizer把数字序列当作一个token时。
- 思考空间不足:Diff格式限制了模型的推理能力,造成思考空间受限。
Cursor的创新解决方案
核心突破:Speculative Edits 算法
Cursor团队研发了一种叫“Speculative Edits”(推测性编辑)的算法,这可是实现快速编辑的关键所在。
具体实现机制:
- 输入数据:
- 当前的文件内容
- 用户的对话历史
- 目标代码块
- 处理方式:
- 使用70B参数的专门训练模型
- 一次性生成完整的重写文件
- 不生成diff,直接输出全新的文件内容
- 技术原理:
- 充分利用代码语法的高结构化特性
- 算法能够预测接下来可能出现的函数括号、缩进、变量名称等
- 采用确定性算法进行推测,而不是依赖草稿模型。
为什么选择全文重写而非Diff?
Cursor团队发现,当语言模型在处理diff格式时会遇到几个关键问题:
- 思考空间限制:Diff格式让模型只能用更少的tokens进行思考,限制了推理能力。
- 分布外数据:模型在预训练和微调中接触到的完整代码文件数量远多于diff格式。
- 行号处理困难:模型处理行号时容易出错,特别是在tokenizer将数字序列视为单个token时。
模型训练策略
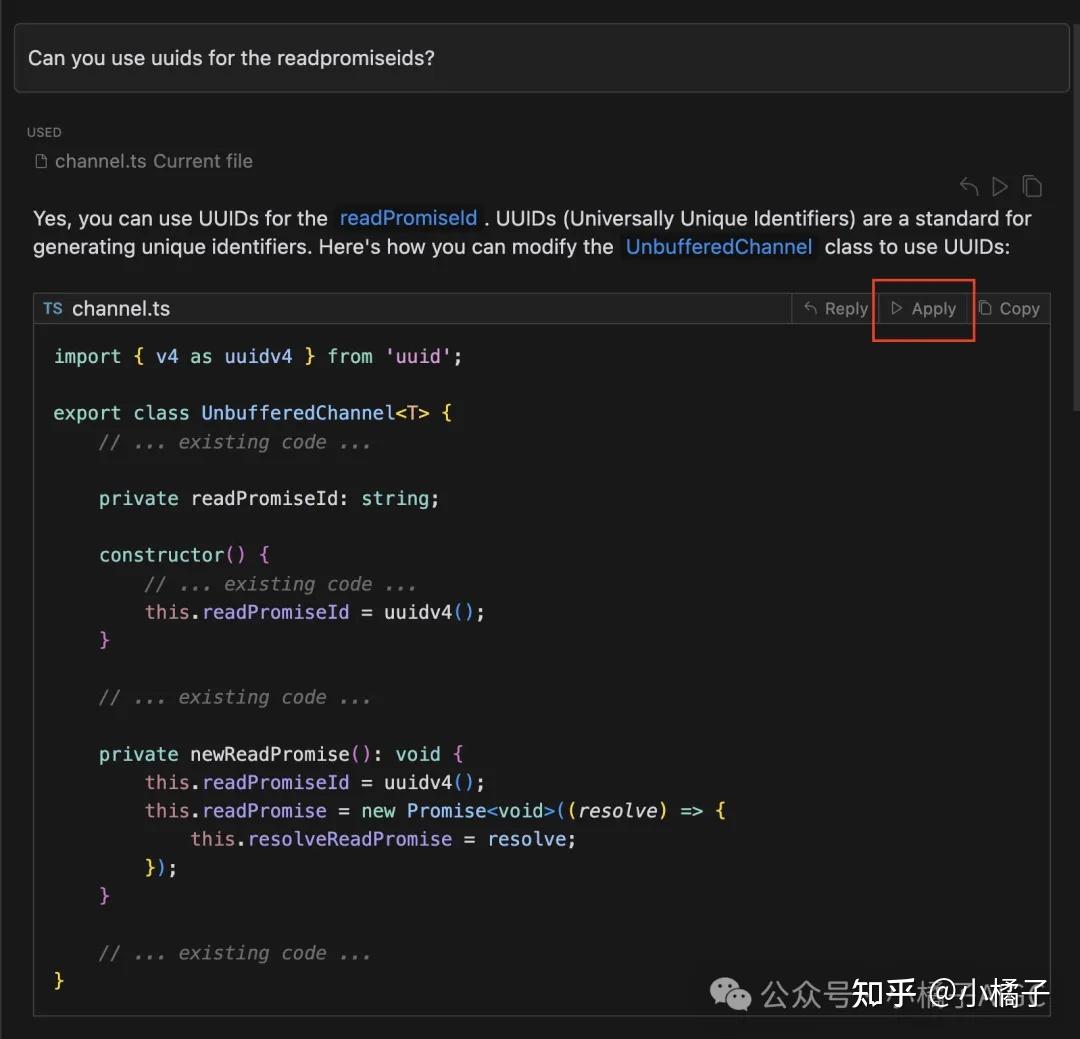
1. 数据合成
- 从少量的“fast-apply”提示开始
- 大量使用cmd-k提示数据进行训练
- 通过GPT-4生成聊天响应,然后让语言模型“应用”这些更改
- 以80/20的比例将合成数据与真实数据混合
2. 模型优化
- 训练Deepseek Coder Instruct和Llama 3模型系列
- 对小文件(
- 减少每个文件名的训练示例数量
- 下采样无操作的数据点
3. 性能表现
- 最佳模型(llama-3-70b-ft)的表现几乎可以匹配claude-3-opus-diff
- 在性能上超越gpt-4-turbo和gpt-4o
惊人的速度提升
性能数据
得益于Speculative Edits算法,Cursor的编辑速度达到了:
- ~1000 tokens/s(约3500字符/秒)的速度
- 相比Llama-3-70b原版推理,速度提升了13倍
- 相比之前的GPT-4推测性编辑的部署,速度提升了9倍
- 相比下一个最快的模型,速度提升了4-5倍
速度测量方法
Cursor采用了一种创新的速度测量公式:
速度 = 重写字符数 / 重写延迟时间(秒)这种测量方法的优点在于:
- 在不同tokenizer之间标准化速度
- 提供一个清晰的关注数字
- 给出生成速度的强下界
技术实现细节
与Fireworks合作
Cursor与Fireworks合作部署其fast-apply模型,Fireworks为此提供了:
- 卓越的推理引擎
- 为定制推测逻辑构建的API支持
- 强大的推测性编辑支持
算法特点
- 确定性推测:通过确定性算法来预测未来的tokens,而非依赖草稿模型
- 代码先验:利用代码编辑中对任意时间点草稿tokens的强先验知识
- 等效重写:相当于完整文件重写,但速度快达9倍
未来发展方向
1. 长上下文训练
- 正在研究将文件重写能力扩展到2500行
- 简单的RoPE位置ID线性缩放效果不佳
- 当前社区的Llama 3 70b长上下文微调也面临问题
2. 知识蒸馏
- 计划将“fast apply”能力蒸馏到更小的模型中,特别是llama-3-8b模型
- 小模型的低延迟在处理大文件时尤其重要
3. 准确性提升
- 使用新部署模型的数据进行在线策略强化学习,以期获得额外的性能提升
实际应用意义
对程序员的价值
- 流畅编程体验:高速编辑不会干扰程序员的思维流畅性
- 大规模重构:能够迅速处理大规模代码重构任务
- 即时响应:接近实时的编辑反馈
对AI编程的意义
- 新的基础设施:fast-apply将成为更复杂代码生成系统的核心组件
- 推理与应用分离:清晰地将规划阶段与应用阶段分开
- 可扩展性:为未来更强大的推理/规划模型提供低延迟的应用能力
技术挑战与解决
挑战1:模型偷懒
问题:大型语言模型在处理大型编辑时容易“偷懒”,导致输出不完整或不准确。
解决方案:通过专门设计的训练数据和评估方法,训练模型完成整个文件的重写。
挑战2:语法错误
问题:编辑过程中容易引发语法错误,比如在SWE-Agent示例中的7次失败尝试。
解决方案:采用结构化的推测性编辑,充分利用代码的语法结构特点。
挑战3:无关更改
问题:像GPT-4这样的模型倾向于“修复/清理”无关代码,例如删除注释或不必要的换行。
解决方案:通过精心设计的训练数据,教会模型只关注用户请求的更改。
评估方法
自动评估
- 构建了约450个400行以下文件的全文编辑评估集
- 使用Claude-3 Opus作为评估器
- Opus评估与人工评估的一致性高得惊人
性能指标
- 准确性:编辑的正确性和完整性
- 速度:处理字符的速度
- 帕累托前沿:在准确性与延迟之间推进边界
结语
通过创新的Speculative Edits算法,Cursor的Apply功能成功地解决了AI辅助编程中的一些关键瓶颈。每秒1000 tokens的编辑速度不仅仅是一个技术指标,更是AI编程工具向实用化迈进的重要一步。
这项技术的成功还证明了:
- 专门化训练的重要性:针对特定任务训练的模型表现更优
- 算法创新的价值:巧妙的算法设计能带来巨大的性能提升
- 工程实践的关键:把研究成果转化为实用产品需要深入的工程优化
随着AI模型推理和规划能力的不断增强,像Cursor这样的低延迟应用技术将越来越重要。未来,我们可以期待更多创新的出现,让AI编程助手真正成为程序员得力的伙伴。










这种速度真的很惊人,代码编辑能快到这种程度,太酷了!
听说传统编辑器在处理大型代码时容易出错,Cursor解决了这个问题,真是个好消息!
这种推测性编辑的算法听起来很高科技,实际操作中会不会出现意外呢?
听说Cursor在重写时不生成diff,这个设计简直太妙了,能减少很多潜在的错误!
这种算法如果能普遍应用到其他工具上,编程效率会不会更上一层楼?
这种全面重写的方式让我想起了自动化测试,能否结合使用,提升整体开发效率?
推测性编辑听上去很高深,操作起来会不会对新手程序员不太友好呢?
这个Apply功能真的太强了,感觉代码编辑瞬间变得轻松了!
看到Cursor不生成diff的设计,真是觉得这个选择很聪明,减少了很多麻烦。