当开发者们兴奋地体验这个新版本的各种更新时,其实有一个更重要的意义悄然浮现:
尽管Cursor在AI编程领域已经走在了前面,但它仍然需要不断提升自己的模型。这次更新的核心,就是它推出了自家的模型Composer,以及Cursor在产品中为其设计的角色。在AI编程的赛道上,Cursor终于迈出了这一关键一步。
全新的开发模式:智能体化与多任务并行
首先我们来看看它在智能体能力上的新变化。
根据官方更新日志,Cursor正在从“以文件为中心的编辑器”向“以智能体为核心的开发平台”转型。
“我们重构了一切。”在2.0之前,打开Cursor的感觉和其他现代编辑器没什么差别:窗口、文件、光标,还有一个随时待命的AI命令行。但现在,一切的焦点不再是“文件”,而是“智能体”(Agent)。
开发者们不再需要告诉AI“打开哪个文件”或“改哪一行代码”。现在,你只需要告诉系统你的目标,它就会派出一个或多个智能体来规划、执行和验证任务。
一个人、一台电脑,八个AI开发者。
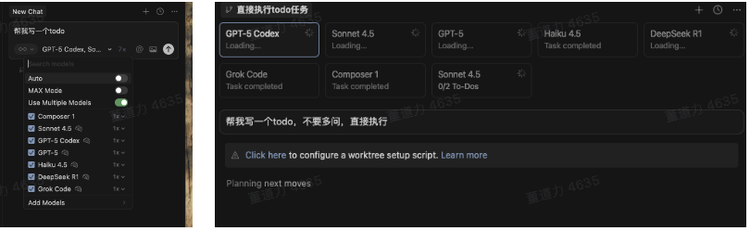
我们简单试了试,打开“使用多个模型”,选择所需的模型,输入提示。然后你就能看到最先进的AI编程模型在为你服务。
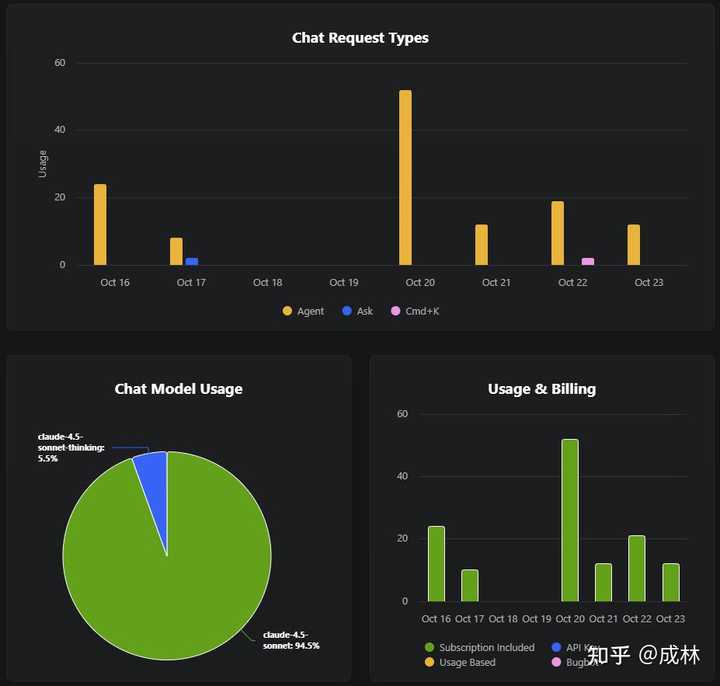
只需一句话,就能让AI消耗大量的tokens。
那模型之间会不会互相覆盖代码呢?Cursor早就考虑到了这一点,官方文档明确表示,它的底层依赖于git worktree机制,每个智能体都在独立的工作副本中运行、修改和测试代码。每个智能体就像是在不同分支上工作的工程师,互不干扰,最后再合并成果。
每个智能体都有自己的代码副本和上下文环境,从而避免了“智能体互相覆盖”或“分支冲突”的问题。
Cursor不仅是一个编辑器,更是一家模型公司
所有这些变化的根本原因,是Cursor首次推出了自家模型Composer。在更新日志中,团队自信地表示:“在相似智能水平下,Composer的推理速度快了4倍。”官方宣传及媒体评测也强调了“大多数交互在30秒内完成”。这意味着Cursor不再依赖第三方的智能,而是将“速度/延迟/上下文管理”等关键因素掌握在自己手中。
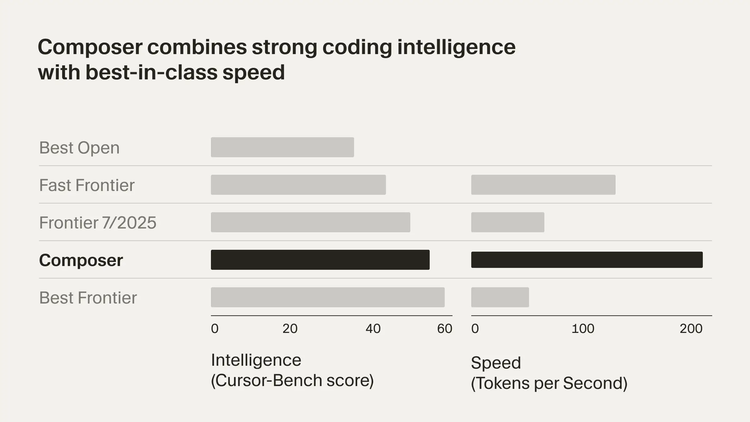
过去,Cursor依赖OpenAI和Anthropic等外部模型,这带来了成本高、响应慢、上下文受限的问题。而Composer的路线则是一次“垂直化”的模型工程:围绕代码生成、语义索引与上下文检索进行定制优化,首先“理解”整个代码库及依赖/命名约定,然后再动手生成代码。结果是从“会写代码的工具”升级为“懂项目的工程师”。
Cursor 2.0将“并行智能体 + 长期规划”推到了前台,效率大幅提升,同时也直面了一个行业级的悖论:订阅收入固定,而推理成本却是按量计费。即使单价在下降,总量却因更深入的思考、更长的上下文和更频繁的工具调用而飙升。
2.0的多智能体让一次任务的Token消耗因智能体数量而成倍增加,计划与思考的时间也变得更长。结果就是“单价下降与用量激增”的拉扯:如果不进行自研和系统级优化,很容易导致收入高但盈利少,变成模型公司的打工者。
从这个角度看,Cursor将Composer打造成“第一方模型”,就是在补这门“模型的课”:既要提高速度,又要降低推理账单,为2.0的多智能体模式提供一个可控的基础。
当然,Composer的推出并不是临时决定的,而是Cursor为2.0铺路的自然结果。首先在8月重写了MoE的MXFP8内核,打牢训练和推理的低延迟基础;然后在9月到10月初用在线强化学习提升补全模型,推出计划模式,实现“先读库—出计划—再执行”的流程;在这条工程链上,10月29日正式发布了Composer。
我试着用Composer写了一个待办事项网页,速度确实很快,但界面等还是很熟悉。可能要在更复杂的项目中,才能真正体验到Composer与其他模型的区别。
内嵌浏览器:AI的自我认知
另一个看似简单却意义深远的改动,就是内嵌浏览器的推出。为什么说“终于”呢?因为这个功能在一些国产AI IDE中早已实现。
在Cursor 2.0之前,AI写完代码后,开发者需要运行项目、查看结果,再反馈问题。现在,AI可以直接在编辑器内部打开浏览器,运行自己写的代码,查看结果,甚至能够主动修复样式或逻辑错误。这种“AI自我感知”的设计,正在模糊人机协作的界限。
在官方演示中,一个简单的前端应用从生成到自测,AI能自动完成多次循环优化,而用户几乎无需输入任何指令。这意味着AI不再是等待被指挥的“助手”,而是一位能够主动检查自己作品的参与者。
[0e795515f844148c8902c79ac41241b6d53b3e86.mp4]
重要但不显眼的更新
与此同时,Cursor 2.0在一些看似“不炫目”但极其重要的方面,也实现了向成熟工程系统的跃迁。
首先是安全与执行边界:随着多智能体能够独立执行命令和运行脚本,AI的角色不仅限于“写代码”,还在“做决策”。因此,2.0默认启用了沙盒终端,让每一条由AI触发的命令只能在隔离环境中运行,无法访问系统的关键路径或外部资源,避免“自动化带来不可控的风险”。
其次是在团队层面。2.0开放了团队规则与共享指令的功能,企业可以为所有成员定义统一的命名规范、注释格式、错误处理约束与构建流程,AI在整个组织中会自然遵守这些“开发宪法”。如果说在1.0时代,你在教AI写你的代码风格,那么在2.0时代,团队直接教AI写整个公司的工程文化。
在体验方面,Cursor 2.0增加了语音控制功能,真的实现了说话编程?

开发者们的看法
在国内外的社区中,Cursor 2.0的讨论几乎呈现出明显的分界:一边是兴奋的尝鲜者,另一边是保持谨慎的专业开发者。支持者认为,Cursor 2.0让“AI参与编码”正式跨越了从辅助到代理的门槛,而怀疑者则提醒,人们或许低估了这种范式转变背后的成本与风险。
在Reddit上,有人一早打开编辑器,就看到了“使用多个模型、Git工作树和智能体评审”等新功能,感叹这个工具发布的节奏“快得有点吓人”。甚至有人直言,Cursor的交互体验“领先于许多竞争产品”,原因在于它不是把AI塞进旧的IDE,而是从一开始就选择站在AI原生的基础上重构一切。
然而,这股热潮下并非只有赞誉。有人在测试多模型协作与智能体评审后表示“请求量消耗得离谱”,瞬间将算力费用的痛点拉回现实。还有人抱怨新定价策略对个人开发者“并不友好”。更保守的声音则警告,尽管Cursor的迭代速度很快,但功能推出的节奏有时也显得不那么稳定。
如果把当前的AI编程赛道摊开来看,模型本身的“上限”短期内很难通过增加参数或加快推理速度突破,而AI IDE的功能也在迅速趋同:智能补全、跨文件改写、内嵌浏览器、自测循环、多模型切换,几乎都在路上。
真正的分水岭,已经从“谁的模型更强”转向“谁能把AI编程这门生意做好”:并行处理、跨文件修改的准确率,以及将每个功能的Token/时间成本控制在可控范围内。
从这个维度来看,Cursor 2.0将多智能体+工作树隔离设为默认模式,用Composer将“低延迟+库级语义理解”融入模型目标,并把推理成本和调度权收回到自己的系统中——这正是在补那门“模型的课”:让速度、准确率与账本同时闭环。
那么,你对Cursor这次更新觉得满意吗?








希望Cursor能继续优化模型,特别是在上下文管理上,避免在复杂项目中出现混乱。
从以文件为中心到以智能体为核心的转变确实是个大胆的尝试,希望能给开发者带来实质性改变。
建议考虑增加对不同编程语言的支持,提升多样性和适用范围。
听说智能体能独立工作,真的能完全避免代码冲突吗?有点怀疑。
用量激增的问题真让人担心,订阅收入固定的情况下,如何平衡成本呢?
希望能进一步优化多语言支持,不然对于某些项目来说可能会局限。