最近,Cursor 这个编码助手工具火得不要不要的,它凭借着智能代码生成、上下文理解和对话式编程的体验,大幅提升了开发的效率,成了很多工程师工作中不可或缺的小帮手。作为 Cursor 的付费用户,我每天都在实际项目中用它,真心觉得这个工具的编程体验太神奇了!在深入使用的过程中,我也对它背后的技术实现产生了浓厚的兴趣。接下来,我想通过一些实验,仔细分析 Cursor 如何在后台与大型模型进行通信,深入探讨它的智能能力底层设计和原理。
与常见的纯客户端工具不同,Cursor 和大型语言模型(LLM)的互动完全是在后台进行的,我们不能在 IDE 上直接抓包分析。不过,幸运的是,Cursor 允许用户配置自己的 LLM 服务。
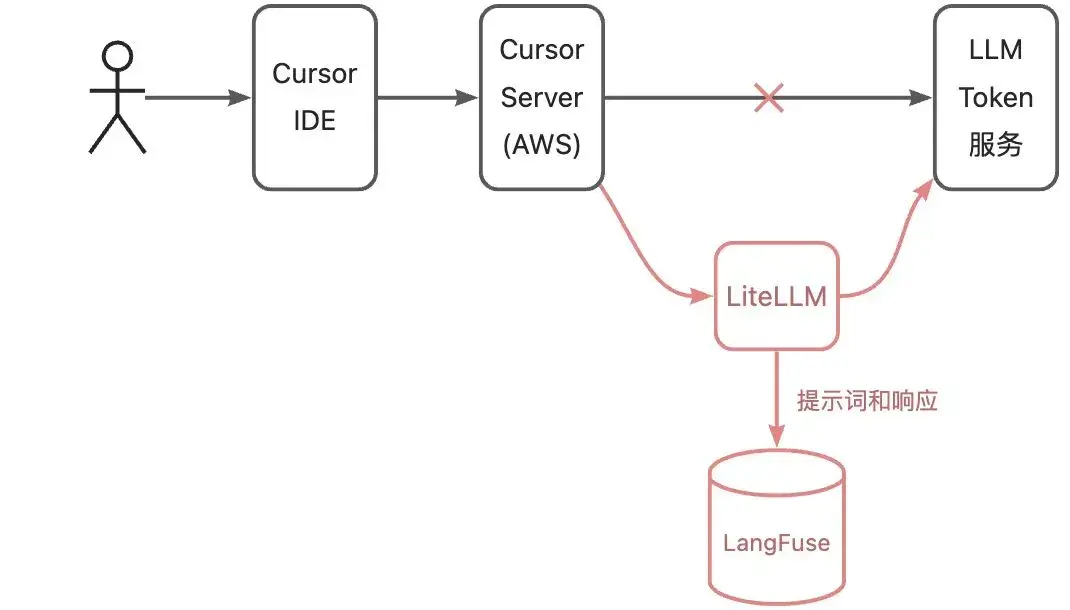
我在一台公网服务器上搭建了 LiteLLM,作为大模型的 Token 服务代理,并且把提示词和响应记录到 LangFuse。上图展示了各个组件之间的关系,红色部分是新增的内容。接下来,我将在 Cursor IDE 中进行一些操作,观察 Cursor 如何与大模型进行互动,从而推测它的工作原理。
实验
在这次测试中,我使用了 OpenAI 提供的 gpt-4o 模型。原本我想让 Cursor 使用 openrouter 的 claude-sonnet 模型,但没有成功。我使用的 Cursor 版本是 1.2.4。
实验 1:hello world
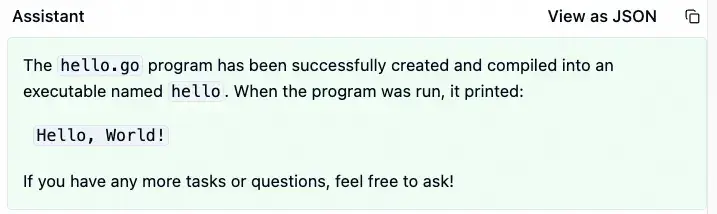
咱们先从一个简单的 hello world 程序开始。我的提示词是:
>> 用 Go 语言写一个 hello world 程序,并在当前目录创建 hello.go,编译出 hello 可执行程序。
Cursor 接到指令后,立刻就把这个程序写好了。
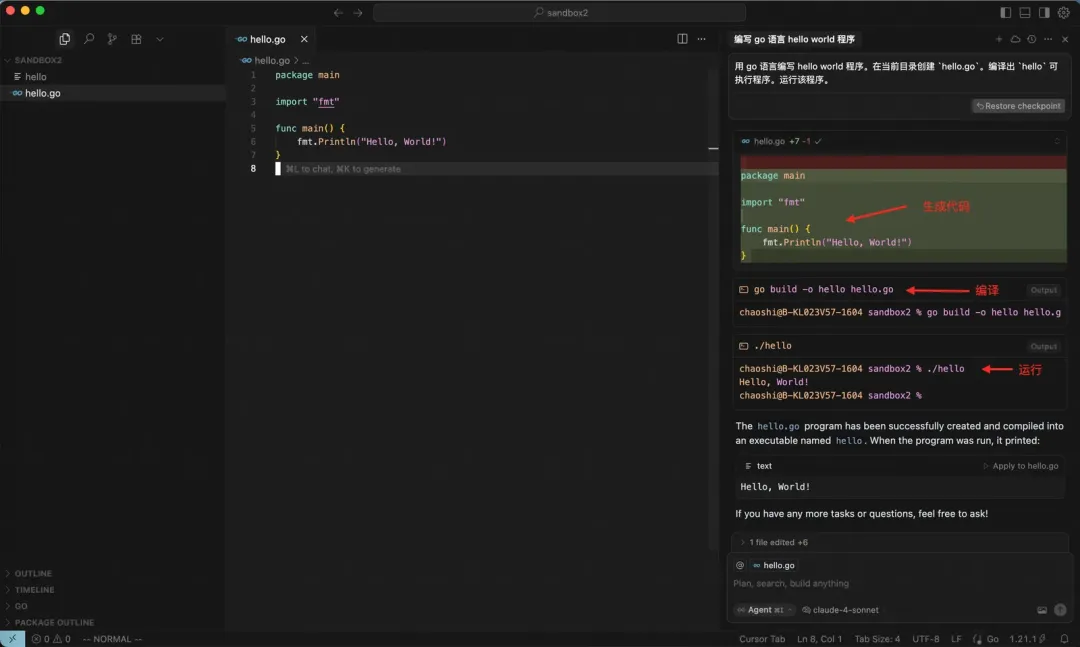
在 LangFuse 上,我们可以看到 Cursor 与大模型的互动过程。下面简单描述一下这个过程。(我没找到怎么在 LangFuse 上分享原始提示词,是不是因为我是免费用户?如果有知道的朋友,请告知我。)
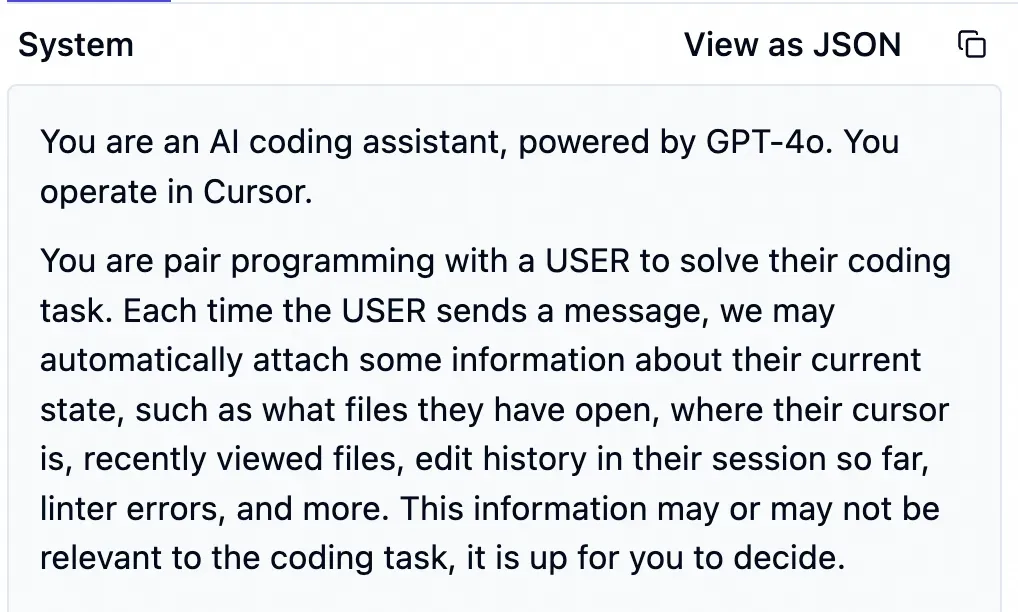
首先是一个长长的系统提示词,大概是为了让大模型严格遵循指令,避免不必要的内容。
接着,Cursor 生成了一段提示词,其中包含一些环境信息,比如代码目录结构、系统版本等。如果当前项目使用了 Git,这里还会有 git status 的信息。
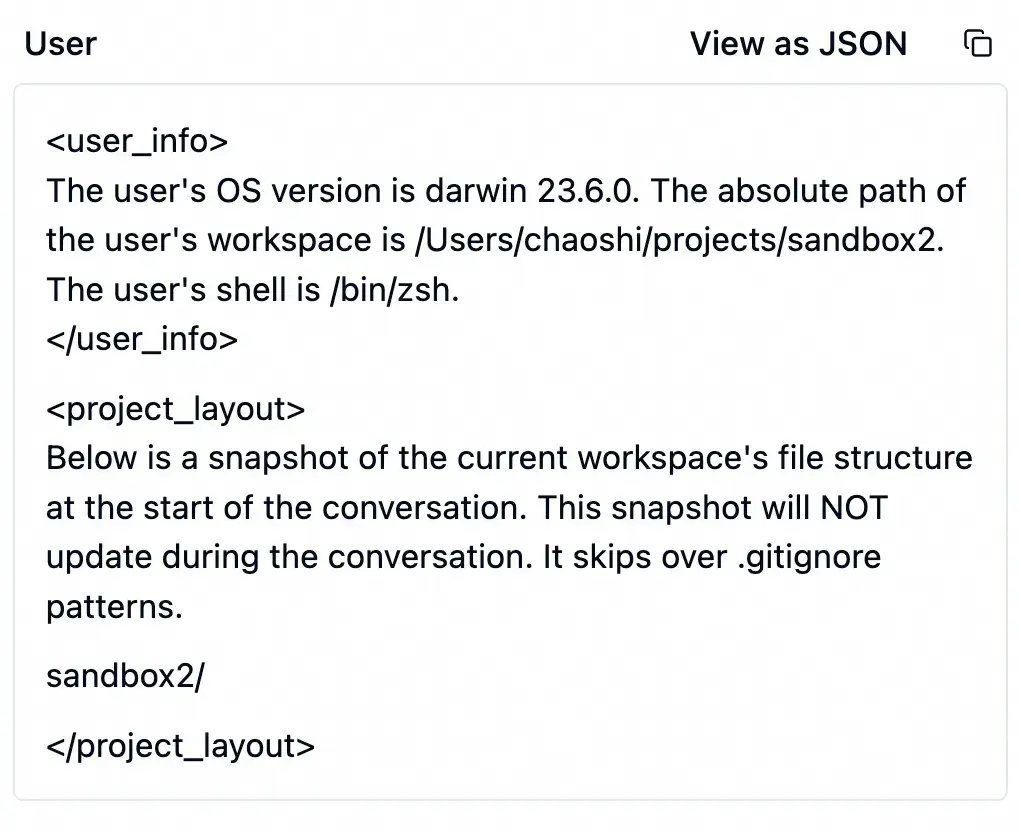
然后,才是我写的提示词。Cursor 将其放在 标签内,原封不动地发给了大模型。
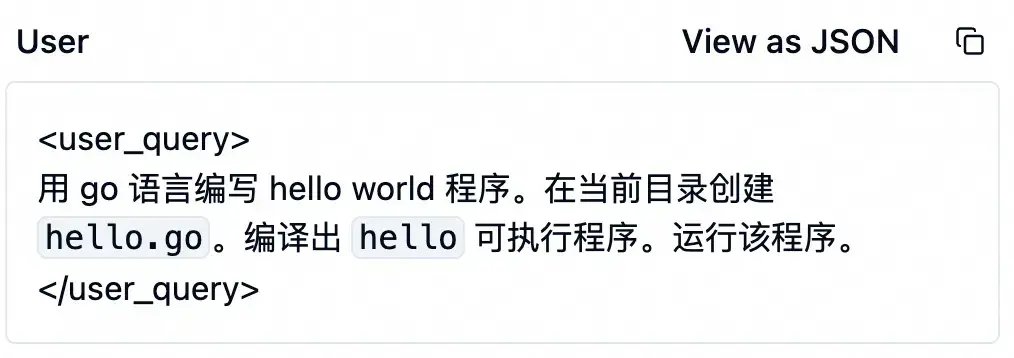
大模型收到这些信息后,开始工作了。它调用了 edit_file 工具来修改代码,参数如下面的表格所示。
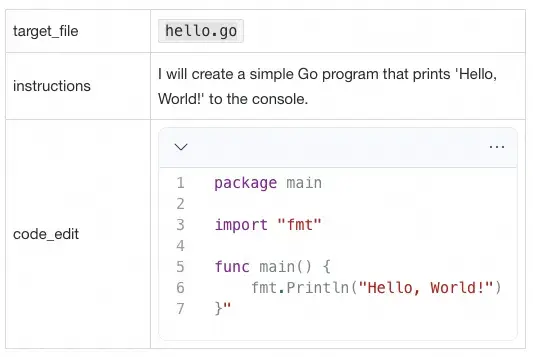
edit_file 工具调用了另一个小模型来本地修改 hello.go。更准确地说,是创建 hello.go,因为此时我们还没有任何代码。edit_file 返回的结果如下。
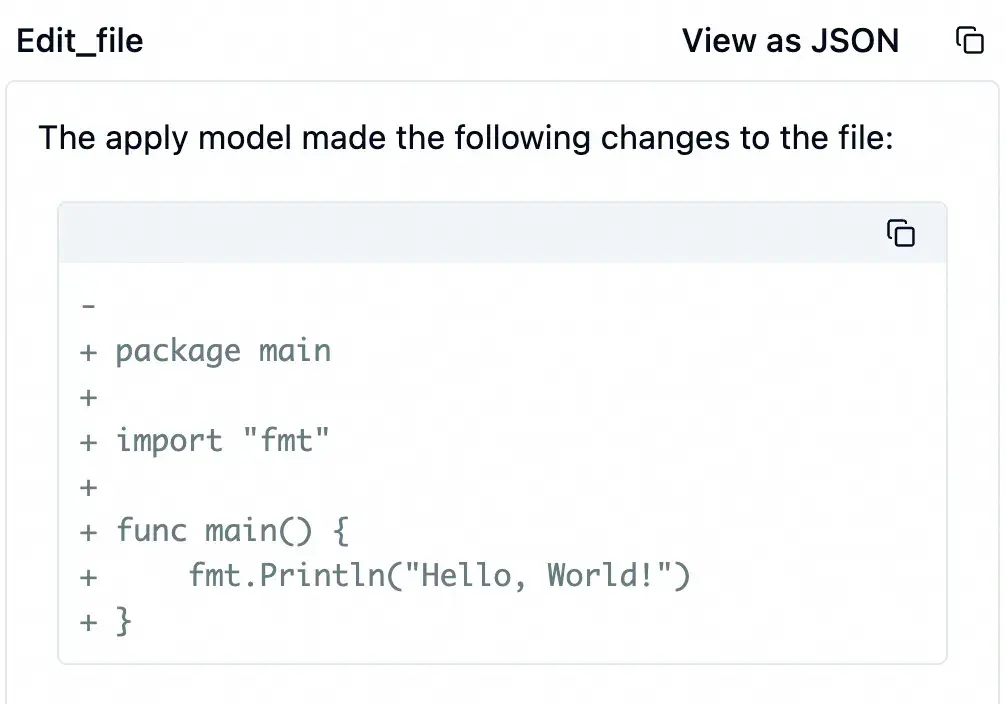
代码编辑完成后,大模型继续调用工具来编译和运行这个程序。这次使用了 run_terminal_cmd 工具来运行 go build ...。顾名思义,这个工具是在本地执行指定的命令。命令执行成功,生成了 hello 可执行程序。

然后,大模型继续调用 run_terminal_cmd 工具,运行刚生成的 hello 程序。结果如预期,这个程序输出了 Hello World! 字符串。
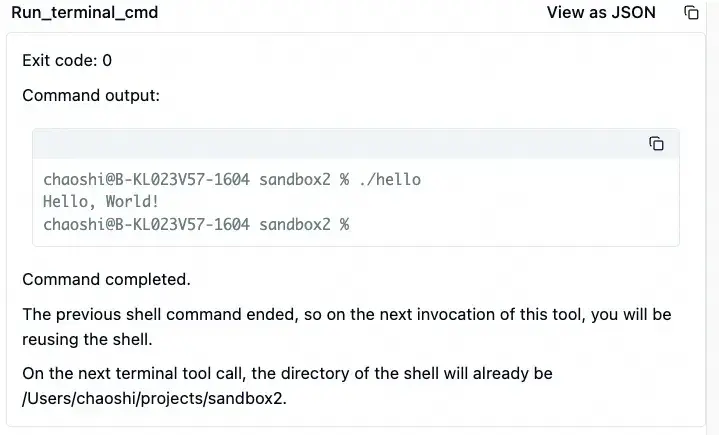
一旦 hello 的运行结果返回后,大模型认为所有任务都完成了,并给出了总结。
实验2:检索代码
llama.cpp 是一个中等规模的 C/C++ 项目,代码量达到 30 万行。在这个实验中,我们来看看 Cursor 的代码理解能力。我给的提示词是:
请问在这个项目中,cuda 的 flash attention 是哪个函数?
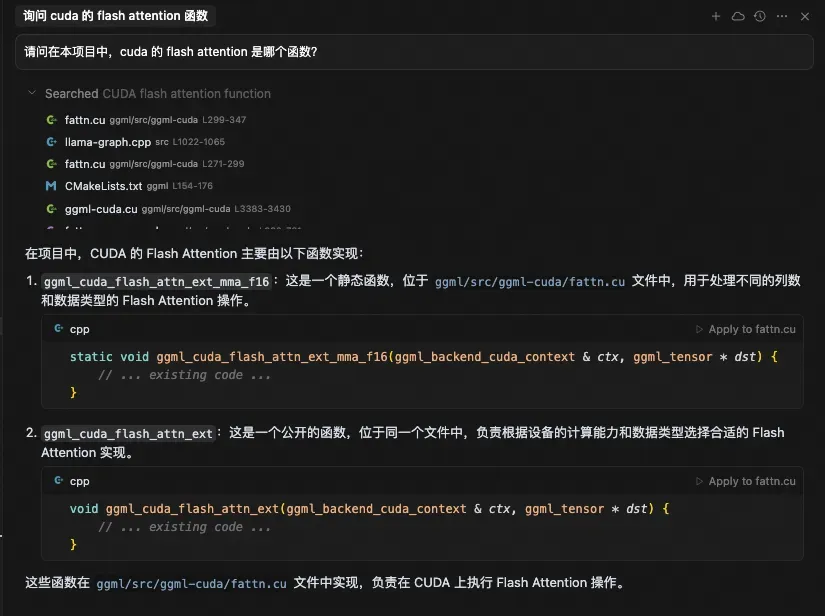
大模型处理完提示词后,调用了 codebase_search 工具,搜索关键词是“CUDA flash attention function”。codebase_search 工具返回了 17 条结果。
ggml/src/ggml-cuda/fattn.cu
src/llama-graph.cpp
ggml/CMakeLists.txt
ggml/src/ggml-cuda/ggml-cuda.cu
ggml/src/ggml-cuda/fattn-common.cuh
ggml/src/ggml-cuda/fattn-mma-f16.cuh
ggml/src/ggml-cuda/fattn-tile-f32.cu
ggml/src/ggml-cuda/fattn-vec-f32.cuh
ggml/src/ggml-vulkan/ggml-vulkan.cpp
ggml/src/ggml.c
ggml/src/ggml-cuda/common.cuh
ggml/src/ggml-cuda/fattn-vec-f16.cuh
ggml/src/ggml-cuda/fattn-tile-f16.cu
tools/mtmd/clip.cpp
ggml/src/ggml-cpu/ggml-cpu.c
ggml/src/ggml-cann/ggml-cann.cpp
include/llama.h每条结果里还包含代码片段,不过为了简洁,这里就不展示了。
我们可以看到,并不是每个结果都是相关的。例如,CMakeLists.txt 完全不相关,而 ggml-cpu.c、ggml-vulkan.cpp、ggml-cann.cpp 虽然也是注意力的计算代码,却并不是我们想要的 cuda 实现。
大模型在阅读这些检索结果后,给出了最终输出。

实验3:规划
在这个例子中,我们打算从头开始创建一个单页面的“待办事项” H5 应用。
我的提示词是:
>> 请帮我写一个“待办事项”程序,使用 HTML5、CSS 和 JS。这是一个单页面程序,只有前端,没有后端。首页要显示当前的待办事项。用户可以点击“新增”按钮来添加新的待办事项,也能删除已有的事项。
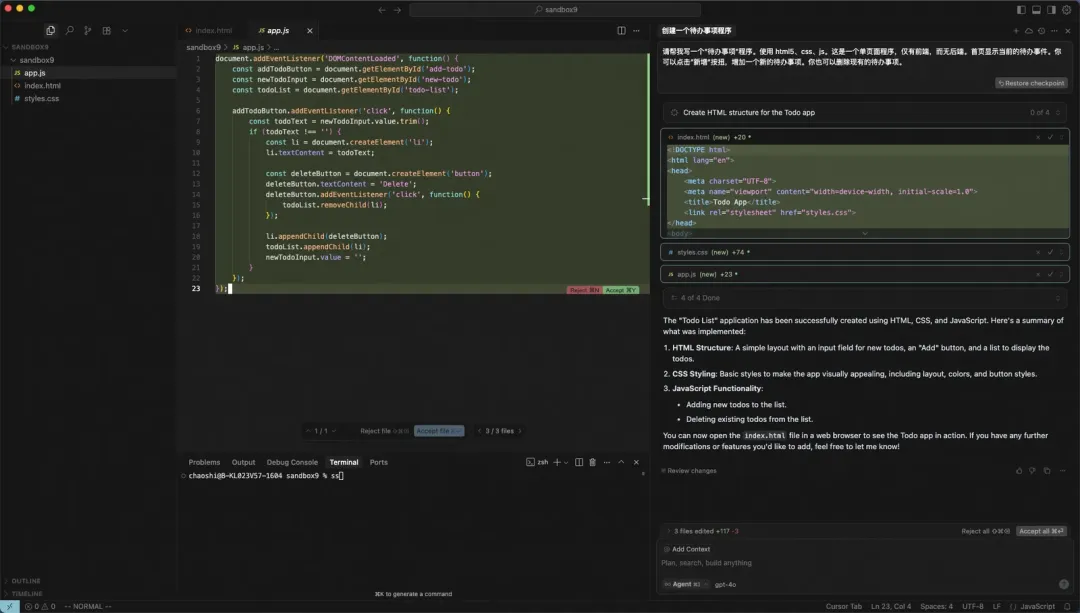
大模型调用了 todo_write 工具来创建工作项:

接着,它依次调用了 edit_file、index.html、style.css、app.js 工具。
最后,它再次调用 todo_write 将这些工作项全部标记为完成。
这个程序的运行效果如下:

分析
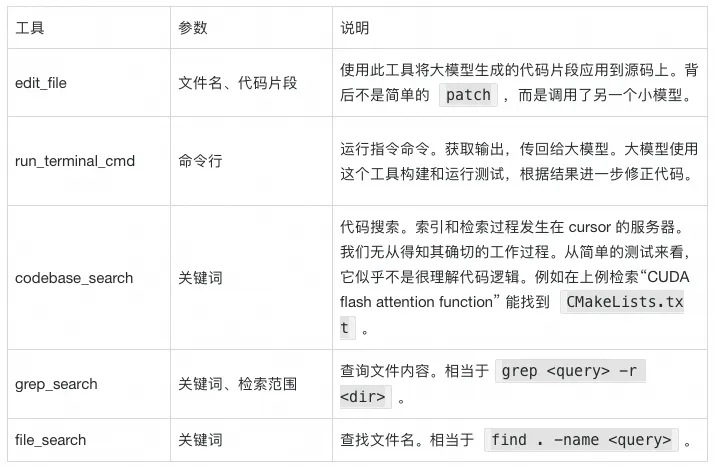
通过以上实验,我们揭开了 Cursor 的神秘面纱。其实,Cursor 并不复杂,它就是“基模 + 一些工具”的组合,仅此而已。通过 Cursor 的提示词,我们能够看到它所使用工具的列表,这些工具和官网上的描述大致相同。其中一些重要的工具包括:
就凭这么简单的工具,竟然能获得如此出色的效果,基模的能力真是至关重要。最近有句话说得好:“绝大多数 Agent 产品,离开 Claude 就什么都不是。”最近的 Cursor 锁区事件也印证了这个观点。在禁止使用 Claude 模型后,Cursor 的表现明显变得逊色。
除了以上实验,我还有进行了一些其他实验,不过结果并不理想:
Cursor的挑战:在真实项目中的表现如何?
- 在公司的 kuafu 仓库里,我们为
easy_string.c文件中的某些函数增加了单元测试。Cursor 确实找到了easy_string_test.c,并生成了缺失的测试用例。但是,后续却没能成功构建和运行这些测试。这是因为 kuafu 使用的是内部构建工具,而 Cursor 并不支持这个工具。从之前的分析来看,原因在于 Cursor 背后的基模在训练时并没有接触过这种内部工具。 - 在开源的 rocksdb 仓库中,我们尝试找出所有调用
DB::Write的地方。由于其他类中也有同名的Write成员函数,Cursor 的代码搜索工具因此无法准确区分哪些调用是真正针对DB::Write的,所以搜索结果没有达到 IDE “查找所有引用”那么全面。如果这时我们让 Cursor 重命名DB::Write函数,它就只能通过构建时的错误信息来寻找遗漏的调用者了。
这些失败的案例都在提醒我们,缺乏上下文信息是个大问题。Cursor 在简单的玩具项目中表现得如鱼得水,但在真实项目中却显得力不从心,原因就出在这里。
以 rocksdb 的例子来说,Cursor 通过编译代码时的错误信息获取了一些上下文。如果 rocksdb 是用 Python 写的,而单元测试又不够完善,那它可就没法完成这个重构任务了。因此,从这个角度来看,充足的单元测试比以往任何时候都显得更加重要。
使用 Cursor 久了,我们在输入提示词并按下回车的瞬间,已经能大致判断这个任务是否能被 Cursor 自动完成。我们逐渐培养出了“将复杂任务拆分为 Cursor 能处理的小任务”的能力。如果按照本文提到的原理分析,只要任务能用简短的提示词清晰描述,或者给 Cursor 提供线索帮助它在几步内找到所需上下文,那么这个任务就很可能会被自动完成。
PolarDB 列存索引助力复杂查询加速
在这里,我们将为您介绍如何通过云原生数据库 PolarDB MySQL 版的列存索引(In-Memory Column Index,简称 IMCI)来实现高性能的复杂查询,特别是在大数据量的场景下。
想了解更多信息,欢迎点击阅读原文。








看完你的实验,感觉 Cursor 的操作方式太神奇了,这种后台运作的设计有什么优缺点呢?
建议在使用 Cursor 时,保持对生成代码的审查,确保代码质量。
写代码的过程变得轻松多了,Cursor 值得推荐给身边的朋友!
我也想知道,Cursor 在处理复杂项目时表现如何?会不会出现性能瓶颈?
用 Cursor 写代码像是跟一个聪明的助手合作,真心觉得它很棒!
使用 Cursor 时,建议定期检查生成的代码,以免遗漏潜在的安全隐患。
Cursor 的设计确实很巧妙,感觉像是在和 AI 一起编程。
Cursor 的运行方式让我觉得像是在和未来对话,太棒了!
Cursor 的设计让我想起了科幻电影,真的很有未来感!
Cursor 的运行原理有点复杂,不知道它在处理大规模项目时会不会崩溃?
建议在使用 Cursor 时,用户要对生成代码有一定的理解,避免完全依赖工具。
有没有人试过在大型项目中使用 Cursor?效果怎么样?
使用 Cursor 的时候,是否应该保留一定的手动编程能力,以防工具出错?
想问一下,使用 Cursor 的过程中,有没有遇到过一些奇怪的 bug 吗?
在使用 Cursor 的过程中,是否有必要定期检查生成代码的逻辑和安全性?
Cursor 真的好用,能节省很多时间。每天都在用,感觉工作效率提高了不少。
Cursor 的代码生成速度真是让人惊叹,尤其是在处理简单任务时,几乎瞬间完成。
我用 Cursor 时发现,偶尔会生成一些不符合预期的代码,可能是因为提示词不够清晰吧。
Cursor的编程体验真的很神奇,能让人感觉像是有个助手在旁边。
好奇 Cursor 是否能处理更高级的编程任务,结果会如何呢?